

论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized G...
source link: https://www.cnblogs.com/BlairGrowing/p/16406463.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data
论文作者:Qi Zhu, Natalia Ponomareva, Jiawei Han, Bryan Perozzi
论文来源:2021, NeurIPS
论文地址:download
论文代码:download
1 Introduction
半监督学习通过使用数据之间的关系(即边连接关系,会产生归纳偏差),以及一组带标签的样本,来预测其余部分的标签。
半监督学习存在的问题:训练数据集和测试数据集的数据分布不一致,容易产生 过拟合、泛化性差的问题。当数据集太小或太大,选择一部分带标记的子集进行训练,这类问题就显得比较明显。
具体来说,我们的贡献如下:
1. We provide the first focused discussion on the distributional shift problem in GNNs.
2. We propose generalized framework, Shift-Robust GNN (SR-GNN), which can address shift in both shallow and deep GNNs.
3. We create an experimental framework which allows for creating biased train/test sets for graph learning datasets.
4. We run extensive experiments and analyze the results, proving that our methods can mitigate distributional shift.
2 Related Work
标准学习理论假设训练和推理数据来自相同的分布,但在许多实际情况下,这不成立。在迁移学习中,领域自适应(Domain adaptation)问题涉及将知识从源域(用于学习)转移到目标域(最终的推理分布)。
[3] 作为该领域的开创性工作定义了一个基于模型在 源域 和 目标域 表现的距离度量函数来量化两域的相似性。为获得最终的模型,一个直观的想法是基于源数据和目标数据的加权组合来训练模型,其中权重是域距离的量化函数。
3 Distributional shift in GNNs
SSL 分类器,通常使用交叉熵损失函数 ll:
L=1M∑i=1Ml(yi,zi)L=1M∑i=1Ml(yi,zi)
当训练数据和测试数据来自同一域 Prtrain (X,Y)=Prtest (X,Y)Prtrain (X,Y)=Prtest (X,Y) 时,训练得到的分类器表现良好。
3.1 Data shift as representation shift
基于标准学习理论的基础假设 Prtrain (Y∣Z)=Prtest (Y∣Z)Prtrain (Y∣Z)=Prtest (Y∣Z),分布位移的主要原因是表示位移,即
Prtrain (Z,Y)≠Prtest (Z,Y)→Prtrain (Z)≠Prtest (Z)Prtrain (Z,Y)≠Prtest (Z,Y)→Prtrain (Z)≠Prtest (Z)
本文关注的是训练数据集和测试数据集表示 ZZ 之间的分布转移。
为衡量这种变化,可使用 MMD[8] 或 CMD[37] 等差异指标。CMD 测量分布 pp 和 qq 之间的直接距离,如下:
CMD=1|b−a|∥E(p)−E(q)∥2+∑k=2∞1|b−a|k∥ck(p)−ck(q)∥2CMD=1|b−a|‖E(p)−E(q)‖2+∑k=2∞1|b−a|k‖ck(p)−ck(q)‖2
-
- ckck 代表第 kk 阶中心矩,通常 k=5k=5 ;
- aa、bb 表示这些分布的联合分布支持度;
上式值越大则两域距离越大。
本文定义的 GNNs 为 Hk=σ(Hk−1θk)Hk=σ(Hk−1θk),传统的 GNNs 为 Hk=σ(A~Hk−1θk)Hk=σ(A~Hk−1θk)。
传统的 GNNs 由于使用了归一化邻接矩阵,导致产生归纳偏差,从而改变了 表示的分布。所以在半监督学习中 ,由于 图归纳以及采样特征向量的偏移,有便宜的训练样本困难产生较大的性能干扰。
在形式上,对分布位移的分析如下:
Definition 3.1 (Distribution shift in GNNs). Assume node representations Z={z1,z2,…,zn}Z={z1,z2,…,zn} are given as an output of the last hidden layer of a graph neural network on graph GG with n nodes. Given labeled data {(xi,yi)}{(xi,yi)} of size MM , the labeled node representation Zl=(z1,…,zm)Zl=(z1,…,zm) is a subset of the nodes that are labeled, Zl⊂ZZl⊂Z . Assume ZZ and ZlZl are drawn from two probability distributions pp and qq. The distribution shift in GNNs is then measured via a distance metric d(Z,Zl)d(Z,Zl)
Figure 1 表明样本偏差导致的分布偏移的影响直接降低了模型的性能。通过使用节点 GCN 模型绘制了三个数据集分布位移距离值( xx 轴)和相应的模型精度( yy 轴)的关系。
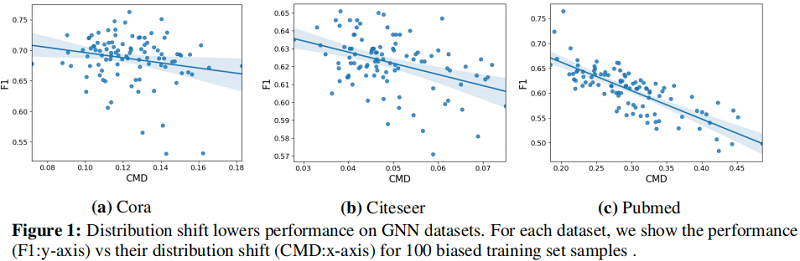
结果表明,GNN 在这些数据集上的节点分类性能与分布位移的大小成反比,并激发了我们对分布位移的研究。
4 Shift-Robust Graph Neural Networks
本节首先提出两种 GNN 模型解决分布位移问题(Prtrain (Z)≠Prtest (Z)Prtrain (Z)≠Prtest (Z),然后提出一种通用框架来减少分布位移2问题。
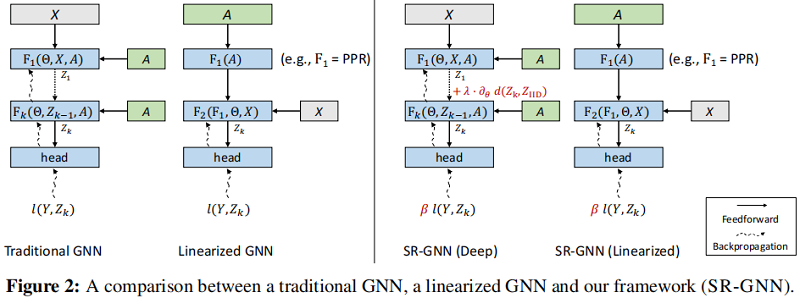
ji
4.1 Scenario 1: Traditional GNN models
传统 GNN 模型 (GCN) ΦΦ 包含 可学习函数 FF ,参数 ΘΘ ,邻接矩阵 AA :
Φ=F(Θ,A)Φ=F(Θ,A)
在 GCN 中,图的归纳偏差在每一层上都是乘法的,并且梯度在所有层中反向传播。最后一层生成的节点表示为:
Z≡Zk=Φ(Θ,Zk−1,A)Z≡Zk=Φ(Θ,Zk−1,A), Zk∈[a,b]nZk∈[a,b]n, Z0=XZ0=X
训练样本 {xi}Mi=1{xi}i=1M 的节点表示为 Ztrain ={zi}Mi=1Ztrain ={zi}i=1M。对于测试样本,从未标记的数据中抽取一个无偏的 IID 样本集 XIID ={x′i}Mi=1XIID ={xi′}i=1M,并将输出表示为 ZIID ={z′i}Mi=1ZIID ={zi′}i=1M。
为减轻训练 和 测试样本之间的分布位移问题,本文提出一个正则化器 d:[a,b]n×[a,b]n→R+d:[a,b]n×[a,b]n→R+ 用于添加到交叉熵损失上。由于 ΦΦ 是完全可微的,可以使用分布位移度量作为正则化,以直接最小化有偏和无偏的 IID 样本之间的差异:
L=1M∑il(yi,zi)+λ⋅d(Ztrain ,ZIID )L=1M∑il(yi,zi)+λ⋅d(Ztrain ,ZIID )
这里度量分布位移采用 中心力矩差异正则化器(central moment discrepancy regularizer)dCMDdCMD:
dCMD(Ztrain ,ZIID)=1b−a∥E(Ztrain )−E(ZIID)∥+∑k=2∞1|b−a|k∥ck(Ztrain )−ck(ZIID)∥dCMD(Ztrain ,ZIID)=1b−a‖E(Ztrain )−E(ZIID)‖+∑k=2∞1|b−a|k‖ck(Ztrain )−ck(ZIID)‖
-
- E(Z)=1M∑iziE(Z)=1M∑izi;
- ck(Z)=E(Z−E(Z))kck(Z)=E(Z−E(Z))k 是 kk 阶中心矩;
4.2 Scenario 2: Linearized GNN Models
线性化GNN模型使用两个不同的函数:一个用于非线性特征变换,另一个用于线性图扩展阶段:
Φ=F2(F1(A)linear function ,Θ,X)Φ=F2(F1(A)⏟linear function ,Θ,X)
其中,线性函数 F1F1 将图归纳偏差与节点特征相结合,然后交予多层神经网络特征编码器 F2F2 解耦。SimpleGCN[34] 中 F1(A)=AkXF1(A)=AkX 。线性化模型的另一个分支 [16,4,36] 采用 personalized pagerank 来预先计算图中的信息扩散 ( F1(A)=α(I−(1−α)A~)−1F1(A)=α(I−(1−α)A~)−1 ),并将其应用于已编码的节点特性 F(Θ,X)F(Θ,X)。
上述两种模型,图归纳偏差作为线性函数 F1F1 的特征输入。但足够阶段并没有可学习层,所以不能简单使用上述提出的分布正则化器。
在这两种模型中,图归纳偏差作为线性 F1F1 的输入特征提供。不幸的是,由于在这些模型的这个阶段没有可学习的层,所以我们不能简单地应用前一节中提出的分布正则化器。
在这种情况下,可以将训练和测试样本视为来自 F1F1 的行级样本,然后将分布位移 Prtrain (Z)≠Prtest (Z)Prtrain (Z)≠Prtest (Z) 问题转化为匹配训练和测试图的归纳偏差特征空间 hi∈Rnhi∈Rn。为从训练数据推广到测试数据,可以采用样本加权方案来纠正偏差,这样有偏差的训练样本 {hi}Mi=1{hi}i=1M 将类似于IID样本 {h′i}Mi=1{hi′}i=1M。由此得到的交叉熵损失为
L=1Mβil(yi,Φ(hi))L=1Mβil(yi,Φ(hi))
-
- βiβi 是每个训练实例的权值;
- ll 是交叉熵损失;
然后,通过求解一个 核均值匹配(KMM)[9] 来计算最优 ββ:
minβi∥∥∥1M∑i=1Mβiψ(hi)−1M′∑i=1M′ψ(h′i)∥∥∥2, s.t. Bl≤β<Buminβi‖1M∑i=1Mβiψ(hi)−1M′∑i=1M′ψ(hi′)‖2, s.t. Bl≤β<Bu
ψ:Rn→Hψ:Rn→H 表示由核 kk 引入的 reproducing kernel Hilbert space(RKHS) 的特征映射。在实验中,作者使用混合高斯核函数 k(x,y)=∑αiexp(αi∥x−y∥2)k(x,y)=∑αiexp(αi‖x−y‖2), αi=1,0.1,0.01αi=1,0.1,0.01。下限 BlBl 和上限 BuBu 约束的存在是为了确保大多数样本获得合理的权重,而不是只有少数样本 获得非零权重。
实际的标签空间中有多个类。为了防止 ββ 引起的标签不平衡,进一步要求特定 cc 类的 ββ 之和在 校正前后保持相同 ∑Miβi⋅I(li=c)=∑MiI(li=c),∀c∑iMβi⋅I(li=c)=∑iMI(li=c),∀c 。
4.3 Shift-Robust GNN Framework
现在我们提出了 Shift-Robust GNN(SR-GNN)-我们解决GNN中分布转移的一般训练目标:
LSR-GNN =1Mβil(yi,Φ(xi,A))+λ⋅d(Ztrain ,ZIID )LSR-GNN =1Mβil(yi,Φ(xi,A))+λ⋅d(Ztrain ,ZIID )
该框架由一个用于处理可学习层中的分布转移的正则化组件(第4.1节)和一个实例重加权组件组成,该组件能够处理在特征编码后添加了图归纳偏差的情况(第4.2节)。
现在,我们将讨论我们的框架的一个具体实例,并将该实例应用于APPNP[16]模型。APPNP模型的定义为:
ΦAPPNP =((1−α)kA~k+α∑i=0k−1(1−α)iA~i)approximated personalized page rank F(Θ,X)feature encoder ΦAPPNP =((1−α)kA~k+α∑i=0k−1(1−α)iA~i)⏟approximated personalized page rank F(Θ,X)⏟feature encoder
首先在节点特征 XX 上应用特征编码器 FF,并线性逼近 personalized pagerank matrix。因此,我们有 hi=πpprihi=πippr,其中 πppriπippr 是个性化的页面向量。为此,我们通过实例加权来减轻由图归纳偏差产生的分布转移。此外,让 Z=F(Θ,X)Z=F(Θ,X) 和我们可以进一步减少非线性网络的分布位移提出的差异正则化器 dd。在我们的实验中,我们展示了SR-GNN在另外两个具有代表性的GNN模型上的应用:GCN[15]和DGI[32]。
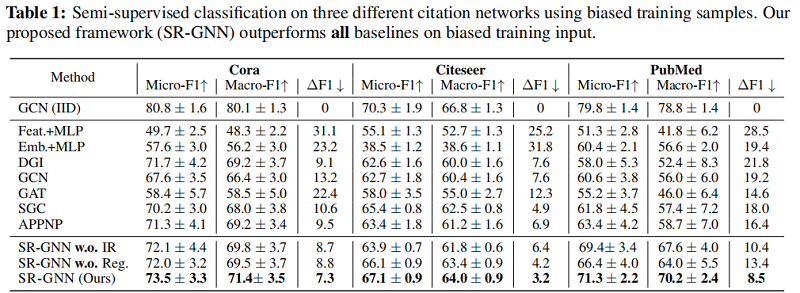
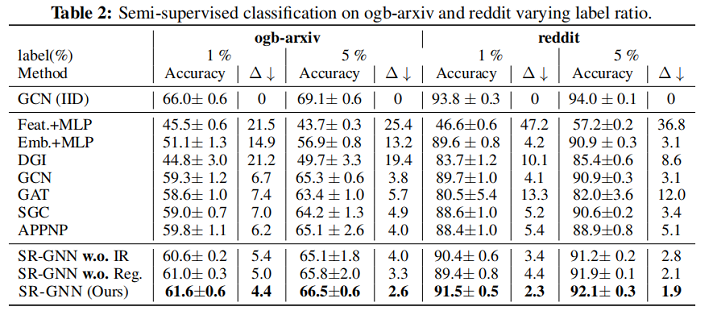
5 Experiments
实验
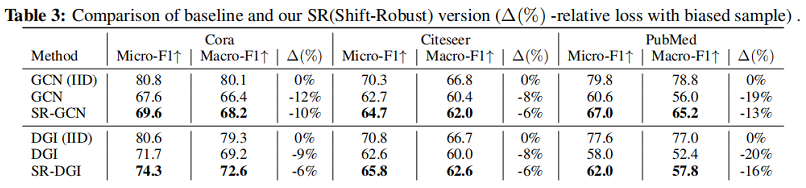
5 Conclusion
对于半监督学习,考虑表示分布一致性问题。
2022-06-24 创建文章
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK