

How to make the fastest .NET Serializer with .NET 7 / C# 11, case of MemoryPack
source link: https://neuecc.medium.com/how-to-make-the-fastest-net-serializer-with-net-7-c-11-case-of-memorypack-ad28c0366516
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
How to make the fastest .NET Serializer with .NET 7 / C# 11, case of MemoryPack
I have released a new serializer called MemoryPack, a new C#-specific serializer that performs much faster than other serializers.
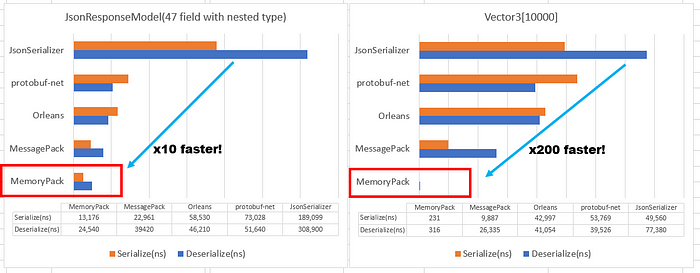
Compared to MessagePack for C#, a fast binary serializer, the performance is several times faster for standard objects, and even 50~100 times faster when the data is optimal. The best support is .NET 7, but now supports .NET Standard 2.1 (.NET 5, 6), Unity, and even TypeScript. It also supports Polymorphism(Union), full version-tolerant, circular references, and the latest modern I/O APIs (IBufferWriter, ReadOnlySeqeunce, Pipelines).
Serializer performance is based on both the “data format specification” and the “implementation in each language”. For example, while binary formats generally have an advantage over text formats (such as JSON), it is possible to have a JSON serializer that is faster than a binary serializer (as demonstrated with Utf8Json). So what is the fastest serializer? When you get down to both specification and implementation, the true fastest serializer is born.
I have been, and still am, developing and maintaining MessagePack for C# for many years, and MessagePack for C# is a very successful serializer in the .NET world, with over 4000 GitHub Stars. It has also been adopted by Microsoft standard products such as Visual Studio 2022, SignalR MessagePack Hub Protocol, and the Blazor Server protocol(blazorpack).
In the last 5 years, I have also processed nearly 1000 issues. I have been working on AOT support with code generators using Roslyn since 5 years ago, and have demonstrated it, especially in Unity, an AOT environment (IL2CPP), and many Unity mobile games using it.
In addition to MessagePack for C#, I have created serializers such as ZeroFormatter(own format) and Utf8Json (JSON), which have received many GitHub Stars, so I have a deep understanding of the performance characteristics of different formats. Also, I have been involved in the creation of the RPC framework MagicOnion, the in-memory database MasterMemory, PubSub client AlterNats, and both client (Unity)/server implementations of several game titles.
MemoryPack’s goal is to be the ultimate fast, practical, and versatile serializer. And I think I achieved it.
Incremental Source Generator
MemoryPack fully adopts the Incremental Source Generator enhanced in .NET 6. In terms of usage, it is not so different from MessagePack for C#, except for changing the target type to partial.
using MemoryPack;
// Source Generator makes serialize/deserialize code
[MemoryPackable]
public partial class Person
{
public int Age { get; set; }
public string Name { get; set; }
}
// usage
var v = new Person { Age = 40, Name = "John" };
var bin = MemoryPackSerializer.Serialize(v);
var val = MemoryPackSerializer.Deserialize<Person>(bin);
The biggest advantage of Source Generator is that it is AOT-friendly, automatically generating optimized serializer code for each type without reflection, without the need for dynamic code generation by IL.Emit, which is conventionally done. This makes it possible to work safely with Unity’s IL2CPP, etc. The initial start-up speed is also fast.
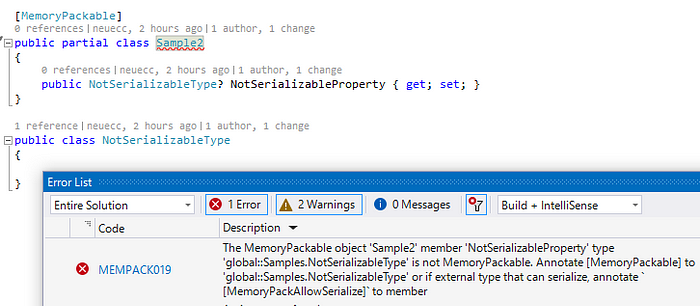
The Source Generator also serves as an analyzer, so it can detect if it is safely serializable by issuing a compile error at edit time.
Note that the Unity version uses the old Source Generator instead of the Incremental Source Generator due to language/compiler version reasons.
Binary Specification for C#
MemoryPack’s tagline is “Zero encoding”. This is not a special story; Rust’s major binary serializer, bincode, for example, has a similar specification. FlatBuffers also reads and writes content similar to memory data for without parsing implementation.
However, unlike FlatBuffers and others, MemoryPack is a general-purpose serializer that does not require a special type and serializes/deserializes against POCO. It also has versioning tolerant to schema member additions and polymorphism support (Union).
varint encoding vs fixed
Int32 is 4 bytes, but in JSON, for example, numbers are encoded as strings with variable length encoding of 1~11 bytes (e.g., 1 or -2147483648). Many binary formats also have variable length encoding specifications of 1 to 5 bytes to save size. For example, the numeric type of Protocol Buffers has variable-length integer encoding that stores the value in 7 bits and the flag for the presence or absence of a following in 1 bit (varint). This means that the smaller the number, the fewer bytes are required. Conversely, in the worst case, the number will grow to 5 bytes, which is larger than the original 4 bytes. MessagePack and CBOR are similarly processed using variable-length encoding, with a minimum of 1 byte for small numbers and a maximum of 5 bytes for large numbers.
This means varint is run extra processing than in the fixed-length case. Let’s compare the two in concrete code. Variable length is varint + ZigZag encoding (negative and positive numbers are combined) used in protobuf.
// Fixed encoding
static void WriteFixedInt32(Span<byte> buffer, int value)
{
ref byte p = ref MemoryMarshal.GetReference(buffer);
Unsafe.WriteUnaligned(ref p, value);
}
// Varint encoding
static void WriteVarInt32(Span<byte> buffer, int value) => WriteVarInt64(buffer, (long)value);
static void WriteVarInt64(Span<byte> buffer, long value)
{
ref byte p = ref MemoryMarshal.GetReference(buffer);
ulong n = (ulong)((value << 1) ^ (value >> 63));
while ((n & ~0x7FUL) != 0)
{
Unsafe.WriteUnaligned(ref p, (byte)((n & 0x7f) | 0x80));
p = ref Unsafe.Add(ref p, 1);
n >>= 7;
}
Unsafe.WriteUnaligned(ref p, (byte)n);
}
Fixed-length is, in other words, writing out C# memory as is (zero encoding), and it is obvious that fixed-length is faster.
This is even more pronounced when applied to arrays.
// https://sharplab.io/
Inspect.Heap(new int[]{ 1, 2, 3, 4, 5 });

In an array of structs in C#, the data is arranged in series. If the struct does not have a reference type (unmanaged type), then the data is completely aligned in memory; let’s compare the serialization process in code with MessagePack and MemoryPack.
// Fixed-length(MemoryPack)
void Serialize(int[] value)
{
// Size can be calculated and allocate in advance
var size = (sizeof(int) * value.Length) + 4;
EnsureCapacity(size);
// MemoryCopy once
MemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer);
}
// Variable-length(MessagePack)合
void Serialize(int[] value)
{
foreach (var item in value)
{
// Unknown size, so check size each times
EnsureCapacity(); // if (buffer.Length < writeLength) Resize();
// Variable length encoding per element
WriteVarInt32(item);
}
}
In the case of fixed length, it is possible to eliminate many method calls and have only a single memory copy.
Arrays in C# are not only primitive types like int, this is also true for structs with multiple primitives, for example, a Vector3 array with (float x, float y, float z) would have the following memory layout.

A float (4 bytes) is a fixed length of 5 bytes in MessagePack. The additional 1 byte is prefixed by an identifier indicating what type the value is (Int, Float, String…). Specifically, [0xca, x, x, x, x, x]. The MemoryPack format has no identifier, so 4 bytes are written as is.
Consider Vector3[10000], which was 50 times better than the benchmark.
// these fields exists in type
// byte[] buffer
// int offset
void SerializeMemoryPack(Vector3[] value)
{
// only do copy once
var size = Unsafe.SizeOf<Vector3>() * value.Length;
if ((buffer.Length - offset) < size)
{
Array.Resize(ref buffer, buffer.Length * 2);
}
MemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer.AsSpan(0, offset))
}
void SerializeMessagePack(Vector3[] value)
{
// Repeat for array length x number of fields
foreach (var item in value)
{
// X
{
// EnsureCapacity
// (Actually, create buffer-linked-list with bufferWriter.Advance, not Resize)
if ((buffer.Length - offset) < 5)
{
Array.Resize(ref buffer, buffer.Length * 2);
}
var p = MemoryMarshal.GetArrayDataReference(buffer);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.X);
offset += 5;
}
// Y
{
if ((buffer.Length - offset) < 5)
{
Array.Resize(ref buffer, buffer.Length * 2);
}
var p = MemoryMarshal.GetArrayDataReference(buffer);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.Y);
offset += 5;
}
// Z
{
if ((buffer.Length - offset) < 5)
{
Array.Resize(ref buffer, buffer.Length * 2);
}
var p = MemoryMarshal.GetArrayDataReference(buffer);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.Z);
offset += 5;
}
}
}
With MessagePack, it takes 30000 method calls. Within that method, it checks to see if there is enough memory to write and adds an offset each time it finishes writing.
With MemoryPack, only a single memory copy. This would literally change the processing time by an order of magnitude and is the reason for the 50x~100x speedup in the graph at the beginning of this article.
Of course, the deserialization process is also a single copy.
// Deserialize of MemoryPack, only copy
Vector3[] DeserializeMemoryPack(ReadOnlySpan<byte> buffer, int size)
{
var dest = new Vector3[size];
MemoryMarshal.Cast<byte, Vector3>(buffer).CopyTo(dest);
return dest;
}
// Require read float many times in loop
Vector3[] DeserializeMessagePack(ReadOnlySpan<byte> buffer, int size)
{
var dest = new Vector3[size];
for (int i = 0; i < size; i++)
{
var x = ReadSingle(buffer);
buffer = buffer.Slice(5);
var y = ReadSingle(buffer);
buffer = buffer.Slice(5);
var z = ReadSingle(buffer);
buffer = buffer.Slice(5);
dest[i] = new Vector3(x, y, z);
}
return dest;
}
This is a limitation of the MessagePack format itself, and as long as the specification is followed, the overwhelming difference in speed cannot be reversed in any way. However, MessagePack has a specification called “ext format family” that allows for special handling of these arrays as part of its own specification. In fact, MessagePack for C# had a special extension option for Unity called UnsafeBlitResolver that does the above.
However, most people probably don’t use it, and no one would use a proprietary option that would make MessagePack incompatible.
So with MemoryPack, I wanted a specification that would give the best performance as C# by default.
String Optimization
MemoryPack has two specifications for String: UTF8 or UTF16. since C# string is UTF16, serializing it as UTF16 saves the cost of encoding/decoding to UTF8.
void EncodeUtf16(string value)
{
var size = value.Length * 2;
EnsureCapacity(size);
// Span<char> -> Span<byte> -> Copy
MemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer);
}
string DecodeUtf16(ReadOnlySpan<byte> buffer, int length)
{
ReadOnlySpan<char> src = MemoryMarshal.Cast<byte, char>(buffer).Slice(0, length);
return new string(src);
}
However, MemoryPack defaults to UTF8. This is because of the payload size issue; with UTF16, ASCII characters would be twice as large, so UTF8 was chosen.
However, even with UTF8, MemoryPack has some optimizations that other serializers do not.
// fast
void WriteUtf8MemoryPack(string value)
{
var source = value.AsSpan();
var maxByteCount = (source.Length + 1) * 3;
EnsureCapacity(maxByteCount);
Utf8.FromUtf16(source, dest, out var _, out var bytesWritten, replaceInvalidSequences: false);
}
// slow
void WriteUtf8StandardSerializer(string value)
{
var maxByteCount = Encoding.UTF8.GetByteCount(value);
EnsureCapacity(maxByteCount);
Encoding.UTF8.GetBytes(value, dest);
}
var bytes = Encoding.UTF8.GetBytes(value) is an absolute no-no, byte[] allocations are not allowed in string writing. Many serializers use Encoding.UTF8.GetByteCount, but also should avoid it, because UTF8 is a variable-length encoding and GetByteCount traverses the string completely to calculate the exact post-encoding size. That is, GetByteCount -> GetBytes traverses the string twice.
Usually, serializers are allowed to reserve a generous buffer. Therefore, MemoryPack allocates three times the length of the string, which is the worst case for UTF8 encoding, to avoid double traversal.
In the case of decoding, further special optimizations are applied.
// fast
string ReadUtf8MemoryPack(int utf16Length, int utf8Length)
{
unsafe
{
fixed (byte* p = &buffer)
{
return string.Create(utf16Length, ((IntPtr)p, utf8Length), static (dest, state) =>
{
var src = MemoryMarshal.CreateSpan(ref Unsafe.AsRef<byte>((byte*)state.Item1), state.Item2);
Utf8.ToUtf16(src, dest, out var bytesRead, out var charsWritten, replaceInvalidSequences: false);
});
}
}
}
// slow
string ReadStandardSerialzier(int utf8Length)
{
return Encoding.UTF8.GetString(buffer.AsSpan(0, utf8Length));
}
Normally, to get a string out of a byte[], you would use Encoding.UTF8.GetString(buffer). But again, UTF8 is a variable-length encoding, and we don’t know the length of UTF16 from it. So with UTF8.GetString, we need to calculate the length as UTF16 to convert it to string, so we are scanning the string twice inside. In pseudo-code, it is
var length = CalcUtf16Length(utf8data);
var str = String.Create(length);
Encoding.Utf8.DecodeToString(utf8data, str);
The string format of a typical serializer is UTF8, which is not decodable to UTF16, so even if you want a length of UTF16 for efficient decoding as a C# string, it is not in the data.
However, MemoryPack records both UTF16-Length and UTF8-Length in the header. Therefore, the combination of String.Create<TState>(Int32, TState, SpanAction<Char,TState>) and Utf8.ToUtf16 provides the most efficient decoding to C# String.
About the payload size
Fixed-length encoding of integers may be inflated in size compared to variable-length encoding. However, in the modern era, using variable-length encoding just to reduce the small size of integers is more of a disadvantage.
Since the data is not only integers, if you really want to reduce the size, you should consider compression (LZ4, ZStandard, Brotli, etc.), and if you compress the data, there is almost no point in variable-length encoding. If you want to be more specialized and smaller, column-oriented compression will give you greater results (e.g., Apache Parquet).
For efficient compression integrated with the MemoryPack implementation, I currently have auxiliary classes for BrotliEncode/Decode as standard.
I also have several attributes that apply special compression to certain primitive columns, such as column compression.
[MemoryPackable]
public partial class Sample
{
public int Id { get; set; }
[BitPackFormatter]
public bool[] Data { get; set; }
[BrotliFormatter]
public byte[] Payload { get; set; }
}
BitPackFormatter is for bool[], bool is normally 1 byte, but since it is treated as 1bit, eight bools are stored in one byte. Therefore, the size after serialization is 1/8.
BrotliFormatter directly applies the compression algorithm. This actually performs better than compressing the entire file.
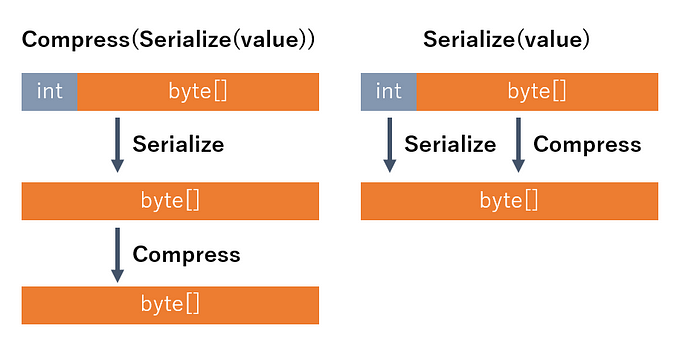
This is because no intermediate copy is needed and the compression process can be applied directly to the serialized data.
The method of extracting performance and compression ratio by applying processing in a custom way depending on the data, rather than simple overall compression, is detailed in Reducing Logging Cost by Two Orders of Magnitude using CLP article on the Uber Engineering Blog.
Using .NET 7 / C#11 new features
MemoryPack has slightly different method signatures in the implementation for .NET Standard 2.1 and the implementation for .NET 7. .NET 7 is a more aggressive, performance-oriented implementation that takes advantage of the latest language features.
First, the serializer interface utilizes static abstract members as follows
public interface IMemoryPackable<T>
{
// note: serialize parameter should be `ref readonly` but current lang spec can not.
// see proposal https://github.com/dotnet/csharplang/issues/6010
static abstract void Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref T? value)
where TBufferWriter : IBufferWriter<byte>;
static abstract void Deserialize(ref MemoryPackReader reader, scoped ref T? value);
}
MemoryPack adopts a Source Generator and requires that the target type be [MemoryPackable]public partial class Foo, so the final target type is
[MemortyPackable]
partial class Foo : IMemoryPackable
{
static void IMemoryPackable<Foo>.Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref Foo? value)
{
}
static void IMemoryPackable<Foo>.Deserialize(ref MemoryPackReader reader, scoped ref Foo? value)
{
}
}
This avoids the cost of invoking via virtual methods.
public void WritePackable<T>(scoped in T? value)
where T : IMemoryPackable<T>
{
// If T is IMemoryPackable, call static method directly
T.Serialize(ref this, ref Unsafe.AsRef(value));
}
//
public void WriteValue<T>(scoped in T? value)
{
// call Serialize from interface virtual method
IMemoryPackFormatter<T> formatter = MemoryPackFormatterProvider.GetFormatter<T>();
formatter.Serialize(ref this, ref Unsafe.AsRef(value));
}
MemoryPackWriter/MemoryPackReader makes use of the ref field.
public ref struct MemoryPackWriter<TBufferWriter>
where TBufferWriter : IBufferWriter<byte>
{
ref TBufferWriter bufferWriter;
ref byte bufferReference;
int bufferLength;
The combination of ref byte bufferReference, int bufferLength is, in other words, an inlining of Span<byte>. Also, by accepting TBufferWriter as ref TBufferWriter, the mutable struct TBufferWriter : IBufferWrite<byte> can now be safely accepted and called.
// internally MemoryPack uses some struct buffer-writers
struct BrotliCompressor : IBufferWriter<byte>
struct FixedArrayBufferWriter : IBufferWriter<byte>
Optimize for all types
For example, collections can be serialized/deserialized as IEnumerable<T> for a common implementation, but MemoryPack provides a separate implementation for all types. For simplicity, a List<T> can be processed as
public void Serialize(ref MemoryPackWriter writer, IEnumerable<T> value)
{
foreach(var item in source)
{
writer.WriteValue(item);
}
}
public void Serialize(ref MemoryPackWriter writer, List<T> value)
{
foreach(var item in source)
{
writer.WriteValue(item);
}
}
The two codes look the same but perform quite differently: foreach to IEnumerable<T> retrieves IEnumerator<T>, while foreach to List<T> retrieves struct List<T>.Enumerator, an optimized and dedicated structure.
However, MemoryPack has further optimized it.
public sealed class ListFormatter<T> : MemoryPackFormatter<List<T?>>
{
public override void Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref List<T?>? value)
{
if (value == null)
{
writer.WriteNullCollectionHeader();
return;
}
writer.WriteSpan(CollectionsMarshal.AsSpan(value));
}
}
// MemoryPackWriter.WriteSpan
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void WriteSpan<T>(scoped Span<T?> value)
{
if (!RuntimeHelpers.IsReferenceOrContainsReferences<T>())
{
DangerousWriteUnmanagedSpan(value);
return;
}
var formatter = GetFormatter<T>();
WriteCollectionHeader(value.Length);
for (int i = 0; i < value.Length; i++)
{
formatter.Serialize(ref this, ref value[i]);
}
}
// MemoryPackWriter.DangerousWriteUnmanagedSpan
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void DangerousWriteUnmanagedSpan<T>(scoped Span<T> value)
{
if (value.Length == 0)
{
WriteCollectionHeader(0);
return;
}
var srcLength = Unsafe.SizeOf<T>() * value.Length;
var allocSize = srcLength + 4;
ref var dest = ref GetSpanReference(allocSize);
ref var src = ref Unsafe.As<T, byte>(ref MemoryMarshal.GetReference(value));
Unsafe.WriteUnaligned(ref dest, value.Length);
Unsafe.CopyBlockUnaligned(ref Unsafe.Add(ref dest, 4), ref src, (uint)srcLength);
Advance(allocSize);
}
CollectionsMarshal.AsSpan from .NET 5 is the best way to enumerate List<T>. Furthermore, if Span<T> can be obtained, it can be handled by copying only in the case of List<int> or List<Vector3>.
In the case of Deserialize, there are some interesting optimizations as well. First, MemoryPack’s Deserialize accepts a ref T? value, and if the value is null, it will overwrite the internally generated object (just like a normal serializer), if the value is passed. This allows for zero allocation of new object creation during Deserialize. Collections are also reused by calling Clear() in the case of List<T>.
Then, by making a special Span call, it is all handled as Spans, avoiding the additional overhead of List<T>.Add.
public sealed class ListFormatter<T> : MemoryPackFormatter<List<T?>>
{
public override void Deserialize(ref MemoryPackReader reader, scoped ref List<T?>? value)
{
if (!reader.TryReadCollectionHeader(out var length))
{
value = null;
return;
}
if (value == null)
{
value = new List<T?>(length);
}
else if (value.Count == length)
{
value.Clear();
}
var span = CollectionsMarshalEx.CreateSpan(value, length);
reader.ReadSpanWithoutReadLengthHeader(length, ref span);
}
}
internal static class CollectionsMarshalEx
{
/// <summary>
/// similar as AsSpan but modify size to create fixed-size span.
/// </summary>
public static Span<T?> CreateSpan<T>(List<T?> list, int length)
{
list.EnsureCapacity(length);
ref var view = ref Unsafe.As<List<T?>, ListView<T?>>(ref list);
view._size = length;
return view._items.AsSpan(0, length);
}
// NOTE: These structure depndent on .NET 7, if changed, require to keep same structure.
internal sealed class ListView<T>
{
public T[] _items;
public int _size;
public int _version;
}
}
// MemoryPackReader.ReadSpanWithoutReadLengthHeader
public void ReadSpanWithoutReadLengthHeader<T>(int length, scoped ref Span<T?> value)
{
if (length == 0)
{
value = Array.Empty<T>();
return;
}
if (!RuntimeHelpers.IsReferenceOrContainsReferences<T>())
{
if (value.Length != length)
{
value = AllocateUninitializedArray<T>(length);
}
var byteCount = length * Unsafe.SizeOf<T>();
ref var src = ref GetSpanReference(byteCount);
ref var dest = ref Unsafe.As<T, byte>(ref MemoryMarshal.GetReference(value)!);
Unsafe.CopyBlockUnaligned(ref dest, ref src, (uint)byteCount);
Advance(byteCount);
}
else
{
if (value.Length != length)
{
value = new T[length];
}
var formatter = GetFormatter<T>();
for (int i = 0; i < length; i++)
{
formatter.Deserialize(ref this, ref value[i]);
}
}
}
EnsurceCapacity(capacity), it is possible to pre-expand the size of the internal array that holds the List<T>. This avoids the need for internal enlargement/copying each time.
But CollectionsMarshal.AsSpan, you will get a span of length 0, because the internal size is not changed. If we had CollectionMarshals.AsMemory, we could get the raw array from there with a MemoryMarshal.TryGetArray combo, but unfortunately there is no way to get the original array from the Span. So, I force the type structure to match with Unsafe.As and change List<T>._size, I was able to get the expanded internal array.
That way, we could optimize the unmanaged type to just copy it, and avoid List<T>.Add (which checks the array size each time), and pack the values via Span<T>[index], which is much higher than the deserialization of a conventional serializer. performance.
While the optimization to List<T> is representative, there are too many others to introduce, all types have been scrutinized and the best possible optimization has been applied to each.
Serialize accepts IBufferWriter<byte> as its native structure and Deserialize accepts ReadOnlySpan<byte> and ReadOnlySequence<byte>.
This is because these types are required by System.IO.Pipelines. In other words, since it is the foundation of ASP .NET Core’s Server (Kestrel), you can expect higher performance serialization by connecting directly to it.
IBufferWriter<byte> is particularly important because it can write directly to the buffer, thus achieving zero-copy in the serialization process. Support for IBufferWriter<byte> is a prerequisite for modern serializers, as it offers higher performance than using byte[] or Stream. Serializer for the graph at the beginning (System.Text.Json, protobuf-net, Microsoft.Orleans.Serialization, MessagePack for C#, and MemoryPack) supports it.
MessagePack vs MemoryPack
MessagePack for C# is very easy to use and has excellent performance. In particular, the following points are better than MemoryPack
- Excellent inter-language compatibility
- JSON compatibility (especially for string keys) and human readability
- Perfect version tolerant by default
- Serialization of object and anonymous types
- dynamic deserialization
- embeded LZ4 compression
- Long proven stability
MemoryPack defaults to limited version tolerant, and the full version tolerant option is slightly less performant. Also, because it is a original format, the only other language supported is TypeScript. Also, the binary itself does not tell what data it is because it requires a C# schema.
However, it is superior to MessagePack in the following ways
- Performance, especially for unmanaged type arrays
- Easy to use AOT support
- Extended Polymorphism (Union) construction method
- Support for circular references
- Overwrite deserialization
- TypeScript code generation
- Flexible attribute-based custom formatter
In my personal opinion, if you are in a C#-only environment, I would choose MemoryPack. However, limited version-tolerant has its quirks and should be well understood beforehand. MessagePack for C# remains a good choice because it is straightforward and easy to use.
MemoryPack is not an experimental serializer that only focuses on performance, but is also intended to be a practical serializer. To this end, I have also built on my experience with MessagePack for C# to provide a number of features.
- Support modern I/O APIs(`IBufferWriter<byte>`, `ReadOnlySpan<byte>`, `ReadOnlySequence<byte>`)
- Native AOT friendly Source Generator based code generation, no Dynamic CodeGen(IL.Emit)
- Reflectionless non-generics APIs
- Deserialize into existing instance
- Polymorphism(Union) serialization
- limited version-tolerant(fast/default) and full version-tolerant support
- Circular reference serialization
- PipeWriter/Reader based streaming serialization
- TypeScript code generation and ASP.NET Core Formatter
- Unity(2021.3) IL2CPP Support via .NET Source Generator
We are planning to further expand the range of available features such as MemoryPack support for MasterMemory and serializer change support for MagicOnion, etc. We position ourselves as the core of Cysharp’s C# library ecosystem. We’re going to put a lot of effort into growing this thing, so for starters, please give it a try!
Recommend
-
92
Utf8Json - Fast JSON Serializer for C# Definitely Fastest and Zero Allocation JSON Serializer for C#(.NET, .NET Core, Unity and Xamarin), this serializer write/read directly to UTF8 binary so boostup performance. And I adopt the same arch...
-
84
fast_jsonapi - A lightning fast JSON:API serializer for Ruby Objects.
-
64
The Symfony Serializer Component exists since the very beginning of Symfony 2. Years after years, it gained a lot of new features useful to transform various data formats to PHP structures and the opposite. It is also a foundation block of API P...
-
52
After more than a two years of work, jms/serializer v2.0 is going to see the light. Here a preview of the changes, new features and improvements that will be released soon.
-
59
README.md jms/serialzer Master 1.x
-
54
README.md Liip Serializer - A "drop in" replacement to JMS serializer This project is Open Sourced based on work that we did initially as close...
-
48
r/javascript: All about the JavaScript programming language!
-
66
An Extensive Kotlinx Serializer Library For Serialization
-
2
使用.NET7和C#11打造最快的序列化程序-以MemoryPack为例
-
2
What Is the Fastest Programming Language? Making the Case for Elixir As turnaround times continue to shrink and the innovation expected from developers expands, programming language speeds can...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK