

高性能零售IT系统的建设09-Spring Boot2.4.2+Spring Cloud+Nacos+Feign+Hystrix的生产...
source link: https://blog.csdn.net/lifetragedy/article/details/128770215
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

高性能零售IT系统的建设09-Spring Boot2.4.2+Spring Cloud+Nacos+Feign+Hystrix的生产级应用实例
通过前面8篇我们已经感受到了我接手时这个项目有多“烂”,当然喽如果只是一味的承认它的烂这不是积极乐观主义。
我在接触管理早期听过一次四大厂的报告,报告中说到:从来没有屎一样的团队只有屎一样的“带队”。
这也符合我们一直接受的正能量教育的理念。
一支IT研发团队有没有战斗力不是只靠威吓、罚、强制可以带得出来,而是需要赋于它“灵魂”。灵魂就是“团结一切可以团结的力量、身先士卒、带头攻关、真正把心放在团队上、把团队当成你的身体的一部分器官和有机体去呵护它”,它才能“健康”成长。
所以,我们的系统在刚上线前我就已经发现了这个系统内含微服务。含了微服务是一件好事,可是这个微服务形同虚设,等于没有。当时手上百废待兴、事情一堆,满足业务功能、强化团队战斗力占了我工作比重的90%,要把一支“培训班”水平的团队在短时间内进行2级跳跨越到研发水平,这对我的挑战相当的大。
但这个问题我是意识到会在不久的将来集中爆发的,所以我做了不少前期准备。但是。。。。。。它还是比我料想的早了1周(我料想是在2021年11月左右爆发,结果它是在2021年10月底爆发的)爆了一个大问题出现,我们来看。
早期系统中的微服务形同虚设
早期系统中的微服务使用的是spring cloud,每一个spring boot都打成了K8S,是一个独立的服务。再怎么K8S,它底层是spring boot、是embedded tomcat,没错吧。而。。。这个tomcat本身带有一个default timeout,是20秒,但。。。上线前都没设置,于是web容器的默认超时就都变成了20秒了。
又,每一个微服务问的访问也没设timeout,而早期的spring cloud的timeout如果你没设同时在spring cloud的自动装配yaml配置文件里也没设置timeout相关的阀值,它取的是本身“容器”的timeout即embedded tomcat 8.5.x的timeout值即20秒。

好,这乐子大了。我们来看一个经典的微服务场景,“雪崩”。
当,一次前端并发在接爱3,000不到一点时,在以下这个图里的优惠券业务这个k8s容器出现了问题,于是所有的“打到”它身上的流量卡住了,每一条卡20秒。前端的3,000到了某个微服务身上有时不止3,000的量,这是因为因为一些中小型企业没有把微服务在“纵向”上再切一刀的“额外硬件成本”所以会导致前后端只要有相关的引用都会把微服务打到某一个组件上。微服务、微服务,再微,它的底层是什么?是HTTP请求呀!
于是乎,当上万的http request打到了优惠券服务上后它开始积压、然后耗尽整个服务内linux的max tcp open数,积压了10几万的tcp导致了:
- 本身这个服务已经没响应了;
- 级联雪崩开始,卡到上一层“加购物车”。购物车再积压10几万tcp,再没响应;
- 购物车服务继续向上层级联雪崩,崩到了商品分类页,然后商品分类页服务中某一些如:推荐商品、首页显示“本周优选”这些小服务都是通过分类页服务取的,于是首页卡死、白屏;
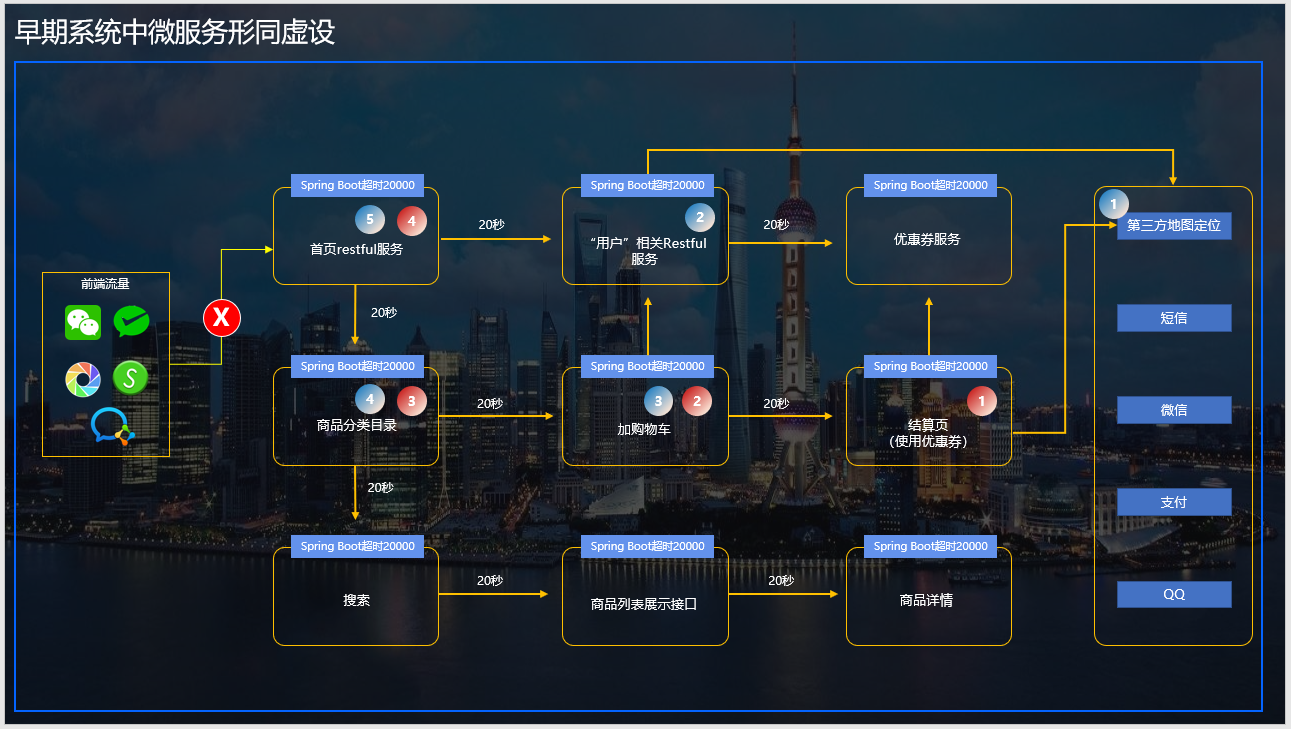
所谓祸不单行,同时我们的第三方渠道里的“地图定位”也因为本身第三方自身的原因维护发生了卡顿。我们零售O2O行当在结算页时经常会有一个“商品预计XXX分钟内送到”这个功能,这个功能是当订单状态变成了“骑手已取货”时,系统把你下完单开始派送的门店的经纬度和你收货地址的经纬度进行匹配后返回的一个预计送达时间的restful api接口。这条接口在10分钟内(零售O2O行当经常碰到第三方外联系统错误的,这很正常)发生了抖动而。。。因为我们调用也没设timeout,于是也是卡20秒,再倒过来级联雪崩,这一条路经过以下路径:
- 第三方地图定位
- “用户”微服务模块
哈哈哈哈,首页白屏、业务哀嚎、老板脸抽筋!
上面这两条路,都是级联雪崩的核心路径。而且前端用户因为商城优惠活动力度大那么它的并发是源源不断的“汹涌”进系统的。
因此,当我们临时重启了购物车发觉都没有用,因为你重启一个模块时流量暂时都是“白屏”,但一旦服务好了,在15-30分钟内由于客户“热情”不减,流量依旧还是往系统里“涌入”,然后再打爆、打爆后再级联。然后我们又发觉了第三方的地图定位系统有问题再去重启“我的”这个微服务,重启完后没1分钟系统再卡、再白屏。
喏,看到了没?90%左右业内的零售IT就是在这种活动中如此的彼于奔命,最终被业务笑话成了“IT要做的事就是重启”。
从微服务的角度想一下级联雪崩时的问题
没错,微服务就是用来对付级联雪崩的。
微服务的核心要素是什么:
- 服务升级、降级
- 服务“回放”
百度上只有1、2、3点,我加了4、5两点是因为百度解释微服务是从技术角度而实际的业务场景容不得我们一切切,下文会详细展开为什么会有4、5两点。
那么我们来看级联雪崩时的问题:
- 服务重启无用-因为你就算定位到了一个服务,你重启它,然后此时外部流量继续打向它,你重启后最最多的好处就像我们的情况一样,整个系统好了1分钟后再卡,就算你全站重启效果依旧一样,因为互联网真实用户的并发流量它相当于一辆“狂飙”中的高铁,它从狂飙到刹车是有一个“惯性”的;
- 明明出问题的模块已经恢复了,为什么和它依赖的其它服务模块也崩了呢?这正是级联雪崩的原理,级联雪崩不是一路向下而是倒过来:自底向上崩的,这有点像“递归”,CALL我的节点在我出问题时都会被“牵联”到,因此它的影响是一大片,崩、崩、崩。。。game over;
那么此时我们因该怎么办?碰到这种问题不是等死吗?而且就像我上文所述,一些第三方外部服务出现抖动、甚至是维护不通知我们零售商户是经常性的,这样一来不是导致了我们每周可能都得来这么一次,那谁受得了呢?
那么我们想到了微服务中的熔断,嗯。。。还有一个限流,熔断和限流是不错!可是。。。你有没有想过一个问题?
熔断后的“业务兜底方案”
限了后、断了后怎么办?用户之前访问是白屏,现在访问时过几秒来一个“网络错误”、“努力加载中请稍侯”,然后此时用户不断的看到“亲,请稍侯”、“亲,努力加载中哦”。。。亲努力访问了10次都是这种。。。于是乎,亲发怒了,见你的鬼哦,88撒油那拉奥斯维达幸了。于是,宝贵的客户就这样损失掉了、企业IT的口碑也因此而完蛋了。
这就是为什么我加入了第4点和第5点。
实际举例来说业务兜底的设计
我们拿实际例子来说事,拿第三方地图定位系统出问题了,我就断开,设置了一个超时4秒,4秒内不响应我就断开,断开后老显示“骑手派送中”就是不显示“预计何时送到”。于是用户等啊等、等啊等,状态显示的是:派送中,过了一小时还是派送中,于是用户点了取消。突然此时门铃响了,快递给你送到了哦 。
这个乌龙还不算大,最大的乌龙是这么一个梗,我给大家讲一下,估计你们看了会笑出“杀猪叫”声来。
说用户等啊等,等了一小时状态还是派送中,用户点了取消,点完取消后又马上下了一单。此时门铃响了,“叮咚,你的订单送到了”,你一脸懵X的接收了订单后,过了1小时。。。“叮咚,你的订单送到了”-这是你取消后又下的一单到了。于是你打开手机APP商城看到上一笔订单被驳回了“撤消申请”,钱也没退因为订单已经送到你家了,于是你本来这些东西准备好一顿吃掉的,这下来了两顿,就算留了一顿放在晚上吃,一是同一天吃重复的东西两次?再者就是:有些生鲜类东西不能放置太久。
这种乐子我相信大伙经常碰到过。
所以熔断了、限流了,你得有一个“补偿机制”或者我们也称为“业务兜底”。
拿这个显示派送时间来说,因为第三方地图出问题了,于是你来一个4秒超时断开,断开后马上取一个系统中设置的默认值如:90分钟,然后把这个90分钟直接return回前端显示好了。这就叫断开(熔断)后的业务兜底。
再拿优惠券来说,这个断了可是没得优惠了?对啊,这种下单时使用“可用优惠券”而。。。此时优惠券服务临时出了问题,那。。。此时你提示用户“可以稍侯下单”同时也有很大一部分用户手上并没有可用的优惠券但是你不能因为一个优惠券服务临时出个问题就影响到其它用户(可能占70%比例)的正常浏览和下单动作呀?是不是?那么此时,你也可以在服务间设置一个超时,超时后断开,一旦断开你提示用户:可以稍侯下单或者可以用线下、座席运营的手段手工补偿用户一张优惠券而不应该去影响其它不显示优惠券、不使用优惠券的普通用户的下单行为,这都比你整个系统“卡、白屏”要好,是吧?
再来说一下限流回放
在这个系统之前的篇章我们说过限流,限完后也是有一个“安抚”页面对吧。这对用户其实也是不太友好的。
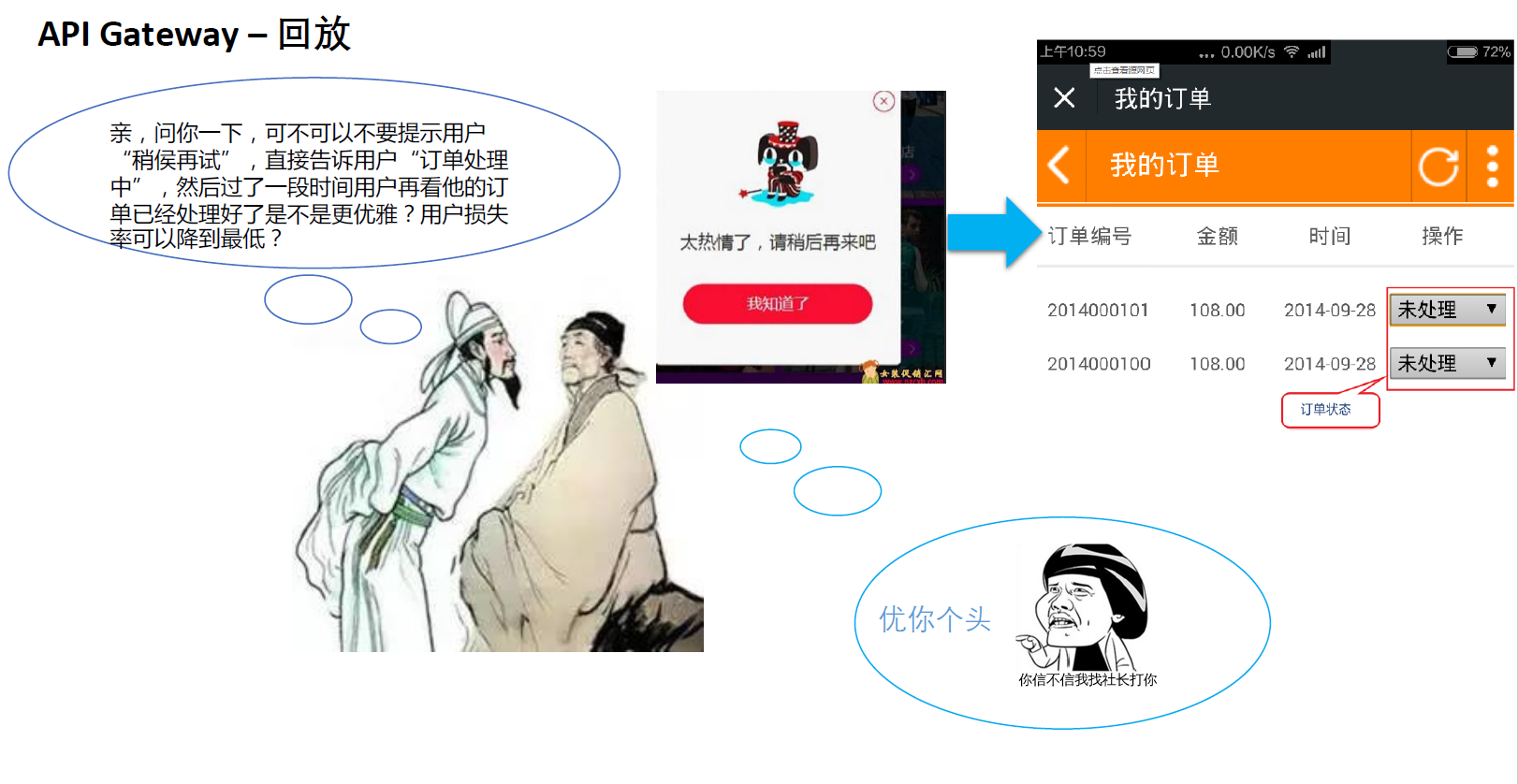
做过支付对接工作的就知道,很多支付第三方都有限流动作,但是人家有一个叫“支付结果回调通知”的功能。
相当于我们让用户只管把结果“成功的写入”我们的系统,对用户来说限流变得“透明”。然后用户的请求落到系统中后呢?我们在系统内部进行一个“削峰”,慢慢消化用户的请求,一旦消化了后再“主动”通知用户。比如下面第二种“回放”的做法,用户只管下单,下完后系统会通知用户“你的订单处理完了”。
这种做法虽然也不能和下完单就出结果相媲美,但是它在“体验友好”和“系统保护”二者间却可以取得完美的“平衡”。
从代码角度来看微服务
上面说了一些理念性的东西,下面我们要进入核心,来看看在我接手的这个640多万行代码的“屎山”里,我们是如何经过前期有针对性的准备并且以小步快跑的方式并且在不影响业务功能叠代的情况下如何把系统改成了真正的微服务的吧。
还是从微服务的核心着手,上手把所有的默认超时统统给我改掉。
微服务中的超时设多少才合理
有说2秒、有说4秒、有说1秒,凭什么呢?拍脑袋吗?
拿数据说事,通过监控我们可以发觉一个系统内部间的服务调用,>1s的 read timeout以及>1s的http connection timeout已经是件很夸张的事了。
各位!同属一个局域网,以云+SSD高速盘为例,你相当于访问你的localhost:9080时你连接一次都要>1s,或者说连接上了取一次response需要>1s,你这是什么接口哈?
你说我一个response里有6万条数据,各位。。。你自己看看你自己说的这句话,一个微服务调用返回一个>6万条json数据的response,这个服务本身就已经需要重构了。
你以为1s太夸张了、太理想化了、太乌托邦了。嘿嘿嘿,我告诉你2020年拼多多、抖音、JD、美团、今日头条的数据。
内部微服务从大方向上被它们分为二类,一类被称为:即时交易含transaction类业务,不得>1s。第二类被称为:即时非交易不含transaction类业务,不得>500毫秒。
各位这么想一下,你的业务系统并发量大这是一件好事啊,说明你的用户量大,日活20W的话你一天都有上千万的成交额,谁不喜欢。那么我们把万级一秒并发这个指标加到你的系统头上,请问在一秒钟内一个API被点击一万次的情况下,你觉得一次get请求<=1s这个要求过份吗?
不过份,我告诉大家,1s超时就断开这个阀值对于开发团队来说还太宽裕了!
就拿我们的系统现在的微服务核心指标就是“本着不相信一切对接方甚至自己几十个模块间也彼此不相信”的原则下,按照:TO C端交易类单接口不得>1s,TO C端非交易类如:getUserById请求不得>500ms,TO B端(后台管理平台内的操作)全部限制在不得>3s来进行微服务的超时设置。
有了数据和理论依据后,我们开始构建我们的微服务底层骨架了。
使用spring cloud2.0构建系统微服务底层
我接手项目后对spring boot做过一次整体升级,新功能几乎全用spring boot2.4.2,大家请一定记得这个版本号哦。
这篇文章中的代码适用于>spring boot2.4<spring boot 3。
这是因为spring boot的版本和spring cloud2.0以及nacos、hystrix熔断、feignclient的版本是完全匹配的。
你要网上不加筛选的乱抄,其结果就是:你的项目要么就是工程启动到一半什么错也不抛然后突然的莫明奇妙的终止,要么就是在工程启动时抛出一堆的exception。
所以我们来看我们的微服务的底层“骨架”。
基于spring 2.4.2的spring cloud2.0的依赖

先来看我们使用的各组件依赖的版本号,这个版本号是我们生产上面对万级并发使用的,它已经历时一年半经历了无数次“大促”的考验了。
接着我们来看maven中的配置
在整个商城的parent pom.xml文件的结构
商城内某一个微服务的provider端
在provider端即微服务提供方,我们为了把一个spring cloud2.0的微服务发布注册进nacos在pom.xml文件中必须要含有以下几行
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">maven配置中的核心要点解读
- 去掉项目自带的slf4j,改用被发布的无jndi漏洞的log4j版本号;
- 一些spring boot的本身或者第三方组件如:mybatis、redis等都会带进自身所依赖的一些logback、log4j、slf4j,最终一个项目集成下来,slf4j版本就有3、4个,搞得项目要么不能启动、要么启动起来后不输出log,因此在parent里使用dependencies manager把这些包都统统排干净了;
- spring boot的版本、spring cloud的版本、spring cloud alibaba、nacos-discovery四者必须完全匹配,因此我才说我这个配置是最稳定的版本,它经历了1年多的生产环境运行了,是我们通过极其无聊、痛苦的项目结构内版本不断的匹配试验才找到的这么一个组合,当然这几个版本的组合也有“明确的细索可循”并不是不加思索的一个一个去手工动,大家可以上spring cloud alibaba的git,在git首页内可以找到这4样东西的版本匹配;
- 最坑的是这个nacos discovery client,它的<version>必须使用我parent的pom中给出的版本-2.2.5.RELEASE,而不能依赖于spring-cloud-alibaba-dependencies自带的;
- 笔者使用的nacos版本为:2.0.2;

provider端的spring boot自动装配用yaml配置,我把yaml文件放在了nacos里,我们的整体商城用的是nacos来作为我们的配置中心的。
在你的eclipse项目内必须含有一个bootstrap.xml文件
它的内容如下:
注意:此处的spring:application:name必须和nacos配置中心里的spring:application:name中完全一致。同时,此处还指定了:
- nacos服务发现的地址
- shared-configs[0]-指定了我们的项目含有一个common.yaml,在common.yaml里定义的是全局redis、db连接,如果对于初学者来说如果你做练习时只有一个yaml配置并不需要include其它全局配置,那么你可以把:从shared-configs[0]到下面的data-id:这两行删了;
- spring:cloud:nacos:config:group-yaml文件所在的group;
- spring:cloud:nacos:config:namespace-yaml文件所在的namespace;
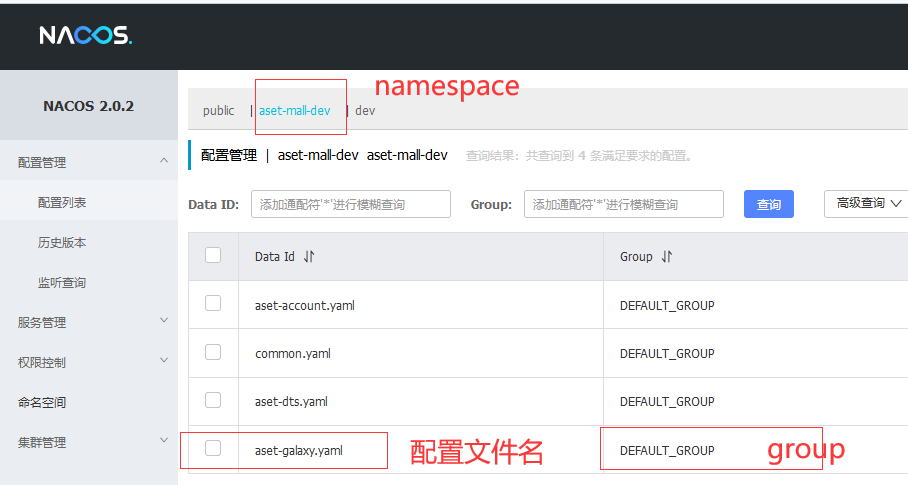
- 配置文件的后缀名为“.yaml";
默认,这个.yaml文件的前缀是以你的spring:application:name+.yaml文件放在相应的namespace->DEFAULT GROUP下的,如下截图所示:
商城内某一个微服务的provider端的spring boot main写法
你必须要使用@EnableTransactionManagement,这样这个服务一旦启动,它就会自动注册进nacos成为一个微服务了。
provider端提供出来的微服务
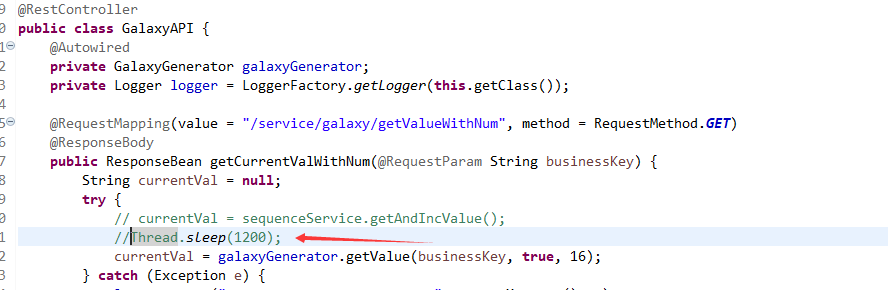
这是一个标准的spring boot controller,只是我们在getCurrentValueWithNum(没错这是一个分布式序列号产生器,随着我的商城的开源我会把这一整套重新整理过的框架的后端、前端-Android开发的商城都开源给大家的-mkyuan.com是我的另一个私人实名永久域名)里故意来了一个Thread.sleep(1200),让这个controller中的get方法被访问时故意耗时1.2秒,以便于后面微服务内演示:熔断以及熔断后的业务兜底。
现在,我们来看把这个工程启动起来。
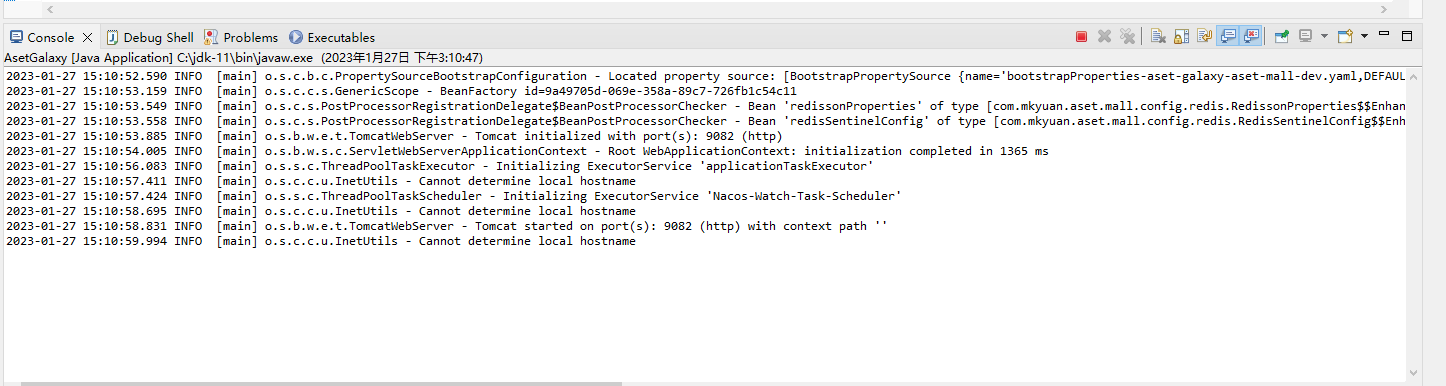
工程成功启动后我们看nacos里面

可以看到这个微服务已经被成功的发布和注册进nacos了。
商城内某一个微服务的consumer端
consumer端的pom.xml文件
先来看pom.xml文件,它和provider端共用一个parent pom.xml文件,因此版本全部保持一致,在子pom.xml文件内由于已经在parent的pom.xml文件的dependencies manager内指定了,因此在子pom.xml文件内不必再指定,要指定也是有一些特殊需求。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">maven配置中的核心要点解读
敲默板了,这块相当重要。
因为以spring boot2的版本进化过程中特别是spring cloud的consumer端内要用到的这几样组件:
- spring cloud
- spring cloud alibaba
- nacos discovery client
- hystrix
- feign
这几者间有着严格的版本依赖,因此从时代上划成了5代:
- 第一代,以spring boot2.0~spring boot 2.1,这一代里这几个组件彼此间有间对应关系;
- 第二代,以spring boot2.1~spring boot 2.2,这一代里这几个组件彼此间有间对应关系;
- 第三代,以spring boot2.2~spring boot 2.3.8,这一代里这几个组件彼此间有间对应关系;
- 第四代,以spring boot2.4~spring boot 2.5,这一代里这几个组件彼此间有间对应关系;
- 第五代,以spring boot2.5~spring boot 3,这一代里这几个组件彼此间有间对应关系;
如果,版本间有着严格的对应关系这倒也算了,大不了版本不一致的情况下我们可以上git的spring cloud alibaba首页里查看几个组件的版本对应关系。
关键最让人坑的是从spring boot2.4.2及使用spring cloud 2022.0后的版本后取消了hystrix,因此不少网上的解决方案说是可以用alibaba的sentinel去做“熔断”,笔者在使用过11个微服务框架的经验里告诉大家:至于用什么组件是木有任何毛线关系的,关键还在于你是否精于这些组件,用最常用的、你最熟悉的达到同样的目的,那么它就是好的架构。这就是架构的精髓:本无架构、架构是迷踪拳、架构是独孤九剑。。。
扯远了,扯回来。
在spring cloud 2022.0后已经去掉了ribbon改用了spring-cloud-loadbalancer,也没有hystrix了,如果你使用的是spring cloud 2022.0版以后的依赖,那么你的项目里会自动带入hystrix的的旧版本:spring cloud hystrix 1.5.4。。。崩溃中。因此我们才在我们的pom.xml文件中exclude掉了ribbon和手工指定了netflix-hystrix版本的道理。

否则,它会让你的项目内的“熔断”功能死活不启作用。因此,才要在此处使用netflix-hystrix并在pom.xml文件中手工指定它的最新版本即:2.2.9.RELEASE。
同时我们不使用feign client的自带HttpClient功能而改用了okhttp3组件。
consumer的spring boot main的启动类中的写法
注意:
- @EnableFeignClients,且置于@SpringBootApplication下,这是因为这个annotation内带扫描含有@FeignClient注解的微服务客户端,而它于spring boot自带的@ComponentScan有“优先级”上的冲突并导致工程启动时随机的报“找不到相关的feign client类依赖“。因此我们会把@EnableFeignClients置于@ComponentScan的上部;
- 必须要有@EnableHystrix(老版本用的是@EnableCircuitBreaker写法)
- spring boot2.4.2工程的main里已经不需要再写@EnableDiscoveryClient这个annotation了
consumer端的feign client以及hystrix断路器的.yaml配置
同样,它需要集成一个bootstrap.xml文件,而把.yaml文件放置于nacos里。


先来看.yaml文件
超级需要注意的地方来了:
- 在spring boot2.4以前由于spring cloud版本还是2021,因此我们使用的是:feign:hystrix:enabled,而在spring boot2.4~2.5因为spring cloud版本变成了2022.0后的版了因此它的写法为:feign:circuitbreaker:enabled了;
- 在项目里你的hystrix的保护时间:sleepWindowInMilliseconds的值,必须大于你的feign里的connect-timeout和read-timeout(实际生产上我们这两个值不是每一个模块都一样的,有一些根据我们的监控甚至有300或者500毫秒的);
- hystrix里的circuitBreaker:requestVolumeThreshold、circuitBreaker:errorThresholdPercentage以及circuitBreaker:sleepWindowInMilliseconds这三个值,我竟然在网上其它的博客以及超过90%的不同真实的项目架构里,从没有看到这3个值的使用。也正是因为大家都是看网上的博客而很多博客讲的是一个入门,然后copy不走样的复制了网上的配置,导致了都没有配这三个值。这三个值不配,你的微服务的熔断功能等于失效。这也是我接手的这个项目内的另一个大问题,即微服务等同于“无”一样。hystrix对于微服务的熔断从这么两个点进行考量:在最近10秒内失败了几次或者在最近10秒内的调用错误失败率超过一定百分比(errorThresholdPercentage)就触发熔断。熔断后我们想一下,此时这个被熔断的服不会一下子好起来,此时我们需要给这个服务一个“喘吸/恢复”的时间,这个时间就叫“保护时间”或者也被称之为“服务降级”时间,即:circuitBreaker:sleepWindowInMilliseconds,这个值不能一概而论,每个服务各有不同,或15分钟、或30分钟、或5分钟。这段保护时间内,流量不会被“打到”失败的服务上,而直接被hystrix拦截在http层直接return到调用断,以充分减少http request的“冲击”,同时在这段保护时间内我们会使用“业务兜底”方案以取得“用户体验”和系统稳定性间的平衡。所以这三个值如果不设,那么你的spring cloud等于没用,这也是为什么很多时候我在面试时问侯选人:为什么你要使用spring cloud?你使用到了什么功能?同时又是什么促使了你要使用spring cloud?如果没有回答到熔断防止级联雪崩并在熔断时采用了“业务兜底”方案,那么这些人统统都只是网上看点资料然后就来面试或者是为了用而用spring cloud的不动脑子的所谓项目经验;
再来看bootstrap.xml文件
这边一定要注意的点就是你的spring:application:name必须和你的nacos里的完全一致。
consumer端调用服务的核心代码
我们的consumer端叫aset-account 、provider端叫aset-galaxy。
因此我们要在aset-account内调用aset-galaxy中的:/service/galaxy/getValueWithNum
我们把所有的provider端的“残根”称为proxy,放于统一的package下。
AsetGalaxyProxy.java
AsetGalaxyFallBack.java
这个XXXFallBack类就是我们的微服务在遇到错误进行熔断时抛出HystrixRuntimeException的地方了。另外就是一定要记得这个类要加上@Component的注解,这个类相当于上述这个AsetGalaxyProxy Interface的Implementation。
因此它的实现很简单,核心是要“抛出这个Exception”。因为如果你在这边把Exception“吃”掉了,然后以logger.error作记录也是可以的。
可是这样操作的话,请问在一个生产级别复杂的环境下,你的熔断后都要做业务兜底的。业务兜底可以是前台(小程序、APP)和后台根据约定的一个code进行联动、也可以仅仅是前端显示“安抚”页面。不管采用什么办法吧,你总要有一个“当碰到熔断的code我们就进行业务兜底”这么一个对code的判断动作,对吧?
你不能一刀切的统一返回-1吧?因为如果都为-1返回,前端会显示“系统繁忙”,而此时如果你“封装过渡”的话也会导致所有的后台错误都被返回-1,然后你的熔断因此又失去了其本质的作用中最核心的-熔断后需要做业务兜底这一功效了。
因此,下面我们来看对这个proxy的调用代码,然后你就可以感受到微服务熔断以及熔断后的业务兜底的本质了。
UserAccountService.java
在看代码前我们先来看微服务的调用顺序(按照1、2、3)如下截图所示:
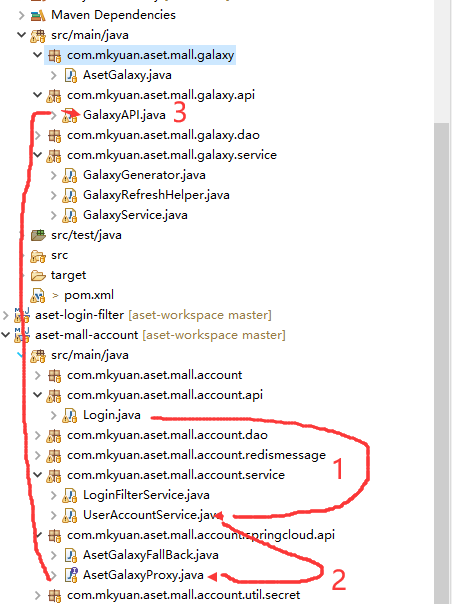
好,我们来看我们的这个service类中的含有微服务调用代码
看这个service类里的方法 ,调用微服务的地方如下所示:
asetGalaxyProxy.getValueWithNum("aset:mall:account:loginid_sequence").getData()如果这个地方出现了服务间的错误,它会抛出一个“HystrixRuntimeException”,catch住这个exception后,你可以把这个错误向上抛到controller层并最终返回出去。你也可以做服务兜底,如果要做服务兜底,我们这边的服务兜底方案为:
如果一个用户通过短信登录时,在生成了ut后还要为它生成一个拿分布式id产生的16位loginId,而当拿分布式id出错时,从业务上讲这个loginId只要随机和唯一即可因此我们可以在当拿分布式id出现了“熔断”后把ut(算法保证全局唯一)的值塞到loginId里,从代码上看这个业务兜底方案就是这样的:
spring boot2.4.2+spring cloud2022.0后版本+feign+hystrix+nacos的微服务运行效果
确保provider端和consumer端都运行起来
进入nacos查看我们的微服务

看,由于我们在provider端的controller一进入就休眠1.2s,因此配合着consumer端的feign的client端的connect-timeout和read-timeout超时为1s,所以通过consumer端的api进行访问连接到后端provider端共耗时了1.02秒,因此它超时了并返回了8001这个code。
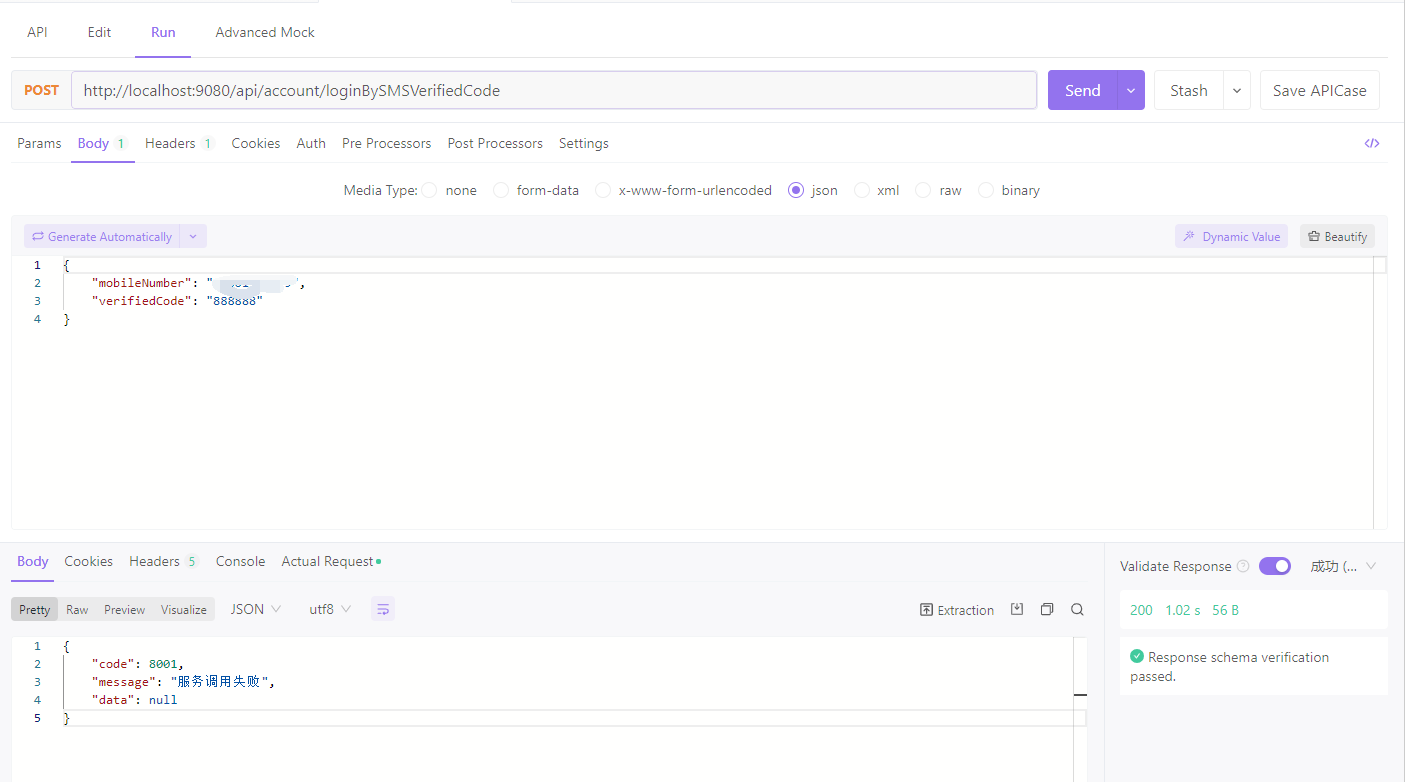
我们在刚才的AccountService的getSmsVerifiedCodeLogin方法返回的这个HystrixRuntimeException的code恰恰就是8001:

于是,我们接连访问5次,前5次都为1.02s
直到第6次,我们看到虽然返回内容一样,但是它的返回时间为8ms,对不对?
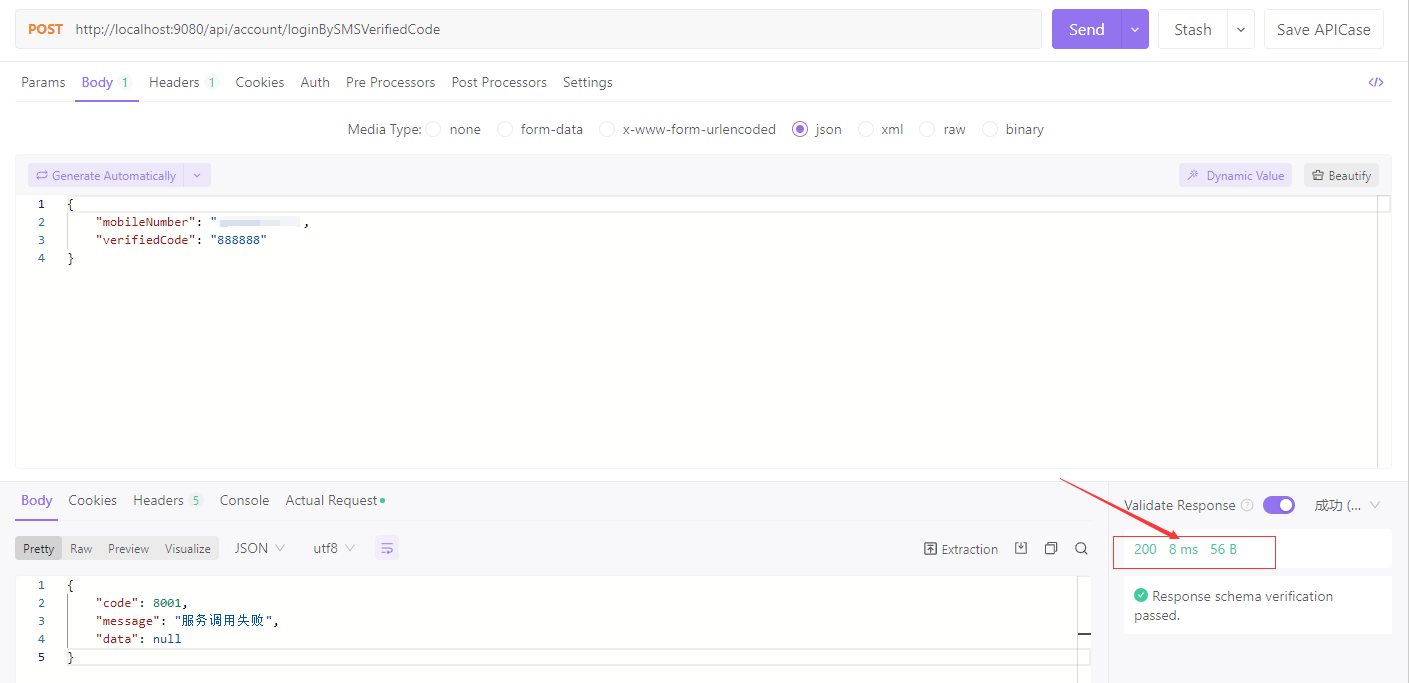
这是因为我们在consumer端设置的这个circuitBreaker:requestVolumeThreshold: 5这个值。然后从此开始往后的circuitBreaker:sleepWindowInMilliseconds: 300000毫秒内,这个服务被“保护”起来了(降级),再有请求这个http request打不到aset-galaxy(provider端)了,而是由aset-account(consumer端)的hystrix直接“拦截”下来了并返回了code 8001,所以此时它的返回速度超快。然后此时你需要等:300,000毫秒即5分钟,并且还要符合provider端恢复了,你才可以再次正常把http request路由到aset-galaxy(provider端)上。注意看下面的这个exception最下面一行,Caused by: java.lang.RuntimeException: Hystrix circuit short-circuited and is OPEN。这就说明,从第5次开始再往后就都是hystrix直接拦截了http request了。

因此,现在我们把provider端故意休眠1.2秒的语句给注释掉,重启provider端!
并且耐心等上个circuitBreaker:sleepWindowInMilliseconds: 300000毫秒!

5分钟后(不好意思我刚才去了次WC、抽了个烟、活动了一下脖子,时间有点超了)当后端的provider恢复了/好了,那么此时hystrix才会“放开”断路器允许http request继续向下请求。
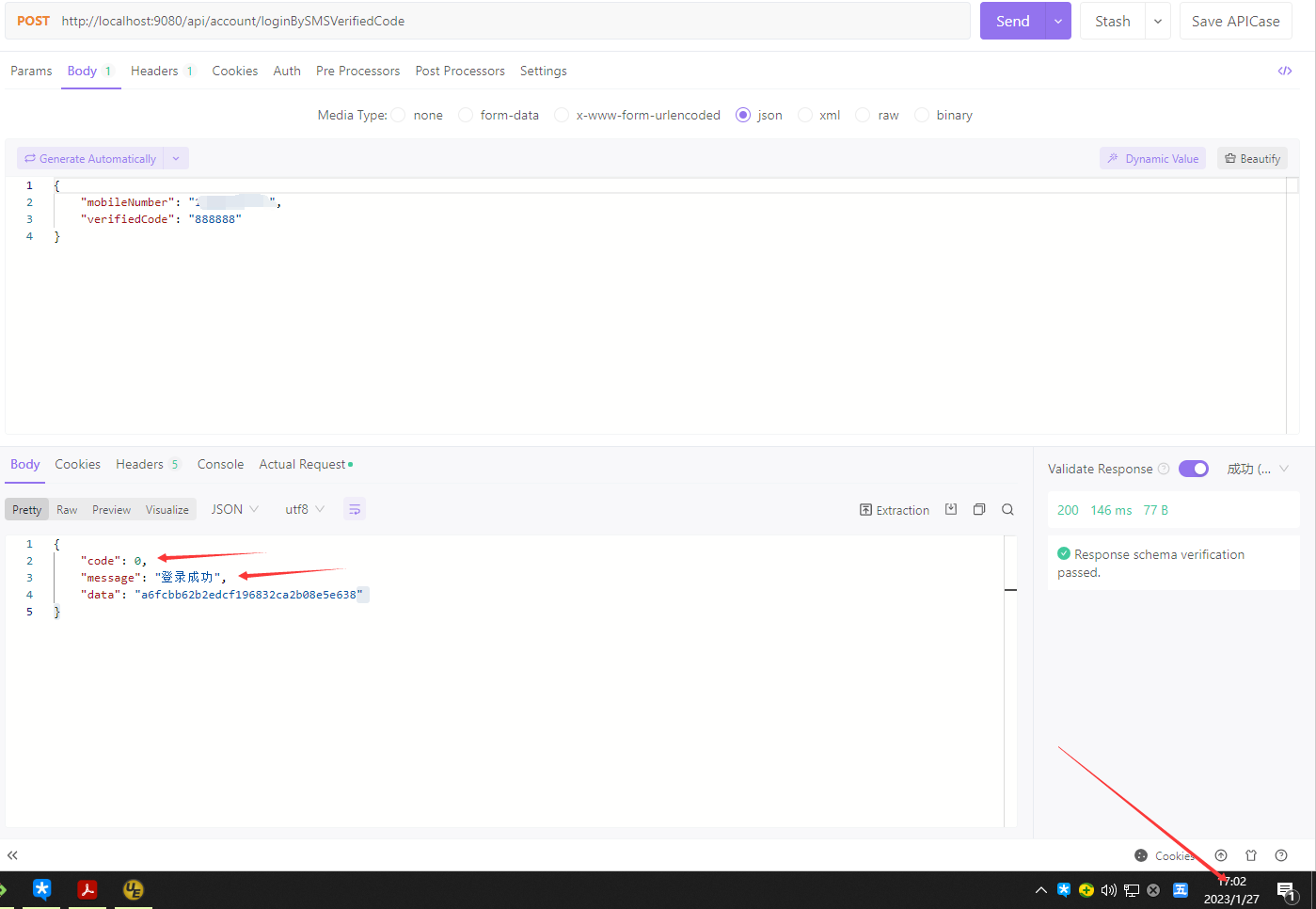
以上,就是我们的生产级微服务的核心骨架、架构思路以及可用代码。
文后的申明
- com.mkyuan是作者本人实名永久域名;
- com.mkyuan.aset.mall是本人重新梳理并使用了最新的技术的一套全新的中台,完成后会把它的前端APP、后台java统统开源并可以面向小微企业完成本人的“中台普惠”的心愿;
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK