

“一句话生成视频”AI 爆火:分辨率达到480×480 只支持中文输入
source link: https://www.cnbeta.com/articles/tech/1276779.htm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
“一句话生成视频”AI 爆火:分辨率达到480×480 只支持中文输入
一周不到,AI 画师又“进阶”了,还是一个大跨步 —— 直接 1 句话生成视频的那种。输入“一个下午在海滩上奔跑的女人”,立刻就蹦出一个 4 秒 32 帧的小片段:

又或是输入“一颗燃烧的心”,就能看见一只被火焰包裹的心:

这个最新的文本-视频生成 AI,是清华 & 智源研究院出品的模型 CogVideo。
Demo 刚放到网上就火了起来,有网友已经急着要论文了:
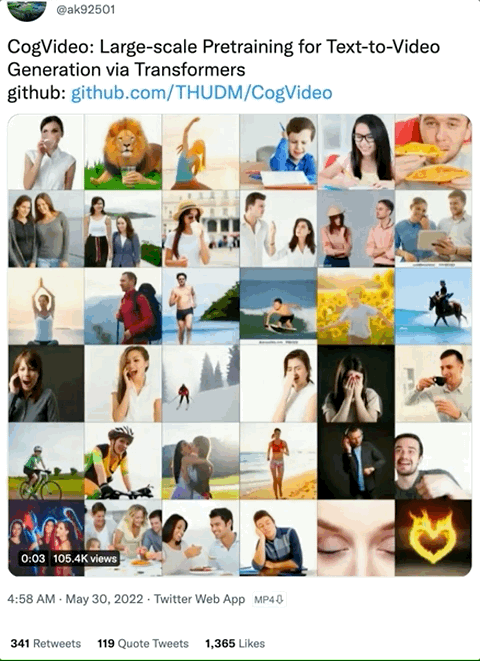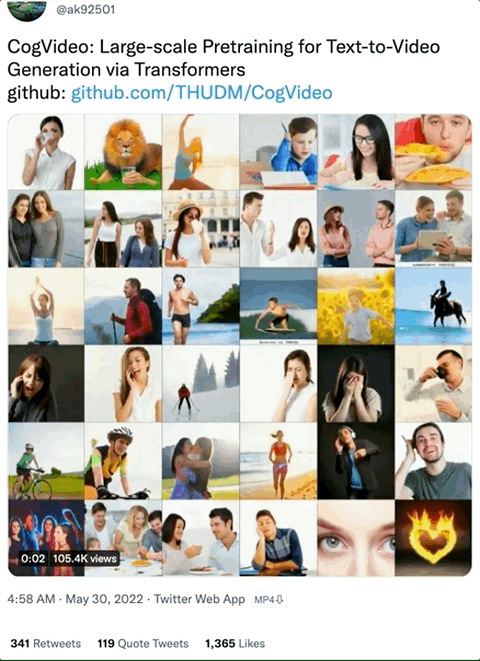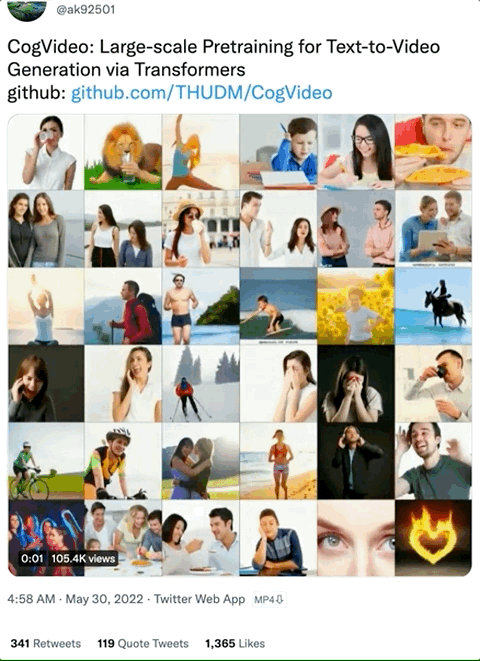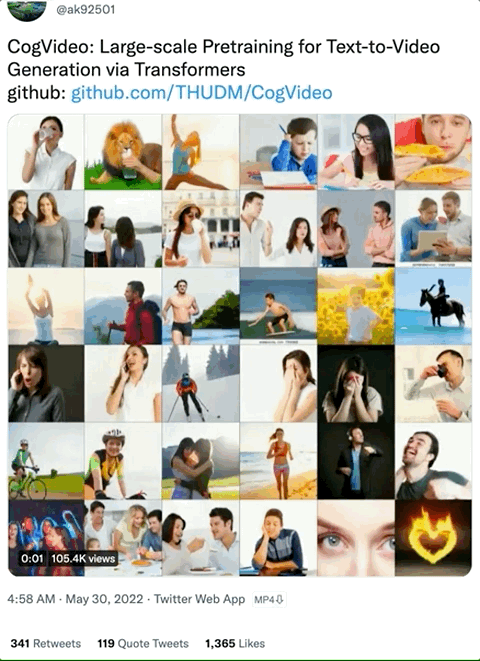

CogVideo“一脉相承”于文本-图像生成模型 CogView2,这个系列的 AI 模型只支持中文输入,外国朋友们想玩还得借助Google翻译:

看完视频的网友直呼“这进展也太快了,要知道文本-图像生成模型 DALL-E2 和 Imagen 才刚出”

还有网友想象:照这个速度发展下去,马上就能看到 AI 一句话生成 VR 头显里的 3D 视频效果了:
所以,这只名叫 CogVideo 的 AI 模型究竟是什么来头?
生成低帧视频后再插帧
团队表示,CogVideo 应该是当前最大的、也是首个开源的文本生成视频模型。
在设计模型上,模型一共有 90 亿参数,基于预训练文本-图像模型 CogView2 打造,一共分为两个模块。
第一部分先基于 CogView2,通过文本生成几帧图像,这时候合成视频的帧率还很低;
第二部分则会基于双向注意力模型对生成的几帧图像进行插帧,来生成帧率更高的完整视频。

在训练上,CogVideo 一共用了 540 万个文本-视频对。
这里不仅仅是直接将文本和视频匹配起来“塞”给 AI,而是需要先将视频拆分成几个帧,并额外给每帧图像添加一个帧标记。
这样就避免了 AI 看见一句话,直接给你生成几张一模一样的视频帧。
其中,每个训练的视频原本是 160×160 分辨率,被 CogView2 上采样(放大图像)至 480×480 分辨率,因此最后生成的也是 480×480 分辨率的视频。
至于 AI 插帧的部分,设计的双向通道注意力模块则是为了让 AI 理解前后帧的语义。

最后,生成的视频就是比较丝滑的效果了,输出的 4 秒视频帧数在 32 张左右。
在人类评估中得分最高
这篇论文同时用数据测试和人类打分两种方法,对模型进行了评估。
研究人员首先将 CogVideo 在 UCF-101 和 Kinetics-600 两个人类动作视频数据集上进行了测试。
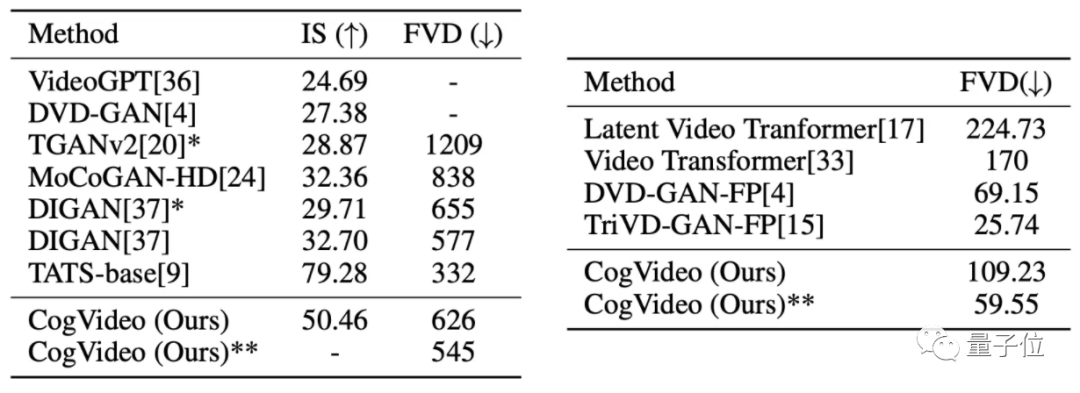
其中,FVD(Fréchet 视频距离)用于评估视频整体生成的质量,数值越低越好;IS(Inception score)主要从清晰度和生成多样性两方面来评估生成图像质量,数值越高越好。
整体来看,CogVideo 生成的视频质量处于中等水平。
但从人类偏好度来看,CogVideo 生成的视频效果就比其他模型要高出不少,甚至在当前最好的几个生成模型之中,取得了最高的分数:
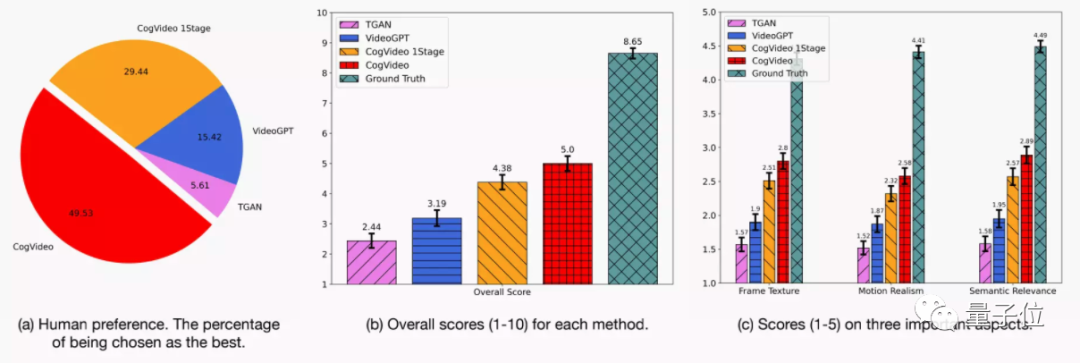
具体来说,研究人员会给志愿者一份打分表,让他们根据视频生成的效果,对几个模型生成的视频进行随机评估,最后判断综合得分:

CogVideo 的共同一作洪文逸和丁铭,以及二作郑问迪,三作 Xinghan Liu 都来自清华大学计算机系。
此前,洪文逸、丁铭和郑问迪也是 CogView 的作者。
论文的指导老师唐杰,清华大学计算机系教授,智源研究院学术副院长,主要研究方向是 AI、数据挖掘、机器学习和知识图谱等。
对于 CogVideo,有网友表示仍然有些地方值得探究,例如 DALL-E2 和 Imagen 都有一些不同寻常的提示词来证明它们是从 0 生成的,但 CogVideo 的效果更像是从数据集中“拼凑”起来的:

例如,狮子直接“用手”喝水的视频,就不太符合我们的常规认知(虽然很搞笑):

(是不是有点像给鸟加上两只手的魔性表情包)

但也有网友指出,这篇论文给语言模型提供了一些新思路:
用视频训练可能会进一步释放语言模型的潜力。因为它不仅有大量的数据,还隐含了一些用文本比较难体现的常识和逻辑。

目前 CogVideo 的代码还在施工中,感兴趣的小伙伴可以去蹲一波了~
项目&论文地址:


Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK