

ChatGPT走红背后:苦熬五年,三次AI路线迭代|行业观察
source link: https://www.36kr.com/p/2123040414124166
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一场还不入局就会被淘汰的游戏,已经在全球拉开帷幕。
去年底,自ChatGPT这个略显拗口的名字在全球引爆对话式风潮,微软、亚马逊、谷歌等大厂入局其中的消息,就像接连丢进水中的石子,不断在科技领域激起浪花。
其中,微软作为ChatGPT背后母公司的投资人最早押下重注,于本周宣布在所有产品线内集成ChatGPT能力。而当ChatGPT将取代搜索引擎的论调甚嚣尘上,谷歌也坐不住了,于北京时间2月7日宣布将推出自己的对话式机器人"Bard"(吟游诗人)。
就在同天,百度官宣将基于自家的文心大模型,推出类ChatGPT的产品"文心一言"。当日下午,国内搜索引擎市场的第二名360紧随其后,披露自家已在内部使用这类产品,同样计划尽快推出类ChatGPT的Demo版产品。消息发出两小时后,其股价应声涨停。
新消息还在持续。北京时间2月8日凌晨,微软在媒体发布会上宣布开放ChatGPT支持的搜索引擎Bing。
而在官宣消息纷飞的背后,不难发现几乎每个追赶ChatGPT的大厂,都在提及"大模型"的概念。
百度在短短数行的官宣中,专门花去一段介绍自家的AI四层架构布局,并重点提及文心大模型。谷歌CEO桑达尔·皮查伊也表示,自家的AI对话式机器人"Bard"(吟游诗人),由大模型LaMDA提供支持。
360的披露十分坦率,表示自家布局ChatGPT类产品的优势在于数据和语料,在预训练大模型方面还存在短板。
ChatGPT和大模型是一体两面的关系。表面看,ChatGPT是一个具备聊天、咨询、撰写诗词作文等能力的对话式机器人。但本质上,它是基于AI大模型而产生的应用——如果没有大模型的能力支撑,如今引爆全球的ChatGPT或将不会诞生。
一. 爆火背后:由大模型打开的ChatGPT魔盒
ChatGPT能达到如今"上知天文、下知地理"的效果,离不开基于海量数据而生的大模型——是大模型,让它理解并使用人类语言,并近乎真实地进行对话和互动。
海量数据是大模型的基础。顾名思义,这是一种通过亿级的语料或者图像进行知识抽取、学习,进而产生的亿级参数模型。而ChatGPT,是OpenAI GPT-3模型的升级。在参数量上,GPT-3模型拥有1750亿参数。
这带来超乎想象的突破——基于大量文本数据(包括网页、书籍、新闻等等),ChatGPT获得了对不同类型的话题进行回答的能力。再加上学习方法的差异性,ChatGPT能够发散式地解答问题。
大模型不是新鲜事物,在2015年左右业内已有讨论。但在大模型出现的背后,其实蕴藏着一场人工智能落地模式的变革。
作为人工智能最重要的组成部分之一,机器学习的落地长期依赖数据模型。它需要大量的数据来训练模型,以便让计算机系统得以从数据中进行学习。
简单从效果总结,当数据量越大,机器学习得以学习的基础越多,让效果更精准、更智能的可能性就越高。
这也意味着,在数据量不够大的过去,机器学习的发展会受到阻碍。而伴随着PC和移动互联的进展,机器学习生存的基础——数据量也呈几何式增长。由此产生的一个现象是,从1950年到2018年,模型参数增长了7个数量级。而在2018年之后的4年内,模型参数增长了5个数量级,从数亿个达到超千亿水平。
也就是说,当数据量充足,机器学习就具备进一步升级的可能,而这个可能性在2018年已经存在。
但是,仅有数据还不够,伴随着数据使用而来的,还有递增的成本——机器学习环节中使用的数据量越大,所需的数据标注、数据清洗、人工调参等成本也就越高。高质量的标注数据难以获得,让整件事的投入产出比打了折。
为了解决这个问题,机器学习的落地方式也发生变化。
如今,机器学习主要分为监督学习、无监督学习和半监督学习三种学习方法。大模型,与无监督学习、半监督学习息息相关。
早前,构建机器学习的主流方法是监督学习。也就是先收集数据,再通过强人工干预/监督的方式,喂给模型一套经过人工校验的输入和输出组合,让模型通过模仿,完成学习。
“在完成标注、清洗环节后,我会给机器输入一组数据,并反馈学习结果的正确或者错误,让它找到参数之间的关联并进行优化。”一位曾参与过算法调优的产品经理表示。
而无监督学习不需要打标,而且在训练数据中,只给定输入,没有人工给出正确的输出,目的是让模型开放式地、自己学习数据之间的关系。
半监督学习则处于两者之间。在这种学习方式中,模型会尝试从未标记的数据中提取信息来改进它的预测能力,同时也会使用已标记的数据来验证它的预测结果。
也就是说,相比过去的监督学习,无监督学习和半监督学习节省了更多成本,降低了对高质量标注数据的依赖。
“如果没有无监督学习,大模型很可能是训练不出来的。”一位横跨学术、商业两界的AI专家不久前告诉36氪。
当然,ChatGPT能横空出世,降低成本并不是最重要的。
在监督学习的模式下,人工"调教"的数据经常来自于一些属于属于特定领域、整体数量不大的数据集。这会导致,一旦某个领域的模型要应用到其他领域,就会出现难以适应的情况,也就是所谓的"模型泛化能力不佳"。
举个例子,在问答数据集上表现不错的模型,用到阅读理解上很可能产生不尽如人意的结果。
而大模型的诞生,能够相对解决"泛化能力"不佳的问题,也就是变得更通用。
这背后也是因为,大模型基于互联网公开的海量数据进行训练,没有以特定的小数量数据作为基础。这种方式,更可能训练出一套适用多个场景的通用基础模型——这同样是ChatGPT能回答各种五花八门问题的重要原因。
总而言之,大模型的落地是机器学习的一个里程碑,也是打开ChatGPT魔盒的关键钥匙。
二. GPT系列:落地大模型的"自我革命"
回顾ChatGPT的迭代,可以看到一部大模型自我升级的历史。在这个过程里,OpenAI至少进行了三次技术路线的"自我革命"。
前文提到,ChatGPT基于OpenAI的第三代大模型GPT-3升级而来,也就是在GPT3.5上进行微调而诞生。
从名称也能看出,OpenAI此前还发布了GPT-1、GPT-2和GPT-3。这几代GPT的落地方式不尽相同。
第一代生成式预训练模型GPT-1于2018年被推出。GPT-1的学习方式是半监督学习,也就是先用无监督学习的方式,在8个GPU上花费1个月从大量未标注数据中学习,然后再进行有监督的微调。
这样做的好处是,只需要少量微调,就可以增强模型的能力,减少对资源和数据的需求。
但问题在于,GPT-1的数据较少,和如今的动辄千亿对比,当时1亿多的参数量似乎少的可怜。这使得,GPT-1模型整体对世界的认识不够全面和准确,并且泛化性依然不足,在一些任务中的性能表现不佳。
在GPT-1推出一年后,GPT-2正式面世。这一代的GPT在底层架构上和"前辈"没有差别,但在数据集方面,GPT-2有着40GB的文本数据、800万个文档,参数量也大幅突破到了15亿个。
有研究显示,参数量爆发的GPT-2,生成的文本几乎与《纽约时报》的真实文章一样令人信服。这也让更多人意识到无监督学习下,大模型的价值所在。
伴随着每年一更新的频率,2020年,GPT-3如约而至。这次的GPT-3,在模型参数上达到了1750亿个,类型上也包含了更多的主题文本。相对GPT-2,这次的新版本已经可以完成答题、写论文、文本摘要、语言翻译和生成计算机代码等任务。
需要指出的是,此时的GPT-3依然走的是无监督学习、大参数量的路线,而到了2022年,情况发生了不小的变化。
这一年,在GPT-3的基础上,OpenAI推出了InstructGPT。OpenAI表示,InstructGPT 是 GPT3 的微调版本,在效果上降低了有害的、不真实的和有偏差的输入。而ChatGPT与InstructGPT除却训练模型的数据量不同,并无太大差异。
问题来了,为什么InstructGPT和ChatGPT可以进一步提升智能性,优化人们的交互体感?
背后原因在于,OpenAI在2022年发布的这两个模型,从技术路线上又开始看重人工标注数据和强化学习——也就是从人类反馈(RLHF) 中强化学习。据介绍,这一次OpenAI使用一小部分人工标记的数据来构建奖励模型。
粗看下来,无监督学习下的大模型路线特点在于数据量大,和降低数据标注和人工依赖——这是GPT-2和GPT-3的核心。
而InstructGPT和ChatGPT的路线,则像是阶段性重回了人工路线。
这种变化看似剧烈,但其实是为了让AI产品更好用而产生的调整。拆解背后逻辑,ChatGPT的训练离不开GPT-3.5的大模型基础,但其中引入的人工标注数据和强化学习,则可以让大模型更理解信息的含义,并进行自我判断——也就是更贴近理想中的人工智能效果。
也就是说,之前的无监督学习给定输入,不给出正确的输出,让模型得以在海量数据的基础上"自由发展",具备人工智能的基本素质。
但此时加入人类对大模型学习结果的反馈,会让模型更理解输入自身的信息和自身输出的信息,变得更好用。落在具体场景中,经过人类反馈的ChatGPT,可以提升判断用户提问意图(即输入)和自身答案质量(即输出)的能力。
为了达成更好的效果,有信息显示,OpenAI招聘了40个博士来进行人工反馈工作。
对人工智能中的人力工作先抛弃再捡回,这看似前后矛盾的做法,也得到不少行业人士肯定。
比如,京东集团副总裁、IEEE Fellow何晓冬不久前对媒体表示,相较之前大量使用无监督深度学习算法,ChatGPT模型背后的算法和训练过程更加新颖。如果没有人的数据甄选,模型参数即便大十几倍,也很难达到如今效果。
“在某种意义上,这其实是对过去一味追求(参数)大和追求无监督学习的一个路线修正。”何晓冬总结。
当然,即使重新重视人工反馈,也不意味着OpenAI完全放弃此前的坚持。有分析指出,ChatGPT的训练主要分为了三个阶段,前两个阶段人工反馈非常重要,但在最后一公里上,ChatGPT只需要学习在第二阶段训练好的反馈模型,并不需要强人工参与。
无论是 GPT-1、2、3还是InstructGPT和ChatGPT,OpenAI这五年的模型迭代之路似乎也是一场自我改革。
这同样说明,把某类技术推演到极致,并不是这家公司的坚持——不论是无监督学习、自监督学习还是半监督学习,从来不是为了炼就大模型,而是想让AI更智能。
三. 大厂收割大模型,但"炼"模型不是终点
即便大模型的能力随着ChatGPT的爆红而走向台前,但业界的争议依旧无法掩饰。
从商业模式来看,当大模型变得更通用,更多企业可以依赖大模型的基础,进行更偏自身业务属性的微调。这样做在理论上的好处是,不少企业可以省去很多训练模型的成本,而推出大模型的公司,可以向前者收取调取大模型的费用。
但36氪发现,这一思路当前也在被一些产业人士"吐槽"。
一家AIGC公司的创始人告诉36氪,这件事不仅是钱和成本的问题,重点是调用第三方大模型存在很多限制,会对自家业务造成影响。
"比如,你很难针对一些应用场景来做优化。"他举例,如果想做声音模拟和形象模拟的综合型需求,需要模型提供方提供综合能力,而一旦有一个技术点不到位,就会导致产品效果不佳。
吐槽效果之外,36氪还了解到业内有公司在通过算法优化的方式,期望降低大模型落地的成本。
但本质上,大模型无疑是一个天生适合巨头的生意——这从其成本投入上可见一斑。
从流程上拆解,构建一个大模型至少需要足够的数据处理、计算和网络能力。
拿流程上游的数据处理来说,无监督学习能解决一部分数据标注的成本,但此前的数据收集、数据清洗成本依然难以降低。而且这些工作经常需要依赖人工,难以完全工具化,
再看计算和网络,大模型的训练任务场景动辄需要几百甚至几千张GPU卡的算力。这意味着在算力之外,当服务器节点众多,跨服务器通信需求大,网络带宽性能亦成为GPU集群瓶颈,高性能计算网络也随之成为一个话题。
具体的数字更具说服力。有报道指出,Stability AI此前仅计算就需要花费约2000万美元。而如果仅拿大模型去做微调和推理,本地也需要好几千GB的内存。潞晨科技创始人尤洋也曾提及,想把大模型部署到生产线,若一个企业从零开始自己做会需要70人左右的人力。而在欧美地区光是养活70个人,成本就需要2000万美金。
大厂对大模型的高价入场券并不讳言。去年年底,一位国内头部互联网公司的数据部门负责人对36氪直言,如果中型公司想要复刻大模型之路,在他看来是一个十分不经济、不理性的行为。他进一步表示,就算是这家市值早超百亿美元的公司,做大模型的初衷也是为服务自身内部的业务——也就是让需要AI能力的各业务部门拥有统一的能力支撑,避免多重内耗。
所以,大厂收割底层大模型,中小公司选取更适合自己业务特点的大模型,并基于此建立起行业应用,是相对合理的路线。换言之,AI领域会重现国内云计算的格局。
大厂热情勃发,带来另一个有趣现象,就是自2020年起,中国的大模型数量骤增。根据统计,仅在2020年到2021年,中国大模型数量就从2个增至21个,和美国量级同等,大幅领先于其他国家。
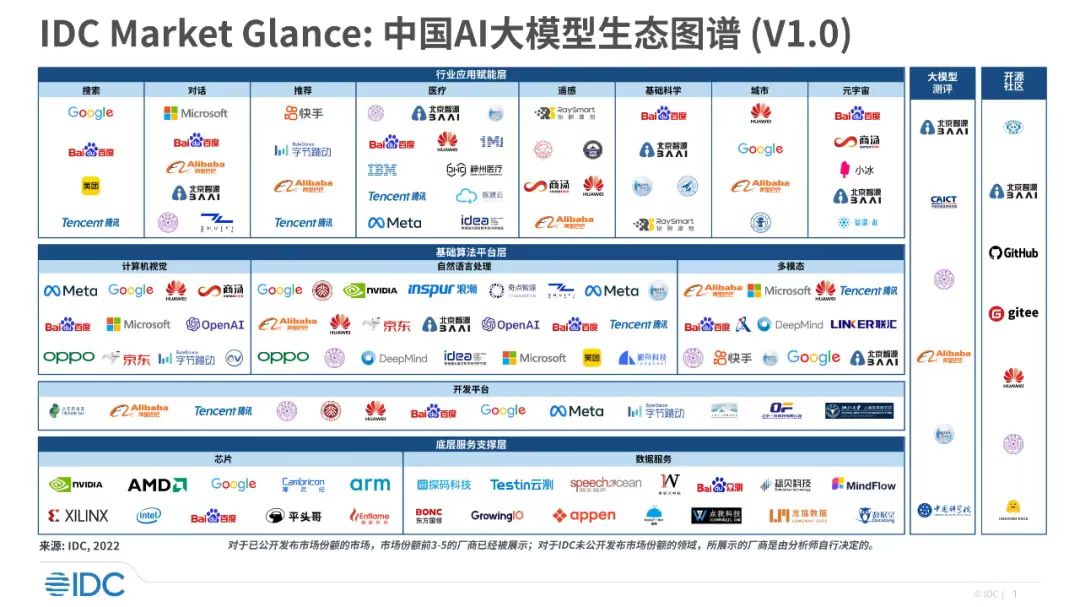
来源:IDC
即便剔除大厂的劲头,这一现象的出现也有着国情合理性。首先,大模型底层更依赖工程能力,再加上中国作为人口和移动互联大国,数据量天然众多。这两个前提,让中国天生具备打造大模型的优势。
然而不论是国内还是国外,大模型都同时面临着一个灵魂拷问——当数据量越叠越大,底层算力又无法承载时,大模型之路是否还能走通?这一问题对中国来说更需重视,毕竟国内对底层硬件能力的突破,还处于漫漫征途中。
或许对中国的从业者而言,这次ChatGPT的爆红只是一个表面现象,更深的启示在于看到OpenAI对大模型落地的"自我迭代"。
毕竟,这家公司已用至少五年的自我博弈过程告诉所有人,一味"炼"就大模型不是目的,让AI真正可用好用,才是终章。
参考文献:
《透过ChatGPT的进化足迹,OpenAI传达了哪些信号?》,脑极体
《百度类ChatGPT产品将在3月完成内测 业内人士:谨慎乐观》,财联社
《ChatGPT爆火,揭秘AI大模型背后的高性能计算网络》,InfoQ
Recommend
-
57
「猫卡」小程序走红,背后是猫经济与空巢青年的崛起-36氪「猫卡」小程序走红,背后是猫经济与空巢青年的崛起Mandy王梦蝶·2018-01-04 11:27
-
7
苦熬无用!研究:睡眠习惯不好的大学生成绩较差,考试容易发挥失常 Evelyn Zhang • 2021-05-17 09:53:10 来源:前瞻网 E984
-
8
导语:热闹的茶饮赛道从来不缺话题和创意。在小众鲜果油柑、泰式绿茶等玩法逐渐普遍之后,不少茶饮品牌又兴起了新玩法,这次不是将产品做大而是做巧。比如,最近兴起的MINI奶茶。最近,小巧可爱的MINI奶茶在社交平台上走红,有的是官方出品,有的是...
-
2
百雀羚、林清轩、逐本走红背后,植物基护肤品的春天来了? 过去被忽视的国牌护肤,在植物基概念越来越火的当下,正在迎来新的发展热潮。 提及当前大热的消费风口,绝对少不了植物基。饱受争议的植物肉、风头正盛的植物奶,无一...
-
4
傅哲宽:苦熬投资学 - 精选 - 商界网 | 商界APP-专注于商人-企业以及商业思维傅哲宽:苦熬投资学 梁坤 2021-09-08 10:12:50...
-
5
FF91五年“发布”三次,贾跃亭画的饼还有人买单吗? 潘涛 发表于 2022年02月24日 07:04 ...
-
5
消费电子“熟透”,苹果硬挺、小米苦熬长桥海豚投研·2022-06-17 12:53通缩抬头,电子消费品谁更坚挺?在疫情和通胀...
-
9
2023,跳水的锂价,苦熬的锂企 生产过剩导致供大于求,锂价于是“跳水”,好日子到头了。 作为一种金属元素,“锂”在近几年成为了热门话题。碳酸锂和氢氧化锂是制造动力电池正极的主要原材料,动力电池又是为新能源汽车提供动力的核心部...
-
5
隆基苦熬“光伏寒冬” 一些分析师认为,目前多数厂商开始集中抛售库存,光伏产业链还在寻底,价格下行趋势会持续到明年上半年。 近期,有关光伏大裁员的消息甚嚣尘上,网传隆基绿能要裁员1万人,其中应届生无补偿被“快速淘汰”。12月26...
-
3
小米汽车来了,苦熬5年的小米股票能否翻身?价值研究所·2023-12-28 11:18小米汽车能“叫好又叫座”吗?12月28日下午,小米...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK