

Graphics, Gaming, and VR blog
source link: https://community.arm.com/arm-community-blogs/b/graphics-gaming-and-vr-blog/posts/unity-ml-agents-on-arm-how-we-created-game-ai-part-3-of-3
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
In part 2 of this blog series, we showed how the game AI agents were designed. We also showed what the generated Neural Network (NN) models looked like for our Dr Arm’s Boss Battle Demo. Part 3 looks at how agents training works and how the game runs on Arm-based devices.
Training Strategy
It is time to start the training
Once everything is set up, it is time to start the training. Many copies of the training area can be instantiated in the scene. This speeds up training, allowing the environment to gather many experiences in parallel. This can be achieved simply by instantiating many agents with the same Behavior Name. In our case, we instantiated 6 training areas as below. This was about twice as fast as a single instance. We also tried with 8 instances, but the effect was not so different from the 6 instances due to the high CPU load.

Figure 1. Training our agent using multiple instances
Training Metrics to Track Learning Progress
The cumulative rewards and episode length are often used as metrics to track learning progress. Along with those training metrics, we referred to the ELO rating system. You can think of the ELO as the rating system or skill points of an online game. If the agent wins against the target, the rate number goes up, and if it loses, it goes down. In adversarial games, the cumulative reward and the episode length may not be a meaningful metric by which to track learning progress. This is because they are entirely dependent on the skill of the opponent, which we are improving as well. For example, a medium-level agent gets much more reward against a low-level opponent than an expert-level one.
Training Result
The graphs below show how the metrics have transitioned over the training steps:
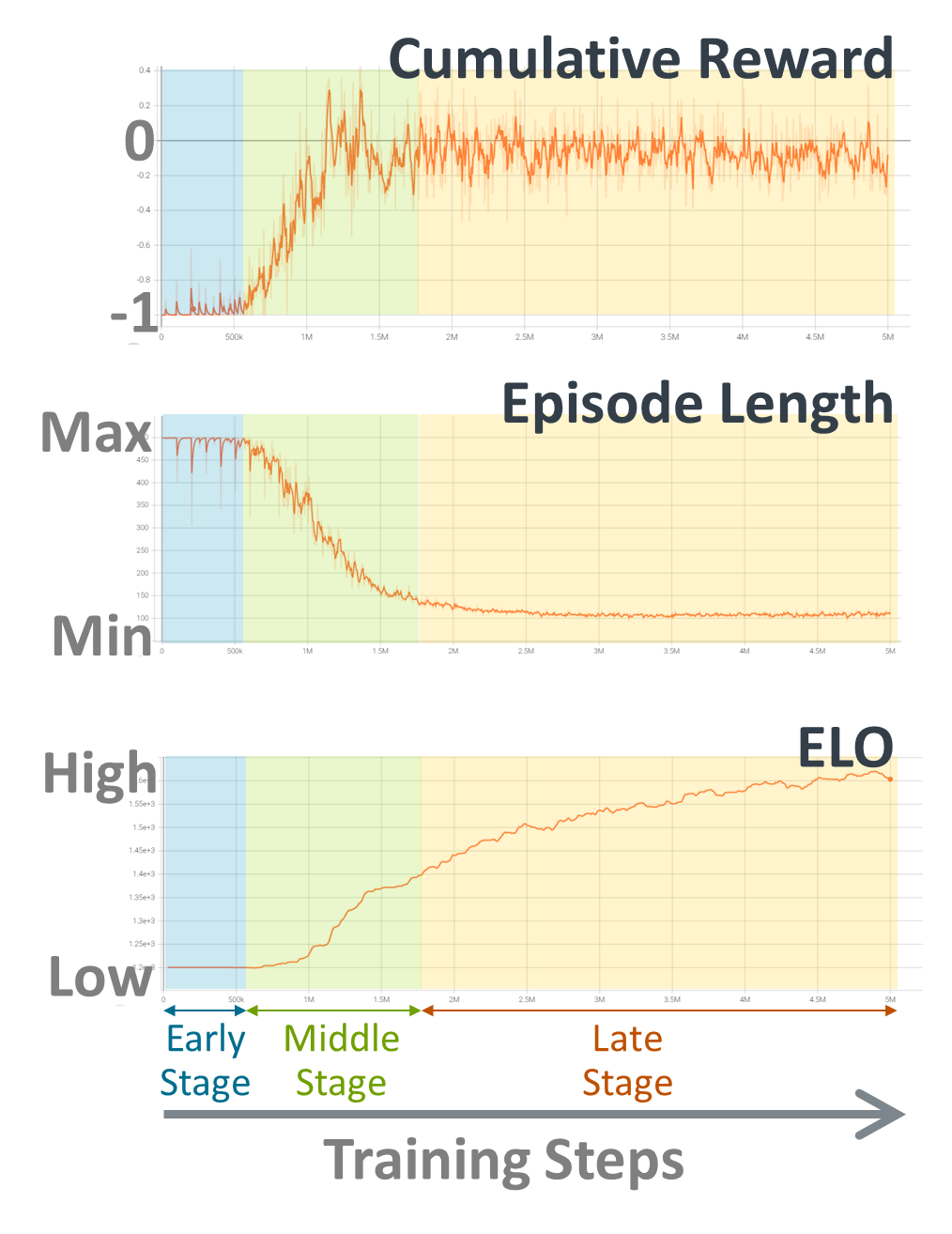
Figure 2. Training metrics to track learning progress
In the initial stages of training, you can see that the value of the cumulative reward is around -1. This is because the actions of the agent are almost random at first. The episode ends when time out happens, giving a reward of -1. The graph of the episode length shows that timeout continues at this stage. The ELO value stays the same at the beginning.
After some iterations, the reward starts to increase. In this middle stage, the agent gradually learns how to behave through the experience of defeating the target. The length of each episode will be reduced accordingly. At the same time, the ELO value begins to increase. This means that the agent is getting smarter.
When the training progresses further, the rewards stabilize around zero. There are no timeouts in every episode at this late stage. The brain of the agent is about the same as the brain of the target. The win rate is almost 50%, and the average reward settles to zero. (To be precise, the convergence value is slightly lower than zero. This is because the target's brain should be always slightly stronger than the brain that is currently trained.)
The length of each episode becomes shorter, converging to a certain length. So, it is difficult to judge the training progress by referring to the reward and the episode length alone. If we look at the ELO value, we can see that it is still increasing steadily. Thus, the ELO value is a better indicator of the training progress at this stage. When this value converges, it is a signal to end the training. It is also important to end the training before the agent overfits against the target.
The parameters used to train this agent are listed below:
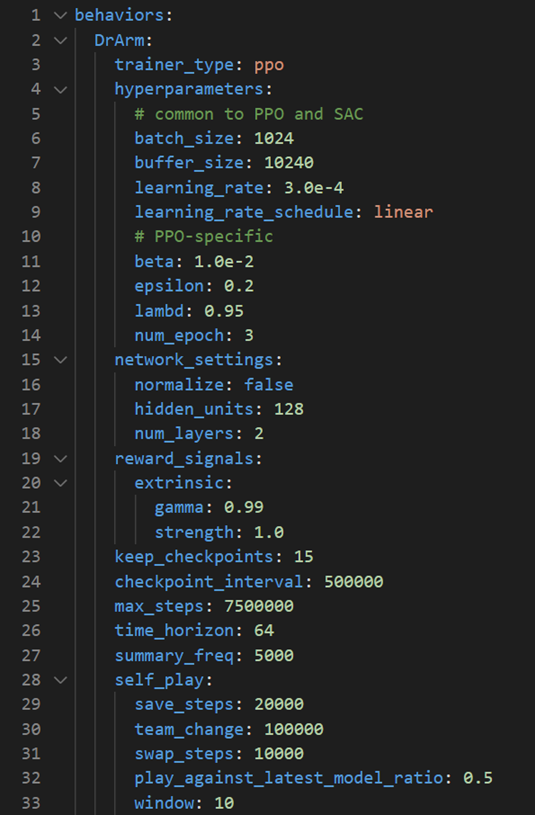
Figure 3. Training parameters used for the demo
Game Deployment on Arm-based Devices
Next, we describe how we use the trained agents in a game on Arm-based devices.
Different Difficulty Levels
As mentioned, we have prepared a game AI with different difficulty levels in the demo. Past snapshots of the NN model with different training times are picked up as different difficulty levels. The three difficulty levels, Easy, Medium, and Hard, are corresponding to the snapshots of the training results shown here.
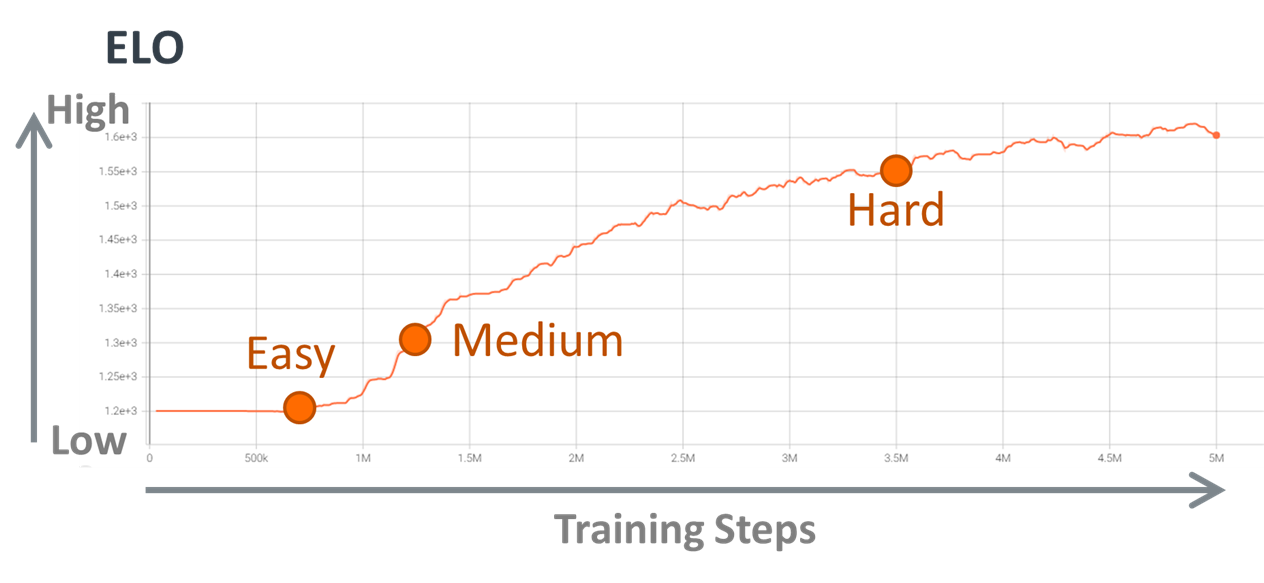
Figure 4. ELO value (skill point)
Let us look at some characteristics of each difficulty level. The GIFs below are snippets from battles. Note that this is actual gameplay, with Dr Arm controlled by me and the Knight controlled by the AI.

Figure 5. Agent with different difficulty levels (left: easy, middle: medium, right: hard)
First, we can say that the easy agent tends to attack straight towards the target. The easy agent is at the stage where they are beginning to understand that the aim is to reduce the HP of the target to zero. Second, the medium agent starts trying to move behind the target. The medium agent starts to learn that they have a higher chance of a successful attack if they get behind the target. Finally, the hard agent takes the strategy of waiting for the player to act and then responding accordingly. In this game, the characters' attack motions are a slightly slow, so the hard agent understands that if they attack first, they are at a disadvantage. The hard agent does not attack usually until the player takes an action.
As a side note, switching NN models on runtime can be implemented as shown in the sample code below:
using Unity.MLAgents;
using Unity.MLAgents.Policies;
using Unity.Barracuda;
// Difficulty Levels
public enum BattleMode
{
Easy,
Medium,
Hard
}
// Unity.Barracuda.NNModel class
public NNModel easyBattleBrain = "BossBattle-easy.onnx";
public NNModel mediumBattleBrain = "BossBattle-medium.onnx";
public NNModel hardBattleBrain = "BossBattle-hard.onnx";
// Should match with Agent's Behavior Name in Unity's UI
public string behaviorName = "BossBattle";
public void setDifficulty(BattleMode mode, Agent agent)
{
switch (mode)
{
case BattleMode.Easy:
agent.SetModel(behaviorName, easyBattleBrain);
break;
case BattleMode.Medium:
agent.SetModel(behaviorName, mediumBattleBrain);
break;
case BattleMode.Hard:
agent.SetModel(behaviorName, hardBattleBrain);
break;
default:
break;
}
}Smart Agents on Arm-based devices
The game was deployed to Windows on Arm devices. We then measured how performant the agents were running by using the Unity profiler.
The timeline below shows what processing is being carried out within a single frame. In this profiling, the game is running at 25fps and each frame takes approximately 40msec. Of these, the time spent by the agent can be found by looking for root.AgentSendState, root.DecideAction and root.AgentAct. In this frame, the NN model took 2.66msec to execute on a Samsung Galaxy Book S. The average over 20 frames was about 2.67msec.

Figure 6. Profiling timeline within a single frame
The Decision Requester component on the agent calls the NN model at a set interval for the developer. I set the Decision Period parameter in the component to 5, meaning the decision making of the agent is done every 5 frames. We tried setting the execution interval to 1, but the character movements became choppy and unnatural. It is necessary to decide the value by considering the task and the appearance of the game.
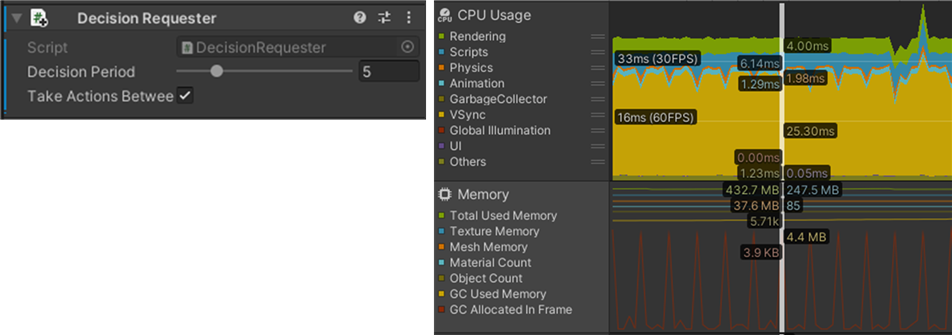
Figure 7. Decision Requester component (left) and timeline that shows NN model execution with specific intervals (right)
All ML-Agents models are executed with Barracuda by default. The Barracuda package is a cross-platform NN inference library for Unity. It can run NN models on both GPU and CPU. But usually, the agent NN model is best executed on CPU.
Our experiments have shown that the size of the NN model is not large enough to use a GPU efficiently. In such cases, the data transfer time to and from the GPU becomes the bottleneck rather than the NN model execution time. Also, GPUs are usually too busy rendering graphics and may not have enough capacity to run the NN model.
Conclusion
The use of ML in games is an exciting field. Among them, its application to game AI is one of the most advanced areas of practical use. We look forward to seeing more games with ML-based game AI, like Reinforcement Learning, soon. We also expect those games to be available on more Arm-based devices, including mobile and WoA.
It was a lot of fun to see the agents gradually improve as we built the demo and trained them. Although there were some issues in building the environment, I was able to train the agents more easily than I had expected. I hope you enjoyed this blog post and get a sense of how to create ML-based game AI. We encourage you to try building your own agents in your game. I really appreciate your feedback and would love to hear about your experiences with the agents you have created.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK