

融合Zabbix和Prometheus,打造无短板可视化的监控不难!
source link: https://www.51cto.com/article/712006.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一、监控工具简介
1、Zabbix
Zabbix 是由Alexei Vladishev开源的分布式监控系统,是一个企业级的分布式开源监控方案。2004年3月发布1.0 稳定版,比Prometheus早了10年以上。能够监控各种网络参数以及服务器健康性和完整性的软件。使用灵活的通知机制,允许用户为几乎任何事件配置基于邮件的告警。
后端使用数据库存储监控配置和历史数据,可以较为方便地对接数据分析、报表定制等渠道,在前端开放了丰富的 RESTful API 供第三方平台调用,整体架构符合当前 DevOps 的趋势。
2、Prometheus
Prometheus是由前Google员工创办公司SoundCloud开发的开源监控报警系统和时序列数据库。相对于k8s是Google Borg系统的开源实现,Prometheus是Google BorgMon的开源实现。
Prometheus 由两个部分组成,一个是监控报警系统,另一个是自带的时序数据库(TSDB)。
Prometheus 在开源社区十分活跃,在 GitHub 上拥有四万多Star,并且系统每隔两三周就会有一个小版本的更新,Prometheus 与它的“师兄”k8s 自带云原生的光环,天然能够友好协作。
二、架构对比
1、Zabbix 架构
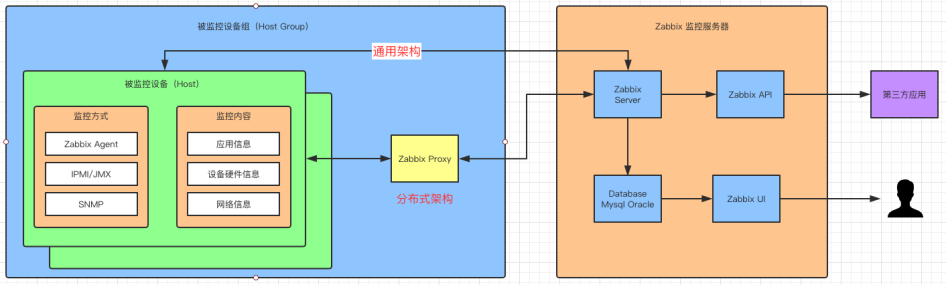
Zabbix Server
核心组件,C 语言编写,负责接收 Agent、Proxy 发送的监控数据,也支持 JMX、SNMP 等多种协议直接采集数据。同时,它还负责数据的汇总存储以及告警触发等。
Zabbix Proxy
可选组件,对于被监控机器较多的情况下,可使用 Proxy 进行分布式监控,它能代理 Server 收集部分监控数据,以减轻 Server 的压力。
Zabbix Agentd
部署在被监控主机上,用于采集本机的数据并发送给 Proxy 或者 Server,它的插件机制支持用户自定义数据采集脚本。
Agent 可在 Server 端手动配置,也可以通过自动发现机制被识别。数据收集方式同时支持主动 Push 和被动 Pull 两种模式。
- Database
用于存储配置信息以及采集到的数据,支持 MySQL、Oracle 等关系型数据库。同时,最新版本的 Zabbix 已经开始支持时序数据库,不过成熟度还不高。
- Web Server
Zabbix 的 GUI 组件,PHP 编写,提供监控数据的展现和告警配置。
2、Prometheus架构
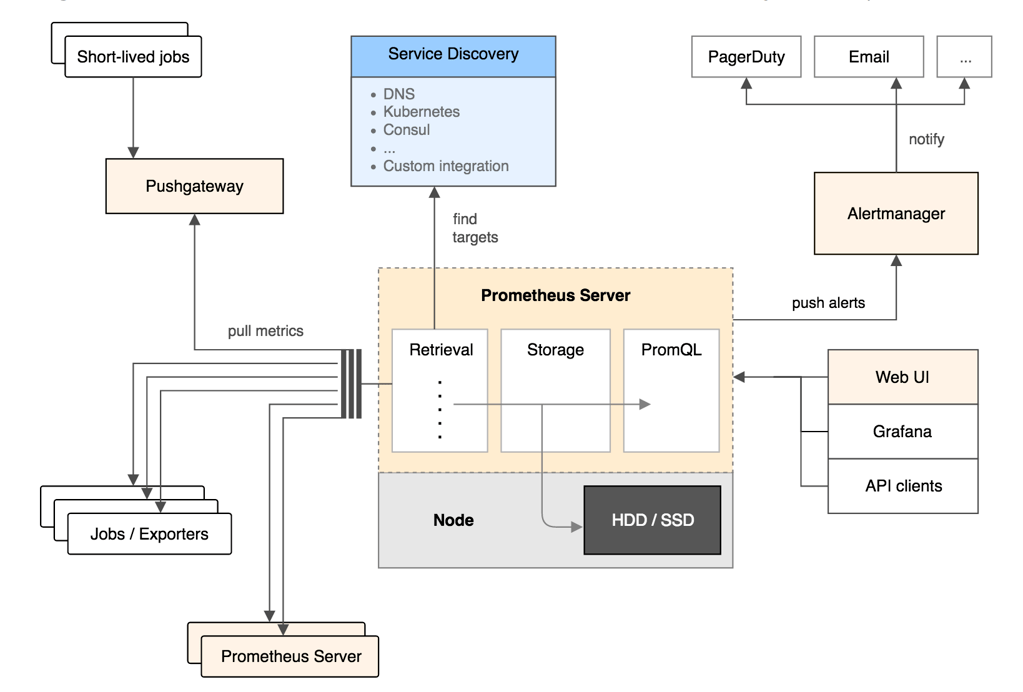
- Prometheus Server
用于定时抓取数据指标(metrics)、存储时间序列数据(TSDB),TSDB在存储监控的性能会优于传统关系型数据库。
- Jobs/exporters
Prometheus 使用各种 exporter 进行监控,exporter 的功能类似于 Zabbix 的 Agent,负责收集监控对象端的数据。
- Pushgateway
监控端的数据会用push的方式主动传给此组件,随后被 Prometheus 服务定时 pull 此组件数据即可。
- Alertmanager
报警组件,类似于Zabbix的Action,可以进行报警触发,比如发送短信和邮件。
Web UI 用于多样的UI展示,一般为Grafana,还有一些例如配置自动发现目标的小组件和后端存储组件。
三、Zabbix和Prometheus优劣
1、Zabbix的优势
- 产品成熟
由于诞生时间长且使用广泛,拥有丰富的文档资料以及各种开源的数据采集插件,能覆盖绝大部分监控场景,支持很多不同类型的设备和平台。
- 采集方式丰富
支持Agent、SNMP、JMX、SSH 等多种采集方式,以及主动和被动的数据传输方式,Agent可以更好地进行统一标准化配置。
- 较强的扩展性
支持 Proxy 分布式监控,有Agent 自动发现功能,插件式架构支持用户自定义数据采集脚本。
- 配置管理方便
能通过Web界面进行监控和告警配置,操作方便,上手简单。
2、Prometheus的优势
- 较强的处理能力
监控数据直接存储在 Prometheus Server 本地的时序数据库中,单个实例可以处理数百万的 Metrics。
- 灵活的数据模型
引入了Tag,属于多维数据模型,聚合统计更方便,支撑不同团队个性化展现。
- 强大的查询语句
PromQL 允许在同一个查询语句中,对多个 Metrics 进行加法、连接和取分位值等操作。
- 支持云环境
能自动发现容器,同时 K8s 和 Etcd 等项目都提供了对 Prometheus 的原生支持,是目前容器监控最流行的方案。
Zabbix 属于老牌的监控系统,资料多,功能全面且稳定,90%以上的配置可以通过Web 端统一操作和实现,比强依赖于配置文件的 Prometheus 要更为方便。
Prometheus有灵活的数据模型、更成熟的时序数据库,大数据量情况下性能更高。支持和Grafana 做快速集成,组合美观且强大的可视化体验,支持为不同团队提供更个性化的展现。
纯容器的环境,毫无疑问Prometheus是更适合的选择,Prometheus是天生为容器化平台打造的监控系统,环境很复杂,有各种操作系统、硬件、中间件、数据库、机房等,那么Zabbix更适合的监控平台,Zabbix兼顾了监控的深度和广度,实现了统一监控平台的目的;但当监控服务器上万,或者监控周期较长,超过了一年,需要面向不同团队灵活可视化展现时,Prometheus又有很强的优势。
四、Zabbix使用现状
公司按照业务线已经划分多套zabbix,运行稳定,但监控数据分散,无法集中化管理,多维度可视化能力较弱,数据存储周期过短,不方便容量预测和管理。
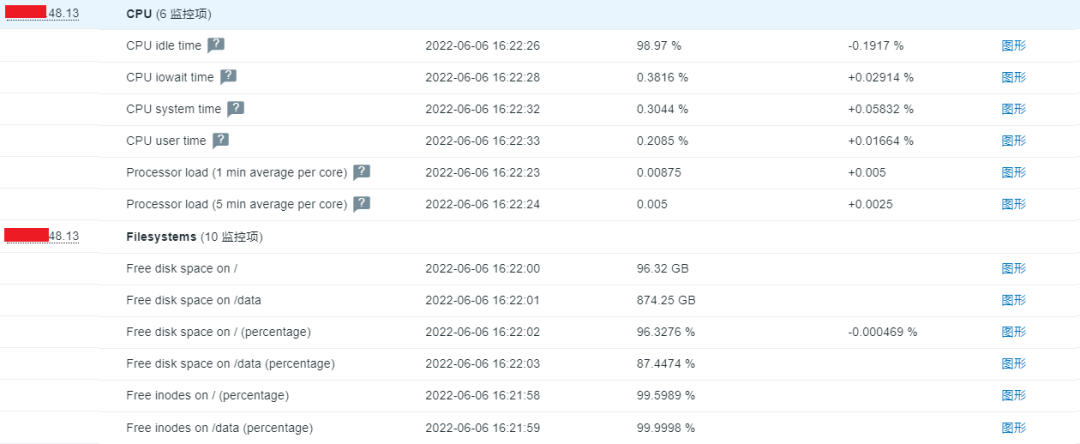
实时监控数据
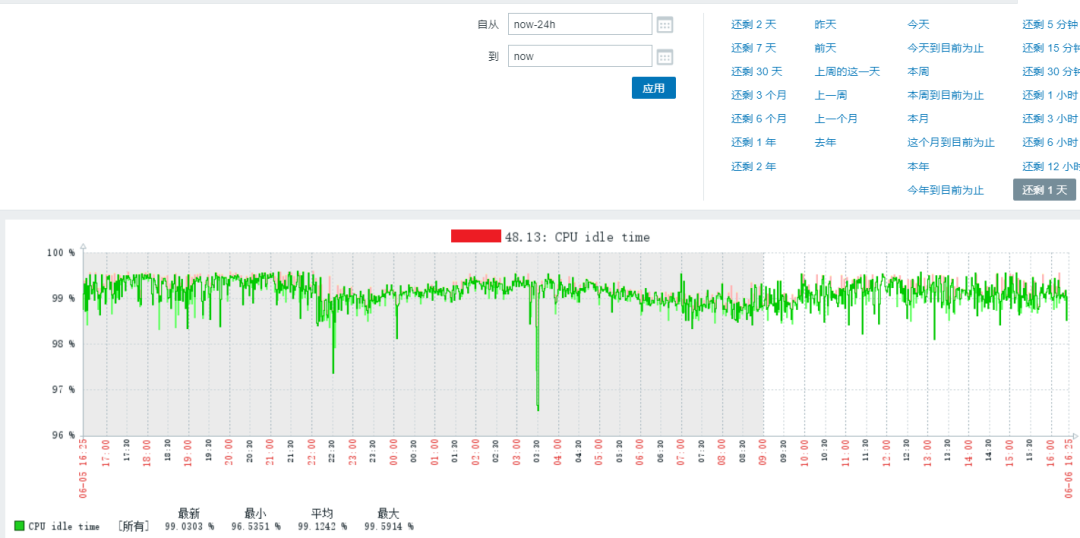
监控趋势图

1、Zabbix 数据库表结构
1)配置数据
① hosts表
存储被监控主机的信息。

常用字段介绍如下:
- Hostid:唯一标识Host在Zabbix及数据库中的id。不同表之间的关联也要用hostid。
- Proxy_hostid:若启用“proxy-server”架构,才会出现被监控机器的proxy_hostid。
- Host:被监控机器的名字。
- Status:机器目前的状态。“0”为正常监控,“1”为disable。
② items表
存储所有监控项,利用hostid在items表中查询该主机有那些监控项,itemid为监控项的id,name为监控项的名称,key_为键值,也就是表达式,怎么对监控项取值。
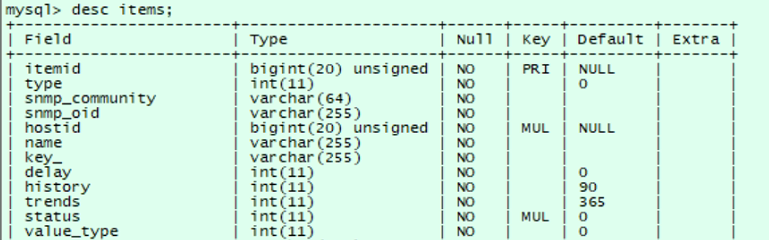
- itemid:item的id。
- type:item的type,和前端见面配置item的type的对应。数据库中,这一列的值是0到17的数字,分别代表不同的类型。
- hostid:item所在的host的hostid。如果该item是属于template,那么这里显示的是templateid。
- name:item的名字。
- key_:item的key。
- status:item的状态。
- value_type:item返回值的类型,配置item时候配置的“Type of Information”。
③ hosts_groups表
存储了host(主机)与host groups(主机组)的关联关系。

④ Host_groups表
主机组,zabbix上主机组命名规范化,方便多维度查找。
姓名_部门_产品_集群名

⑤ problem表
存储问题事件。
查询当前未恢复的问题事件Top10 并将时间戳转换为格式化时间。
SELECT p.eventid as 事件id,FROM_UNIXTIME(p.clock,'%Y-%m-%d %H:%i:%s') as clock,p.name as 触发事件,p.severity as 事件等级 FROM problem p WHERE p.source='0' AND p.object='0' AND NOT EXISTS (SELECT NULL FROM event_suppress es WHERE es.eventid=p.eventid) AND p.r_eventid IS NULL ORDER BY p.eventid DESC LIMIT 10;2)历史数据
Zabbix系统针对每个监控项在每次采集时所收集到的数据,这个数据保存Zabbix系统数据库的历史表中。监控的主机的数量较多的时候,zabbix系统每台产生的数量是非常庞大的,这对数据库是一种负担。建议对数据库进行分区或尽量减小历史数据的保留天数,以免给数据库系统带来很大的压力。
①history表:存储信息类型为浮点数的监控项历史数据。
- history_log表:存储信息类型为日志的监控项历史数据。
- history_str表:存储信息类型为字符的监控项历史数据。
- history_text表:存储信息类型为文本的监控项历史数据。
- history_uint表:存储信息类型为数字(无正负)的监控项历史数据。
② history表结构
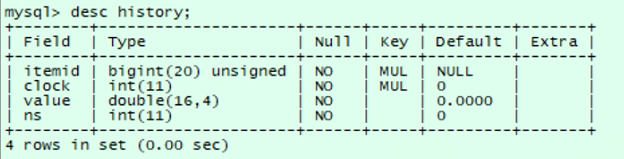
- itemid: 监控项唯一标识id。
- clock: 时间戳整数部分。
- value:监控项的值。
- ns:纳秒数。
查询 2022/06/07 00:00:00 -2022/06/08 00:00:00 itemid 29175 浮点数监控项历史数据。
select itemid,from_unixtime(clock) as time,value from history where itemid=29175 and clock >= unix_timestamp('2022/06/07 00:00:00') and clock <= unix_timestamp('2022/06/08 00:00:00');五、super_exporter
为了解决zabbix存在的不足,我们进行了zabbix和Prometheus融合监控项目,通过为每套zabbix数据库开发部署一套super_exporter,定期从数据库抓取该zabbix下的所有监控服务器性能数据,上报给Prometheus。为了减轻主数据库压力,提升响应速度,为每套zabbix新增一个独立从库,专门为super_exporter抓取数据使用。
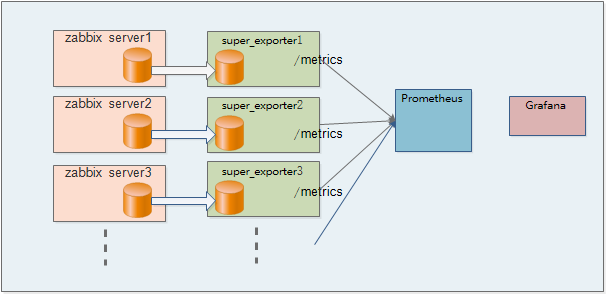
prometheus配置抓取任务,主机多的情况下,单个zabbix下总监控项会达到上万,性能优化后确保总执行时间不超过30s。

Metrics返回该zabbix管理的所有监控主机对应的多个监控项性能指标,涉及dba,host,产品部门,产品,集群,机房等标签。

super_exporter从hosts表获取本zabbix实例管理的监控主机集合,从hstgrp表获取主机对应运维负责人、部门、产品、集群名等业务层多维数据。从zabbix实例本身部署情况获取机房位置等数据,从items获取需要集中管理的监控项,从history类表抓取最近采集周期的监控数据。
六、Grafana展现
通过抓取zabbix汇聚的监控数据,存于TSD时序数据库,利用PromQL语言进行相关监控项的多标签聚合计算。使用grafana灵活强大的多维度可视化能力,方便及时地进行性能风险识别,进行长生命周期的资源容量预估。
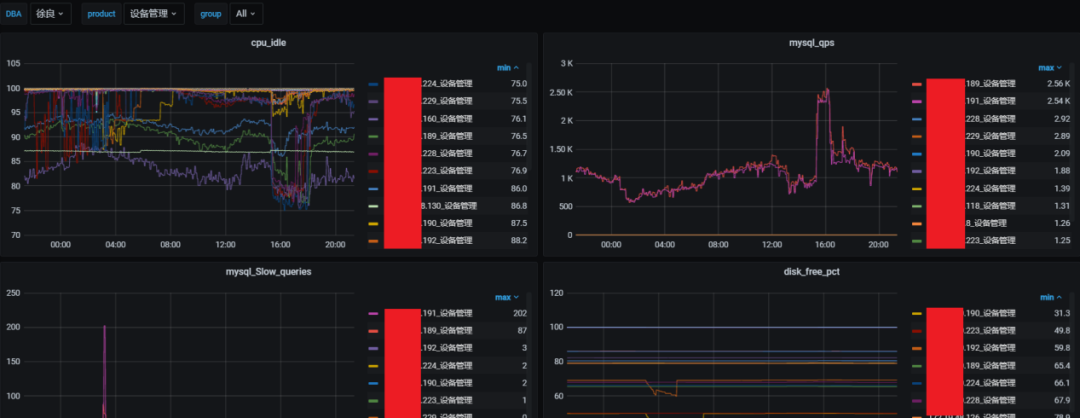
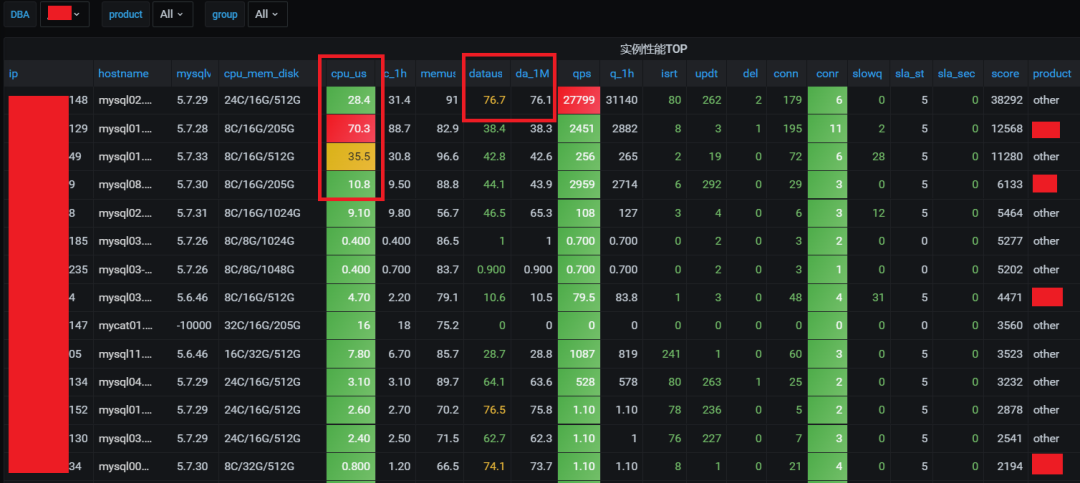
通过数据行列转化,实例健康指数积分计算和排序,风险实例头部展示,临近性能值趋势对比,实时查看实例整体运行情况。
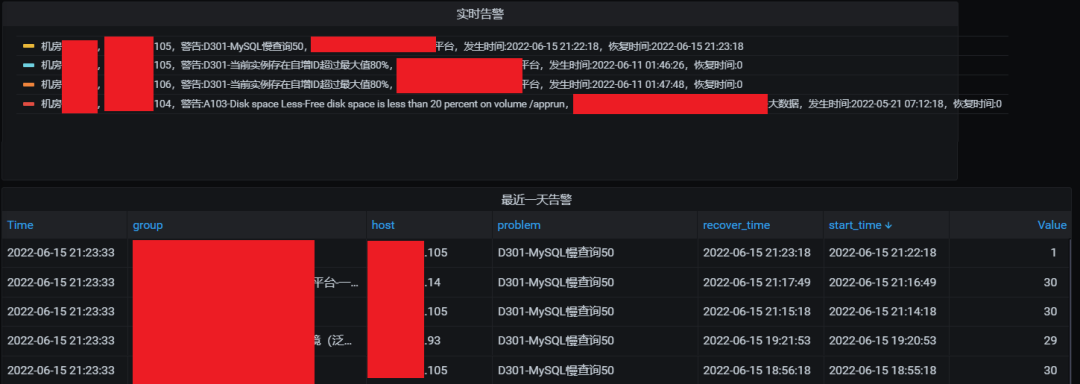
实时聚合多机房zabbix监控告警,集中化展现当前告警项;同时记录历史告警,审计告警趋势。
zabbix和prometheus融合,能够结合zabbix的成熟生态、配置灵活性和Prometheus的存储、展现优势,提供更强大的监控能力,支撑家庭业务百亿级人机物连接相关监控数据存储。单个Prometheus支持百万级Metrics,但随着接入zabbix的增多,监控数据时间存储周期拉长,未来将引入Thanos进行Prometheus长期化存储。同时super_exporter未来对接cmdb系统,匹配更多的业务标签数据,支持更多维的统计计算能力,满足公司不同团队的定制化数据展示需求。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK