

强化学习-学习笔记4 | Actor-Critic - climerecho
source link: https://www.cnblogs.com/Roboduster/p/16448038.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Actor-Critic 是价值学习和策略学习的结合。Actor 是策略网络,用来控制agent运动,可以看做是运动员。Critic 是价值网络,用来给动作打分,像是裁判。
4. Actor-Critic
4.1 价值网络与策略网络构建
a. 原理介绍
状态价值函数:
Vπ(s)=∑aπ(a|s)⋅Qπ(s,a)Vπ(s)=∑aπ(a|s)⋅Qπ(s,a) (离散情况,如果是连续的需要换成定积分)
V 是动作价值函数 QπQπ 的期望,π(s|a)π(s|a) 策略函数控制 agent 做运动,Qπ(s,a)Qπ(s,a) 价值函数评价动作好坏。但是上述这两个函数我们都不知道,但是可以分别用一个神经网络来近似这两个函数,然后用Actor-Critic方法来同时学习这两个网络。
策略网络(actor):用网络 π(s|a;θ)π(s|a;θ) 来近似 π(s|a)π(s|a),θθ 是网络参数
价值网络(critic):用网络 q(s,a;w)q(s,a;w) 来近似 Qπ(s,a)Qπ(s,a),ww 是网络参数
actor 是一个体操运动员,可以自己做动作,而 agent 想要做的更好,但是不知道怎么改进,这就需要裁判给她打分,这样运动员就知道什么样动作的分数高,什么样动作的分数低,这样就能改进自己,让分数越来越高。
这样:Vπ(s)=∑aπ(a|s)⋅Qπ(s,a)≈∑aπ(a|s;θ)⋅q(s,a;w)Vπ(s)=∑aπ(a|s)⋅Qπ(s,a)≈∑aπ(a|s;θ)⋅q(s,a;w)$
b. Actor 搭建
策略网络。
- 输入:状态 s
- 输出:可能的动作概率分布
- AA 是动作集,如AA ={ "left","right","up"}
- ∑a∈Aπ(a|s,θ)=1∑a∈Aπ(a|s,θ)=1
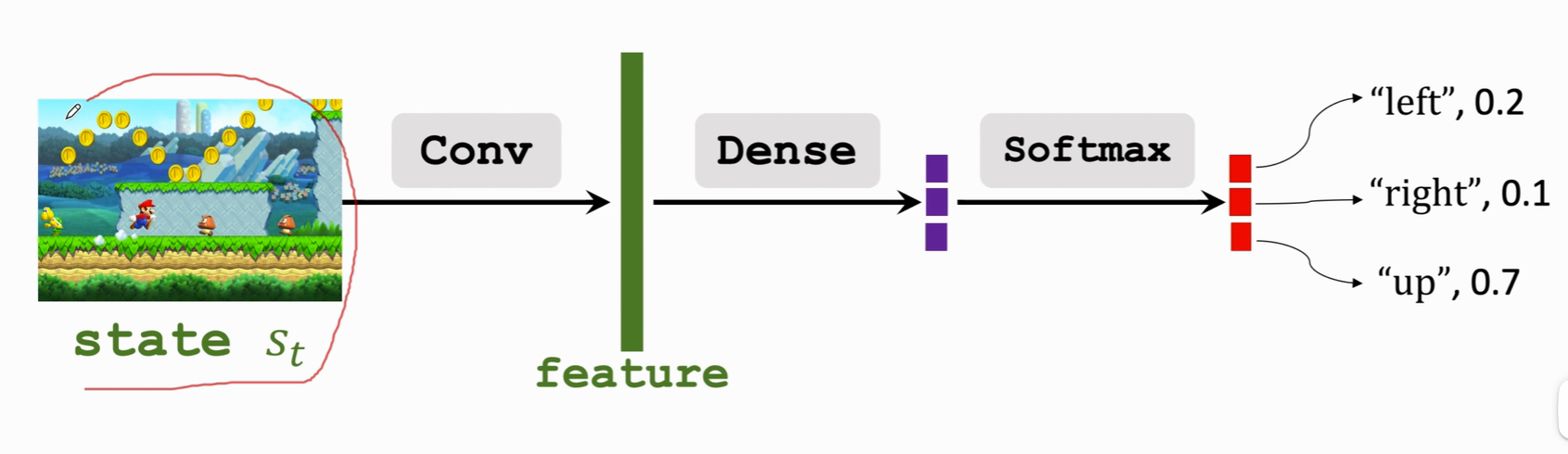
卷积层 Conv 把 state 变成 一个特征向量 feature ,用一个或多个全连接层 Dense 把特征向量 映射为紫色,归一化处理后得到每个动作的概率。
c. Critic搭建
输入:有两个,状态 s 和动作 a
输出:近似的动作价值函数(scalar)
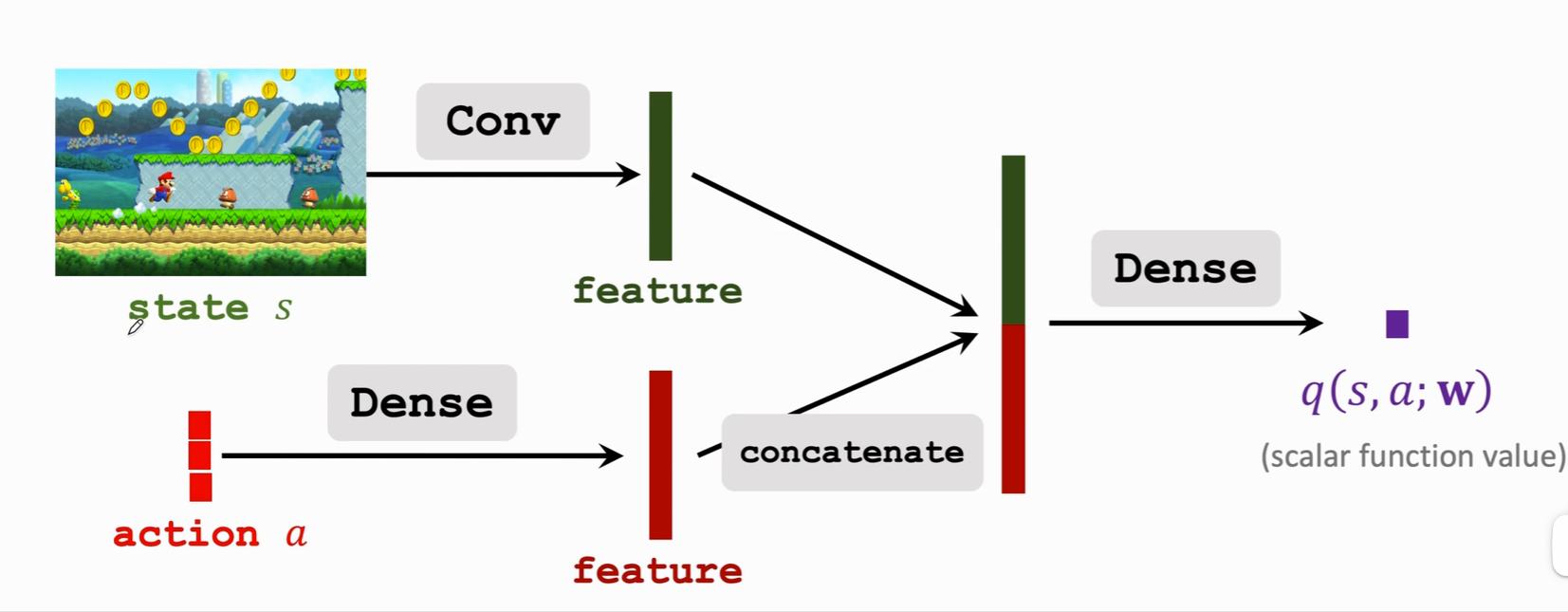
如果 动作 是离散的,可以用 one-hot coding 来表示,比如向左为[1,0,0],向右为[0,1,0] ······ 分别用卷积层与全连接层从输入中提取特征,得到两个特征向量,然后把这两个特征向量拼接起来,得到一个更高的特征向量,最后用一个全连接层输出一个实数,这个实数就是裁判给运动员打的分数。这个动作说明,处在状态 s 的情况下,做出动作 a 是好还是坏。这个价值网络可以与策略网络共享卷积层参数,也可以跟策略网络完全独立。
4.2 Actor-Critic Method
同时训练策略网络与动作网络就称为 Actor-Critic Method。
定义:使用神经网络来近似 两个价值函数
训练:更新参数 θ、wθ、w
- 更新策略网络π(s|a;θ)π(s|a;θ)是为了让V(s;θ,w)V(s;θ,w)的值增加
- 监督信号仅由价值网络提供
- 运动员actor 根据裁判critic 的打分来不断提高自己的水平
- 更新价值网络q(s,a;w)q(s,a;w)是为了让打分更精准
- 监督信号仅来自环境的奖励
- 一开始裁判是随机打分,但是会根据环境给的奖励提高打分水平,使其接近真实打分。
步骤总结:
- 观测状态 stst
- stst 作为输入,根据策略网络 π(⋅|st;θt)π(⋅|st;θt) 随机采样一个动作 atat
- 实施动作 atat 并观测新状态 st+1st+1 以及奖励 rtrt
- 用奖励 rtrt 通过 TD 算法 在价值网络中更新 w,让裁判变得更准确
- 使用 策略梯度算法 在策略网络中更新θθ,让运动员技术更好
a. TD 更新价值网络
-
用价值网络 Q 给 动作at、at+1at、at+1 打分,即计算 q(st,at;wt)q(st,at;wt) 与 q(st+1,at+1;wt)q(st+1,at+1;wt)
-
计算TD target:yt=rt+γ⋅q(st+1,at+1;wt)yt=rt+γ⋅q(st+1,at+1;wt),
比对上一篇笔记中的策略学习,需要用蒙特卡洛来近似q(st,at;wt)q(st,at;wt),而使用价值网络来近似更真实一些。
-
损失函数是预测值与部分真实值之间的差。
Loss值: L(w)=12[q(st,at;w)−yt]2L(w)=12[q(st,at;w)−yt]2
-
梯度下降:Wt+1=wt−α⋅∂L(w)∂w|w=wtWt+1=wt−α⋅∂L(w)∂w|w=wt
b. 策略梯度更新策略网络
状态价值函数 V 相当于运动员所有动作的平均分:
V(s;θ,w)=∑aπ(s|a;θ)⋅q(s,a;w)V(s;θ,w)=∑aπ(s|a;θ)⋅q(s,a;w)
策略梯度:函数 V(s;θ,w)V(s;θ,w) 关于参数 θθ 的导数
- g(a,θ)=∂logπ(a|s;θ)∂θ⋅q(s,a;w)g(a,θ)=∂logπ(a|s;θ)∂θ⋅q(s,a;w),这里 q 相当于裁判的打分
- ∂V(s;θ;wt)∂θ=EA[g(A,θ)]∂V(s;θ;wt)∂θ=EA[g(A,θ)]策略梯度相当于对函数 g 求期望,把 A 给消掉,但是很难求期望,用蒙特卡洛近似取样求就行了。
算法:
根据策略网络随机抽样得到动作 a :a∼π(⋅|st;θt)a∼π(⋅|st;θt) 。
对于 ππ 随机抽样保证g(a,θ)g(a,θ)是无偏估计
有了随机梯度 g,可以做一次梯度上升:θt+1=θt+β⋅g(a,θt)θt+1=θt+β⋅g(a,θt),此处 ββ 是学习率。
c. 过程梳理
下面我们以运动员和裁判的例子梳理一下过程:

首先,运动员(左侧的策略网络)观测当前状态 s ,控制 agent 做出动作 a;运动员想要进步,但它不知道怎样变得更好(或者没有评判标准),因此引入裁判来给予运动员评价:
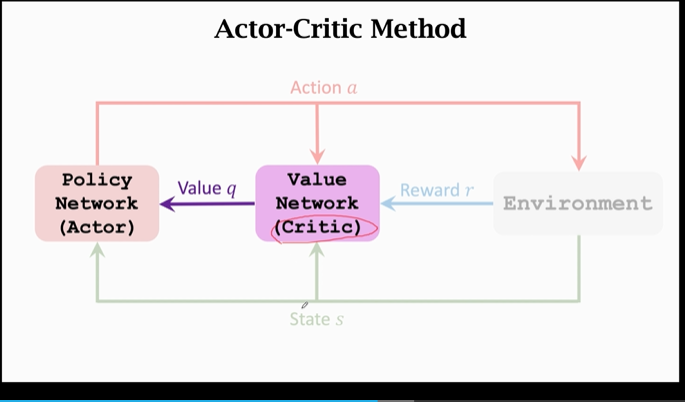
运动员做出动作后,裁判员(价值网络)会根据 a 和 s 对运动员(策略网络)打一个分 q,这样运动员根据 q 来改进自己:

运动员的“技术”指的是 策略网络中的参数,我们此前认定参数越好,我们的效果就越好。在这个模型中,运动员拿到 s、q 以及 a来计算 策略梯度,通过梯度上升来更新参数。通过改进 “技术”,运动员的平均分(就是value q)会越来越高。
但值得注意的是:至此,运动员一直是在裁判的评判下进行的,他的标准 q 是裁判给的。运动员的平均分 q 越高也不能说明真实水平的上升。我们还需要提升裁判的水平。
增加一个想法:我觉得 actor-critic 的思想是两部分,一是让 评判标准更接近上帝 的想法,二是 在给定评判标准下 让执行效果拿到更大的分数。
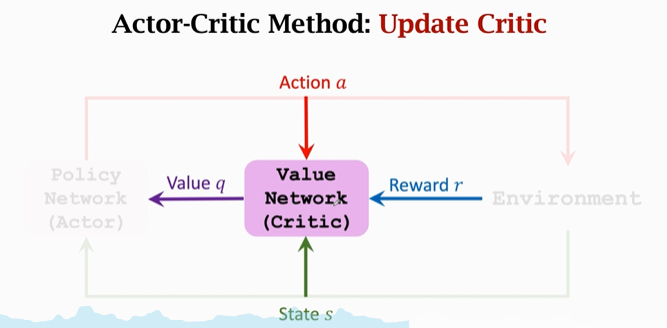
对于 价值网络/裁判 来说 初始的打分是随机的。裁判要靠 奖励r 来提高打分的水平,这里奖励r 就相当于 上帝的判断。价值网络根据 a、s、r 来给出分数 q ,通过相邻两次的分数 qt、qt+1qt、qt+1 以及 rtrt,使用 TD 算法 来更新参数,提高效果
d. 算法总结
下面稍微正式一点的总结一下:
-
观测旧状态 stst,根据策略网络π(⋅|st;θt)π(⋅|st;θt)随机采样一个动作atat
-
agent 执行动作atat;环境会告诉我们新的状态st+1st+1和奖励rtrt
-
拿新的状态st+1st+1作为输入,用策略网络ππ计算出新的概率并随机采样新的动作:a~t+1∼π(⋅|st+1;θt)a~t+1∼π(⋅|st+1;θt),这个动作只是假想的动作,agent不会执行,只是拿来算下 Q 值。
-
接下来算两次价值网络的输出:qt=q(st,at;wt)和qt+1=q(st+1,a~t+1;wt)qt=q(st,at;wt)和qt+1=q(st+1,a~t+1;wt),a~t+1a~t+1用完就丢掉了,并不会真正执行;
-
计算TD error:δt=qt−(rt+γ⋅qt+1)TD targetδt=qt−(rt+γ⋅qt+1)⏟TDtarget
-
对价值网络求导:dw,t=∂q(st,at;w)∂w|w=wtdw,t=∂q(st,at;w)∂w|w=wt
这一步 torch 和 tensenflow 都可以自动求导。
-
TD算法 更新价值网络,让裁判打分更精准:wt+1=wt−α⋅δt⋅dw,twt+1=wt−α⋅δt⋅dw,t
-
对策略网络
ππ求导:dθ,t=∂logπ(at|st,θ)∂θ|θ=θtdθ,t=∂logπ(at|st,θ)∂θ|θ=θt同理,可以自动求导
-
用梯度上升来更新策略网络,让运动员平均成绩更高:θt+1=θt+β⋅qt⋅dθ,tθt+1=θt+β⋅qt⋅dθ,t,这里qt⋅dθ,tqt⋅dθ,t是策略梯度的蒙特卡洛近似。
每一轮迭代做以上9个步骤,且制作一次动作,观测一次奖励,更新一次神经网络参数。
根据策略梯度算法推导,算法第 9 步用到了 qtqt,它是裁判给动作打的分数,书和论文通常拿 δtδt 来替代 qtqt。qtqt 是标准算法,δtδt 是Policy Gradient With Baseline(效果更好),都是对的,算出来期望也相等。
Baseline是什么?接近 qtqt 的数都可以作为 Baseline,但不能是 atat 的函数。
至于为什么baseline效果更好,因为可以更好的计算方差,更快的收敛。
这里的等价后面再讨论。这里先理解。
4.3 总结
我们的目标是:状态价值函数:Vπ(s)=∑aπ(a|s)⋅Qπ(s,a)Vπ(s)=∑aπ(a|s)⋅Qπ(s,a),越大越好
- 但是直接学 ππ 函数不容易,用神经网络-策略网络 π(s|a;θ)π(s|a;θ) 来近似
- 计算 策略梯度 的时候有个困难就是不知道动作价值函数 QπQπ,所以要用神经网络-价值网络q(s,a;w)q(s,a;w)来近似。
在训练时:
- agent由 策略网络(actor) 给出动作 at∼π(⋅|st;θ)at∼π(⋅|st;θ)
- 价值网络 q 辅助训练 ππ,给出评分
训练后:
- 还是由策略网络给出动作at∼π(⋅|st;θ)at∼π(⋅|st;θ)
- 价值网络 q 不再使用
如何训练:
用策略梯度来更新策略网络:
- 尽可能提升状态价值:Vπ(s)=∑aπ(a|s;θ)⋅q(s,a;w)Vπ(s)=∑aπ(a|s;θ)⋅q(s,a;w)
- 计算策略梯度,用蒙特卡洛算: ∂V(s;θ;wt)∂θ=EA[∂ log π(a|s;θ)∂θ⋅q(s,a;w)]∂V(s;θ;wt)∂θ=EA[∂logπ(a|s;θ)∂θ⋅q(s,a;w)]
- 执行梯度上升。
TD 算法更新价值网络
-
qt=q(st,at;w)qt=q(st,at;w)是价值网络是对期望回报的估计;
-
TD target:yt=rt+γ⋅maxaq(st+1,at+1;w)yt=rt+γ⋅maxaq(st+1,at+1;w),ytyt也是价值网络是对期望回报的估计,不过它用到了真实奖励,因此更靠谱一点,所以将其作为 target,相当于机器学习中的标签。
-
把qt与ytqt与yt差值平方作为损失函数计算梯度:
∂(qt−yt)2/2∂w=(qt−yt)⋅∂q(st,at;w)∂w∂(qt−yt)2/2∂w=(qt−yt)⋅∂q(st,at;w)∂w
-
梯度下降,缩小qt与ytqt与yt差距。
x. 参考教程
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK