

高性能零售IT系统的建设10-一个系统日志记录搞崩了整个公司的O2O交易系统
source link: https://blog.csdn.net/lifetragedy/article/details/130731507
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

绝大多数业务系统其实都是一座屎山,本人接手的这座屎山目前已经成了一座金山。这其中的幸酸只有那些从0参与过并活到现在的一些“老人”们心中自知其中的滋味。
在3年半前,本以为买来的一套将近600万行代码、达800张表、几乎用到了所有的互联网中间件技术的中台我们只需要在其上开发业务代码、做企业的业务数字化创新就可以了,哪曾想到过它连200每秒并发都撑不住呢?
前面的系列我还只是讲了这座屎山中的问题的冰山一角,这些问题其实它们的根源是很easy就可以解决和治理的,但是当它已经是一个生产环境并且把这个问题我们放到99%的互联网企业里竟然都存在这种问题。这里面除了问题的本身技术层面的问题导致外,其实还有一个是“技术人员/团队文化”管理不善导致。
对于技术人员团队文化以及技术管理这个话题我会另开贴子来说明,我可以说80%的技术问题源自技术人员本身的职业素质和团队文化,20%才是真正的高难度技术问题。甚至更高可以把文化、综合素质导致的生产问题占比上升到90%这么一个比率。而且绝大多数(包括BATJ里也有一堆这样的问题还在日常发生着)。
这不。。。这次类似的问题又来了!
购物车性能随着TPS上升越来越慢甚至出现卡死和白屏
截至写稿时,现在的这支团队谁都不能相信在5位数并发下我们的购物车的提交可以在<1s的响应时间内返回。
回到3年半前这个系统刚上线两个月时,外部的订单量开始以倍数翻升,差不多在200tps即200个订单同时在购物车里提交要生成订单并异步落DB形成流水这么一个动作,一次一秒200个一提交,整个购物车的单用户响应时间已经>8s,一天内总有个8-10次会有出现小程序白屏、卡顿、进度条转啊转转不出。
听:那是业务在咆哮。。。听:那是IT在呻吟。。。
要知道,BATJ、MT、BE一些一线大厂的购物车都是<1s的响应啊。这才200tps,要是2,000tps的情况下呢?用户下单动作还不得几十秒一次呢?
我们是可以划入零售中的高频消费一类的商铺,2,000 tps日常那是最最基本的一个指标啊,如果店超3位数达4位数规模的企业一般都可以到达3,000-6,000 tps。因此购物车这么糟糕这个生意没法玩啊!
按照我对这个拿过来的代码整体架构风格的熟悉,我们顺藤摸瓜通过APM监控+Glowroot,很快就定位到了这么一个东西,而如果把这么一个东西改了可以彻底提高购物车到3-4s,而这个改动呢还是很简单的一个改动,可以说一点无技术含量的问题,但就是有那么90%以上的软件开发商甚至包括大厂都会有这个问题。
这到底是一个什么问题呢?
LOG4J输出日志!!!
小小的LOG4J竟然卡爆了全站
在这个系统的原厂框架内,TO C端的登录、注册、下单、领卷都关键动作因为都为http 200返回,因此异常日志都会以log4j来做记录,而零售中的业务动作会伴随着:正向单、反向单的动作。尤其是正向单、反向单时都又会涉及算税、分摊、支付等动作。因此我们为了排查经常除了在DB或者是NOSQL容器中记录业务流水交易日志以用来在发生问题时做红冲、冲单、反冲等动作外还需要额外记录一些关键信息以便于在并发、乱序的接口访问场景中通过LOG4J.ERROR/INFO出来的东西来便捷化我们的系统BUG的排查。
然后,我们会使用ELK或者是一些第三方日志系统亦可以是一些SAAS化产品来搜集全局日志。都是这么做的,那么日志把系统搞挂?这个简直不可思议。
前面说了,我们的一些TO C端甚至包括TO B端在一些关键部位都有LOG4J。很多还是AOP形式的。因此我们在排查购物车爆卡的问题的时我们发觉,其中一个人的一次购物车的LOG4J日志,在ELK里达到4MB,200个人一秒就是800MB。
尤其是我们的一些可爱的架构人员在排查这个购物车问题时说:这一段时间ELK里的日志光在ELK显示一下就把IE撑死了、查询时ELK页面不响应了、这个日志复制出来存盘成TXT后再用记事本打开查阅结果连记事本都打不开。。。。。。
天那!这是什么东西呢?这是系统日志呢还是每秒钟在生成一部DVD片子呢?

为什么会有这么多的日志呢?比如说购物车里我需要记录是哪个LOGIN TOKEN、有哪些PRODUCT-ID、有没有使用的券ID这些基本信息就可以构成我们在发生生产问题时的代码排查所需的基本元素了?就算往日志里再多加点内容,我们说:把每个商品的单价、品名、重量这些都打印在LOG4J。。。多增加了15个字段,我们看了一下,也不超过2K啊?怎么会有一次请求达4MB?
于是我们就在测试环境单做一笔交易,然后我们来看这一笔交易生成的购物车提交这个动作生成的日志内容。。。不看不知道,看了吓一跳。。。这个日志有200行哈!原来这个代码是把这个用户从注册、登录、门店、SKU、活动、券这些信息经过交叉比对(其实是一个迪卡尔积的交叉比对数据结构)的这一整个结果,变量名叫:paras,然后把这个paras呢给写在了log4j.info、log4j.debug、war、error中了。
这还不是最恐怖的地方,最恐怖的地方是业务代码里少有、不多有log4j.info啦、warn啦、error啦。。。这些log4j的输出大量的是含在一个个的AOP里的,由如下图所示:
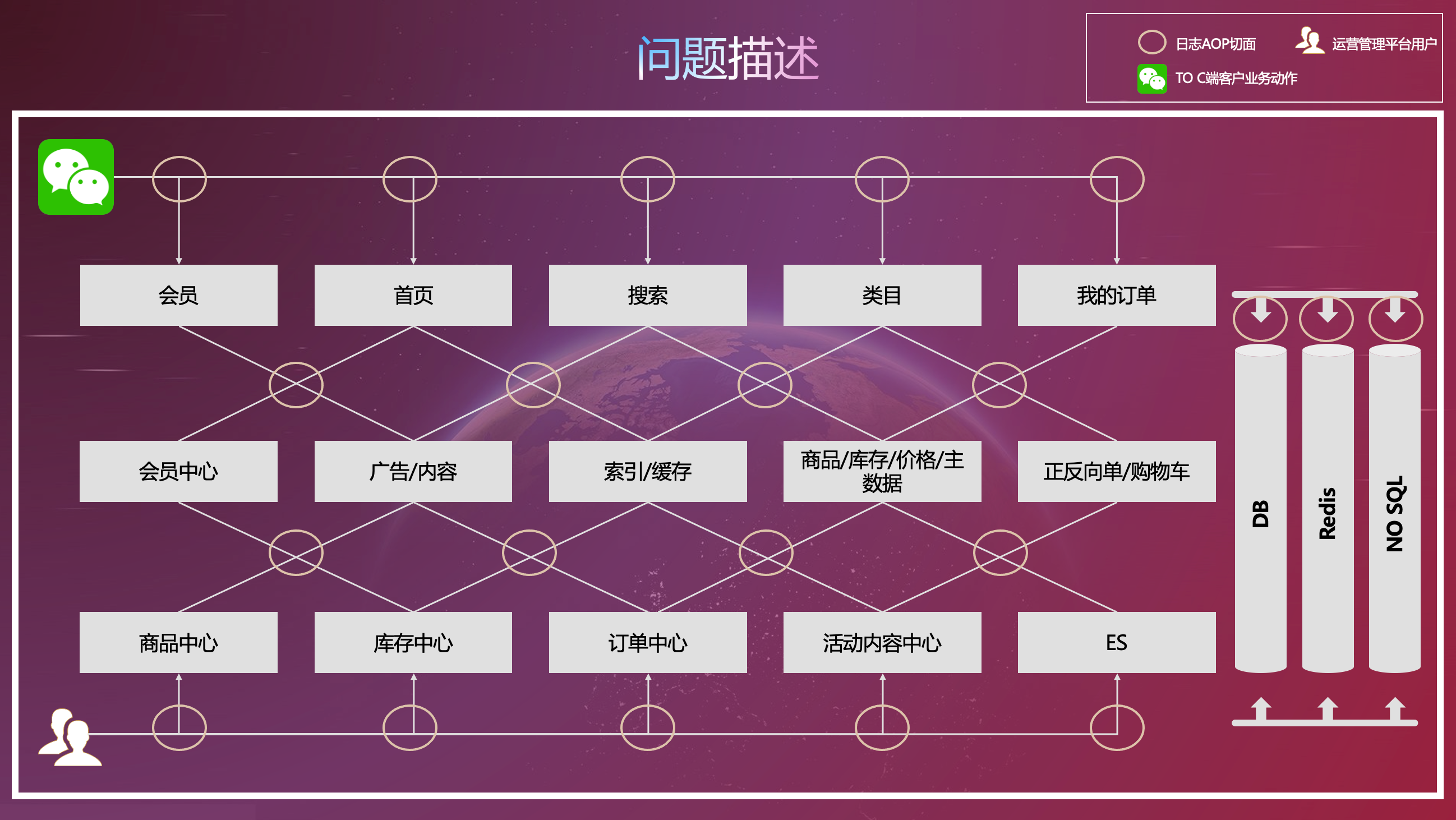
因为所谓的原来的架构框架为了加速开发团队交付的速度(乙方型公司图交付快,好快点拿到回款)因此不需要程序员们去考虑这些细节的操作、精细化的操作,所以就做了很多的封装,而这个封装的思想是个好东西但是这个行为实在是low的不行让人简直无法接受。
哦,不对。。。不仅仅是AOP,还有很多filter。。。还有很多helper类、还有很多spring boot的auto configuration类。。。都有像下面这么一句话,此处的参数这个paras里有80-100多个字段有些字段还是List<ProductInfor>然后在ProductInfor里再有一个如:Map<Long, Store>的复杂类型:
logger.info(paras);优雅啊、封装啊、开发省事啊、交付项目快啊!
哈哈,光一个购物车是800MB日志,介个还是最小的一个日志。。。各位,我们是一个零售企业哈,我们还有积分、还有促销、还有广告、会员日、目录浏览、搜索这些业务动作,它们都在吐着LOG4J日志。因此呢,当这个系统在200tps左右,一天能产生230多个G的log4j日志。
这些日志,还都参与到了一个互联网TO C端的实时交易中、它们从内网流到外网、从外网流到内网。占用了带宽、占用了磁盘、搞爆了小程序、搞爆了业务模块、搞爆了整个中台、搞爆了ELK。

如何改进?
这个问题的改进依然延用本系列中我前几篇中所一直用到的:逐步、递进、把大蛋糕切碎成小饼干的这种”零敲细打牛皮糖“手法来做改进,它分成了以下三个层面来做这件事的改进:
- 长期彻底杜绝
如果只有中短期改进的手法的话这是不够的。我们复盘了这个问题和追溯为什么会有这样的问题?是什么造成了这么简单的一个属于1+1=2的问题会造成如此大规模、严重的问题的呢?
此处再多说一句,各位不要笑,这和外包、乙方无关或者说不是强关联。更多的层面即造成此问题的90%的原因是属于意识层面。这样的问题在大厂里也都彼彼皆是,大家不要以为大厂就没有这种情况,稍有不注意就会形成类似这种低级问题。因此把这个事要延伸开来看团队和产品的长期发展,就不应该只观注于短期解决。短期解决不是本事、这个很简单。
难是难在1年后、2年后、3年后同类型的问题是不是会再犯呢?
因此我们这做任何事都有短、中、长三期考虑,长期上就是要建立起一支综合素质完全匹配研发的高效能团队。而要进化到这样的一支团队,人的意识才是最最重要的决定因素。只有意识到位了,它才会变成深入这个团队“骨髓”和“灵魂”的知识,我们用接地气的话来形容那就是:把这种意识变成团队的基因。
所以我们在给出具体解决方案前我们先来看我们梳理出的为什么会导致一个小小的log4j可以搞挂一个系统的root cause吧。

下面我们就一起来看详细展开的解决方案。
我们就把购物车这边的场景中那些个的确需要用log4j打印出来以便于万一生产有问题可以方便快速排查的字段列出来,差不多24个。。。那么需要这24个就log4j里打印这24个字段的值就行了,而不需要去把一整个从上到下的context的paras给输出到log4j中。
得到的效果
单单去掉了大对象在log4j中输出,整个购物车的提交在200并发下就从8秒提高到了4秒(我们现在的购物车已经完全媲美一流的商城了)。这个差距得要有多大?给人以一种。。。神来之笔的感觉。很多人不相信,你们到底这5分钟干了什么?
而身在其中的我们都知道,这东西简直没有技术含量到不能再没有技术含量了。
由于有了这么小的一个改动就取得了这么大的成功,于是给到了整个团队以信心并且把这个教训变成了一个鲜血淋淋的历史教育场景。因此我们制定了一套改进手法,我们会在所有的微服务中先通过全局文件内容搜索logger.info/debug/warn/error一类的语句。再搜索使用AOP方式来输出logger的那些个点。
共找出2,000多处点,然后把这2,000多处渠总成一个excel,按照业务场景进行归并。然后再按照业务场景同购物车内的log4j的正确输出同理。找到每一条日志输出中我们到底要什么字段,那么在代码里就打印那些个字段,不允许有一整个大对象放在log4j里输出。
于是大部队开始跟随着平时的叠代。。。比如说这次叠代动到了10个微服务,这10个微服务里的log4j输出就顺带着随手“撸干净”了。
差不多叠代了2个版本-2个半月彻底改净。
得到的效果
仅仅把这些无用的log4j取掉,整体系统性能平均提高了23%。瞠目结舌的效应。
长期根本上杜绝
经历了这个过程,我们把这个血淋淋的教训要深刻进我们团队的骨髓和灵魂深处,让它变成一种整个团队的基因,以便于传承。
因此,我们制定了如下这样的规范条文,开发规范我们把它设为一道“雷线”、一道“红线”,谁敢再碰那么“炸谁”。
在大家一致同意、执行规范的过程中,团队中人来人往也是正常的。。。这之间也有极个别人去试图触碰这条“雷线”,因此在这个过程中我们也真“炸飞”了那么几个“勇士”。
我们来看log4j使用规范,它分成这么几个部分:
- 如何规范使用(包括了log4j史诗漏洞);
- 统一申明命名;
- 统一了日志产生的格式、回滚策略、统一为log4j2.xml;
- 7条强制规范(不得触碰的“雷线”);
以上第4部分就是我要为大家展示的核心,因为前3点网上多多少少只要花点小功夫都可以收集完整,而第4部分是网上绝对不会提的,这也是我们用血的教训换来的成果。它具有极高的实用价值。
- 不得使用System.out.println来输出任何类型日志,否则会被视为严重代码问题,第3次违犯会被扣绩效。
- 不得循环内输出大量日志,如:logger.info(obj),否则会被视为严重代码问题,第3次违犯会被扣绩效。
- 不得在AOP内使用log4j输出大对象,否则会被视为严重代码问题,第3次违犯会被扣绩效。
- 不得使用JsonUtils.objectToJsonString(obj),否则会被视为严重代码问题,第3次违犯会被扣绩效。
- 抛错时必须使用logger.error(msg,e),一定要把这个exception的链路记录下来,这是强制的。
- 如果有一些代码中有throw,但是如果在throw的“上层”没有logger.error(msg,e)去记,那么你在这条throw语句前也必须用logger.error(msg,e)去落盘。
- 如果抛错没有抛到日志,或者是把没有把catch(Exception e)中的这个e通过logger.error(msg,e)中的这个e去落盘将被视为严重代码不合格。
这个规范目前已经执行了2年半了,这个问题从此在我们团队内消失,无论是团队的老人还是新人再也没有发生过。而这个教训每每提起每个人都还记忆犹新。
这就是国内零售业务场景所特有的一些梗。
零售业务场景为什么难做以及零售业务场景为什么充斥着一些高性能相关的技术问题呢
这是因为零售业务由其是在国内的零售业务,它所面临的客流以及因为客流而产生的数据量和国外的一些ERP有着本质的不同。
我们都知道一些国际知名甚至Gartner排名第一象限的产品在国内都无法支持甚至中小型的业务流量的主要原因就在于一个零售型企业,无论它是生鲜、还是商超百货、是CVS-小店还是Hyper-大超甚至是会员店,我们看看在国内都是怎么个开法怎么个玩法以及有哪些不一样的点呢?
店一开就开个3位数,6,000家,7,000家也是很正常的,国内外都有这种规模的店。
像一些国外著名的如:711、奥乐齐、比宜德、家乐福、甚至国内一些大的商超如:永辉、苏宁都是动辙6,000、7,000、上万家店一开的。但是在国外就没有出现过什么超过每秒3位数的并发场景,这是因为:
- 国内的客户基数放在那边的;
- 国内的消费频次放在那边的;
- 国外地广人稀、消费习惯还是“咣当、咣当”的收银机这种线下体验就算店多也并不存在海量并发场景;
- 国外购物习惯还是以一周一买、仓储式为主(欧美)。而东亚日本、HK一带讲究的是“到店体验”因此也无大规模的并发场景;
于是任何零售企业放在国内,我们看看它在数字上会发生什么变化吧:
- 会员数至少是7位数,300万、500万会员的零售企业在国内只能算中小型企业,这点会员量诚实的说在零售行当工作的人都知道,这点会员量差不多只够一个企业可以活着吧,彼彼皆是百万级别会员的店。一般如一些大厂都是上亿会员、几千万会员的。像笔者之前供职的家乐福,也是4,000万会员起板;
- 单店SKU数,CVS-小店如全家小店这种单店SKU数不大的,但是它的每个SKU很“精”一般在300-500个SKU,平均CVS一般在2,000-3,000 SKU,一个Hyper-大店在8,000平方米或者二层Hyper那种具有2万平方米的SKU含量都在10-20万级别;
- 我们同一个品牌都是讲究全渠道的,全渠道即包括至少美团、饿百、天猫、京动到家、线下门店、小程序、APP,达7个渠道上同时售卖;
然后我们取平均数,按照这样的公式来看我们在国内零售企业会发生的数据量,套用基本公式:活跃客户(经常回购)*SKU*门店*渠道*促销活动类型,这么一个迪卡尔积就是我们构成一个零售企业最最基本的单天数据量。
于是我们用1,000万中的25%活跃客户即250万*100家门店*7个渠道*6个促销活动(指定单品、全品、by渠道促销/全渠道促销、满减、无门槛、组合促销-这6个最常用)=多少数据量?11位数的数据量在参于运算。
碰到高峰把这活跃客户从25%变成50%,你就多乘了250万!这还只是我说的一个零售国内企业的最最基本数据元素的构成,我还没有算上积分、会员活动、以及各种组合玩法和新媒体玩法。
11位数,我们还要算上一个国内零售具有的特色,即:越是节假日生意越火爆和各种如:双11啦、618啦、520啦。。。等等等。。。另外这还只是一家小型零售企业的规模,如果是中到大型你要把会员数往亿去算、把店数往千去算。
一切纸面、书面、理论、网上您可以看到的设计模式、Sample如果在开发和设计之初并没有按照这样的数据量去做设计,那么在上生产后一开始或者因为此时你的DB里是从0条记录开始记录的、一开始或许你只有3家门店10家门店、一开始你可能只有两根销售渠道,那么一切看似功能完好并无问题。
而当时间一累计,往往根据国内零售的规律一个店如果的确做的不错它会在半年内上升一个“坡度”。比如说笔者从每天500单到3,000单再到万单其实本单位只用了一年多时间即实现了。
此时如果再回过头来看原先这个没有基于真正国内零售style设计的平台和架构,此时一切所谓的封装、模式、设计、模型都将会变形、扭曲,而此时就是:业务天天说IT供不上炮弹、IT-007还得不到好甚至全军覆灭的终极原因。
而这样的问题在本人先后经历的两座屎山上都全套来了一遍,好在我们在一开始就已经有了这方面的知识储备和意识以及得益于本人的领导对我的全力支持,我们才可以在短时间内把这么多问题全部改掉使之在短时间内变成了一座金山。
后面的篇章里我还将持续的为大家介绍我们还遇到了哪些问题,一切其实都围绕着我在本系列中的第五篇提到的这个:五纵三横式企业架构设计来讲。
好了,到此我们结束今还天的篇章。
Recommend
-
41
Log4j 介绍过了,SLF4J 介绍过了,Logback 也介绍过了,你以为日志系列的文章就到此终结了? 不不不,我告诉你,还有一个 Log4j 2,顾名思义,它就是 Log4j 的升级版,就好像手机里面的 Pro 版。我作为一个写文章方面的工具人,或者叫打工人,怎...
-
6
从问题的表象来看问题是怎么发生的 我们的系统大约在上线后2个月内,我们发觉我们的前端小程序即TO C端的商品目录这一块,经常会有用户在点一下“分类”进入后在显示相应的分类项时右边的具体商品列表会时不时卡一下,卡个大概1秒-2秒左右。它还经常发生。
-
7
上文我们讲述了HTTP乱用、不规范引起的血灾。本文继续讲的是“血光之灾”的内容。好像前两篇怎么都这么“重口味”? 这是因为我要用两篇同样的同内容,它们都属于:涉及到的技术问题相当的简单,但在百人开发团队中也是最容易失控的并结合着真实案例,让大家体会...
-
10
高性能零售IT系统的建设05-从0打造一个每秒万级并发的互联网交易系统的技术全架构 ...
-
5
系统监控的重要性不容小觑 前面我以两个“重口味”的例子给大家看到了这么一件事: 这是很基础的问题,属于1+1=2的问题;可是在一个百万行代码的系统中、达百人团队协同开发时它必然会发生,不要指望这种简单问题的发生机率为0,一定...
-
3
美团高性能终端实时日志系统建设实践2022年11月03日 作者: 洪坤 徐博 陈成 少星
-
5
高性能零售IT系统的建设07-通过一次重大危机感受Redis从使用到失智到理性的治理 ...
-
9
高性能零售IT系统的建设08-9年来在互联网零售O2O行业抗黑产、薅羊毛实战记录及打法 ...
-
7
高性能零售IT系统的建设06-当应对大量HTTP请求时兼顾性能、处理速度的架构设计 ...
-
5
高性能零售IT系统的建设09-Spring Boot2.4.2+Spring Cloud+Nacos+Feign+Hystrix的生产级应用实例 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK