

Docker搭建大数据平台之Hadoop, Spark,Hive初探
source link: https://www.51cto.com/article/714441.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一、 文章前序
- 网络的发达,使得世界上有网络的每个地方,无时无刻都在产生数据。这些累积的数据,就像无形的巨大资源,等待着人们去挖掘。于是,大数据处理的理论以及实践随之产生的技术越来越成熟。作为一名开发者,学习理解并使用,或许可以用来解决身边的某些问题。
- 本文基于云原生docker,搭建单机版的大数据平台,初探大数据相关技术的搭建使用,抛砖引玉。
2、相关技术
- Zookeeper
分布式集群管理、master选举、消息发布订阅、数据存储、分布式锁等等。分布式协调服务,用于维护集群配置的一致性、任务提交的事物性、集群中服务的地址管理、集群管理等。 - HDFS
分布式文件系统,适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭 之后就不需要改变。 - Yarn
分布式资源管理系统,用于同一管理集群中的资源(内存等) - MapReduce
Hadoop的编程框架,用map和reduce方式实现分布式程序设计,类似于Spring。 - Hive
数仓工具,Hive进行数据离线批量处理时,需将查询语言先转换成MR任务,由MR批量处理返回结果,所以Hive没法满足数据实时查询分析的需求。 - Hbase
Hadoop下的分布式数据库,类似于NoSQL。 - Sqoop
用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递。 - Hadoop
Hadoop 是一种分析和处理大数据的软件平台,是一个用Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。
Hadoop=HDFS+Yarn+MapReduce+Hbase+Hive+Zookeeper+Hbase+Hive+Sqoop (生态圈)
3、用户画像
- 用户画像:
用户信息标签化。 - 数据是通过收集用户的社会属性、消费习惯、偏好特征等产生。
- 通过对数据的分析,对用户或者产品特征进行刻画,统计,从而挖掘潜在的价值信息。
- 统计类标签,例如:近30天类的活跃天数,活跃时长等。
- 规则类标签,例如:当用户在30天内的活跃天数大于15天时会被打上 活跃用户 的标签。
- 机器学习挖掘类标签,例如:用户购买商品偏好,用户流失意向等。
二、Docker搭建大数据平台
- 宿主机:WIN10 笔记本 16G ,VMWare虚拟机。
- 虚拟机:CentOS8,64位,桥接模式,分配内存8G内存,存储80G。
- 本文搭建后,使用free -h 查看,使用了4.6G内存。
2、技术框架版本以及下载链接
hadoop-2.7.7 | http://archive.apache.org/dist/hadoop/core/hadoop-2.7.7/ | |
hbase-2.1.1 | http://archive.apache.org/dist/hbase/1.2.1/ | |
hive-2.3.4 | http://archive.apache.org/dist/hive/hive-2.3.4/ | |
jdk1.8.0_144 | ||
scala-2.11.12 | https://www.scala-lang.org/download/2.11.12.html | |
spark-2.4.8-bin-hadoop2.7 | http://archive.apache.org/dist/spark/spark-2.4.8/ | |
zookeeper-3.4.8 | http://archive.apache.org/dist/zookeeper/zookeeper-3.4.8/ |
3、依赖包已上传到天翼云盘(不限速)
https://cloud.189.cn/t/RF3YrmYb6RZv (访问码:0iz2)。
4、安装Docker
5、docker创建独立网段
docker network create --subnet=172.18.0.0/16 spark-net6、容器规划
域名 | IP |
cloud1 | 172.18.0.2 |
cloud2 | 172.18.0.3 |
cloud3 | 172.18.0.4 |
7、创建基础容器并安装ssh以及免密配置
参数 | 说明 |
–name | |
-h | |
–add-host | /etc/hosts文件中的域名与IP的映射 |
–net |
# 拉取基础镜像
docker pull ubuntu
#创建基础容器并设置当前容器IP
docker run --name cloud1 \
--net spark-net --ip 172.18.0.2 \
-h cloud1 \
--add-host cloud1:172.18.0.2 \
--add-host cloud2:172.18.0.3 \
--add-host cloud3:172.18.0.4 \
-it ubuntu#清空/etc/apt/sources.list文件
echo > /etc/apt/sources.list
#向/etc/apt/sources.list文件写入阿里云镜像地址
cat >> /etc/apt/sources.list <<EOF
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
EOF
#安装vim
apt-get update
apt-get install -y vim
apt-get install net-tools
#在容器cloud1中通过apt工具来安装ssh
apt-get install -y ssh
#往~/.bashrc中加入ssh服务启动命令
vim ~/.bashrc
export LC_ALL="C.UTF-8"
/usr/sbin/sshd
#需要创建个目录
mkdir -p /run/sshd
#直接回车
ssh-keygen -t rsa -P ""
#私钥(~/.ssh/id_rsa)由客户端持有
#公钥(~/.ssh/id_rsa.pub)交给服务端
#已认证的公钥(~/.ssh/authorized_keys)由服务端持有,只有已认证公钥的客户端才能连接至服务端
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#测试是否能连接成功
ssh root@cloud18、大数据环境安装
- 各软件版本
软件 | 版本 |
Java | 1.8.0_144 |
Scala | 2.11.12 |
Zookeeper | 3.4.10 |
Hadoop | 2.7.7 |
Spark | 2.4.8 |
Hive | 2.3.4 |
mkdir -p /usr/local/spark- 将环境所需依赖包拷贝到容器内
# 在容器内创建目录
mkdir -p /opt/spark_tar
# 如果依赖包放在/opt下 则进入到/opt目录下然后执行如下命令
docker cp apache-hive-2.3.4-bin.tar.gz cloud1:/opt/spark_tar
docker cp hadoop-2.7.7.tar.gz cloud1:/opt/spark_tar
docker cp jdk-8u191-linux-x64.tar.gz cloud1:/opt/spark_tar
docker cp scala-2.11.12.tgz cloud1:/opt/spark_tar
docker cp spark-2.4.8-bin-hadoop2.7.tgz cloud1:/opt/spark_tar
docker cp zookeeper-3.4.10.tar.gz cloud1:/opt/spark_tar
docker cp mysql-connector-java.jar cloud1:/opt/spark_tar
docker cp hive-site.xml cloud1:/opt/spark_tar
#或执行我放在云盘中的脚本 sh cpAllToCloud1.sh
#在容器目录/opt/spark_tar下执行解压
tar -zxvf apache-hive-2.3.4-bin.tar.gz -C /usr/local/spark/
tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local/spark/
tar -zxvf jdk-8u191-linux-x64.tar.gz -C /usr/local/spark/
tar -zxvf scala-2.11.12.tgz -C /usr/local/spark/
tar -zxvf spark-2.4.8-bin-hadoop2.7.tgz -C /usr/local/spark/
tar -zxvf zookeeper-3.4.10.tar.gz -C /usr/local/spark/
mv /usr/local/spark/apache-hive-2.3.4-bin /usr/local/spark/hive-2.3.4
#或执行我的脚本 sh tarAllToUsrLocal.sh (也就是把上面的命令放在一个文件内一次执行)
cd /usr/local/spark/
drwxr-xr-x 9 1000 staff 149 Jul 19 2018 hadoop-2.7.7/
drwxr-xr-x 10 root root 184 Jul 14 17:55 hive-2.3.4/
drwxr-xr-x 7 uucp 143 245 Oct 6 2018 jdk1.8.0_191/
drwxrwxr-x 6 1001 1001 50 Nov 10 2017 scala-2.11.12/
drwxr-xr-x 13 501 1000 211 May 8 2021 spark-2.4.8-bin-hadoop2.7/
drwxr-xr-x 10 1001 1001 4096 Mar 23 2017 zookeeper-3.4.10/- 配置环境变量
vim ~/.bashrc
export JAVA_HOME=/usr/local/spark/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin
export SCALA_HOME=/usr/local/spark/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
export ZOOKEEPER_HOME=/usr/local/spark/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export HADOOP_HOME=/usr/local/spark/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export SPARK_HOME=/usr/local/spark/spark-2.4.8-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
export HIVE_HOME=/usr/local/spark/hive-2.3.4
export PATH=$HIVE_HOME/bin:$PATH
source ~/.bashrc9、Zookeeper安装及配置
#生成配置文件
cp /usr/local/spark/zookeeper-3.4.10/conf/zoo_sample.cfg /usr/local/spark/zookeeper-3.4.10/conf/zoo.cfg
#创建zookeeper数据目录
mkdir -p /root/zookeeper/tmp
#修改配置文件
vim /usr/local/spark/zookeeper-3.4.10/conf/zoo.cfg
#修改配置项
dataDir=/root/zookeeper/tmp
#文件末尾添加
server.1=cloud1:2888:3888
server.2=cloud2:2888:3888
server.3=cloud3:2888:3888
#保存退出
#设置当前Zkserver信息
#~/zookeeper/tmp/myid文件中保存的数字代表本机的Zkserver编号
#在此设置cloud1为编号为1的Zkserver,之后生成cloud2和cloud3之后还需要分别修改此文件
echo 1 > ~/zookeeper/tmp/myid10、Hadoop安装及配置
- 修改Hadoop启动配置文件
#修改Hadoop启动配置文件
vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
#文件末尾添加
export JAVA_HOME=/usr/local/spark/jdk1.8.0_191
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=${HADOOP_HOME}/lib/native"
export LD_LIBRARY_PATH=$JAVA_LIBRARY_PATH
#保存退出- 修改核心配置文件
参数 | 说明 |
fs.defaultFS | 默认的文件系统 |
hadoop.tmp.dir | 临时文件目录 |
ha.zookeeper.quorum | Zkserver信息 |
#修改核心配置文件
vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/core-site.xml
#在<configuration>节点内添加如下配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>cloud1:2181,cloud2:2181,cloud3:2181</value>
</property>- 修改HDFS配置文件
参数 | 说明 |
dfs.nameservices | 名称服务,在基于HA的HDFS中,用名称服务来表示当前活动的NameNode |
dfs.ha.namenodes.<nameservie> | 配置名称服务下有哪些NameNode |
dfs.namenode.rpc-address.<nameservice>.<namenode> | 配置NameNode远程调用地址 |
dfs.namenode.http-address.<nameservice>.<namenode> | 配置NameNode浏览器访问地址 |
dfs.namenode.shared.edits.dir | 配置名称服务对应的JournalNode |
dfs.journalnode.edits.dir JournalNode | 存储数据的路径<br /> |
#修改配置文件
vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
#在<configuration>节点内添加如下配置
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>cloud1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>cloud1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>cloud2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>cloud2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://cloud1:8485;cloud2:8485;cloud3:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hadoop/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>- 修改Yarn的配置文件
参数 | 说明 |
yarn.resourcemanager.hostname | RescourceManager的地址,NodeManager的地址在slaves文件中定义 |
#修改配置文件
vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/yarn-site.xml
#在<configuration>节点内添加如下配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>cloud1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>- 修改指定DataNode和NodeManager的配置文件
vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/slaves
#改为如下内容
cloud1
cloud2
cloud311、Spark安装及配置
- Spark启动配置文件
#生成启动配置文件
cp /usr/local/spark/spark-2.4.8-bin-hadoop2.7/conf/spark-env.sh.template /usr/local/spark/spark-2.4.8-bin-hadoop2.7/conf/spark-env.sh
#编辑启动配置文件
vim /usr/local/spark/spark-2.4.8-bin-hadoop2.7/conf/spark-env.sh
#文末添加如下配置
export SPARK_MASTER_IP=cloud1
export SPARK_WORKER_MEMORY=1024m
export JAVA_HOME=/usr/local/spark/jdk1.8.0_191
export SCALA_HOME=/usr/local/spark/scala-2.11.12
export SPARK_HOME=/usr/local/spark/spark-2.4.8-bin-hadoop2.7
export HADOOP_CONF_DIR=/usr/local/spark/hadoop-2.7.7/etc/hadoop
export SPARK_LIBRARY_PATH=$SPARK_HOME/lib
export SCALA_LIBRARY_PATH=$SPARK_LIBRARY_PATH
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export LD_LIBRARY_PATH=$JAVA_LIBRARY_PATH- 修改指定Worker的配置文件
vim /usr/local/spark/spark-2.4.8-bin-hadoop2.7/conf/slaves
#改为如下内容
cloud1
cloud2
cloud3- 修改文件汇总
root@cloud1:/# vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
root@cloud1:/# vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/core-site.xml
root@cloud1:/# vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
root@cloud1:/# vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/yarn-site.xml
root@cloud1:/# vim /usr/local/spark/hadoop-2.7.7/etc/hadoop/slaves
root@cloud1:/# cp /usr/local/spark/spark-2.4.8-bin-hadoop2.7/conf/spark-env.sh.template /usr/local/spark/spark-2.4.8-bin-hadoop2.7/conf/spark-env.sh
root@cloud1:/# vim /usr/local/spark/spark-2.4.8-bin-hadoop2.7/conf/spark-env.sh
root@cloud1:/# vim /usr/local/spark/spark-2.4.8-bin-hadoop2.7/conf/slaves12、集群部署
- 提交容器为新镜像
#提交cloud1容器,命令返回新镜像的编号
#为新镜像打标签为Spark
docker commit cloud1 spark:v4
#删除原来的cloud1容器,重新创建
docker stop cloud1
docker rm cloud1
#如果docker网段没创建的话,创建下
docker network create --subnet=172.18.0.0/16 spark-net- 用新镜像创建容器
创建3个ssh的Tab页,分别执行如下命令。
# 50070 端口
# 8088 端口
# 7077 端口 spark
# 9000 端口 hdfs
# 16010 端口 hbase
# 2181 端口 zookeeper
# 10000 端口 hive server
docker run --name cloud1 \
-p 50070:50070 \
-p 8088:8088 \
-p 8080:8080 \
-p 7077:7077 \
-p 9000:9000 \
-p 16010:16010 \
-p 2181:2181 \
-p 10000:10000 \
--net spark-net --ip 172.18.0.2 \
-h cloud1 \
--add-host cloud1:172.18.0.2 \
--add-host cloud2:172.18.0.3 \
--add-host cloud3:172.18.0.4 \
-it spark:v4docker run --name cloud2 \
--net spark-net --ip 172.18.0.3 \
-h cloud2 \
--add-host cloud1:172.18.0.2 \
--add-host cloud2:172.18.0.3 \
--add-host cloud3:172.18.0.4 \
-it spark:v4docker run --name cloud3 \
--net spark-net --ip 172.18.0.4 \
-h cloud3 \
--add-host cloud1:172.18.0.2 \
--add-host cloud2:172.18.0.3 \
--add-host cloud3:172.18.0.4 \
-it spark:v4- 分别在cloud2和cloud3容器中修改Zookeeper配置
#在cloud2执行
echo 2 > ~/zookeeper/tmp/myid
#在cloud3执行
echo 3 > ~/zookeeper/tmp/myid- 在所有节点启动Zkserver
#在所有节点查看Zkserver运行状态:
#显示连接不到Zkserver的错误,可稍后查看
#Master表示主Zkserver,Follower表示从Zkserver
zkServer.sh status
#3个节点分别启动Zkserver
zkServer.sh start- hdfs的namenode的HA模式的同步
- 启动JournalNode
第一次格式化HDFS的过程中,HA会journalnode通讯,所以需要先把三个节点的journalnode启动。
- 在cloud1节点上执行
# daemons 会启动3个节点的journalnode ,此处执行全启动
hadoop-daemons.sh start journalnode
# daemon 只会启动当前的journalnode
hadoop-daemon.sh start journalnode- 格式化NameNode
其中一个namenode(任选1个)上格式化,比如此处选择在cloud1节点上格式化namenode。
hdfs namenode -format
# namenode格式化结果中出现has been successfully formatted.说明格式化成功了
# 然后执行在cloud1节点hadoop-daemon.sh start namenode命令,启动namenode
hadoop-daemon.sh start namenode- NameNode同步
另一个namenode位于cloud2,所以需要在cloud2节点上进行namenode同步操作。
hdfs namenode -bootstrapStandby
#成功会提示common.Storage: Storage directory /hadoop/dfs/name has been successfully formatted.
#启动cloud2节点的namenode
hadoop-daemon.sh start namenode- 初始化 NameNode ZKFC
在其中一个namenode上初始化zkfc。
hdfs zkfc -formatZK
#Successfully created /hadoop-ha/hdfs1 in ZK.说明ZK格式化成功!- 全面启动HDFS
#cloud1节点上执行 停止已启动的HDFS
stop-dfs.sh
#1)停止2个namenode
#2)停止所有datanode
#3)停止所有 journalnode
#4)停止2个zkfc
#全面启动HDFS
start-dfs.sh- 在cloud1启动HDFS,Yarn,Spark
启动NameNode,DataNode,zkfc,JournalNode。
#上面启动了,这里就不用执行了
start-dfs.sh- 启动ResouceManager,NodeManager
start-yarn.sh- 启动Master,Worker
start-all.sh- 查看启动进程
root@cloud1:/# jps
2080 NodeManager
305 NameNode
18 QuorumPeerMain
2295 Worker
1816 ResourceManager
971 DataNode
2365 Jps
1167 JournalNode
2207 Master13、外部web访问地址
服务 | 地址 |
HDFS | cloud1:50070 |
Yarn | cloud1:8088 |
Spark | cloud1:8080 |
#查看开放端口
firewall-cmd --zone=public --list-ports
#依次开放端口
firewall-cmd --zone=public --add-port=50070/tcp --permanent
#重新加载配置
firewall-cmd --reload
#重启docker
systemctl daemon-reload
systemctl restart docker
#或者关闭防火墙
#停止firewall
systemctl stop firewalld.service
#禁止firewall开机启动
systemctl disable firewalld.service14、访问截图
http://192.168.0.135:50070/dfshealth.html#tab-datanode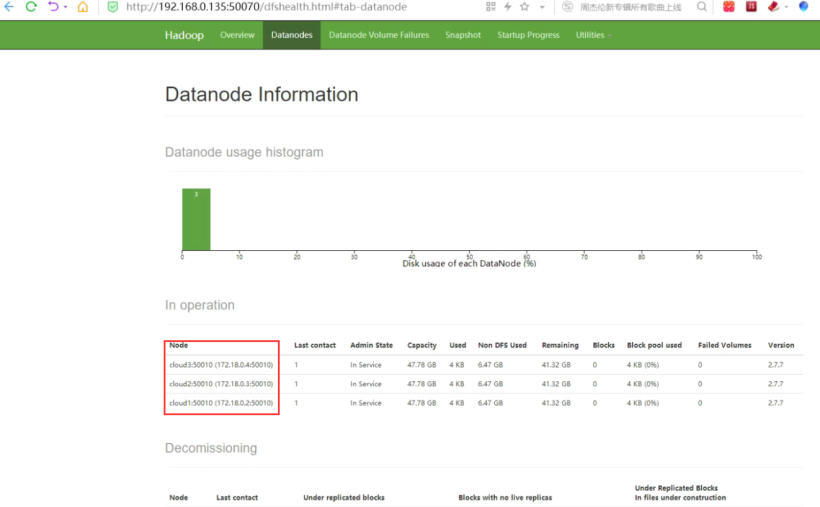
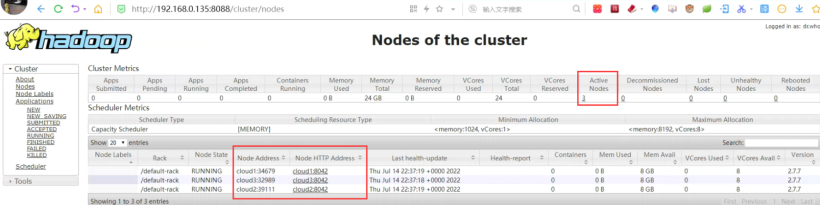
http://192.168.0.135:8088/cluster。
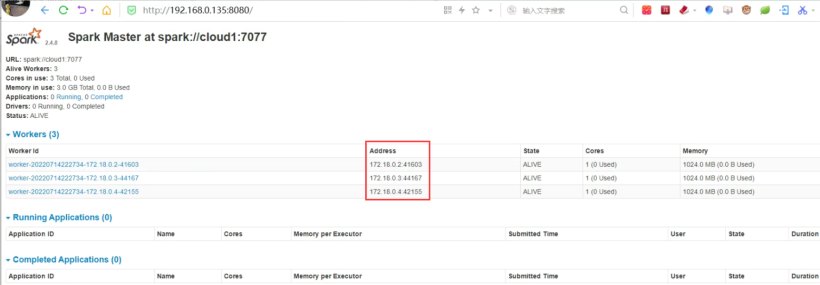
http://192.168.0.135:8080/。
15、测试提交Spark统计任务
准备待统计文本:
#容器内创建文本
vim /opt/put.txt
#添加如下内容
shao nai yi
nai nai yi yi
shao nai nai将文本上传到hdfs上:
#hdfs上创建目录
hdfs dfs -mkdir /opt
#上传文本到hdfs上
hdfs dfs -put /opt/put.txt /opt
#查看文件内容
hadoop fs -cat /opt/put.txt执行Spark统计任务:
spark-submit \
--master spark://cloud1:7077 \
--class com.gtstar.WordCountLocal \
/opt/my_scala-1.0-SNAPSHOT.jar \
hdfs://cloud1:9000/opt/put.txt \
hdfs://cloud1:9000/wc
#注意:my_scala-1.0-SNAPSHOT.jar 在我上传的网盘中,scala编写的简单统计#核心类 com.gtstar.WordCountLocal
import org.apache.spark.{SparkConf, SparkContext}
object WordCountLocal {
def main(args: Array[String]): Unit = {
var conf = new SparkConf()
conf.setAppName("WordCountLocal")
val sparkContext = new SparkContext(conf)
//读取参数1 (待计算的文本内容,/opt/put.txt)
val textFileRDD = sparkContext.textFile(args(0))
//空格分词
val wordRDD = textFileRDD.flatMap(line => line.split(" "))
//相同的词进行累加
val pairWordRDD = wordRDD.map(word => (word, 1))
val wordCountRDD = pairWordRDD.reduceByKey((a, b) => a + b)
//将结构输出到参数2
wordCountRDD.saveAsTextFile(args(1))
}
}
#源码放在gitee上 https://gitee.com/hxmeng/my_scalam.git查看统计结果:
#查看输出到hdfs的统计结果
hadoop fs -cat /wc/*
root@cloud1:/opt# hadoop fs -cat /wc/*
(nai,5)
(yi,3)
(shao,2)16、Hive安装
连接mysql(准备个mysql数据库)。
mysql中执行
# 创建数据库 hive_metadata 并授权限
create database if not exists hive_metadata;
#创建hive用户,并赋予权限
grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'master' identified by 'hive';
flush privileges;检查环境配置。
#如果已配置,则无需执行
vim ~/.bashrc
export HIVE_HOME=/usr/local/spark/hive-2.3.4
export PATH=$HIVE_HOME/bin:$PATH
source ~/.bashrc配置hive-site.xml。
cp /usr/local/spark/hive-2.3.4/conf/hive-default.xml.template /usr/local/spark/hive-2.3.4/conf/hive-site.xml
vim /usr/local/spark/hive-2.3.4/conf/hive-site.xml
# 由于hive-site.xml配置项过多,所以提前配置好
# 从外部拷贝到容器中 docker cp /opt/hive-site.xml cloud1:/opt/
cp /opt/hive-site.xml /usr/local/spark/hive-2.3.4/conf
#注意数据库相关配置,cloud1可替换为外部可连通的IP
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://cloud1:3306/hive_metadata?createDatabaseIfNotExist=true</value>配置hive-env.sh。
cp /usr/local/spark/hive-2.3.4/conf/hive-env.sh.template /usr/local/spark/hive-2.3.4/conf/hive-env.sh
vim /usr/local/spark/hive-2.3.4/conf/hive-env.sh
export HADOOP_HOME=/usr/local/spark/hadoop-2.7.7
export HIVE_CONF_DIR=/usr/local/spark/hive-2.3.4/conf
export JAVA_HOME=/usr/local/spark/jdk1.8.0_144
export HIVE_HOME=/usr/local/spark/hive-2.3.4初始化Hvie元数据到mysql数据库中。
schematool -dbType mysql -initSchema准备测试导入数据。
vim /opt/users.txt
1,浙江工商大学
2,杭州
3,I love
4,ZJGSU
5,加油哦执行导入:
保持后执行
hive
进入到命令行模式
创建存储user的Hvie表
hive> create table users(id int, name string) row format delimited fields terminated by ',';
导入数据
hive> load data local inpath '/opt/users.txt' into table users;
验证导入数据
hive> select * from users;如果执行 hive 时报错:
#检查HDFS主备状态
#查看nn的状态
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
#强制性把nn1状态置为active:
hdfs haadmin -transitionToActive --forcemanual nn1
#多次格式化的话
# 删除文件夹
rm -rf /root/hadoop/tmp/dfs/data/current
# 重新格式化
hdfs namenode -format三、基于Docker镜像快速创建
cloud1,cloud2,cloud3三个节点的镜像都放到了天翼云盘上,环境信息均已配置完成,只需要挨个启动就行。
cloud1:https://cloud.189.cn/t/Qj6ZBvvANFj2 (访问码:hhl5)。
cloud2: https://cloud.189.cn/t/2q6fMnAjUjIj (访问码:5km2)。
cloud3: https://cloud.189.cn/t/Afa6bme6NFza (访问码:j6ik)。
#3个节点分别启动Zkserver
zkServer.sh start
##cloud1全面启动HDFS
start-dfs.sh
#cloud1 启动ResouceManager,NodeManager
start-yarn.sh
#cloud1 启动Master,Worker
start-all.sh四、常见问题
1、 zookeeper集群启动失败
rm -rf /root/zookeeper/tmp/version-2/ /root/zookeeper/tmp/zookeeper_server.pid
zkServer.sh start
docker 关闭集群容器后,再重启,再每个容器启动zk,就一直报连接拒绝
原因分析:容器IP不固定,会随机变动
解决:自定义docker网络
docker network create --subnet=172.18.0.0/16 spark-net
启动容器时固定IP
--net spark-net --ip 172.18.0.2
--net spark-net --ip 172.18.0.3
--net spark-net --ip 172.18.0.42、hdfs的HA启动失败
原因分析:操作步骤错误导致节点不能正常格式化
解决:操作步骤- cloud1节点启动三个节点的journalnode,因为第一次格式化HDFS的过程中,HA会journalnode通讯。
- 格式化cloud1节点namenode。
- NameNode同步。
- 格式化 NameNode ZKFC。
3、hdfs的HA都是standby
# 查看nn的状态
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
# 强制性把nn1状态置为active
hdfs haadmin -transitionToActive --forcemanual nn1
#删除文件夹
rm -rf /root/hadoop/tmp/dfs/data/current
#重新格式化
hdfs namenode -format4、hive启动失败
1. tail -f /tmp/root/hive.log 查看日志信息
2. 是否有mysql驱动jar cp /opt/my_tar/mysql-connector-java.jar /usr/local/hive-2.3.4/lib/
3. 检查HDFS状态 hdfs haadmin -getServiceState nn1
4. /usr/local/hive-2.3.4/conf/hive-site.xml 配置中路径以及msyql地址是否正确5、 hadoop报错: Operation category READ is not supported in state standby
同 3 解决方式Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK