

Stream流原理与用法总结,你学会了吗?
source link: https://developer.51cto.com/article/715931.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Stream流原理与用法总结,你学会了吗?-51CTO.COM

一、接口设计
从Java1.8开始提出了Stream流的概念,侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式;依旧先看核心接口的设计:
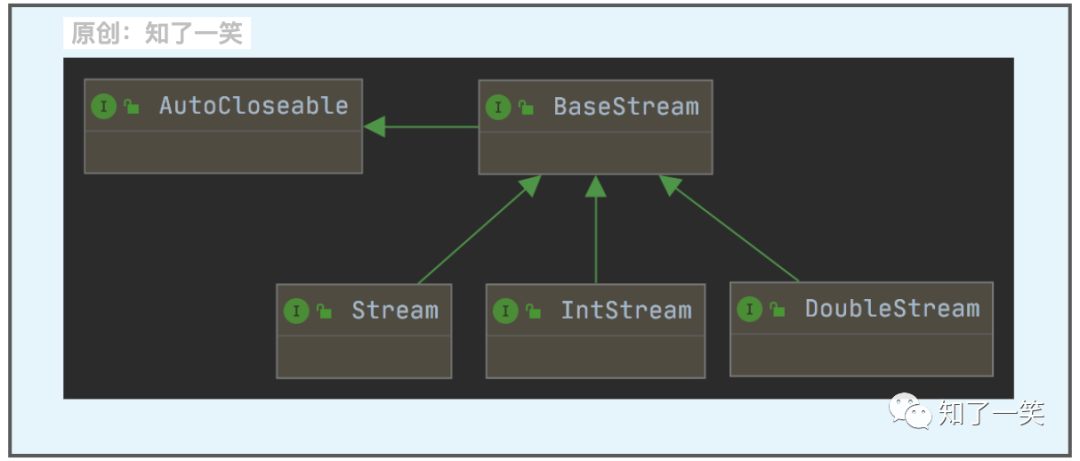
BaseStream:基础接口,声明了流管理的核心方法;
Stream:核心接口,声明了流操作的核心方法,其他接口为指定类型的适配;
基础案例:通过指定元素的值,返回一个序列流,元素的内容是字符串,并转换为Long类型,最终计算求和结果并返回;
System.out.println("sum1="+IntStream.of(1,2,3).sum());
System.out.println("sum2="+Stream.of("1", "2", "3").mapToLong(Long::parseLong).sum());整个Stream处理过程上看可以分为三段:创建流、中间操作、最终操作,即多个元素值通过流计算最终获取到求和的结果;
二、创建操作
除了Stream提供的创建方法之外,在Java1.8中,很多容器类的方法都进行的扩展,提供了集合元素转流的能力;
Stream创建:
Stream<Integer> intStream = Stream.of(1, 2) ;Collection创建:
List<String> getList = Arrays.asList("hello","copy") ;
Stream<String> strStream = getList.stream() ;Array创建:
Double[] getArray = new Double[]{1.1,2.2};
Stream<Double> douStream = Arrays.stream(getArray) ;上述方式创建的Stream流默认都是串行序列,可以通过Stream.isParallel进行判断;执行Stream.parallel方法可以转为并行流;
三、中间操作
通常对于Stream的中间操作,可以视为是源的查询,并且是懒惰式的设计,对于源数据进行的计算只有在需要时才会被执行,与数据库中视图的原理相似;
Stream流的强大之处便是在于提供了丰富的中间操作,相比集合或数组这类容器,极大的简化源数据的计算复杂度,案例中使用的数据结构如下;
public class TesStream {
public static void main(String[] args) {
List<User> userList = getUserList () ;
}
private static List<User> getUserList (){
List<User> userList = new ArrayList<>() ;
userList.add(new User(1,"张三","上海")) ;
userList.add(new User(2,"李四","北京")) ;
userList.add(new User(3,"王五","北京")) ;
userList.add(new User(4,"顺六","上海,杭州")) ;
return userList ;
}
}filter:过滤,输出id大于1的用户;
userList.stream().filter(user -> user.getId()>1).forEach(System.out::println);map:将现有的元素转换映射到对应的结果,输出用户所在城市;
userList.stream().map(user -> user.getName()+" 在 "+user.getCity()).forEach(System.out::println);peek:对元素进行遍历处理,每个用户ID加1输出;
userList.stream().peek(user -> user.setId(user.getId()+1)).forEach(System.out::println);flatMap:数据拆分一对多映射,用户所在多个城市;
userList.stream().flatMap(user -> Arrays.stream(user.getCity().split(","))).forEach(System.out::println);sorted:指定属性排序,根据用户ID倒序输出;
userList.stream().sorted(Comparator.comparingInt(User::getId).reversed()).forEach(System.out::println);distinct:去重,用户所在城市去重后输出;
userList.stream().map(User::getCity).distinct().forEach(System.out::println);skip & limit:截取,过滤后的数据跳过,截取第一条;
userList.stream().filter(user -> user.getId()>1).skip(1).limit(1).forEach(System.out::println);相比于集合与数组在Java1.8之前的处理逻辑,通过Stream流的方法简化对数据改、查、过滤、排序等一系列操作,上面对于最终方法只涉及了foreach遍历;
四、最终操作
Stream流执行完最终操作之后,无法再执行其他动作,否则会报状态异常,提示该流已经被执行操作或者被关闭,想要再次执行操作必须重新创建Stream流;
min:最小值,获取用户最小的id值;
int min = userList.stream().min(Comparator.comparingInt(User::getId)).get().getId();max:最大值,获取用户最大的id值;
int max = userList.stream().max(Comparator.comparingInt(User::getId)).get().getId();sum:求和,对用户ID进行累计求和;
int sum = userList.stream().mapToInt(User::getId).sum() ;count:总数,id小于2的用户总数;
long count = userList.stream().filter(user -> user.getId()<2).count();foreach:遍历,输出北京相关的用户;
userList.stream().filter(user -> "北京".equals(user.getCity())).forEach(System.out::println);findAny:查找符合条件的任意一个元素,获取一个北京用户;
User getUser = userList.stream().filter(user -> "北京".equals(user.getCity())).findAny().get();findFirst:获取符合条件的第一个元素;
User getUser = userList.stream().filter(user -> "北京".equals(user.getCity())).findFirst().get();anyMatch:匹配判断,判断是否存在深圳的用户;
boolean matchFlag = userList.stream().anyMatch(user -> "深圳".equals(user.getCity()));allMatch:全部匹配,判断所有用户的城市不为空;
boolean matchFlag = userList.stream().allMatch(user -> StrUtil.isNotEmpty(user.getCity()));noneMatch:全不匹配,判断没有用户的城市为空;
boolean matchFlag = userList.stream().noneMatch(user -> StrUtil.isEmpty(user.getCity()));这里只是演示一些简单的最终方法,主要涉及Stream流的一些统计和判断相关的能力,在一些实际的业务应用中,显然这些功能还远远不够;
五、Collect收集
Collector:结果收集策略的核心接口,具备将指定元素累加存放到结果容器中的能力;并在Collectors工具中提供了Collector接口的实现类;
toList:将用户ID存放到List集合中;
List<Integer> idList = userList.stream().map(User::getId).collect(Collectors.toList()) ;toMap:将用户ID和Name以Key-Value形式存放到Map集合中;
Map<Integer,String> userMap = userList.stream().collect(Collectors.toMap(User::getId,User::getName));toSet:将用户所在城市存放到Set集合中;
Set<String> citySet = userList.stream().map(User::getCity).collect(Collectors.toSet());counting:符合条件的用户总数;
long count = userList.stream().filter(user -> user.getId()>1).collect(Collectors.counting());summingInt:对结果元素即用户ID求和;
Integer sumInt = userList.stream().filter(user -> user.getId()>2).collect(Collectors.summingInt(User::getId)) ;minBy:筛选元素中ID最小的用户
User maxId = userList.stream().collect(Collectors.minBy(Comparator.comparingInt(User::getId))).get() ;joining:将用户所在城市,以指定分隔符链接成字符串;
String joinCity = userList.stream().map(User::getCity).collect(Collectors.joining("||"));groupingBy:按条件分组,以城市对用户进行分组;
Map<String,List<User>> groupCity = userList.stream().collect(Collectors.groupingBy(User::getCity));在代码工程中会涉及到诸多的集合数据计算的逻辑,尤其在微服务场景中,VO数据模型需要对多个服务的数据进行组装,通过Collector可以极大精简组装过程;
Recommend
-
10
三个Windows的小窍门,你学会了吗?发布于 01-09 · 2283 次播放视频相关好物知乎盐选会员¥19.00 起
-
8
大家好,我是安果!在编写爬虫前,我们都需要对目标应用进行抓包,然后分析一波后,才能进入到编写脚本的阶段对于使用 iPhone 的小伙伴来说,日常抓包不要太容易。PC 端工具,比如:Charles、Fiddler 完全够打;「 Stream」是 iOS 端一款非常强大...
-
6
五分钟学会 gRPC,你学会了吗?-51CTO.COM 五分钟学会 gRPC,你学会了吗? 作者:crossoverJie 2022-03-08 08:39:22 gRPC 内容还是非常多的,本文只是作为一份入门资料希望能让不了解 gRPC 的能...
-
2
小包第一个 qq 号前面是 444 ,用久了,感觉看 4 这个数字真顺眼。恰逢 Promise 也有四个很像的静态三兄弟(Promise.all、Promise.allSettled、Promise.race、Promi...
-
6
小包第一个 qq 号前面是 444 ,用久了,感觉看 4 这个数字真顺眼。...
-
7
一、bq24735简介bq24735 是一款高效率同步电池充电器。当系统供电需求暂时高于适配器最大供电水平的时候, bq24735 使用智能加速技术来允许电池向系统中释放能量,这样的话将保护适配器不被损坏。
-
3
Pandas Query 方法深度总结,你学会了吗?-51CTO.COM Pandas Query 方法深度总结,你学会了吗? 作者:周萝卜 2022-07-26 00:25:57 事实证明实际上可以使用 query() 方法做到这一点...
-
6
Stream简化元素计算; 一、接口设计 从Java1.8开始提出了Stream流的概念,侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式;依旧先看核心接口的设计:
-
4
Java基础 | Stream流原理与用法总结 推荐 原创 知了一笑 2022-08-09 08...
-
5
Order By 的高级用法,你学会了吗 作者:丶平凡世界 2022-12-06 08:37:43 SQL的理论其实是集合论,常见的类似求数据的交集、并集、差集都可以使用集合的思维来求解。集合中的行之间没有预先定义的顺序,它只是成员...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK