

图形引擎实战:Unity Shader变体管理流程
source link: https://blog.uwa4d.com/archives/USparkle_SVMP.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一、什么是Shader变体管理
想要回答这个问题,要看看什么是Shader变体。
1. 变体
我们用ShaderLab编写Unity中的Shader,当我们需要让Shader同时满足多个需求,例如,这个是否支持阴影,此时就需要加Keyword(关键字),例如在代码中#pragma multi_compile SHADOW_ON SHADOW_OFF,对逻辑上有差异的地方用#ifdef SHADOW_ON或#if defined(SHADOW_ON)区分,#if defined()的好处是可以有多个条件,用与、或逻辑运算连接起来:
Light mainLight = GetMainLight();
float shadowAtten = 1;
#ifdef SHADOW_ON
shadowAtten = CalculateShadow(shadowCoord);
#endif
float3 color = albedo * max(0, dot(mainLight.direction, normalWS)) * shadowAtten;
然后对需要的材质进行material.EnableKeyword("SHADOW_ON")和material.DisableKeyword("SHADOW_ON")开关关键字,或者用Shader.EnableKeyword("SHADOW_ON")对全场景包含这一keyword的物体进行设置。
上述情况是开关的设置,还有设置配置的情况。例如,我希望高配光照计算用PBR基于物理的光照计算方式,而低配用Blinn-Phong,其他计算例如阴影、雾效完全一致,也可以将光照计算用变体的方式分隔。
如果是Shader编写的新手,可能有两个问题:
1. 我不能直接传递个变量到Shader里,用if实时判断吗?
答:不可以,简单来说,由于GPU程序需要高度并行,很多情况下,Shader中的分支判断需要将if else两个分支都计算一遍,假如你的两个需求都有不短的代码,这样的开销太大且不合理。
2. 我不可以直接将Shader复制一份出来改吗?
答:不是很好,例如你现在复制一份Shader出来,还需要对应脚本去找到需要替换的Shader然后替换。更重要的是,当你的Shader同时包含很多需要切换的效果:阴影、雾效、光照计算、附加光源、溶解、反射等等,总不能有一个需求就Shader*2是吧。
#pragma multi_compile FOG_OFF FOG_ON
#pragma multi_compile ADDLIGHT_OFF ADDLIGHT_ON
#pragma multi_compile REFLECT_OFF REFLECT_ON
//something keyword ...
这种写法属于比较死亡的写法,别在意,后面自然会说出各种写法中不好的地方并提出回避建议。
而对于当前材质,就会利用上述的关键字进行排列组合,例如一个“不希望接受阴影,希望有雾,需要附加光源,不带反射”,得到的Keyword组合就是:SHADOW_OFF FOG_ON ADDLIGHT_ON REFLECT_OFF,这个Keyword组合就是一个变体。对于上面这个例子,可以得到2的4次方16个变体。
我们知道了什么是变体,再来回答为什么要变体管理。
可以发现上述例子中,每多一条都会乘2,实际上一列Keyword声明可以不止两个,声明三个、甚至更多也是可能的。
不管怎么说,随着#pragma multi_compile的增加,变体数量会指数增长。这样会带来什么问题呢?
这时候需要了解下Shader到底是什么。
2. Shader
ShaderLab其实不是很底层的东西,它封装了图形API的Shader,以及一堆渲染命令。对于图形API,Shader是GPU的程序,不同API上传Shader略有区别,例如OpenGL:
GLuint vertex_shader;
GLchar * vertex_shader_source[];//glsl源码
//创建并将源码传递给GPU
vertex_shader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertex_shader, 1, vertex_shader_source, NULL);
//编译
glCompileShader(vertex_shader);
//绑定
glAttachShader(program, vertex_shader);
DX12/Vulkan的编译方式有很多,可以提前编译成二进制/中间语言的DXBC/SPIR-V,也可以用HLSL/GLSL实时生成DXBC/SPIR-V传递给GPU,例如DX12使用D3DCompileFromFile实时编译HLSL到DXBC:
ComPtr<ID3DBlob> byteCode = nullptr;//二进制DXBC
D3DCompileFromFile(filename.c_str(), defines, D3D_COMPILE_STANDARD_FILE_INCLUDE,
entrypoint.c_str(), target.c_str(), compileFlags, 0, &byteCode, nullptr);
对于现在的我们来说主要关注前两个参数,第一个是读取的文件名,第二个是D3D_SHADER_MACRO的数组:
typedef struct _D3D_SHADER_MACRO
{
LPCSTR Name;
LPCSTR Definition;
} D3D_SHADER_MACRO;
实际上传入类似这样:
const D3D_SHADER_MACRO defines[] =
{
"FOG", "1",
"ALPHA_TEST", "1",
NULL, NULL
};
这个就是变体的底层所在,也就是说,每有一个变体,都会构造这么一个Defines,然后调用编译程序编译Shader为DXBC。
我们在引擎层面说的变体,就是这些底层的Shader,是OpenGL的GLSL、DirectX的DXBC/DXIL、Vulkan的SPIR-V;而变体指数级增长,相当于这些底层的这些Shader指数级增长。
变体数太多对开发模式可能没有什么,最多是开编辑器时多喝点茶,但项目需要打包、上线就不是这样了。
别看这些都能Shader实时用Shader编译生成,但引擎不会这么做,而是在打包时就需要知道所有可能用到的变体,将其打包出来。
很浅显的原因是Shader编译的时间也不短,Unity/UE这些引擎为了方便用户编写,主要编写的语言是HLSL,如果你的游戏是DX11/DX12,实际运行会将HLSL编译为DXBC,单个的时间不长,但达到一定数量就会有明显卡顿,如果场景出现一些附加光源,突然多出来这些变体Shader需要实时生成,这个时间说不定会是几秒。
如果你的API是OpenGL,为了获取到GLSL,Unity用HLSLcc将HLSL变成GLSL,然后再编译程序;如果API是VulKan,前面按照OpenGL一样先生成GLSL,然后再用glslang生成SPIR-V。对于UE,这个流程会有区别,详见《跨平台引擎Shader编译流程分析》。
对于DX12和VK这样的现代API,新生成Shader意味着要生成PSO(管线状态对象),这又是一笔超级大的开销。
如果不提前将Shader Build好,你现在打包时编译Shader的时间,就是你未来用户第一次进入游戏的时间。总之确定了一件事,__在打包时,预计用到的Shader变体(DXBC/GLSL/SPIR-V)就会全都打入包中。
变体数量对包体的影响倒是未必很大,因为AssetBundle有压缩,而你的变体之间只是略有差异,很可能200MB的Shader文件,压缩后不到2MB。
真正进入游戏中,游戏会先将Shader从AssetBundle中解压出来放到CPU先准备着,当GPU需要用到变体时,再送入GPU。重点是解压后Shader的大小就不是那么理想了,你可以用你完全没有Shader管理的游戏项目打个包,然后Unity到Window>Analysis>Profiler。
连接adb到手机,然后点击 内存>Take Sample AndroidPlayer>Other>Rendering>ShaderLab 查看:
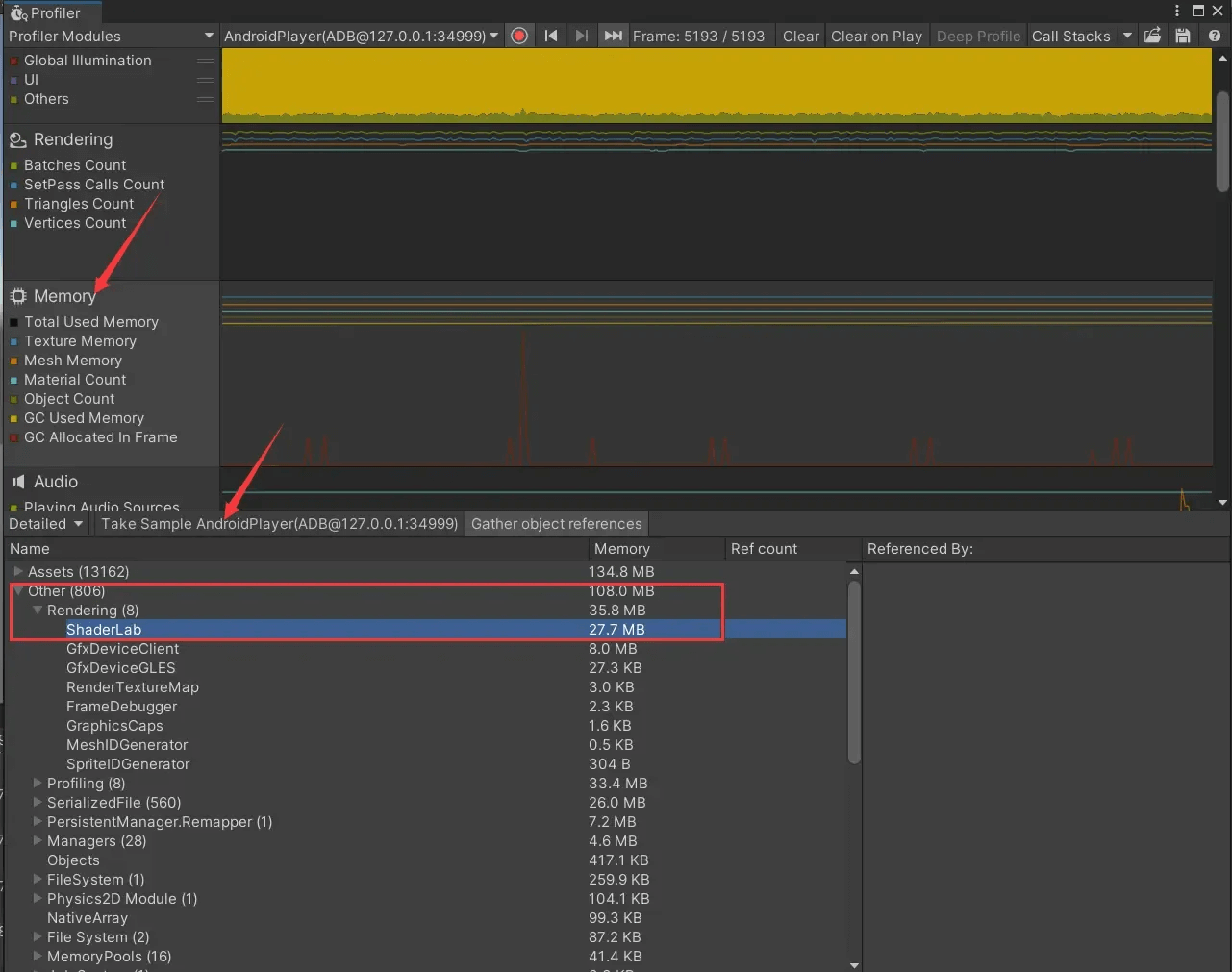
未经过管理的变体可能导致ShaderLab占用内存一个多G,这显然是不可接受的。这是内存上的问题,此外还有运行时加载的问题。但现在还是上述的情景,假如场景中突然出现一盏附加光源,需要对已有的Shader都开启新的变体,这些变体都存在于内存中,因为你打包时已经打入了,你省下了将HLSL生成为DXBC/GLSL/SPIR-V的时间,但是将DXBC/GLSL/SPIR-V送入GPU、生成PSO的时间却是省不下的,这依旧可能会造成卡顿。
结合上述问题,所以我们需要对Shader变体做管理。
二、如何对Shader变体进行管理
上面描述了Keyword组合造成的变体数量爆炸,首先我们希望无效变体尽量少,想要达成这个目的,需要从两方面出发,分为个人和项目。
1. 个人角度对Shader变体管理
个人是指TA、引擎、图程以及其他Shader开发者,在编写Shader时就要注意变体的问题。
首先,该用if用if,之前虽然说在GPU执行分支开销不低,但只是相对而言的,如果你的if else执行的是整个光照计算,那显然是不可接受的,但假如if else加起来没两行代码,那显然是无所谓的,要是在变体极多的时候去掉个Keyword,变体数直接砍半,对项目的好处是极大的,这需要开发者自己权衡。
其次,之前的例子都用的是multi_compile,但实际上不一定需要multi_compile,某些情况下用shader_feature是可以的。
1.1 multi_compile和shader_feature的区别
用multi_compile声明的Keyword是全排列组合,例如:
#pragma multi_compile A B
#pragma multi_compile C D E
组合出来就是AC、AD、AE、BC、BD和BE6个,如果再来一个#pragma multi_compile F G显然会直接翻倍为12个。
shader_feature则不同,它打包时,找到打包资源对变体的引用,最普通能对变体引用的资源是Material(例如场景用了一个MeshRenderer,MeshRenderer用了这个材质,材质用了这个Shader的一个变体)。
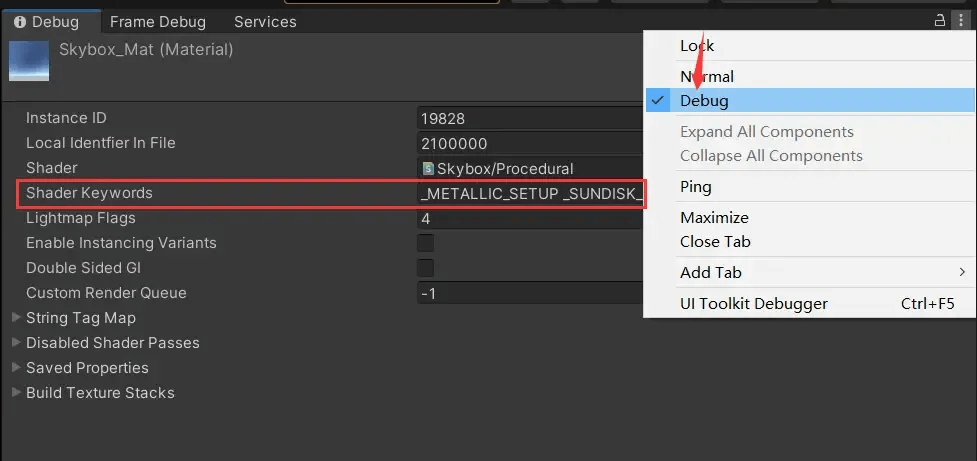
在Inspector窗口右上角将Normal换成Debug模式,可以看到材质引用的Keyword组合:
假如将上述multi_compile替换为shader_feature:
#pragma shader_feature A B
#pragma shader_feature C D E
我打包只打一个材质,这个材质用到了变体组合AC,那么打包时只会将AC打出来。
如果我的材质引用的是AE,那么会打出AC和AE,因为C是第二个Keyword声明组的默认Keyword,当你的材质用了这个Shader,却没有发现没有引用这一声明组的任何一个Keyword(比如上面CDE都没引用),就会退化成第一个默认Keyword(上面的例子是C)。
所以一般声明Keyword组如果包含默认Keyword、关闭Keyword不会声明XXX_OFF,而是声明成 #pragma multi_compile _ C D,这样如果材质引用AD,则会打出A和AD,不会减少变体数量,但可以减少Global Keyword的数量(Unity 2020及以下版本只能有384个Global Keyword,2021之上有42亿个。)
1.2 打包规则
打包时会将multi_compile和shader_feature分为两堆,分别计算组合数,然后两者再组合,例如:
#pragma multi_compile A B
#pragma multi_compile C D
#pragma shader_feature E F
#pragma shader_feature G H
当你只打两个材质,引用的变体分别是ADEG和ACFH,前两个multi_compile组直接组合成4个变体,后面两个shader_feature组分别引用到了EG和FH,然后两组组合4*2,最后打出8个变体。
1.3 编写建议
对于个人来说,较为通用的编写方式是,multi_compile建议用于声明可能实时切换的全局Keyword声明组,例如阴影、全局雾效、雨、雪。因为一个物体可能在多个场景使用,材质也就会在多个场景用到,一个场景有雾,另一个场景有雨,而材质只能引用一组Keyword组合,为了能实时切换,就需要把切换效果后的变体也打入包中;而对于材质静态的Keyword声明组就可以用shader_feature,例如这个材质是否用到了NormalMap,是否有视差计算,这个在打包时就确定好的,运行时不会动态改变,即可声明为shader_feature。
multi_compile_local适合解决打包时不确定变体,需要在运行时动态切换单个材质变体的需求,例如某些建筑、角色需要运行时溶解;溶解只针对当前角色的材质而不是全局的,需要Material.EnableKeyword,所以用Local;并且需要溶解/未溶解的变体都被打入包中,所以需要声明为multi_compile在打包时排列组合,组合起来就是multi_compile_local。
小贴士:
shader_feature和multi_compile后面也可以加其他条件,例如,如果确定一组Keyword声明只会导致VertexShader有变化,即可再后面加_vertex,例如shader_feature_vertex。
shader_feature_local的_local声明和变体数无关,是Unity 2021之前为了解决GlobalKeyword数量问题出现的解决方案,声明为Local Keyword不会占用Global Keyword数,建议是如果Keyword声明组是需要材质本身设置(而不是全局的),声明为_local;当Keyword为Local时,Shader.EnableKeyword或CommandBuffer.EnableKeyword这种全局开启Keyword方式,无法启用当前材质的关键字,只能由材质开启。
有些声明是Unity内置的,例如#pragma multi_compile_instancing相当于#pragma multi_compile _ INSTANCING_ON,#pragma multi_compile_fog则会声明几个雾相关的keyword。
2. 项目角度的变体管理
有些问题从个人开发角度是难以规避的。希望Shader的开发者都能从个人编写角度做好变体管理,往往是不现实的,Shader开发者水平有高有低,或许某个实习生或客户端为了快速实现效果,就从网上Copy下来一段代码,运行一下效果没问题就不管了;再或者某个美术导入了一个插件,而插件的编写者没有考虑过变体的问题等等。
2.1 变体剔除
Unity提供了IPreprocessShaders接口,让用户自定义剔除条件。
自定义的类继承IPreprocessShaders后,需要实现void OnProcessShader(Shader shader,ShaderSnippetData snippet,IList inputData)方法,这是一个回调函数,当打包时,所有Shader变体都会送进来进行判断。
三个参数中,第一个是UnityShader对象本体。
第二个存了底层Shader类型和Pass类型,ShaderType包括Vertex、Fragment、Geometry等;PassType存了Pass类型,例如BuildIn Shader一般有ForwardBase、ForwardAdd,SRP的SRP、SRPDefaultUnlit等。
第三个参数是ShaderCompilerData的List,ShaderCompilerData包含了当前变体包含哪些Keyword、变体所需的API特性级别、变体的API(只要PlayerSetting里添加了平台对应的API,可以同时打出多个图形API所需的Shader),可以将一个ShaderCompilerData视作一个变体。
这些参数包含变体的全部条件,用户可以根据项目需要自行编写剔除逻辑,当判断需要剔除一个Shader变体时,只需要将ShaderCompilerData从inputData这个List中删除即可。
下面是一个简单实例,如果我们想剔除所有包含INSTANCING_ON Keyword的变体时应该如何编写:
class StripInstancingOnKeyword : IPreprocessShaders
{
public void OnProcessShader(Shader shader, ShaderSnippetData snippet, IList<ShaderCompilerData> inputData)
{
for (int i = inputData.Count - 1; i >= 0; i--)
{
ShaderCompilerData input = inputData[i];
//Global And Local Keyword
if (input.shaderKeywordSet.IsEnabled(new ShaderKeyword("INSTANCING_ON")) || input.shaderKeywordSet.IsEnabled(new ShaderKeyword(shader, "INSTANCING_ON")))
{
inputData.RemoveAt(i);
}
}
}
}
一般情况下,项目会编写一个配置文件,里面记录各种需要剔除的变体条件,比如URP项目不需要BuildIn下的ForwardBasePass、DeferredPass,可以直接将这些Pass剔除掉,防止项目中有BuildIn下残留的变体。
有些Shader抄案例时,附带了#pragma multi_compile_fog等Unity自动生成的关键字,而实际上Shader可能用不到,可以通过项目整体剔除来抵消项目人员犯错。
还可以根据项目需求编写条件,比如说项目中角色Shader带有高配和低配关键字,用于区分着色计算,高配用于展示,低配用于战斗,能确定战斗效果(例如溶解、石化等)变体不可能出现高配变体上,因此可以判断当同时出现高模Keyword和战斗效果Keyword时剔除变体。
在我们项目中,通过变体剔除,能将占用上GB内存的ShaderLab降低到20多MB,可见变体剔除的必要性。
对于变体剔除工具的设计,可以参考我的个人变体剔除工具。
有时候需要注意,一些库(比如高版本的URP)也会自带变体剔除,了解项目时,先全局搜下继承IPreprocessShaders的类,防止变体在自己不知道的时候被剔掉。
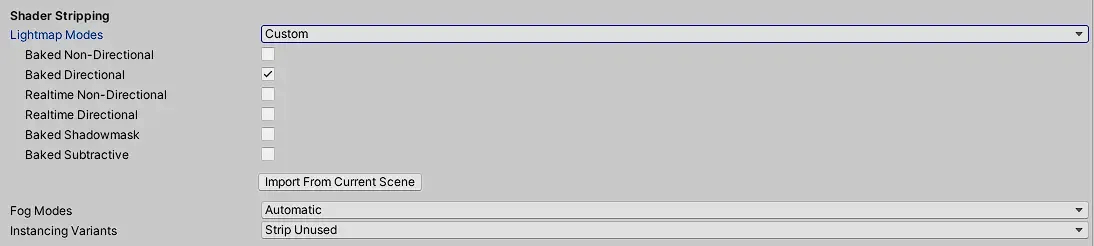
此外项目设置里也有一套变体剔除,在ProjectSetting>Graphics的Shader Stripping项下,当Modes是Custom时,只有勾选的会被打入包中。例如下图,只勾选了Baked Directional,会导致烘焙Lightmap的Shader中,如果有LIGHTMAP_ON但没有DIRLIGHTMAP_COMBINED的变体都被剔除。
上面用变体剔除解决变体过多的问题,但变体还有运行时加载时间和打包引用问题需要解决。
Unity为了解决这些问题,提供了变体收集功能,功能围绕着变体收集文件ShaderVariantCollection,创建方法为:在Project窗口右键>Create>Shader Variant Collection(2019是Create>Shader>Shader Variant Collection)。
这个文件本身没有什么特殊的,就是记录变体的文件而已,每个变体为PassType与Keyword的组合:
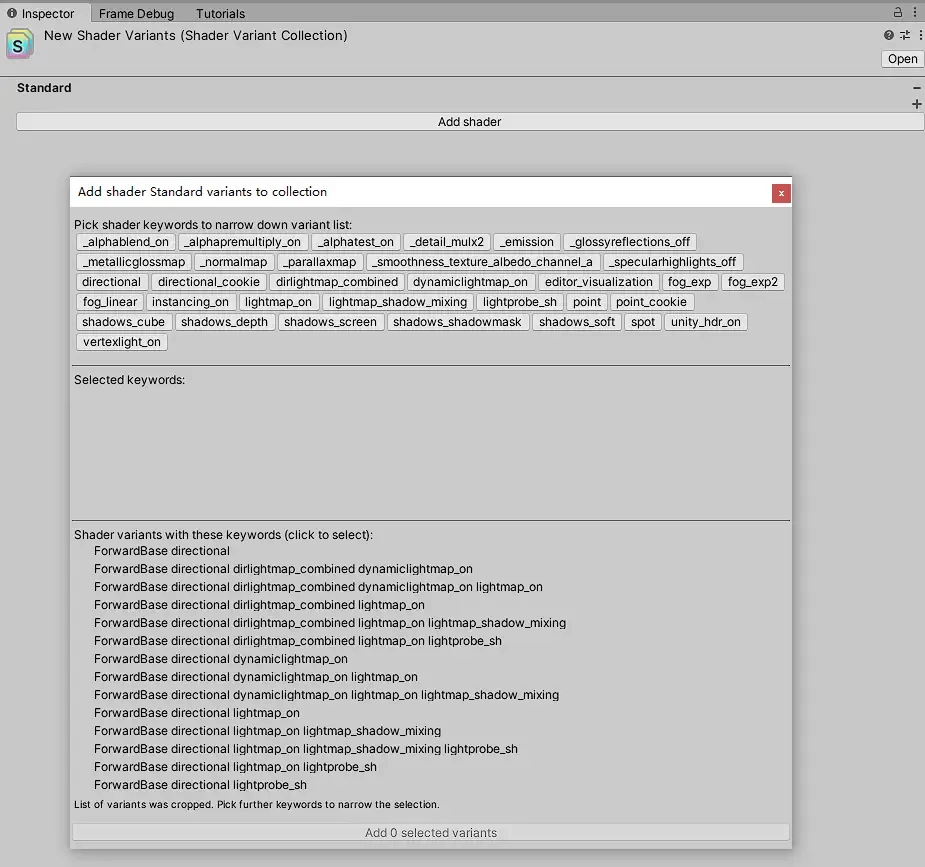
文件的作用有两个,其一是在打包时,对变体引用;其二是运行时,利用文件预热变体。
3. 变体预热
3.1 为什么要变体预热
还是上面的例子:Unity自带的设计中,附加光源是额外的变体,当场景超过一盏实时光时,会打开附加光源变体;这样可以保证,场景只有一盏实时光时,不会有额外的Shader计算开销。
但也带来一个问题。假如当前场景各种物体用到了50个变体,突然多出一个实时方向光,为了使场景被这第二盏灯照亮,需要将所有物体的变体切换为有附加光源的那一个,也就是相当于要准备50个变体。如果这50个变体没有准备完,就会造成卡顿。
这个场景是运行时游戏,附加光源的变体已经在包中,不需要重新从ShaderLab生成对应平台的底层Shader,但依旧需要将底层Shader送入GPU,例如glShaderSource加载GLSL源代码、vkCreateShaderModule从二进制SPIR-V创建VkShaderModule对象,以及后续创建PSO等流程依旧不能节省。
这样一来,还是会造成运行时卡顿,为了解决这个问题,就需要变体预热,提前将可能用到的变体送入GPU。
3.2 变体预热的方法
Unity提供了ShaderVariantCollection.WarmUp、Shader.WarmupAllShaders这些接口。其中Shader.WarmupAllShaders会预热所有变体,假如对变体剔除结果非常有信心可以使用。
ShaderVariantCollection.WarmUp会预热当前变体收集文件中所有记录的变体,提供了更精细化控制的可能,例如某些变体只会在某个小游戏场景出现,那么可以将相关变体放在一个收集文件中,只有进入这个小游戏场景加载时才预热变体。
4. 变体引用
4.1 为什么要变体引用
依照上文的说法,材质和变体收集文件都可以引用变体,那为何还需要变体收集文件呢?
如果是Unity直接Build一个包出来,那么确实不需要变体收集文件来引用变体。
但如果在有热更需求时就不同了;全部的Shader一般会打到一个单独Bundle中,根据Bundle中其他资源对变体的引用,决定哪些变体会打入当前Bundle;对变体产生引用的材质,往往不会放到Shader所在的Bundle,而是分散到其他很多Bundle中,这样就会导致打Shader的那个Bundle找不到变体引用,从而无法将需要的变体打入Shader Bundle。
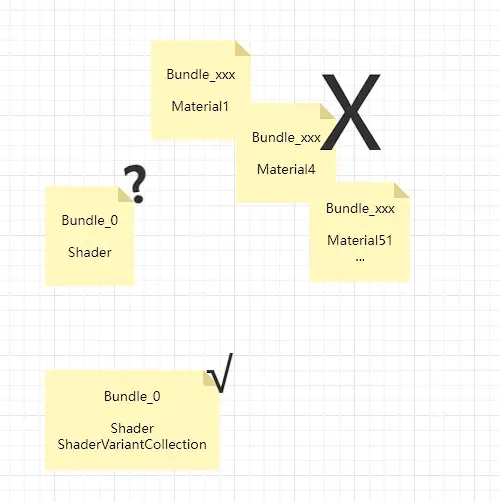
所以就需要一个变体收集文件,将需要打包的变体写入文件,用这个文件来保持变体引用,然后将文件和Shader打入同一个Bundle中,这样就能将需要的变体打入Bundle。
5. 变体收集
变体收集文件是一个记录变体的文件,需要考虑的是如何收集需要的变体。
5.1 基础操作
最基础的操作就是手动添加,就如下图所示,变体收集文件的面板中,点击Shader后面的“+”,然后排除不需要的Keyword,在下面选择需要添加的变体,然后点击“Add 2 selected variants”。
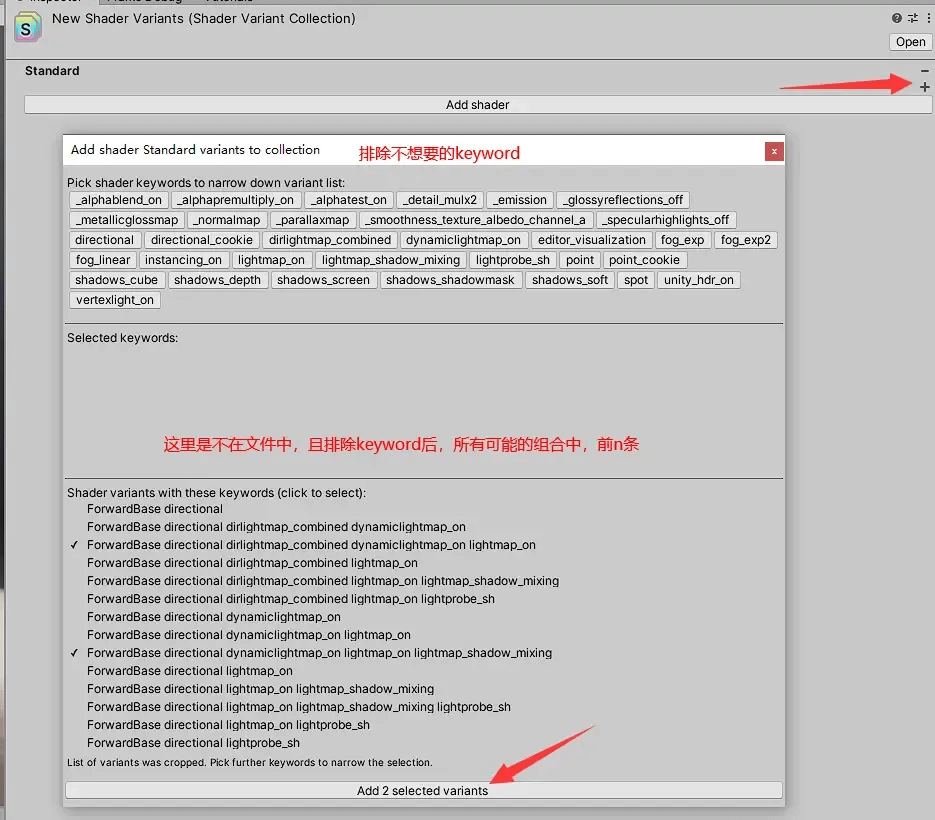
这种方法只适合简单维护,实在不推荐这样做,显而易见的原因是这样很容易漏掉变体,而且Unity的这个工具面板,也给我一种“都别这么用”的感觉。
就提出几个简单的操作场景:如果文件中已经有了二、三十个Shader,个别Shader内收集了五、六十个变体,我想要在这么多Shader和变体中,找到我想要操作的Shader,就需要翻好久。
如果我想要添加一个Keyword,与现有的变体做排列组合,只能用面板手动点击。
如果收集文件中已经有一千多个变体,这个面板就会出现明显卡顿。
总结起来就三个字:孬操作。这肯定不是技术问题,那么我只能理解为Unity告诉我们:“都给我老老实实去跑变体收集!”
5.2 跑变体收集
这个是相对自动的方法,使用方法是在ProjectSetting>Graphics的最下面,先Clear掉当前的记录,然后进行游戏,尽量覆盖大多数游戏内容,之后点击Save to asset保存。
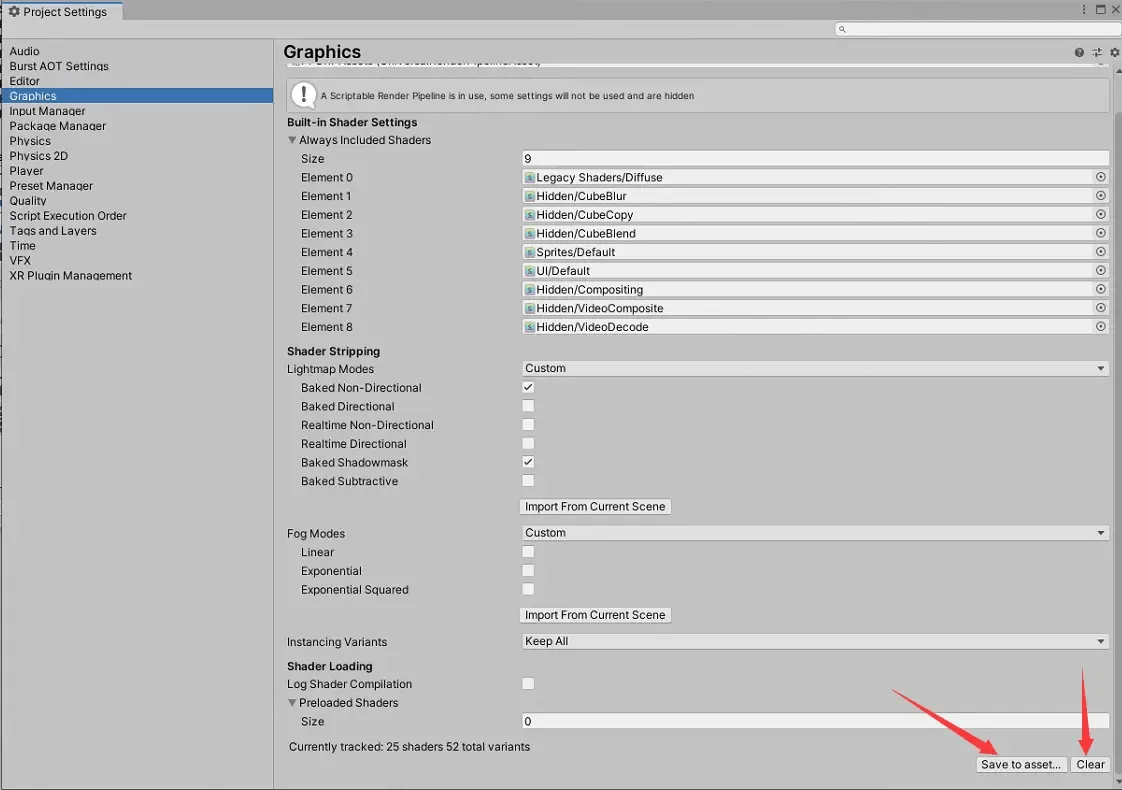
显而易见的问题是,容易漏变体,无论是给引擎还是测试来跑变体收集,总可能有覆盖不到的变体。
其次是不好更新,假如调了下场景以及材质,上传后需要更新文件,那只能重新跑收集,不然总不能让美术去管变体收集吧?
其三是容易受Shader质量影响。假如某个Shader开发者没注意,在Shader不需要的时候,加了这个声明:#pragma multi_compile_fwdbase,这个Built-in的变体声明,声明出DIRECTIONAL、LIGHTMAP_ON、DIRLIGHTMAP_COMBINED、DYNAMICLIGHTMAP_ON、SHADOWS_SCREEN、SHADOWS_SHADOWMASK、LIGHTMAP_SHADOW_MIXING、LIGHTPROBE_SH这么一大串变体,而运行游戏时,Unity会根据当前情况启用这些变体,就会导致变体收集到不需要的变体。
6. 定制化变体收集工具
6.1 变体收集文件的增删查改
既然Unity内置的工具不好用,那就要想办法自定义工具。
然后Unity给了当头一棒,ShaderVariantCollection接口不全,自带的接口中只包含:Shader数量、变体数量、添加和删除变体。至于文件中有哪些Shader和变体,接口是一概没有的。
好在Unity开放出了UnityCsReference,其中ShaderVariantCollection的Inspector给出了示例写法,需要用SerializedObject获取C++对象:
private ShaderVariantCollection mCollection;
private Dictionary<Shader, List<SerializableShaderVariant>> mMapper = new Dictionary<Shader, List<SerializableShaderVariant>>();
//将SerializedProperty转化为ShaderVariant
private ShaderVariantCollection.ShaderVariant PropToVariantObject(Shader shader, SerializedProperty variantInfo)
{
PassType passType = (PassType)variantInfo.FindPropertyRelative("passType").intValue;
string keywords = variantInfo.FindPropertyRelative("keywords").stringValue;
string[] keywordSet = keywords.Split(' ');
keywordSet = (keywordSet.Length == 1 && keywordSet[0] == "") ? new string[0] : keywordSet;
ShaderVariantCollection.ShaderVariant newVariant = new ShaderVariantCollection.ShaderVariant()
{
shader = shader,
keywords = keywordSet,
passType = passType
};
return newVariant;
}
//将ShaderVariantCollection转化为Dictionary用来访问
private void ReadFromFile()
{
mMapper.Clear();
SerializedObject serializedObject = new UnityEditor.SerializedObject(mCollection);
//serializedObject.Update();
SerializedProperty m_Shaders = serializedObject.FindProperty("m_Shaders");
for (int i = 0; i < m_Shaders.arraySize; ++i)
{
SerializedProperty pair = m_Shaders.GetArrayElementAtIndex(i);
SerializedProperty first = pair.FindPropertyRelative("first");
SerializedProperty second = pair.FindPropertyRelative("second");//ShaderInfo
Shader shader = first.objectReferenceValue as Shader;
if (shader == null)
continue;
mMapper[shader] = new List<SerializableShaderVariant>();
SerializedProperty variants = second.FindPropertyRelative("variants");
for (var vi = 0; vi < variants.arraySize; ++vi)
{
SerializedProperty variantInfo = variants.GetArrayElementAtIndex(vi);
ShaderVariantCollection.ShaderVariant variant = PropToVariantObject(shader, variantInfo);
mMapper[shader].Add(new SerializableShaderVariant(variant));
}
}
}
能增删查改就带来无限的可能,在我编写的工具中,首先就给了便捷访问功能,抛弃了Unity自带的面板,可以快速定位Shader、Pass、变体:
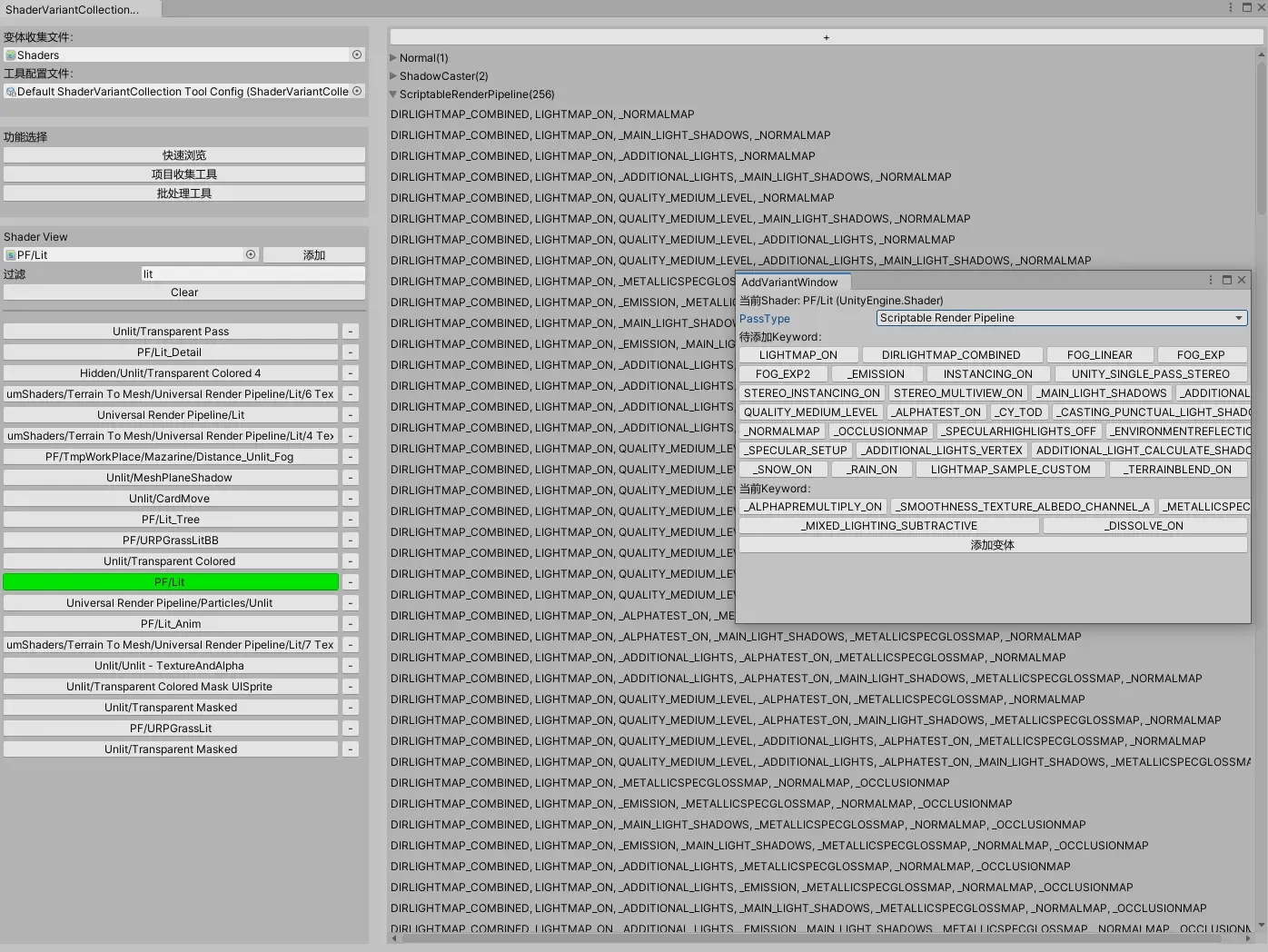
6.2 自动化的变体收集
话说回来,自动化的变体收集,就要知道哪些变体需要被打包。按照我们之前说的,材质会引用变体,所以首先确定哪些材质会被打包;其次,确定这个材质会引用哪个、哪些变体;最后,将变体写入变体收集文件。
对于哪些材质会被打包,我能想到的有两种,其一是被打包场景所引用的材质,既BuildSetting里面那些场景;其二是项目的资源表直接或间接引用材质。
其他可能性暂时想不到,但基于拓展性需求,我抽象出收集器类,工具会执行所有收集器收集材质,如果有拓展需求,就添加收集器:
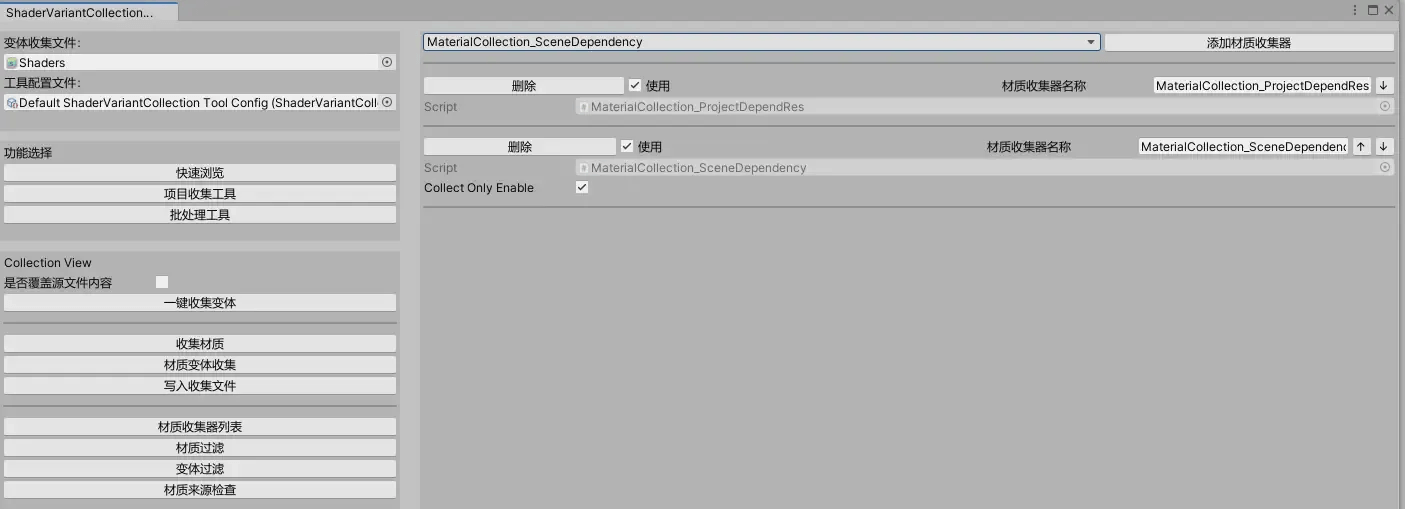
上图中就包含了两个材质收集器,分别收集场景依赖和资源表依赖材质。
对于材质会引用到哪个、哪些变体,依照上文变体剔除配图所示,材质会保留ShaderKeywords,似乎这就是材质所引用的变体。
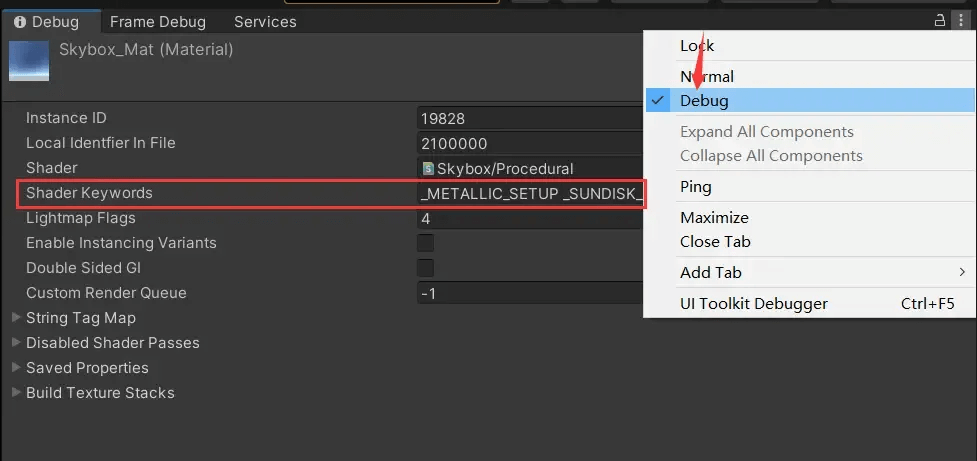
其实不然,这里是材质经过调用Material.EnableKeyword后,会将Keyword写入这里,哪怕Shader没有这个Keyword。
在上文中,我们建议对于所有在打包时,材质能确定的静态效果(是否用Bump Map、视差、BlendMode等),用shader_feature_local来定义;同时,材质面板的自定义代码中,开启效果的按钮,会调用Material.EnableKeyword。
但Unity抽象的ShaderLab不止一个Pass,假如我们要给阴影投射Pass声明一个Keyword组,开启效果时,面板代码会按程序往材质的ShaderKeywords里面写入一个Keyword,但正常的Pass(如UniversalForward、ForwardBase等)并没有声明这个Keyword,因此这个ShaderKeywords很显然不能代表这个材质所引用的变体,也可以说明材质能不止引用一个变体。
如何知道材质到底引用了多少个变体,我们看下面的例子(伪代码):
Pass
{
Tags{"LightMode" = "ShadowCaster"}
#pragma shader_feature SHADOW_BIAS_ON
#pragma shader_feature _ALPHATEST_ON
}
Pass
{
Tags{"LightMode" = "UniversalForward"}
#pragma shader_feature _ALPHATEST_ON
#pragma shader_feature _NORMALMAP
//....
}
此时,一个材质的ShaderKeywords中记录了SHADOW_BIAS_ON、_ALPHATEST_ON两个Keyword,那么材质就引用了SHADOW_BIAS_ON _ALPHATEST_ON和_ALPHATEST_ON这两个变体。
这没什么问题,似乎找到当前PassType可以包含的最长组合就好了,但ShaderLab中的PassType是可以重复的,此时如果有一个描边Pass:
Pass
{
Tags{"LightMode" = "Outline"}
#pragma shader_feature OUTLINE_RED OUTLINE_GREEN OUTLINE_BLUE
#pragma shader_feature _ALPHATEST_ON
}
这个Pass的类型也是ScriptableRenderPipeline,如果一个材质引用了SHADOW_BIAS_ON、_ALPHATEST_ON、OUTLINE_RED三个Keyword,那么实际上Shader引用了三个变体,分别是SHADOW_BIAS_ON _ALPHATEST_ON(ShadowCasterPass)、_ALPHATEST_ON(UnversalForwardPass)、_ALPHATEST_ON OUTLINE_RED(OutlinePass),这种情况就无法简单用Unity现有API来判断材质究竟引用了多少个变体。
我当前的方案,是对ShaderKeywords中每个Keyword与其他所有Keyword进行组合,找到每个Keyword的最长合法组合都算作材质引用变体;可以缓解但无法解决上述情况,想要解决就必须获取ShaderPass本身的Keyword声明情况,可惜Unity没有提供相关API,只能自己写代码进行文本分析;所以Shader建议编写时不要在相同PassType的不同Pass中声明相同的Keyword。
合法的变体组合,Unity也没有提供相关接口,但构造变体对象时如果不合法,会在构造函数报错,所以我的判断函数简单粗暴,直接用try catch。
经过这样一轮收集,基本解决了变体打包时的引用问题。
7. 工具拓展
7.1 变体预热
上述解决了变体引用问题,打包大多数情况不会发生丢变体的情况,但变体预热的问题又回来了,我们只收集了材质中的ShaderKeywords,按照上面的说法,这些Keyword都是shader_feature,属于静态效果的开关,但动态的效果没有进行组合。
如雾效、Lightmap、多光源等效果,这些Keyword是由multi_compile声明的,打包时会自动与shader_feature的组合进行再排列组合,会打入包中,不会出现丢变体的问题;但预热所解决的问题不是打包,而是运行时切换效果时,加载Shader带来的卡顿问题;假如变体收集文件没有收集multi_compile的组合,ShaderVariantCollection.WarmUp就不会预热相关变体。
所以我们希望尽可能的,将所有可能切换效果的变体,写入变体收集文件中。既然打包时会进行排列组合,那么可以将这一步骤引入变体收集。
这种功能可能会在每次重新收集变体后都要执行一遍,因此我将这一类行为抽象为批处理执行器接口,接口包含Execute方法,传入变体收集文件,然后在方法里进行相关操作。执行器是可序列化的对象,可以将数据保留,只需要变体管理者操作一次,即可在多次收集材质时复用。
排列组合执行器会完成我需要的功能:
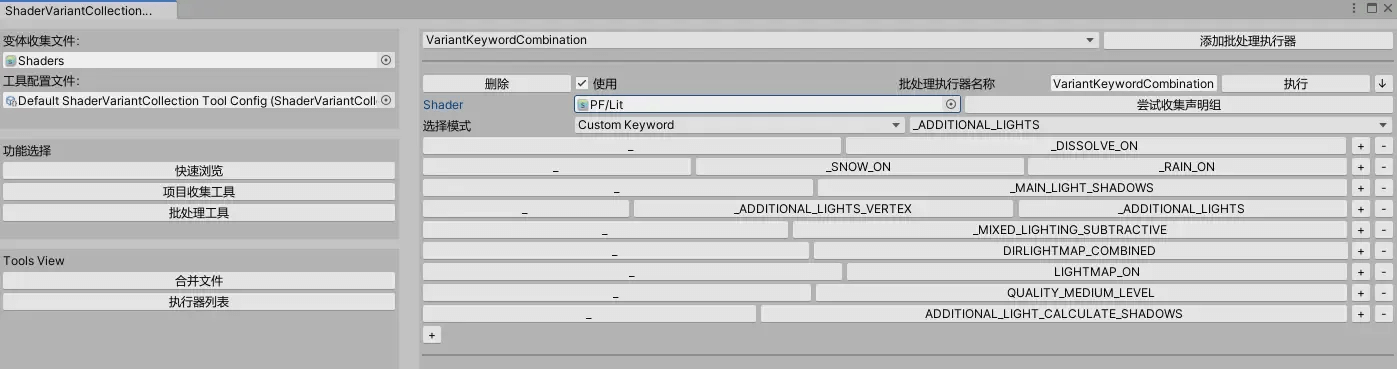
执行器自定义面板的尝试收集声明组,会用正则匹配Shader中声明的所有multi_compile组合,然后再由人工剔除不需要的声明组。
通过运行执行器,即可将声明组与收集文件中相应Shader变体进行排列组合,这样就能将multi_compile组合也进行预热。
7.2 变体剔除
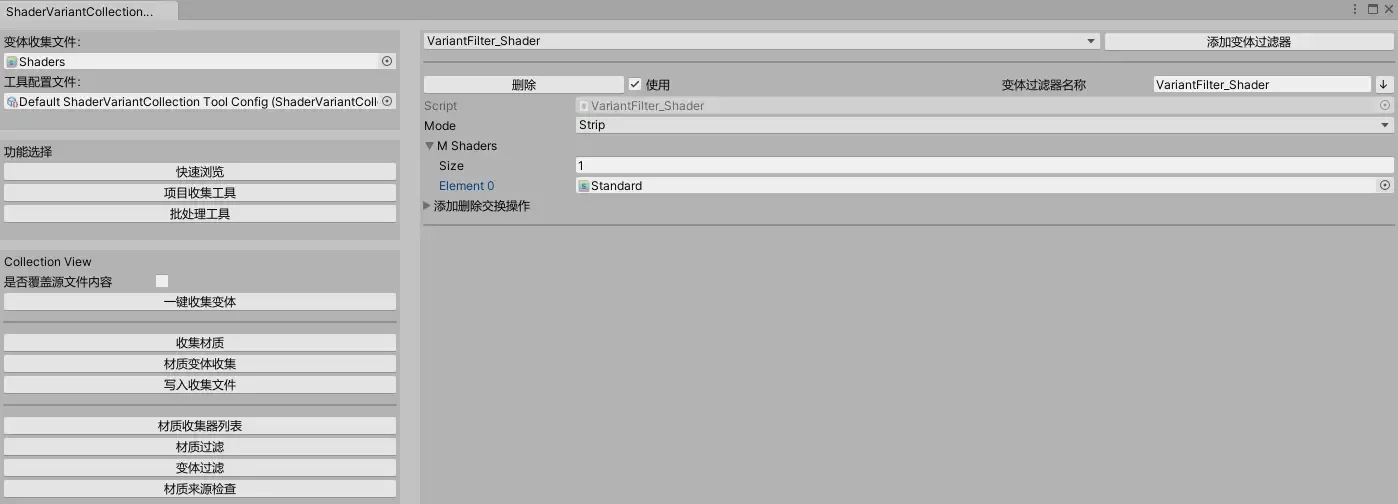
自动收集免不了收集到一些不想要的Shader和变体,例如URP项目里收集到Standard,哪怕变体剔除工具会作为打包前最后一道壁垒,我扔希望在收集就避免收集到。
我先是抽象出材质和变体的过滤器类,根据需求实现接口,这样避免收集到不想要的变体。
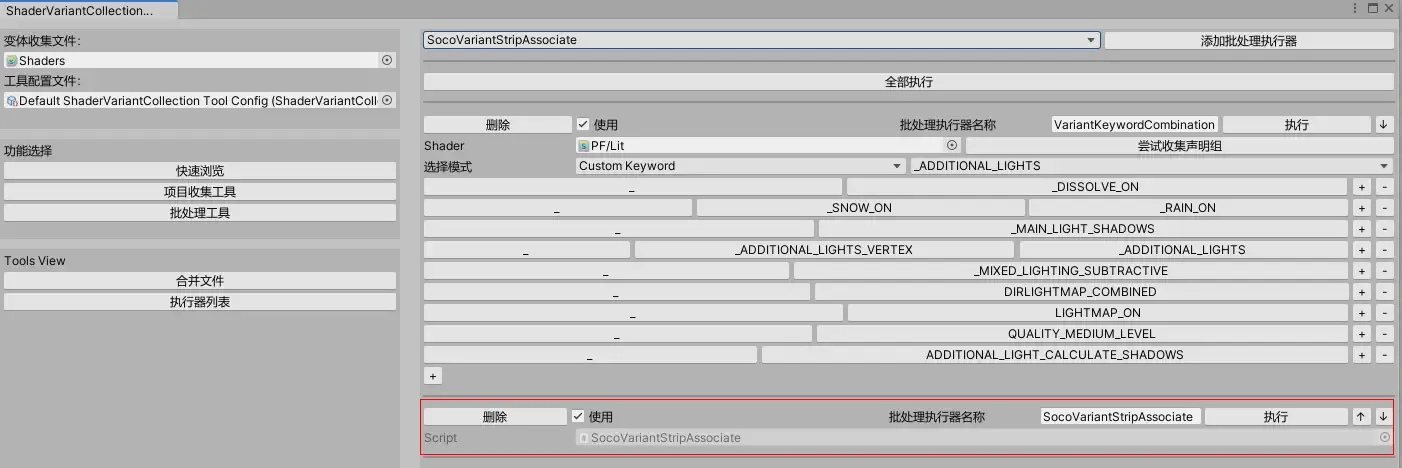
其次是收集到变体,再进行排列组合后,某些变体组合可能是我们不想要的,如果再写一套剔除执行器似乎和变体剔除有些重复了,但转念一想,我们有变体剔除工具,何不将两者联动下,于是专门写了一个联动执行器,调用变体剔除工具的接口提前进行变体剔除:
三、总结
我花了不少时间思考并完成了相关工具的设计,也参考了其他人的工具和方法。
项目中应用时,有些同事误以为这些工具是全自动的,放在工程里就完事,但我感觉这不大可能;项目没有对Shader进行严格的约束,Shader开发者的能力也有高有低,Keyword定义各种Copy、shader_feature和multi_compile定义哪个、是否定义成Local、built-in keyword有什么作用,很多人都不明白就开始写(这是很正常的,学习是循序渐进的过程),工具自然也无法判断开发者的意图。
因此一定有一个十分了解变体管理流程的人,来管理整个项目的Shader和变体,我开发的工具是用来简化这一流程,解决上述内置变体收集功能的痛点:易漏变体、不好更新、易受Shader质量影响,以及对现有文件的增删改查问题。上述提到的操作步骤无需进行多次操作,在首次调整好参数后会记录到配置文件中,日后需要重新收集时,只需要重新收集、运行批处理执行器即可。
这是侑虎科技第1390篇文章,感谢作者搜狐畅游引擎部供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
作者主页:https://www.zhihu.com/org/sou-hu-chang-you-yin-qing-bu
再次感谢搜狐畅游引擎部的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK