

AIGC应用层的不变
source link: https://www.woshipm.com/ai/5821081.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
AIGC应用层的不变
这段时间,有关 AI 的信息如雪花般涌来,这个时候,我们要如何在快速变化的技术浪潮中把握不变,把握住关键点呢?在本篇文章里,作者便发表了他关于 AIGC 发展浪潮的看法,一起来看看作者的分析和解读。

世界在加速,那么抓住船头即可。
每天都有新的AI的paper发表、AI应用发布,难免让人陷入FOMO:遗漏了信息就错过了机会、我是不是会迟早被AI替代…
如何在瞬息万变的技术前沿中把握住不变,才是关键。
科普Q1:为什么是现在?
事实上AI研究员们一直在追求LLM这类通用模型,就像是物理学家在追求大一统模型一样。然而机器学习中执行能力是很重要的考量指标(比如CV中就是识别正确率),它决定了能不能落地到场景中使用。
而在GPT2时期,通用AI的执行能力比起垂类AI相差的太多,所以一直没有很好的反响。GPT3引入了人类作为标注员进行投票(RLHF机制)和加注大量数据后,通用AI的执行能力迅速逼近垂类AI。
数据越大越好(ScalingLaw)被证实、涌现被证实,接着ChatGPT以对话形式迅速获得了过亿用户。LLM掀起了巨浪。
科普Q2:这次的AI和之前有什么不同?
用户感知ChatGPT会和Siri、小爱有什么不同?比如你问Siri今天天气怎么样,它会先用知识图谱解读这段话,然后调用对应的天气AI接口后输出结果,所以Siri=多个垂类AI + 知识图谱缝合。
显而易见,Siri的上限取决于你的内置垂类AI数量。当意外场景出现时,它会说:“我不明白你的意思,让我们换个话题聊聊”。如果你想突破这个桎梏,你就需要训练更多的垂类AI,而每训练一个垂类的AI需要大量数据和成本。
而GPT是直接通过海量数据+文本挖空,去查找对应的文本,然后会得到很高的词频然后输出结果,以此达到优秀的语义分析能力。重点在于:没有预置场景值训练,也不需要知识图谱解读,GPT是真正意义上的通用AI,它的上限取决于你的指令(Prompt)。
一、范式转移
且不论技术上限,理想情况下这次的AI会朝着什么方向发展呢?看技术paper是很难看的到脉络的,事物在不断发展。
我觉得比较好的思路是看领航者Sam Altman怎么想。Sam写过一篇文章叫《万物摩尔定律》,其中畅想了AGI如何改造人类社会,其中的核心就是将人的成本从边际成本变成固定成本,固定成本意味着每18个月成本就会减半,最终将无处不在。
比如过往培养一个律师需要大量的学习进修和案件实操,但AGI可以将律师代码化,让原本只能服务少数人的律师能够被所有人调用,且不需要更多成本。
曾经发生的边际成本变固定成本:人们把实际数据(data)搬运到互联网上,过往你接收信息需要报纸,现在你只需要打开电脑或手机浏览即可,这个过程不需要额外的印刷成本。随即有公司提供了将数据(data)转化为可用信息(information)的服务,比如Google、Amazon等,这其中完成了一次商业的再分配。
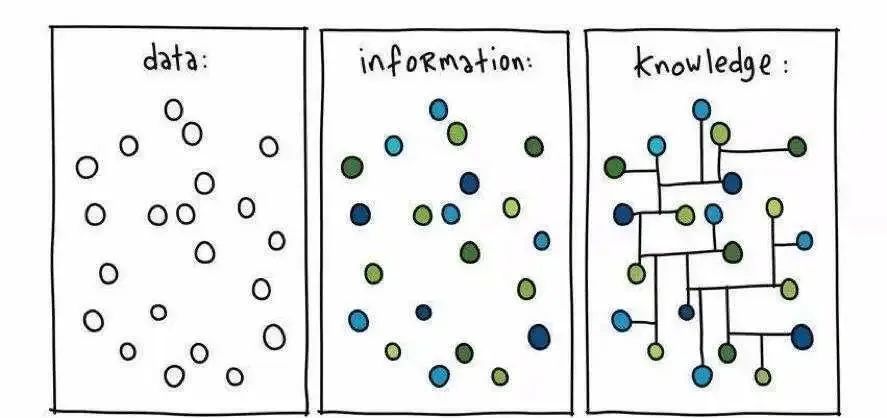
而这次的改变是:信息(information)→ 知识(knowledge)。
不同于垂类AI,LLM拥有组装所有信息的能力,也能输出各种人类能输出的结果。也就是说原本需要靠人来组织信息的需求,现在靠AI都有机会完成。
二、定义LLM:缸中之脑
Sam提到建立AGI的四大要素:
- 涌现(emergence)机器也能表现出类人的智能性。
- 自解释性(Affordance)视觉属性,暗示用户应当怎么使用。
- 代理(agency)当智能出现后,人们能将任务托管。
- 具身(embodiment)机器肉身与物理世界交互,完成任务。
可以看出,Sam的最终目标是为了让AGI替代人类完成任务,目前的进度是体现出了类人的智能性,LLM擅长以人类的角度组装信息,所以我们不妨大胆一点,先把LLM的终局当成“缸中之脑”。
① 这能够解释一些现象的必然性:
对话交互最先出现是必然:无论是文生图还是ChatGPT,人们想要感知一个可思考的大脑,最自然的方式就是对话,我们在现实中就是这么和其他人互动的。
② 除了对话,脑也能基于已有知识解读:
脑可以演算预测:对蛋白质结构进行推理。
脑可以识别信息中的意图:从用户的对话中发现用户的需求并找到对应业务分流(如Plugin),比如识别代码来猜测代码的目的,甚至是操作代码。
③ 还有代理(agency)上的尝试:
脑的反思和执行:AutoGPT、AgentGPT。
脑和脑之间的协同:“西部世界”小镇游戏。
至于是不是OpenAI官方下场尝试已经不重要了,它是必然会发生的尝试。以后可能还会出现更多“脑”相关组合的尝试…
简而言之,我们在思考LLM可以做什么的时候,不妨想想现在人都在做什么脑力工作,这些都是有可能被切片替换的,自然也会有新的产品机会。
三、LLM当前技术局限性
理想归理想,应用归应用。现在可以看看LLM技术的局限性了。以下是我收集到的一些技术上的局限性:
1. 无法内部对话(有部分可以通过step by step解决)
在微软的《人工通用智能的小火苗:与 GPT-4 共同完成的早期实验》(Sparks of Artificial General Intelligence: Early experiments with GPT-4)文章中提到:
模型具有生成正确答案所需的足够知识。但问题在于 GPT-4 输出生成的前向性质,下一个单词预测架构不允许模型进行「内部对话」。模型的输入是「多少个质数…」这个问题,期望的输出是最终答案,要求模型在(实质上)单个前馈架构的一次传递中得出答案,无法实现「for 循环」。
而人类不是这么处理的,当需要写下最终答案时,人类可能会使用草稿纸并检查数字。普通人很可能不能在没有计划的情况下写出如此简明的句子,而且很可能需要反复「倒退」(进行编辑)几次才能达到最终形式。
2. 脱离物性(很快会被解决,如SAM,GPT4)
GPT它基于现有的符号系统,符号秩序去计算。这会导致和“物”分裂开来,他看不到那个真正的“物”。它看不到那个未被符号化的实在界。悖论恰恰是这样的,在某个时刻纯粹的差异出现了,AI不能把握符号秩序内的冲突对抗性,或者因为视差看不见的那部分。
3. 出现幻觉
有人用「随机鹦鹉」来形容大模型没有理解能力、出现幻觉(hallucinations)等行为,诟病这些模型只会制造语法上合理的字串或语句,并没有做到真正的理解,甚至LeCun(AI之父之一)也说将大模型称为「随机鹦鹉」是在侮辱鹦鹉。
这里着重提一下Yann LeCun的看法
https://drive.google.com/file/d/1BU5bV3X5w65DwSMapKcsr0ZvrMRU_Nbi/view
- 自回归 LLM 可能很有用,尤其是对于写作和编码帮助
- 大模型通常会产生幻觉或产生并非基于事实信息的内容
- 大模型对物理世界的理解有限,这可以通过他们在某些谜题上的表现来观察得到
- 大模型的计划能力相当原始
- 大模型的工作记忆有限
- 大模型对每个生成的token执行固定数量的计算步骤,从而限制了它们更具动态性的潜力
- 大模型远非图灵完备,这意味着它们无法模拟通用计算机
- 自回归生成过程呈指数发散且难以控制
但我认为Lightory说的非常有道理:
人类实际上也只是在使用概念、而不考察概念。这种方式恰好佐证了 GPT 技术路线的有效性。GPT 是否真正理解知识、是否真正具备智能已经不重要。真正重要的是:LLM表现出理解知识和具备智能。
这里也引用推友廖海波(@realliaohaibo)的一段话:
有业界知名大佬公开认为:GPT只是概率模型,并不理解事物的底层本质,所以没什么卵用。我不太同意。
人脑神经元的层面上也不理解逻辑,但是组合起来对外表现就是可以逻辑推理。就好像晶体管看见自己表现的0/1,不知道自己在显示一个像素还是一个字母一样。这是一些事实,甚至不是一个观点。
尽管目前有诸多缺陷,但算不上致命,LLM当前依旧可以定义为“大脑”,只是略有残缺。
四、LLM落地-前期
History does not repeat itself, but it does often rhyme.
历史不会重复,但是会押韵。
很显然,我们能从局限性中感觉到,当前的AI和理想中的AI存在着一些距离。想要在人类和现实交互环节中嵌入更多AI,不断对齐(Alignment)是关键,AI与现实世界匹配越多,能做的就越多,人需要做的就越少。
我认为文生图是走在文生文的前面的,文生图的进化方向预示了LLM输出质量的可控性是短期内商业落地的重点:
- Mid journey → 在线大模型(GPT)
- StableDiffusion → 本地大模型(本地GPT模型)
- LoRA → 微调模型(system、fine tuning、embedding,类GPT的本地LoRA模型已经出现)
- ControlNet → 局部内容控制(肢体控制是文生图技术,文生文还未出现对应技术,会不会出现存疑)
但文生图是有标准的生产场景的(比如主美可以自训练Checkpoint、LoRA来获得想要的风格,ControlNet可以做AI模特等),文生文没有。
我认为短期文生文对齐是需要基于场景的,而且要做很多的用户意图识别,因为用户有时候描述不清楚自己的需求。
无论是产品上还是技术上的,这里的对齐,主要应该是对齐身份/职业/大脑功能模块,人在社会的角色工具性突出,对应的就是身份/职业。对齐人比较偏情感需求。
除了整块大脑之外,当然还有颗粒度更小的应用,比如做简单的泛化判定,实质上就是在把大脑进行工具性的切片。(下方是泛化判定的梗case)
User:
从现在开始,请你按照我的要求进行回复
①如果文本正在陈述观点,无论观点对错,你只需要回复我”典”
②如果文本中存在偏袒维护某一方的行为,你只需要回复我”孝”
③如果文本中情绪倾向偏急躁与消极,你只需要回复我”急”
④如果遇到了无法判断的文本,你只需要回复一个”6″。
你的输出只能包含一个字,不要包含其他的内容。
——————————————————————
GPT:明白,我会按照您的要求进行回复。
User:你说得对,但原神是米哈游自主研发的一款全新开放世界冒险游戏
GPT:典
User:原神怎么你了?
GPT:急
User:给世界一点小小的中国震撼
GPT:孝
接下来,如果我作为一个创业者想参与应用层,我应该怎么入场?
1. 挑什么业务
投资机构是商业的第一梯队,仅次于创业者,先看看他们的共识。
- 做有数据壁垒的业务:当前主流认知是AI 领域的用户量以及背后的行业/行为数据,是可以辅助模型生成更高质量的对话,是正向循环的。这样就会有先入壁垒。
- 做不会被取代的业务:OpenAI、大公司不会做的才是机会,这样可以确保不会被大流碾压和替代。
- 做可行性更高的业务:商业化和应用可控程度高度相关,能马上商业化的一般是对质量要求没那么高的环节。
2. “脑”如何工作
如果将LLM抽象为大脑,按照行为心理学划分的输入(刺激)和输出(反应),得到的关键点有2个:信源(prompt)、信息处理(transform)。
1)信源(Prompt)
从信息格式角度说:
除了主流的文字外,图像理解、音频、视频、3D都是能预想到的发展方向。
但还有另一部分细小的信源:GPS、陀螺仪、GUI交互(如点击、缩放)、温度、红外线、光照等等。这些微小信源以非常具体的数据格式存在,API的加成下我们还能获得到更多的信息。(比如GPS可以通过高德API获得到周围的饭馆,商超等)。
这些信源有的是用户主动生产,有些是经过用户允许后可以被动获取的。
从场景说:
需要去找很可能会产生信源的地方。
- 文字:bing搜索、咨询、文档写作等。
- 音频:会议、音乐播放、线下聊天等。
- 视频:日常拍摄、电影创作等。
- GPS、陀螺仪、GUI交互、温度、红外线、光照:旅游、购物等。
2)信息处理(Transform)
只要LLM拿到了这些信源,他们能做的转化就很多。由于视频就是由逐帧组成,以下都简称为图。
目前主流的是自然语言的转化。
- 文生图:SD/MJ等,可能需要复合工程优化prompt。
- 文生文:GPT组织复合信息,形成系统内容(如AudioPen等)。
- 文识图:通过Meta的SAM将图片、视频分解成若干元素。
其次是图/视频。
- 图转图:Image2Image、MJ等。
- 图生文:GPT4识别梗图,甚至是根据图片生成代码。
还有些硬核的:
比如设备支持的3D坐标、点阵等(通过自然语言控制3D人物肢体)…
还有些非常规语言的(虽然不属于应用层):
通过学习蛋白质序列“语法”,使用少量已知序列来生成全新的蛋白质序列开发新型药物。
3. 信息→知识的机会
正如上文所说,而这次的改变是:信息(information)→ 知识(knowledge)。以往互联网应用通过引入“UGC”来解决这些需求,但缺点是需要时间沉淀。随着LLM的出现,这些原本需要靠人来组织的需求,现在靠AI都有机会完成。
所以从产品角度很容易得出结论:
需求如果只到信息则机会不大。
google等传统应用就能搞定:比如查天气,目前的互联网应用基本都在解决信息检索的问题。
未被满足的需求,需要信息组织的有机会。
具体来说会马上有结构性变化的一些需求case:
- 咨询:我开车撞了人,需要赔多少钱(伤残程度、所在城市、民法典、裁判文书网信息组合)
- 购物建议:我要去夏威夷,需要购买什么用品(夏威夷温度、google上的大量信息组合)
- 旅游攻略:我需要制定攻略,我的起点是广州xx,终点是深圳xx(高德API、蚂蜂窝信息组合)
已经有需求,但是以往是靠堆人/堆成本的有机会。
鉴于现在LLM输出的质量并不稳定,在面向C端商业化时,对成品质量要求/可控性要求越低的,越容易低成本商业化(比如Hackathon中分镜、嫌犯画像等)。
B端涉及大量僵硬逻辑的:OA、ERP、RPA等,因为业务复杂,每出现一种情况就需要添加新的逻辑和成本,现在可以靠GPT识别自然语言意图并收束到代码动作(action)的能力达到更灵活的效果。
但这些都会被新的交互范式所推翻重构。
因为这些论断都是建立在旧交互上的习惯难以迁移的基础上的。
基于旧交互做的胶水,在AI还未完善的时候当然有一些好的结果,但是当未来AI可以完成对指令的自我优化,技术一定会向着一切从简的方向走。
目前的界面无法个性识别每个用户的意图,所以设计的是满足大多数人需要的界面。虽然LLM的出现并不能完全解决意图的识别问题,但是会极大地简化交互过程,以更自然,更个性化的人机交互形式呈现。
五、新交互范式-中期
进入的标志是出现了新的AI交互范式,并以一种不可逆转的形式向大众普及。
- 新的设备是什么?还会是手机吗?(手机的LBS和PC的LBS本质上是两个东西,手机上的图像输入和PC的图像输入也是两个东西。不能用旧认知去看新东西。)
- 终端肯定是本地大模型和多个小模型,身份定制化,私人化,专业化,情感化。
我认为对话框不是终点,信息的意图识别才是终点。而基于场景,做的复合信息的意图识别标准化是Dirtywork。这意味着LLM不是灯泡(电器),而是电网。
简单类比下:当你意图清楚时,你是给siri输入内容让app打开app的对应内容快,还是直接点击指定的app更快?意图识别取代不了对话框,但很有可能可以取代桌面的文件夹陈列。
新的交互范式发生时,是有窗口期留给开发者跟进的,LLM能完成任务,但用户有时无法描述具体的意图,这之中存在着GAP,要么开发者做Dirtywork,要么纯靠AI来猜测意图来设计交互,个人认为后者短时间不太可能做到,要达到这样的涌现,需要的信源太多,计算量也太大。
六、赛博具身-后期
这部分和IOT相关,是Tesla和波士顿动力这类实体硬件的领域,LLM想要完成更现实的任务从而真正达到生产力解放,拥有一个“身体”是必然的,但未必长得像人(hh),这还太遥远,就不展开说了。
本文由@海玮 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK