

Tech Talk · 云技术有话聊 | 信服云数仓Dipper背后的“加速”技术
source link: http://www.ciotimes.com/IT/209879.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Tech Talk · 云技术有话聊 | 信服云数仓Dipper背后的“加速”技术 - IT业界_CIO时代网 - CIO时代—新技术、新商业、新管理
Tech Talk · 云技术有话聊 | 信服云数仓Dipper背后的“加速”技术
2022-06-02 15:36:40 来源:
关键词: Tech Talk
一、数据仓库当前面临的挑战
数据仓库是用来存放各个业务系统数据的地方,包括网站的访问日志、业务数据等。基于收集上来的散乱的海量的数据,以数据集成的方式进入到了数据仓库的系统,再进行数据清洗、数据汇聚、数据加工等步骤,进而用于进行大数据分析操作。这些操作都是在数据仓库里面来完成,最后形成集成数据集合,用于支撑各个部门的决策过程。
数据仓库是企业数字化转型里面不可或缺的一部分,这体现在商业智能数据挖掘、数据仪表盘和数据探索这些方面。无论是企业的数据分析师,还是企业的经营决策者,都需要用它来发现商业中可能忽略的问题,实现决策的科学制定。
当前数据仓库的一些需求,其实基本上处理的数据是 PB 级的数据,不仅要负责 PB 级的数据的存储,还要负责 PB 级数据的计算。因为这里计算资源和存储资源比较多,如何通过性价比更高方式来保证数据的存储,保证数据的计算能够是高效的,也是很多企业关心的问题。
要支持这种高性能的这样的查询,对于用户来讲,数据仓库对外的输出的窗口提供这样的功能。所以在高并发聚合分析、亿级别的并发秒级检索、高性能的 AD hoc查询这三方面都要给用户提供一种高性能的体验。
二、数据仓库难点与解决方案
总结起来,用户的痛点分为三方面:多系统带来的运维复杂;查询性能不足;人工建仓成本高。
针对多系统部署、成本高的痛点,信服云提供了一套的一体化智能运维系统。在这个系统里有很多的组件,例如分布式计算引擎,统一的元数据管理引擎,这些引擎在系统中是统一部署的。
根据机器的实际的情况进行参数的调优和配置,实现一键安装。运行过程中出现了问题,也可以及时地发出告警,提醒人员说当前系统可能存在问题。
在这里面,如果是说每套系统发生挂掉的情况,通过高可用机制也能够尽快恢复线上业务的生产,来降低因为系统故障导致的业务中断。
业务系统运行在这样的数据仓库上,就能够保证用户的系统是高可用的,实现智能运维,来降低运维的成本。
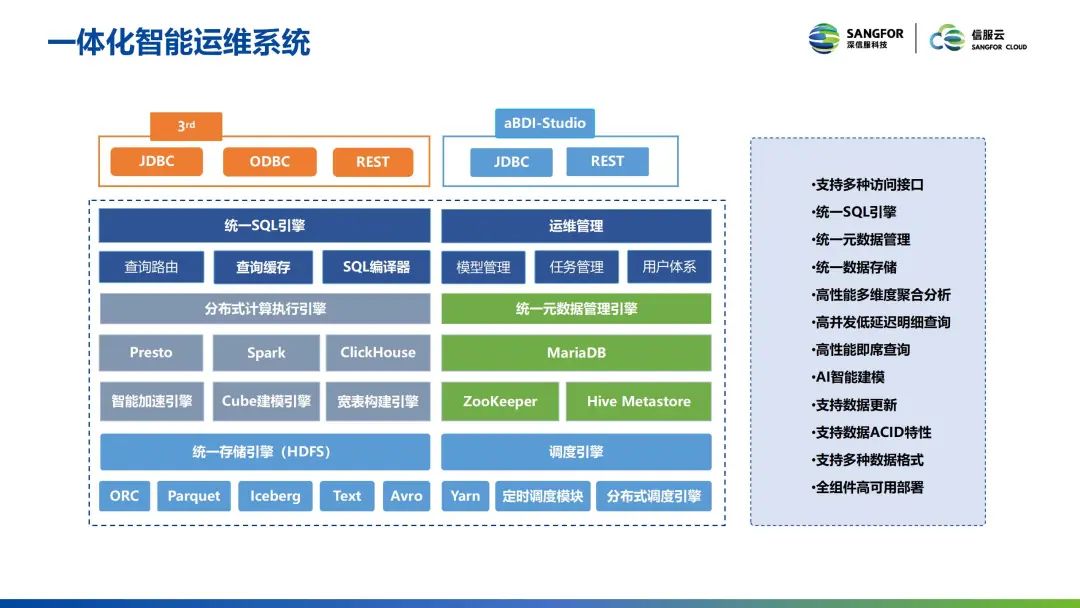
当查询涉及到大批量数据计算或者大批量数据分析时,可以提供Hive 或者是 Spark 这样的分析引擎,限制内存和计算资源的使用情况,保证计算过程的稳定执行。
当涉及聚合查询或者明细查询时,提供提供索引机制,在减小计算数据量的情况下,采用类似于Presto这种引擎,实现低延迟快速的计算。
如果秒级甚至说毫几百毫秒依旧不能满足需求,信服云会给用户开一个高速缓存,并采用内存计算引擎,为用户提供更高并发、更低延迟的查询体验。
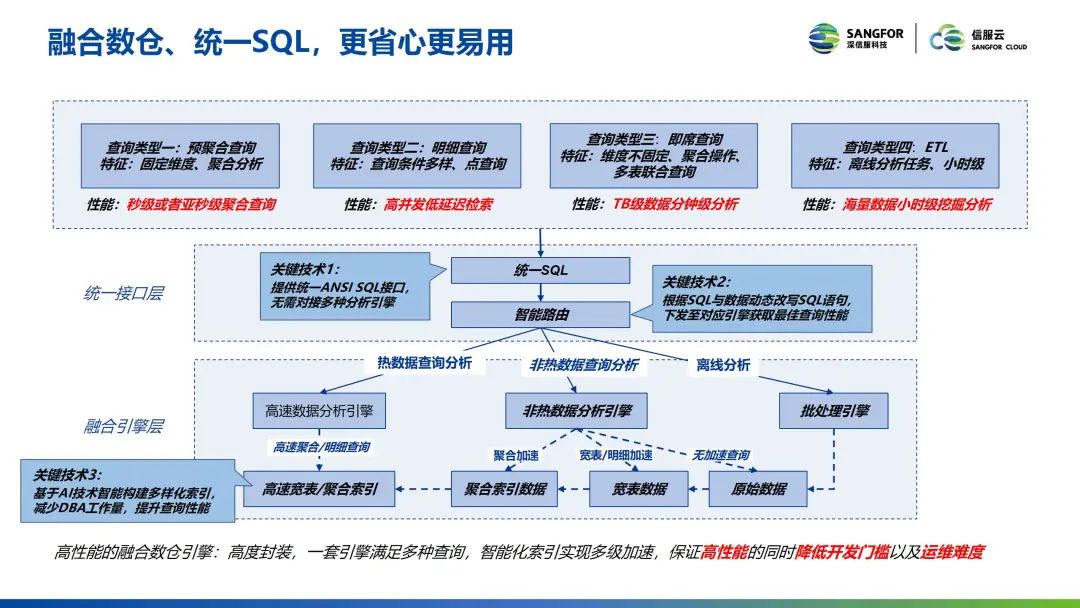
融合数仓的背后有三种关键技术。第一,提供一套 ANSI SQL 接口,无需对接多种分析引擎。尽管下面用到了三个不同的组件,但是对于用户来讲,只要写一套 ANSI SQL 的语法,就能够获得特定的转换,无需用户考虑组件的切换。
第二,提供一套智能路由引擎,对于用户来说,需要人工区分查询的类型,增加了工作量。而信服云提供这套智能路由,它可以通过这种 SQL 语的分析来判断是大批量数据的查询、还是高性能的检索,这个时候可以自动地选择合适的引擎,来达到更优的性能情况。
第三,所有的索引不需要用户来指明说要构建什么索引,在这过程中可以通过 SQL 语句的分析来自适应地为用户建立各种各样的索引。
以电子制造业场景为例,使用了信服云的数据仓库,1万块圆晶芯片能够达到秒级响应,相较于原来的几十分钟的分析速度,提升了用户的检验效率。
在医疗场景下,对于同一套数据存储的明细查询性能,清理缓存之前,可以达到并发500,即使是清理缓存以后,也能达到 200 的并发,超过用户给百级并发秒级响应的预期。
以 IT部门构建的数据中台TiDB 查询引擎场景为例,采用信服云数据仓库后,可以实现大部分的语句的智能聚合索引,从而完成这种自动化建模,这对他们而言起到了加速效果,获得了良好的查询体验。
还有能源、水务、教育、日志分析等场景,信服云的数仓架构都提供了很好的查询体验,高性能的数仓组件大幅度降低了查询的时延,能够在千万级事实数据下达到秒级响应的效果。
以上就是本次直播的主要内容。对于技术内容感兴趣的IT朋友可以关注“深信服科技”公众号回顾本期直播,了解更多技术内容。
第三十四届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK