

用Python库BeautifulSoup来读取广东疫情近期数据并存在csv上
source link: https://www.pkslow.com/archives/python-bs4-csv
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

之前用代码做了个广东疫情新增病例的视频,具体可查看《用Python做了一个广东疫情新增病例动态视频》,但当时是手动去网站找数据然后输入到Excel的,这对于一个程序员来说显然是不可接受的:
- 手工容易出错;
- 时间成本高;
- Excel要钱。
因此,我决定写个代码,自动读取数据并存在csv文件中。
2 获取超链接
首先我们到官网查看内容展示:

它是一天一个报告,并没有整合,所以必要读取该网页的内容,获取所有相关的超链接。并且要解析出对应的日期,方便以后使用。代码如下:
def fetch_links():
url = "http://wsjkw.gd.gov.cn/xxgzbdfk/"
req = requests.get(url)
soup = BeautifulSoup(req.content, 'lxml')
links = soup.findAll('a')
valid_links_filter = filter(lambda item: 'title' in item.attrs and '广东省新冠肺炎疫情情况' in item.attrs['title'],
links)
valid_links = list(valid_links_filter)
return valid_links
首先使用requests库读取网页内容,然后通过BeautifulSoup加载,获取所有超链接<a/>。因为整个网站的超链接很多,需要做一个过滤,通过一个filter,把关键字过滤出来即可。
3 获取文本内容
通过上面的方法找到每天的网页后,就需要把报告的内容提取出来,还是先来分析一下网页:

通过查看并分析,图片文中的第一段是我们需要的,它可能是在<p>中或<span>中。一样是通过关键字来匹配获取:
def fetch_content(url):
req = requests.get(url)
soup = BeautifulSoup(req.content, 'lxml')
ps = soup.findAll('p')
valid_ps_filter = filter(lambda item: '全省新增本土确诊病例' in item.text,
ps)
valid_ps = list(valid_ps_filter)
if not valid_ps:
ps = soup.findAll('span')
valid_ps_filter = filter(lambda item: '全省新增本土确诊病例' in item.text,
ps)
valid_ps = list(valid_ps_filter)
valid_p = valid_ps[0]
return valid_p.text
解析出数据
获取到文本内容后,它是一段文字,我们需要从中获取到新增数字,这里使用的是正则的办法,直接上代码吧:
def parse_data(str):
confirm_str = re.search('全省新增本土确诊病例\\d+例', str)
confirm_str = re.search('\\d+', confirm_str.group())
confirm_gd = int(confirm_str.group())
asymptomatic_str = re.search('新增本土无症状感染者\\d+例', str)
asymptomatic_str = re.search('\\d+', asymptomatic_str.group())
asymptomatic_gd = int(asymptomatic_str.group())
gz_strs = re.findall('广州\\d+例', str)
gz_str = re.search('\\d+', gz_strs[0])
confirm_gz = int(gz_str.group())
gz_str = re.search('\\d+', gz_strs[1])
asymptomatic_gz = int(gz_str.group())
return confirm_gd, confirm_gz, asymptomatic_gd, asymptomatic_gz
5 保存数据
拿到数据后,就需要保存起来日后使用。但已经获取过的数据,其实是没有必要再次获取的,所以我们写文件前要做一个判断。要先读文件,然后判断某天数据是否已经存在,如果不存在则需要获取并保存,否则跳过。
读取的函数如下:
def read_data_from_csv(file_name):
data_store = []
with open(file_name) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
line_count = 0
for row in csv_reader:
if line_count == 0:
print(f'Column names are {", ".join(row)}')
line_count += 1
else:
data_store.append(row)
print(f'{row[0]}, {row[1]}, {row[2]}, {row[3]}, {row[4]}')
line_count += 1
print(f'Read {line_count} lines.')
return data_store
判断是否存在:
def is_exist(data_store, date):
already_exist = False
for row in data_store:
if row[0] == date:
return True
return already_exist
最后,写文件和其它函数整合在一起如下:
if __name__ == '__main__':
data_store = read_data_from_csv('covid-19.csv')
valid_links = fetch_links()
valid_links.reverse()
with open('covid-19.csv', 'a') as covid_file:
covid_writer = csv.writer(covid_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
for link in valid_links:
date = link.nextSibling.text
if is_exist(data_store, date):
continue
content = fetch_content(link.attrs['href'])
confirm_gd, confirm_gz, asymptomatic_gd, asymptomatic_gz = parse_data(content)
covid_writer.writerow([link.nextSibling.text, confirm_gd, confirm_gz, asymptomatic_gd, asymptomatic_gz])
结果如下:
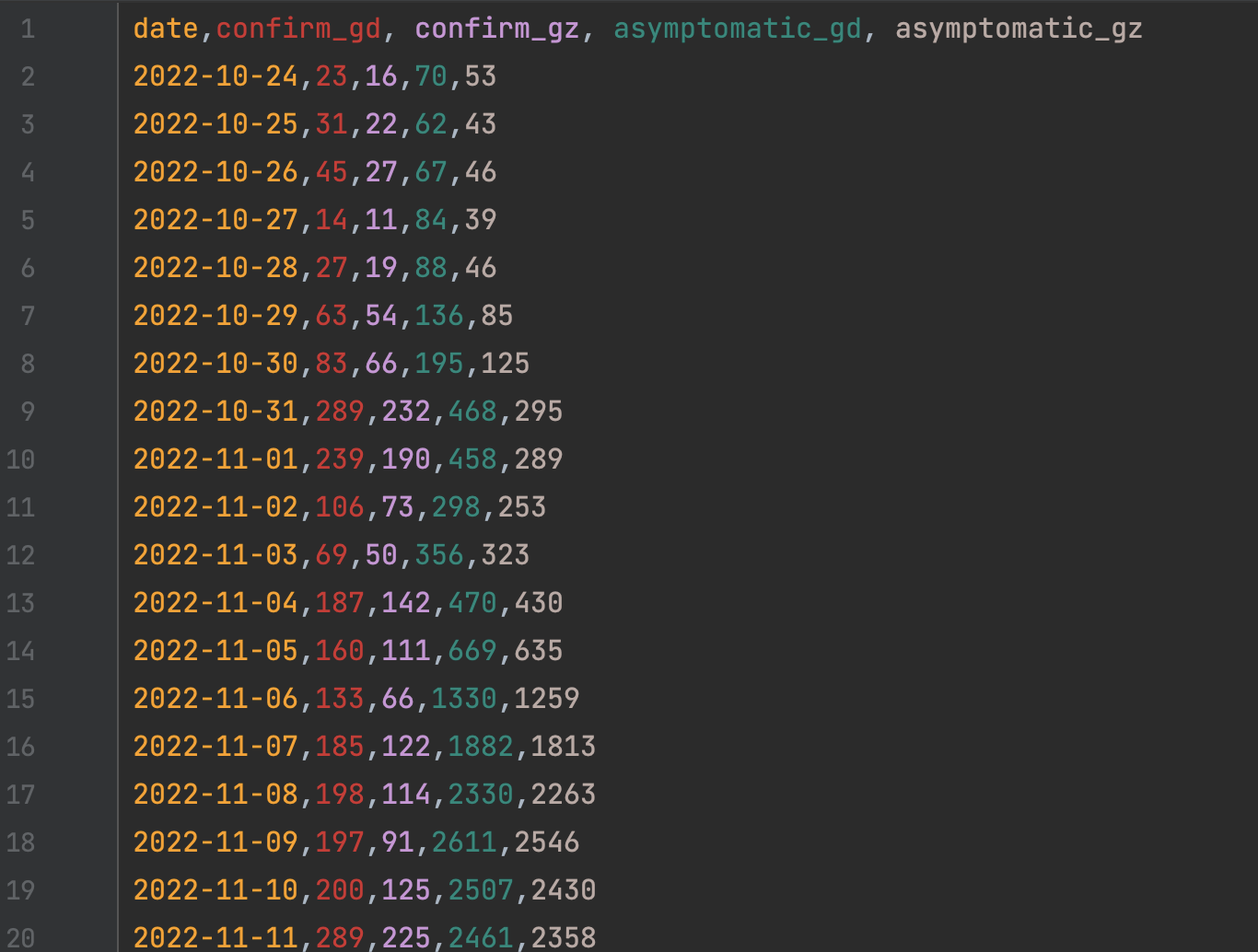
愿大家健康快乐!
代码请看GitHub: https://github.com/LarryDpk/pkslow-samples/tree/master/python
References:
https://docs.python.org/3/library/csv.html
https://realpython.com/python-csv/
BS4: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Libs:
$ pip3 show beautifulsoup4
Name: beautifulsoup4
Version: 4.11.1
Summary: Screen-scraping library
Home-page: https://www.crummy.com/software/BeautifulSoup/bs4/
Author: Leonard Richardson
Author-email: [email protected]
License: MIT
Location: /usr/local/lib/python3.9/site-packages
Requires: soupsieve
Required-by:
$ pip3 show lxml
Name: lxml
Version: 4.9.1
Summary: Powerful and Pythonic XML processing library combining libxml2/libxslt with the ElementTree API.
Home-page: https://lxml.de/
Author: lxml dev team
Author-email: [email protected]
License: BSD
Location: /usr/local/lib/python3.9/site-packages
Requires:
Required-by:
$ pip3 show requests
Name: requests
Version: 2.28.1
Summary: Python HTTP for Humans.
Home-page: https://requests.readthedocs.io
Author: Kenneth Reitz
Author-email: [email protected]
License: Apache 2.0
Location: /usr/local/lib/python3.9/site-packages
Requires: certifi, charset-normalizer, idna, urllib3
Required-by:
Code for all: GitHub
欢迎关注微信公众号<南瓜慢说>,将持续为你更新...

Recommendations:
Cloud Native
Terraform
Container: Docker/Kubernetes
Spring Boot / Spring Cloud
Https
如何制定切实可行的计划并好好执行
</div
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK