

下一代大数据分布式存储技术Apache Ozone初步研究 - itxiaoshen
source link: https://www.cnblogs.com/itxiaoshen/p/17354015.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

下一代大数据分布式存储技术Apache Ozone初步研究
Apache Ozone 官网地址 https://ozone.apache.org/ 最新版本1.3.0
Apache Ozone 官网最新文档地址 https://ozone.apache.org/docs/1.3.0/
Apache Ozone 源码地址 https://github.com/apache/ozone
Apache Ozone是一个高度可扩展、冗余的分布式对象存储,适用于分析、大数据和云原生应用,以在Kubernetes等容器化环境中有效地工作。Ozone支持S3兼容的对象API以及Hadoop兼容的文件系统实现。它针对高效的对象存储和文件系统操作进行了优化。建立高可用性、可复制的块存储层的Hadoop分布式数据存储(Hadoop Distributed Data Store, hds),像Apache Spark, Hive和YARN这样的应用程序在使用Ozone时无需任何修改即可工作;Ozone附带了一个Java客户端库、S3协议支持和一个命令行接口。
Apache Ozone 可与Cloudera 数据平台(CDP) 一起使用,可以扩展到数十亿个不同大小的对象。它被设计为原生的对象存储,可提供极高的规模、性能和可靠性,以使用 S3 API 或传统的 Hadoop API 处理多个分析工作负载。Ozone其发展是准备替代HDFS的下一代的大数据存储系统,着力要解决的目前HDFS存在的问题如NameNode的扩展性和小文件的性能问题。
先回顾一下HDFS,HDFS通过把文件系统元数据全部加载到数据节点Namenode内存中,给客户端提供了低延迟的元数据访问。由于元数据需要全部加载到内存,所以一个HDFS集群能支持的最大文件数,受Java堆内存的限制,上限大概是4亿~5亿个文件。所以HDFS适合大量大文件[几百兆字节(MB)以上]的集群,如果集群中有非常多的小文件,HDFS的元数据访问性能会受到影响。虽然可以通过各种Federation技术来扩展集群的节点规模,但单个HDFS集群仍然没法很好地解决小文件的限制。
Ozone是新一代的对象存储系统,其架构设计简单的可以总结为:
- 基于Raft+RocksDB来实现了一个分布式的kv存储,使用该kv存储来实现独立的元数据的存储,使得元数据完成了高可用和scale out的高扩展性。
- 基于Raft实现了数据存储功能。数据实现高可用和扩展性。
- 数据块的元数据分了两层:SCM管理block,block在Container的布局的信息保存在DataNode本地的rocksdb中,这种设计对小文件比较好。
Ozone目前社区开发比较活跃;架构比较合理,在扩展性和小文件方面优异;其设计目标和应用场景也比较明确清晰:弥补HDFS的缺陷,替换HDFS在大数据领域的地位。
- 可伸缩的:Ozone旨在支撑数百亿甚至更多的文件和块。
- 一致的:Ozone是一种强一致性的分布式存储,其一致性通过使用像RAFT这样的协议来实现。
- 云原生:Ozone可以在YARN和Kubernetes这样的容器化环境良好运行。
- 安全:Ozone与kerberos基础设施集成以实现访问控制,并支持TDE和在线加密。
- 多协议支持:Ozone支持不同的协议,如S3和Hadoop文件系统API。
- 高可用性:Ozone是一种完全复制的系统,可以在多次故障完美恢复。
Ozone主要设计要点是可扩展性,它的目标是扩展到数十亿个对象;Ozone将命名空间管理和块空间管理分开;命名空间由名为Ozone Manager (OM)的守护进程管理,块空间由Storage Container Manager (SCM)管理。Ozone命名空间由多个存储体组成。存储卷也被用作存储会计的基础;Ozone由volumes、buckets、keys组成:
- volumes:类似于用户帐户;只有管理员可以创建或删除卷。
- buckets:桶类似于目录。一个桶可以包含任意数量的键,但桶不能包含其他桶。
- keys:类似于文件,Ozone将数据以键的形式存储在这些桶中。
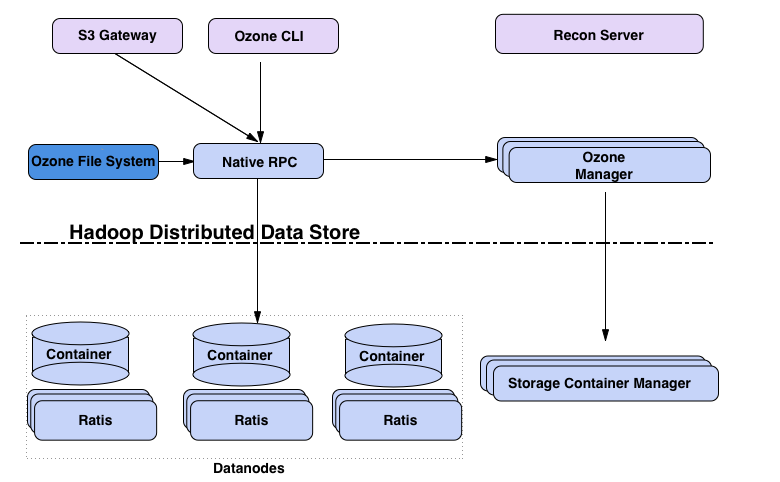
Ozone的核心组件:
-
客户端:S3 Gateway 提供 s3 协议的客户端,Ozone FileSystem为兼容HDFS的文件系统客户端。
-
元数据服务器
-
- Ozone Manager(OM):用于管理系统的元数据,文件系统的对应的主要是inode和dentry的管理,对象系统元数据主要是user,bucket,object等。Ozone Manager通过Raft + RocksDB实现了元数据存储分布式的KV存储。Raft协议使用开源的Apache Batis来实现。底层的KV存储使用了基于LSM Tree的RocksDB来实现。由于RocksDB存储是对写比较友好的存储系统,读操作不太友好。因此OM在内存中做了相应的元数据缓存系统用于缓存经常访问的元数据,可以显著降低读操作的不友好的影响。
- Storage Container Manager(SCM):集群和数据块管理,用于管理Data Node和数据Block相关的管理。
-
数据服务器:Datanodes用于存储数据,Containers就是block的集合,用于存储数据,其分布在Data Node上。所有数据都存储在数据节点上。客户端以块的形式写数据。Datanode将这些块聚合到一个存储容器中。存储容器是客户端写的关于块的数据流和元数据。
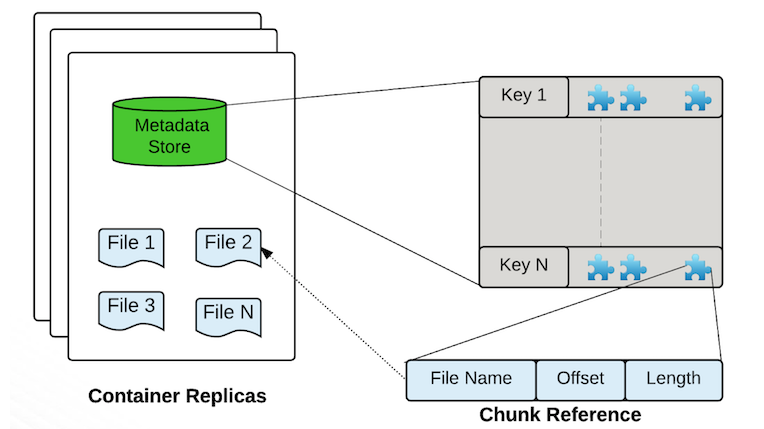
-
Containers是Ozone/ hdd的基本复制单元,它们由存储容器管理器(SCM)服务管理。容器是大的二进制存储单元(默认为5Gb),可以包含多个块,Container是数据复制(data replication)的基本单位。
- 一个DataNode上会有多个Container
- 一个Container有全局唯一的Container ID(Cid)
- 一个Container的对应的三个副本分布在三个Data Node上,通过RAFT协议实现数据的复制和一致性。
- 创建容器时,它以OPEN状态启动。当容器已满(写入约5GB数据)时,容器将关闭并成为closed容器。OPEN和CLOSED容器的基本区别
Open Close mutable (不能删除,可追加写) Immutable (可以删除,不能追加写) replicated with RAFT(Ratis) (写操作是通过 raft协议复制完成) replicated with async container copy (删除操作和数据修复操作不需要raft协议) Raft leader is used to READ/WRITE (写操作需要通过Leader,只能通过Leader读写) All the nodes can be used to READ (所以节点都可以读) - BlockID分两部分:ContainerID和LocalID,ContainerID用于标记该block所属的Container,LocalID用于查找该Block在Container的Offset等位置信息
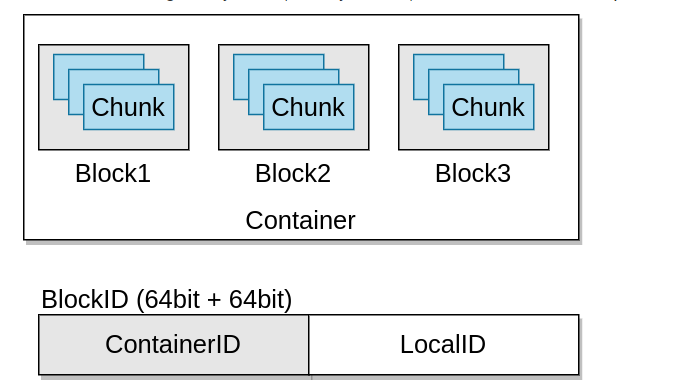
- Block:数据存储块默认最大256MB,一个Container包含多个Block。一个Block是一个可变的数据块,由基本的chunk组成。
- Chunk:数据存储块,默认最大4MB,一个Block包含多个Chunk,Chunk是客户端数据读写的基本单位。
- Ratis PipeLine:数据复制的数据流,可以理解为一个独立的Raft Group用于数据复制。Pipeline和Container是一对多的关系。一个Raft Group可以实现多个Container的数据复制。
-
-
Recon Server:系统监控和管理
Ozone管理器是名称空间管理器,存储容器管理器管理物理层和数据层,Recon是Ozone的管理接口。从另一个的视角来看Ozone,将其想象为构建在hdd(一个分布式块存储)之上的名称空间服务的Ozone Manager。可视化臭氧的方法是观察功能层;这里有元数据管理层,由Ozone管理器和存储容器管理器组成。数据存储层基本上是数据节点,由SCM管理。由Ratis提供的复制层用于复制元数据(OM和SCM),也用于在数据节点上修改数据时保持一致性。Recon管理服务器与Ozone的所有其他组件进行通信,并为Ozone提供统一的管理API和用户体验。协议总线允许通过其他协议扩展Ozone。目前只有通过协议总线构建的S3协议支持。协议总线提供了一个通用概念,可以实现调用O3 Native协议的新文件系统或对象存储协议。Apache Ratis是开源的java版的raft协议的实现。对于数据和元数据都用了Raft协议来保障数据的一致性和高可用。
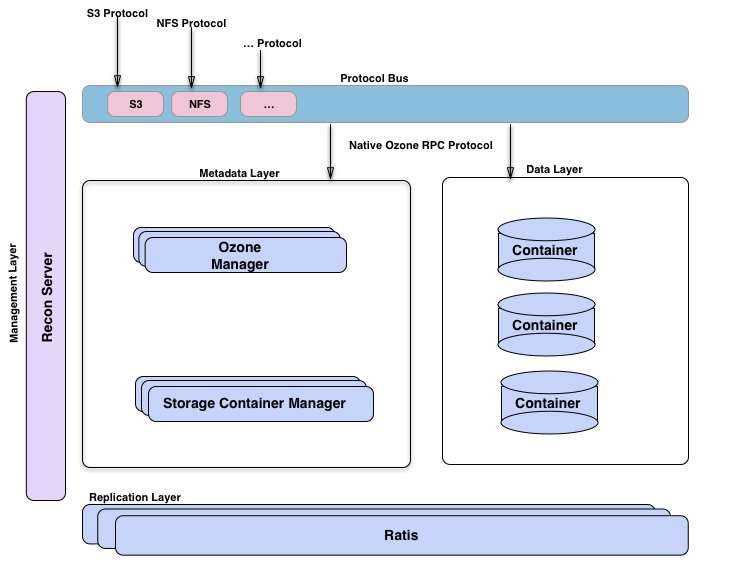
- 协议层:提供s3 protocol,NFS protocol等协议
- 元数据层:MetaData layer:包括 Ozone Manager处理文件系统或者对象存储系统的元数据。Storage Container Manager处理集群和数据块相关的元数据。Ozone把HDFS的元数据拆分为OM文件系统的目录管理和SCM数据块管理。
- 数据层:Data Layer层,主要是DataNode 组成的集群,每个DataNode上包括很多Container,Container组成Raft Group来实现数据的复制。
写入数据时,向Ozone管理器请求一个块,Ozone管理器会返回一个块并记住该信息
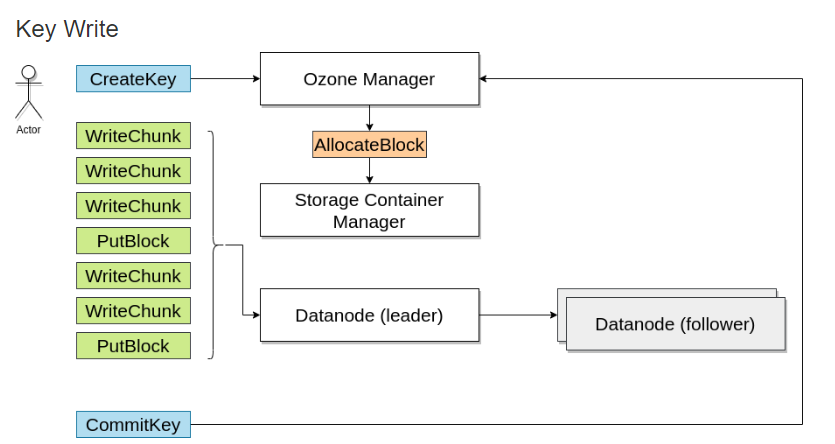
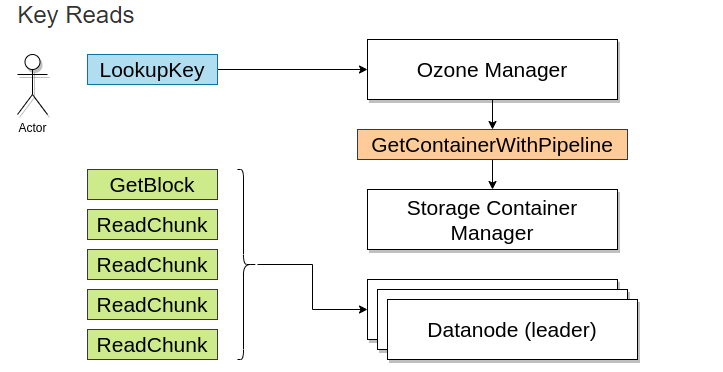
当读取该文件时,由Ozone Manager返回需要块的地址。
- 简单启动:从Docker Hub运行Ozone
- 推荐:从官方发布运行Ozone。Apache Ozone也可以从官方发布包中运行。随着官方源代码的发布,还发布了一组方便的二进制包;可以很轻松的在不同的配置中运行这些二进制文件。
- 物理部署Ozone集群。
- K8S部署Ozone集群。
- MiniKube部署Ozone集群。
- docker-compose部署本地集群
- Hadoop Ninja:从源码中构建Ozone部署包。
Docker启动
# 如果是用于开发测试,可以通过容器启动Ozone;启动一体化Ozone容器最简单的方法是从docker hub中使用最新的docker镜像,该容器将运行所需的元数据服务器(Ozone Manager、Storage container Manager)、一个数据节点和S3兼容的REST服务器(S3 Gateway)。
docker run -p 9878:9878 -p 9876:9876 apache/ozone

Docker-compose启动
# 本地多容器集群,如果要部署伪集群,每个组件在自己的容器中运行,则可以使用docker-compose启动,从docker hub中的映像中提取这些文件
docker run apache/ozone cat docker-compose.yaml > docker-compose.yaml
docker run apache/ozone cat docker-config > docker-config
# docker-compose启动集群
docker-compose up -d
# 如果需要多个数据节点,可以按比例扩展:
docker-compose up -d --scale datanode=3

访问Ozone Recon的控制台页面http://hadoop3:9888 ,查看概览可以看下Datanodes、Pipelines、Volumes、Buckets、Keys等,还可以查看数据节点信息
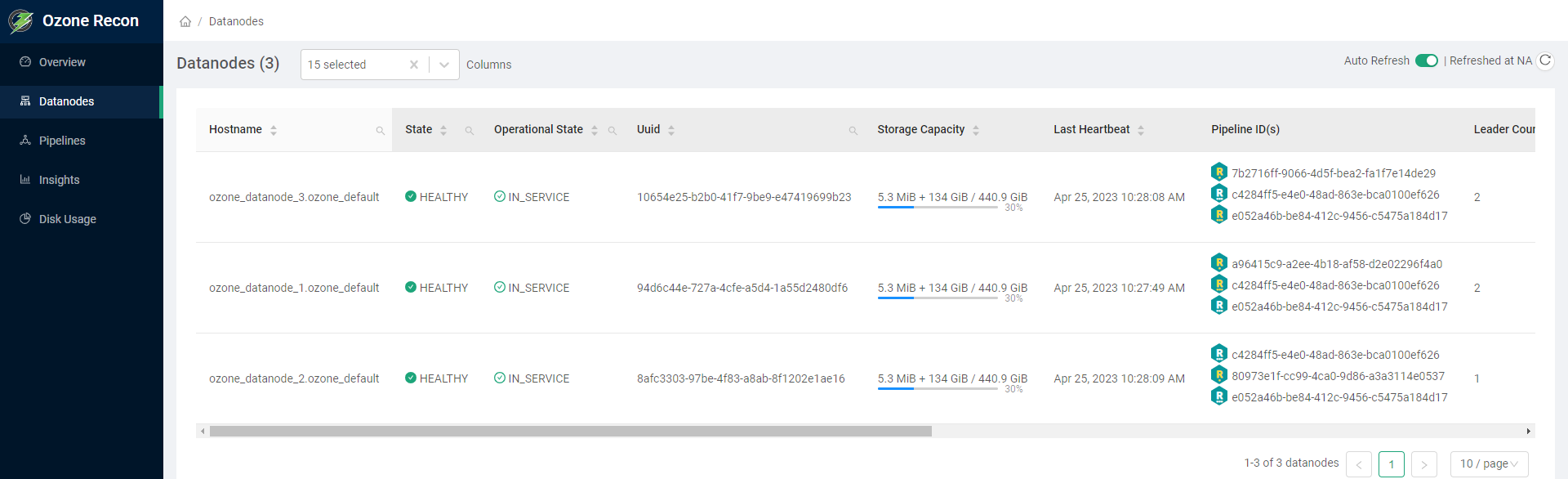
企业预置型(On Premise)安装
可以在一个真正的集群中设置臭氧,建立一个真正的集群,其组成部分
- Ozone Manager:是负责Ozone 命名空间的服务器。臭氧管理器负责所有的卷,桶和键操作。
- Storage Container Manager:充当块管理器。Ozone Manager从SCM请求块,客户机可以向其写入数据。
- datanode:Ozone数据节点代码运行在HDFS datanode内部,或者在独立部署的情况下运行臭氧datanode守护进程。
# 下载ozone最新版本的1.3.0
wget https://dlcdn.apache.org/ozone/1.3.0/ozone-1.3.0.tar.gz
# 解压文件
tar -xvf ozone-1.3.0.tar.gz
# 进入目录
cd ozone-1.3.0
# 配置文件位于ozone根目录下的etc/hadoop/ozone-site.xml
<property>
<name>ozone.metadata.dirs</name>
<value>/data/disk1/meta</value>
</property>
ozone.scm.names
<property>
<name>ozone.scm.names</name>
<value>scm.hadoop.apache.org</value>
</property>
ozone.scm.datanode.id.dir
<property>
<name>ozone.scm.datanode.id.dir</name>
<value>/data/disk1/meta/node</value>
</property>
ozone.om.address
<property>
<name>ozone.om.address</name>
<value>ozonemanager.hadoop.apache.org</value>
</property>
# scm初始化
ozone scm --init
# scm启动
ozone --daemon start scm
# om初始化
ozone om --init
# om启动
ozone --daemon start om
# 数据节点启动
ozone --daemon start datanode
# 简洁启动
ozone scm --init
ozone om --init
start-ozone.sh
命令行接口
Ozone shell是从命令行与Ozone交互的主要接口,其背后使用Java API。如果不使用ozone sh命令,就无法访问一些功能。例如:
- 创建有配额的卷
- 管理内部acl
- 使用加密密钥创建桶
所有这些都是一次性的管理任务。应用程序可以使用其他接口,如Hadoop兼容文件系统(o3fs或ofs)或S3接口来使用臭氧,而不需要这个CLI。
# 查看卷的帮助ozone sh volume --help# 查看具体操作帮助ozone sh volume create --help# 创建卷ozone sh volume create /vol1# 查看卷信息ozone sh volume info /vol1# 列出卷ozone sh volume list /
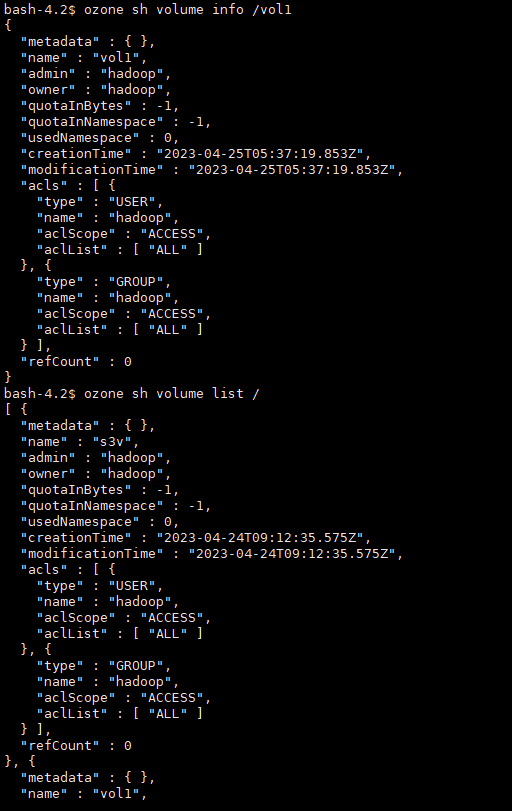
# 创建桶ozone sh bucket create /vol1/bucket1# 查看桶ozone sh bucket info /vol1/bucket1# 存储键数据ozone sh key put /vol1/bucket1/anaconda-post.log /anaconda-post.log# 查看键数据ozone sh key info /vol1/bucket1/anaconda-post.log# 读取键数据到本地ozone sh key get /vol1/bucket1/anaconda-post.log /data/
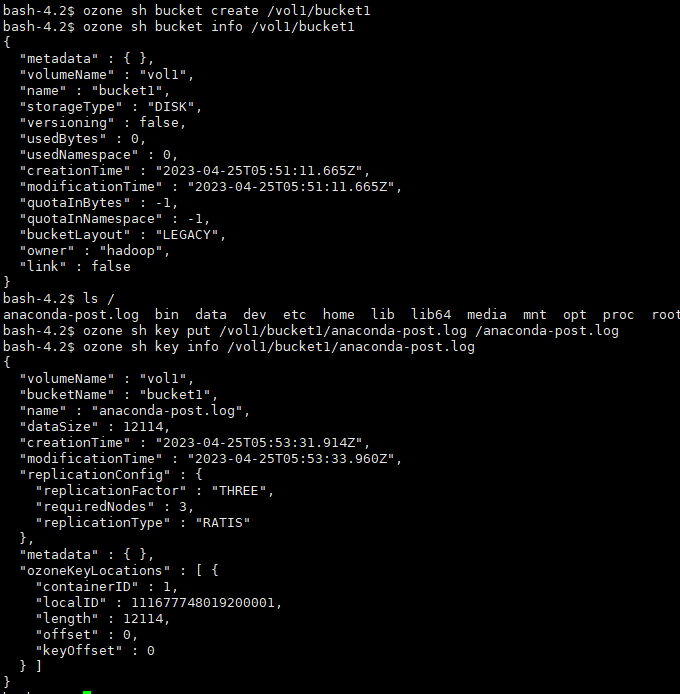
# 指定URLozone sh bucket info o3://172.28.0.8:9862/vol1/bucket1
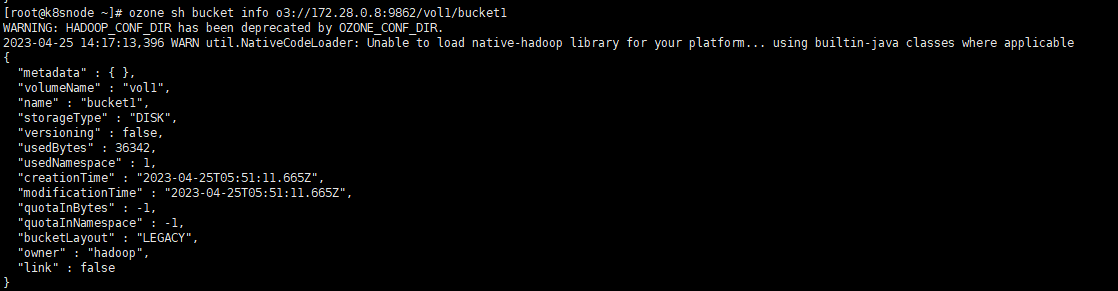
Ofs (Hadoop兼容)
Hadoop兼容的文件系统接口允许像Ozone这样的存储后端轻松集成到Hadoop生态系统中。Ozone文件系统是一个与Hadoop兼容的文件系统。
目前,Ozone支持o3fs://和ofs://两种方案。o3fs和ofs之间最大的区别在于,o3fs只支持单个桶上的操作,而ofs支持跨所有卷和桶的操作,并提供所有卷/桶的完整视图。
卷和挂载位于OFS文件系统的根级别。桶自然列在卷下。键和目录位于每个桶的下面。注意,对于挂载,目前只支持临时挂载/tmp。
请将下面内容添加到core-site.xml中。
<property> <name>fs.ofs.impl</name> <value>org.apache.hadoop.fs.ozone.RootedOzoneFileSystem</value></property><property> <name>fs.defaultFS</name> <value>ofs://hadoop3/</value></property>
将ozone- filessystem -hadoop3.jar文件添加到类路径中(注意如果使用Hadoop 2.X,使用ozone- filessystem -hadoop2-*.jar)
export HADOOP_CLASSPATH=/opt/ozone/share/ozone/lib/ozone-filesystem-hadoop3-*.jar:$HADOOP_CLASSPATH
设置了默认的文件系统,用户就可以运行ls、put、mkdir等命令。
# 创建卷,也即是创建目录hdfs dfs -mkdir /volume1# 创建桶,也即是创建二级目录hdfs dfs -mkdir /volume1/bucket1# 写入数据文件hdfs dfs -put /tmp/data.txt /volume1/bucket1/# 查看文件hdfs dfs -ls /volume1/bucket1/
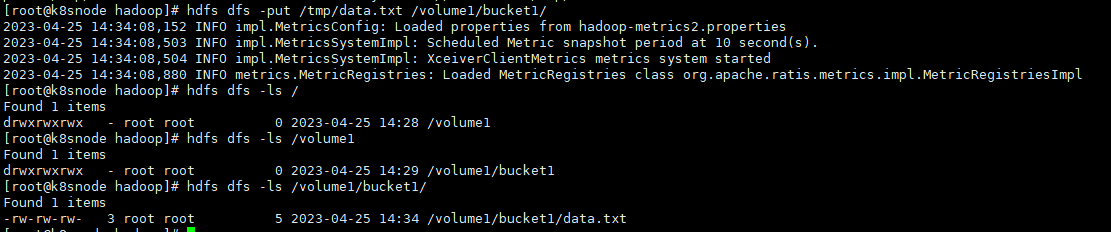
通过Ozone的shell也能查看对应的信息
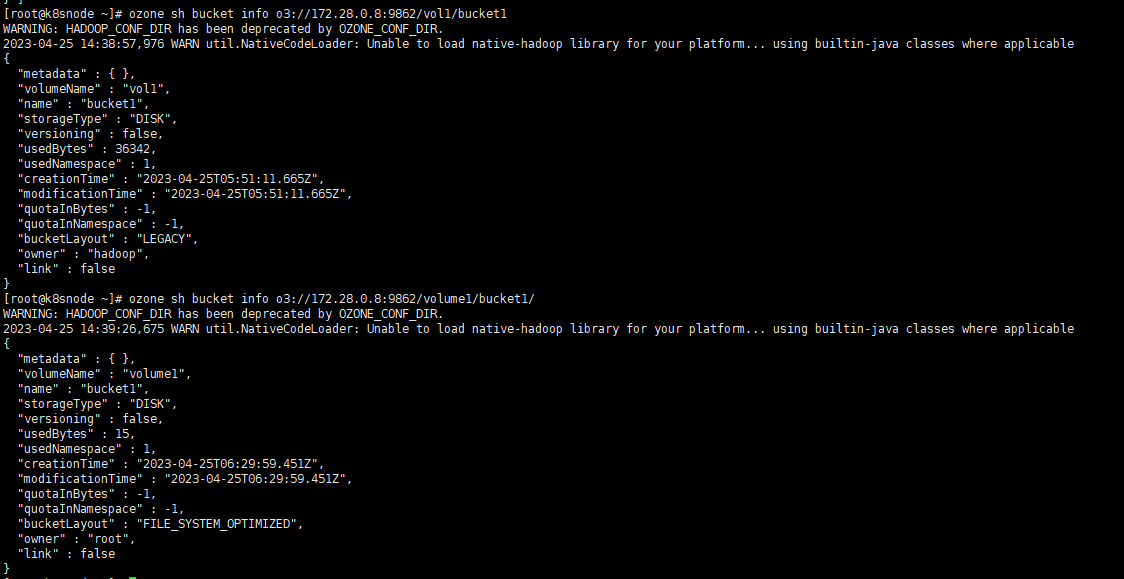
# o3fshdfs dfs -ls o3fs://bucket.volume.cluster1/prefix/# ofshdfs dfs -ls ofs://cluster1/volume/bucket/prefix/
Recon API
Recon API v1是一组HTTP端点,可帮助了解Ozone集群的当前状态,并在需要时进行故障排除。
标记为admin的端点只能由Ozone中指定的Kerberos用户访问。安全集群的Administrators或ozone.recon.administrators配置。
| Property | Value |
|---|---|
| ozone.security.enabled | true |
| ozone.security.http.kerberos.enabled | true |
| ozone.acl.enabled | true |
# 获取容器curl http://hadoop3:9888/api/v1/containers

这个相当于管理页面的后台接口

- 本人博客网站IT小神 www.itxiaoshen.com
Recommend
-
10
Apache DolphinScheduler新一代分布式工作流任务调度平台实战-上 ...
-
9
Apache DolphinScheduler新一代分布式工作流任务调度平台实战-中 ...
-
5
一文理解Hadoop分布式存储和计算框架入门基础
-
3
全能成熟稳定开源分布式存储Ceph破冰之旅-上
-
8
大数据下一代变革之必研究数据湖技术Hudi原理实战双管齐下-上 ...
-
3
大数据下一代变革之必研究数据湖技术Hudi原理实战双管齐下-中 ...
-
8
集成Flink 本节通过一个简单Flink写入Hudi表的编程示例,后续可结合自身业务拓展,先创建一个Maven项目,这次就使用Java来编写Flink程序。 由于中央仓库没有scala2.12版本的资源,前面文章已经编译好相关jar,那这里就将hudi-flink1...
-
5
云原生K8S精选的分布式可靠的键值存储etcd原理和实践 ...
-
2
基于列存储的开源分布式NoSQL数据库Apache Cassandra入门分享 ...
-
11
实时分布式低延迟OLAP数据库Apache Pinot探索实操 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK