

Explaining modern server monitoring stacks for self-hosting
source link: https://dataswamp.org/~solene/2022-09-11-exploring-monitoring-stacks.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

About me: My name is Solène Rapenne, pronouns she/her. I like learning and sharing knowledge. Hobbies: '(BSD OpenBSD Lisp cmdline gaming internet-stuff). I love percent and lambda characters. OpenBSD developer solene@.
Contact me: solene on libera.chat, solene+www at dataswamp dot org or @[email protected] (mastodon). If for some reason you want to support my work, this is my paypal address: [email protected].
!/bin/introduction §
Hello 👋🏻, it's been a long time I didn't have to take a look at monitoring servers. I've set up a Grafana server six years ago, and I was using Munin for my personal servers.
However, I recently moved my server to a small virtual machine which has CPU and memory constraints (1 core / 1 GB of memory), and Munin didn't work very well. I was curious to learn if the Grafana stack changed since the last time I used it, and YES.
There is that project named Prometheus which is used absolutely everywhere, it was time for me to learn about it. And as I like to go against the flow, I tried various changes to the industry standard stack by using VictoriaMetrics.
In this article, I'm using NixOS configuration for the examples, however it should be obvious enough that you can still understand the parts if you don't know anything about NixOS.
The components §
VictoriaMetrics is a Prometheus drop-in replacement that is a lot more efficient (faster and use less resources), which also provides various API such as Graphite or InfluxDB. It's the component storing data. It comes with various programs like VictoriaMetrics agent to replace various parts of Prometheus.
VictoriaMetrics official website
Prometheus is a time series database, which also provide a collecting agent named Node Exporter. It's also able to pull (scrape) data from remote services offering a Prometheus API.
NixOS is an operating system built with the Nix package manager, it has a declarative approach that requires to reconfigure the system when you need to make a change.
Collectd is a agent gathering metrics from the system and sending it to a remote compatible database.
Grafana is a powerful Web interface pulling data from time series databases to render them under useful charts for analysis.
Node exporter full Grafana dashboard
Setup 1: Prometheus server scraping remote node_exporter §
In this setup, a Prometheus server is running on a server along with Grafana, and connects to remote servers running node_exporter to gather data.
Running it on my server, Grafana takes 67 MB, the local node_exporter 12.5 MB and Prometheus 63 MB.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
grafana 837975 0.1 6.7 1384152 67836 ? Ssl 01:19 1:07 grafana-server
node-ex+ 953784 0.0 1.2 941292 12512 ? Ssl 16:24 0:01 node_exporter
prometh+ 983975 0.3 6.3 1226012 63284 ? Ssl 17:07 0:00 prometheus
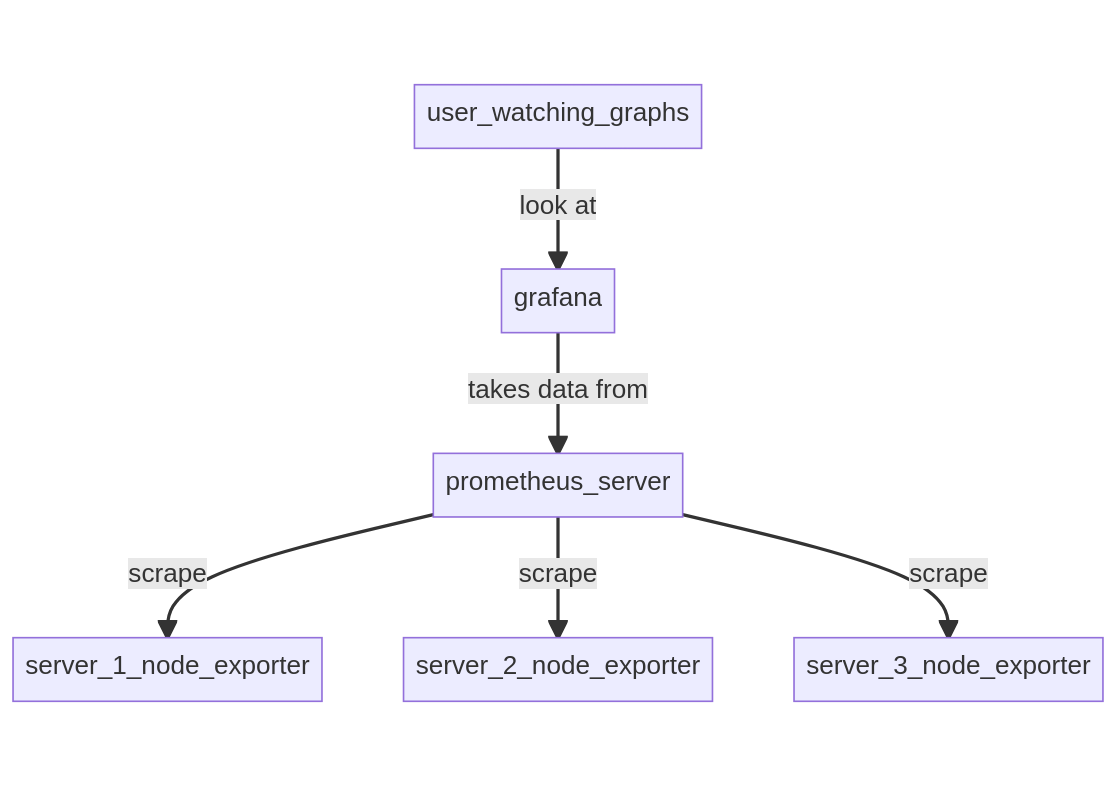
- model: pull, Prometheus is connecting to all servers
Pros §
- it's the industry standard
- can use the "node exporter full" Grafana dashboard
Cons §
- uses memory
- you need to be able to reach all the remote nodes
Server §
{
services.grafana.enable = true;
services.prometheus.exporters.node.enable = true;
services.prometheus = {
enable = true;
scrapeConfigs = [
{
job_name = "kikimora";
static_configs = [
{targets = ["10.43.43.2:9100"];}
];
}
{
job_name = "interbus";
static_configs = [
{targets = ["127.0.0.1:9100"];}
];
}
];
};
}
Client §
{
networking.firewall.allowedTCPPorts = [9100];
services.prometheus.exporters.node.enable = true;
}
Setup 2: VictoriaMetrics + node-exporter in pull model §
In this setup, a VictoriaMetrics server is running on a server along with Grafana. A VictoriaMetrics agent is running locally to gather data from remote servers running node_exporter.
Running it on my server, Grafana takes 67 MB, the local node_exporter 12.5 MB, VictoriaMetrics 30 MB and its agent 13.8 MB.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
grafana 837975 0.1 6.7 1384152 67836 ? Ssl 01:19 1:07 grafana-server
node-ex+ 953784 0.0 1.2 941292 12512 ? Ssl 16:24 0:01 node_exporter
victori+ 986126 0.1 3.0 1287016 30052 ? Ssl 18:00 0:03 victoria-metric
root 987944 0.0 1.3 1086276 13856 ? Sl 18:30 0:00 vmagent
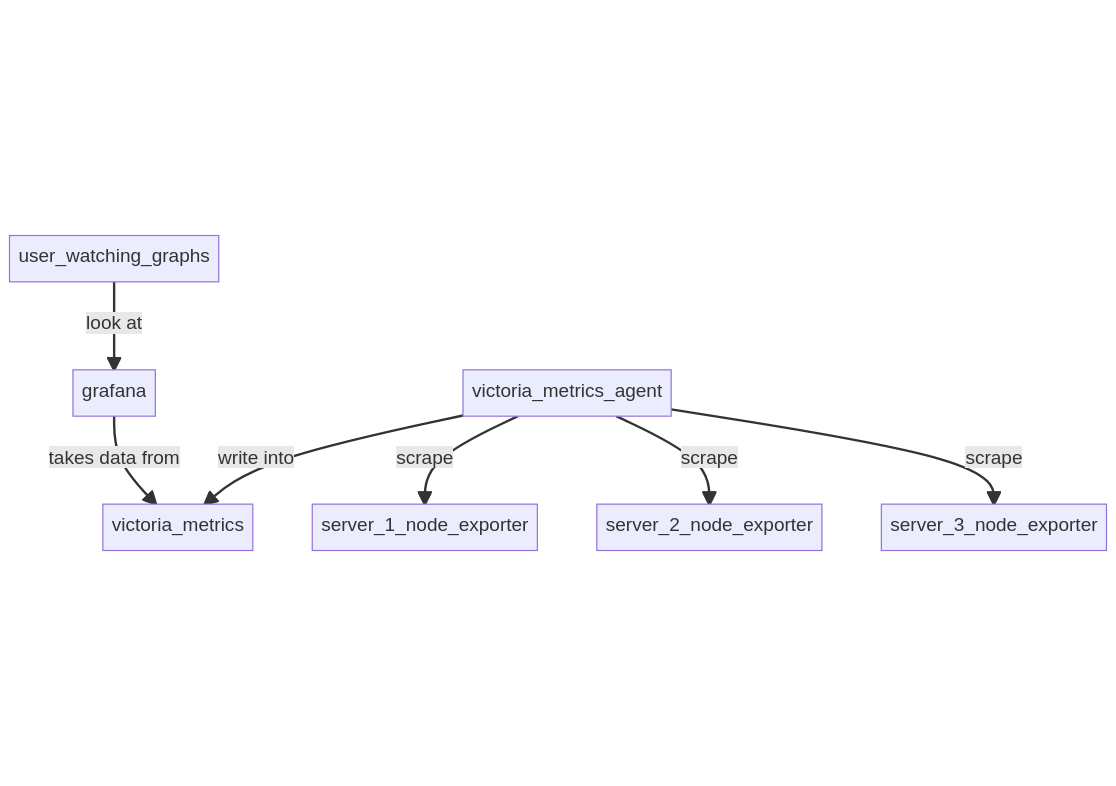
- model: pull, VictoriaMetrics agent is connecting to all servers
Pros §
- can use the "node exporter full" Grafana dashboard
- lightweight and more performant than Prometheus
Cons §
- you need to be able to reach all the remote nodes
Server §
let
configure_prom = builtins.toFile "prometheus.yml" ''
scrape_configs:
- job_name: 'kikimora'
stream_parse: true
static_configs:
- targets:
- 10.43.43.1:9100
- job_name: 'interbus'
stream_parse: true
static_configs:
- targets:
- 127.0.0.1:9100
'';
in {
services.victoriametrics.enable = true;
services.grafana.enable = true;
systemd.services.export-to-prometheus = {
path = with pkgs; [victoriametrics];
enable = true;
after = ["network-online.target"];
wantedBy = ["multi-user.target"];
script = "vmagent -promscrape.config=${configure_prom} -remoteWrite.url=http://127.0.0.1:8428/api/v1/write";
};
}
Client §
{
networking.firewall.allowedTCPPorts = [9100];
services.prometheus.exporters.node.enable = true;
}
Setup 3: VictoriaMetrics + node-exporter in push model §
In this setup, a VictoriaMetrics server is running on a server along with Grafana, on each server node_exporter and VictoriaMetrics agent are running to export data to the central VictoriaMetrics server.
Running it on my server, Grafana takes 67 MB, the local node_exporter 12.5 MB, VictoriaMetrics 30 MB and its agent 13.8 MB, which is exactly the same as the setup 2, except the VictoriaMetrics agent is running on all remote servers.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
grafana 837975 0.1 6.7 1384152 67836 ? Ssl 01:19 1:07 grafana-server
node-ex+ 953784 0.0 1.2 941292 12512 ? Ssl 16:24 0:01 node_exporter
victori+ 986126 0.1 3.0 1287016 30052 ? Ssl 18:00 0:03 victoria-metric
root 987944 0.0 1.3 1086276 13856 ? Sl 18:30 0:00 vmagent
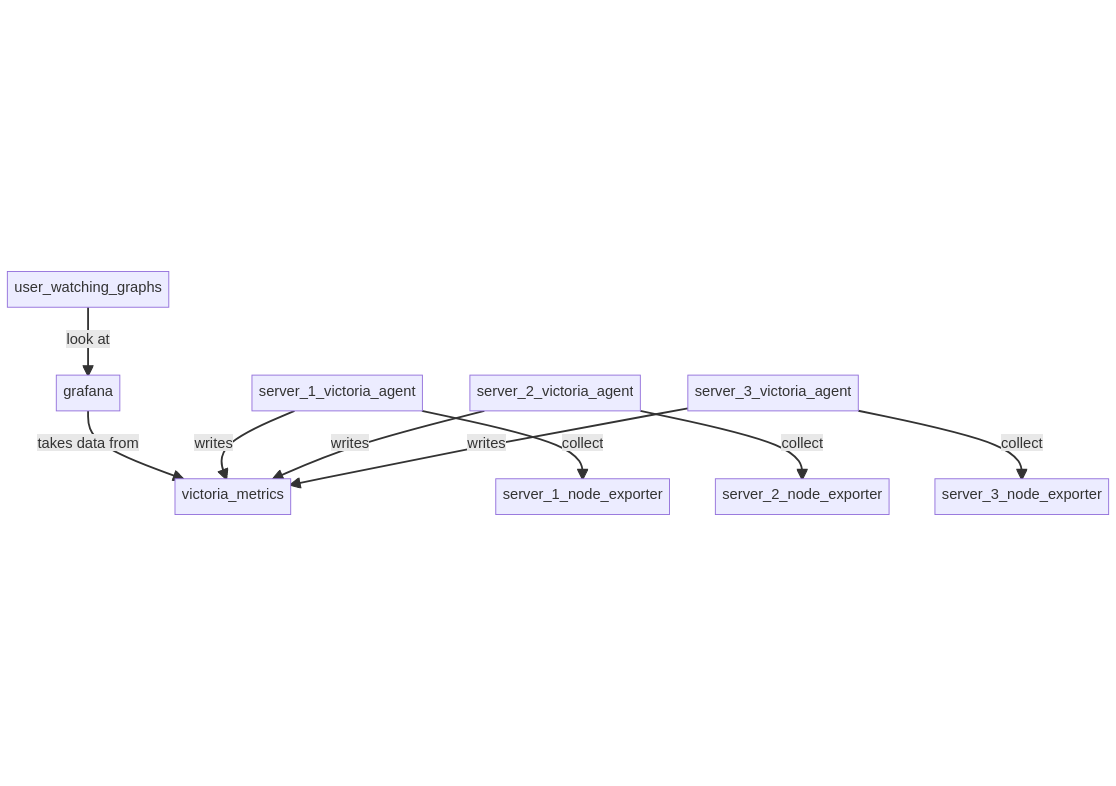
- model: push, each agent is connecting to the VictoriaMetrics server
Pros §
- can use the "node exporter full" Grafana dashboard
- memory efficient
- can bypass firewalls easily
Cons §
- you need to be able to reach all the remote nodes
- more maintenance as you have one extra agent on each remote
- may be bad for security, you need to allow remote servers to write to your VictoriaMetrics server
Server §
{
networking.firewall.allowedTCPPorts = [8428];
services.victoriametrics.enable = true;
services.grafana.enable = true;
services.prometheus.exporters.node.enable = true;
}
Client §
let
configure_prom = builtins.toFile "prometheus.yml" ''
scrape_configs:
- job_name: '${config.networking.hostName}'
stream_parse: true
static_configs:
- targets:
- 127.0.0.1:9100
'';
in {
services.prometheus.exporters.node.enable = true;
systemd.services.export-to-prometheus = {
path = with pkgs; [victoriametrics];
enable = true;
after = ["network-online.target"];
wantedBy = ["multi-user.target"];
script = "vmagent -promscrape.config=${configure_prom} -remoteWrite.url=http://victoria-server.domain:8428/api/v1/write";
};
}
Setup 4: VictoriaMetrics + Collectd §
In this setup, a VictoriaMetrics server is running on a server along with Grafana, servers are running Collectd sending data to VictoriaMetrics graphite API.
Running it on my server, Grafana takes 67 MB, VictoriaMetrics 30 MB and Collectd 172 kB (yes).
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
grafana 837975 0.1 6.7 1384152 67836 ? Ssl 01:19 1:07 grafana-server
victori+ 986126 0.1 3.0 1287016 30052 ? Ssl 18:00 0:03 victoria-metric
collectd 844275 0.0 0.0 610432 172 ? Ssl 02:07 0:00 collectd
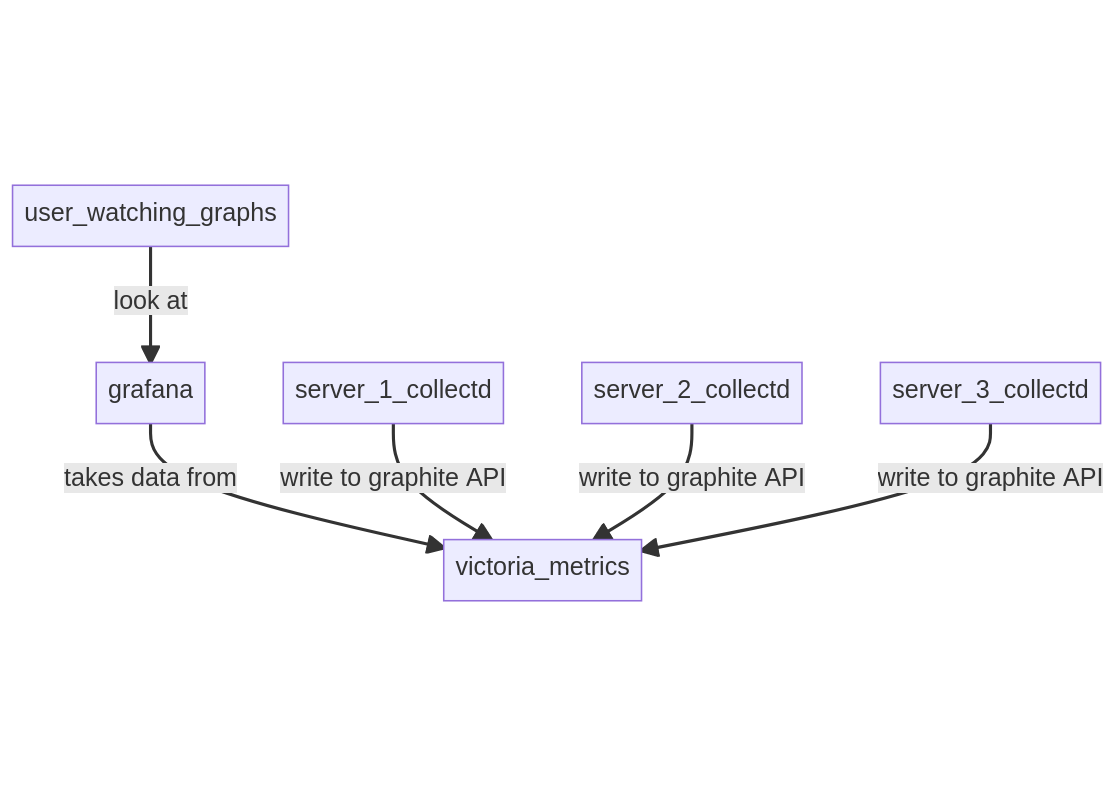
- model: push, VictoriaMetrics receives data from the Collectd servers
Pros §
- super memory efficient
- can bypass firewalls easily
Cons §
- you can't use the "node exporter full" Grafana dashboard
- may be bad for security, you need to allow remote servers to write to your VictoriaMetrics server
- you need to configure Collectd for each host
Server §
The server requires VictoriaMetrics to run exposing its graphite API on ports 2003.
Note that in Grafana, you will have to escape "-" characters using "\-" in the queries. I also didn't find a way to automatically discover hosts in the data to use variables in the dashboard.
UPDATE: Using write_tsdb exporter in collectd, and exposing a TSDB API with VictoriaMetrics, you can set a label to each host, and then use the query "label_values(status)" in Grafana to automatic discover hosts.
{
networking.firewall.allowedTCPPorts = [2003];
services.victoriametrics = {
enable = true;
extraOptions = [
"-graphiteListenAddr=:2003"
];
};
services.grafana.enable = true;
}
Client §
We only need to enable Collectd on the client:
{
services.collectd = {
enable = true;
autoLoadPlugin = true;
extraConfig = ''
Interval 30
'';
plugins = {
"write_graphite" = ''
<Node "${config.networking.hostName}">
Host "victoria-server.fqdn"
Port "2003"
Protocol "tcp"
LogSendErrors true
Prefix "collectd_"
</Node>
'';
cpu = ''
ReportByCpu false
'';
memory = "";
df = ''
Mountpoint "/"
Mountpoint "/nix/store"
Mountpoint "/home"
ValuesPercentage True
ValuesAbsolute False
'';
load = "";
uptime = "";
swap = ''
ReportBytes false
ReportIO false
ValuesPercentage true
'';
interface = ''
ReportInactive false
'';
};
};
}
Trivia §
The first section named #!/bin/introduction" is on purpose and not a mistake. It felt super fun when I started writing the article, and wanted to keep it that way.
The Collectd setup is the most minimalistic while still powerful, but it requires lot of work to make the dashboards and configure the plugins correctly.
The setup I like best is the setup 2.
Recommend
-
69
README.md
-
18
I have to admit, I took my sweet time to write this post and release this tool, but the time has finally come. I am finally ready to publish pwndrop , which has been in development for the last two years...
-
10
So you want to start a blog? And are cheap, lazy, and generally worthless? That makes two of us. At the end of this tutorial (10 minutes tops), you’ll have a functioning Ghost blog protect...
-
28
Ab Origine - Latin, "From the beginning". Build the simplest linux system capable of compiling itself. Cross compile it to every target supported by QEMU. Boot it under QEMU...
-
7
Happy Monday to you all and happy October. I hope you have a good week. My goal: to develop a data model
-
15
Ranked #13 for todayUmbrelA beautiful personal server OS for self-hostingUmbrel is a beautiful personal server OS that makes self-hosti...
-
19
Umbrel — A personal server OS for self-hosting umbrel.local...
-
5
Instantly share code, notes, and snippets. CSS Modern Font Stacks ...
-
4
Modern Font StacksFont StacksFont Size: 2 Font Weight: 400
-
16
Show HN: Modern Font Stacks – New system font stack CSS for modern OSs This is...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK