

周刊(第15期):图解ARIES论文(上)
source link: https://www.codedump.info/post/20220514-weekly-15/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

引言:ARIES(Algorithm for Recovery and Isolation Exploiting Semantics的简称)是论文《ARIES: A Transaction Recovery Method Supporting Fine-Franularity Locking and Partial Rollbacks Using Write-Ahead Logging》中提到的一种存储引擎中数据恢复的算法。这篇论文可以说是存储引擎数据恢复领域必读的一篇论文,这两期的周刊就是对这篇论文的图解,这是其中的上篇。
图解ARIES论文(上)
在展开解释ARIES算法原理之前,需要对Page oriented类存储引擎的日志系统有一定的了解,才能继续解释基于这个日志系统之上做的恢复算法。
在一个存储系统中,出错是非常常见的情况的,这就涉及到出错了之后系统恢复时还需要能继续工作,即数据不能发生破坏导致整个系统跑不起来。
于是,当系统出错需要重启恢复时,就涉及到以下两个动作:
- 撤销(Undo):未完成或者由于各种原因发生的事务,其修改需要被撤销,即回滚为事务之前的旧值。
- 重做(Redo):已经提交的事务,其修改操作的效果需要体现为新值。
来看下图中提出的问题:
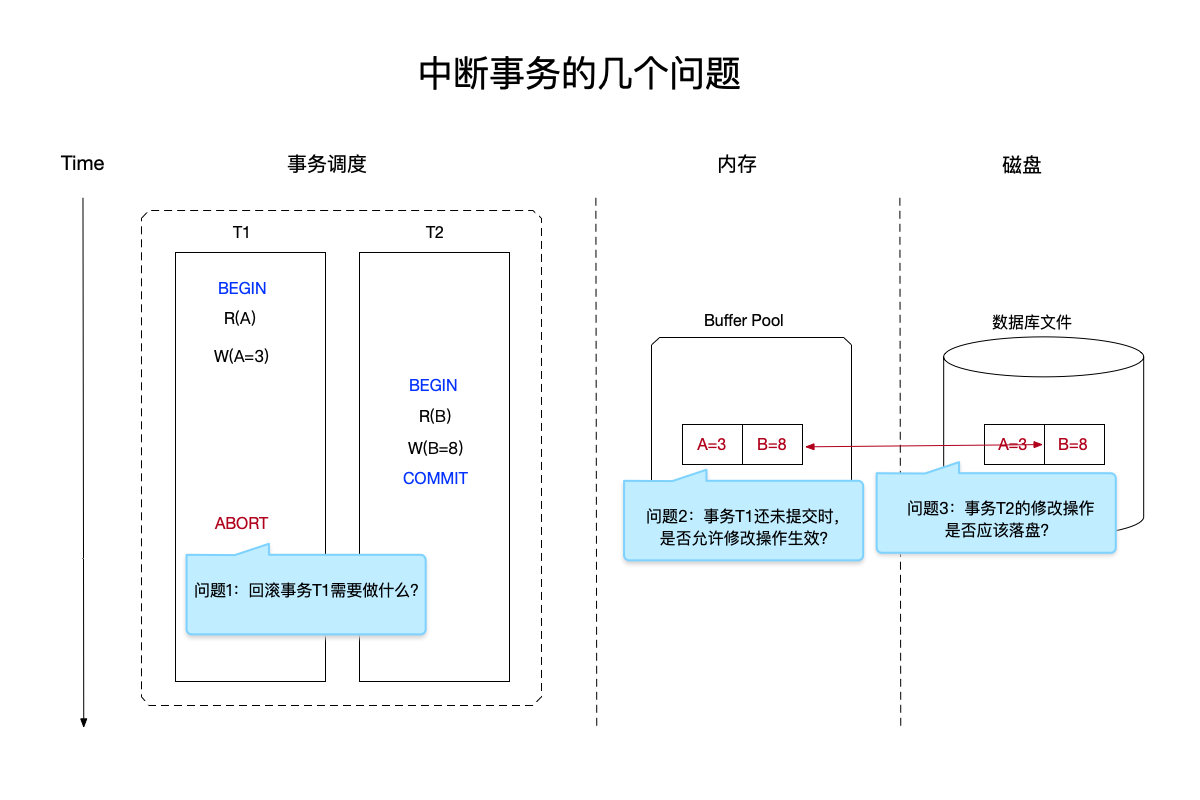
在上图中:
- 存在事务T1和T2在同时执行:
- 事务T1:修改A值为3,但是在事务还未提交前,事务T2开始执行。
- 事务T2:修改B值为8,并且成功提交。
- 事务T1终止:在事务T2成功提交之后,事务T1终止。
这个事务调度的执行顺序引发了以下几个问题:
- 回滚未提交的事务T1需要做什么?
- 对于未提交的事务T1,是否允许其修改操作在持久化存储上生效(即将A修改为3)?
- 在磁盘的数据库文件中,已成功提交的事务T2,其修改操作是否应该立即落盘(即从buffer pool中同步修改的内容到硬盘)。
第一个问题当前暂且放到一边,来看后面两个问题。
“是否允许未提交事务的修改在持久化存储上生效”(Whether the DBMS allows an uncommitted txn to overwrite the most recent committed value of an object in non-volatile storage),被称为Steal policy:
- steal:允许未提交事务的修改持久化存储上生效。
- no steal:反之。
一个事务在提交之前是否需要将所有修改同步到持久化存储上(Whether the DBMS requires that all updates made by a txn are reflected on non-volatile storage before the txn is allowed to commit.),也有两种策略:
- force:必须将事务的所有修改都同步到持久化存储上,事务才被允许提交。
- no-force:反之。
围绕着这两个不同的维度,有了不同的做法。
我们来按照上面的定义,使用no-steal+force的策略,来重新看看前面的问题。
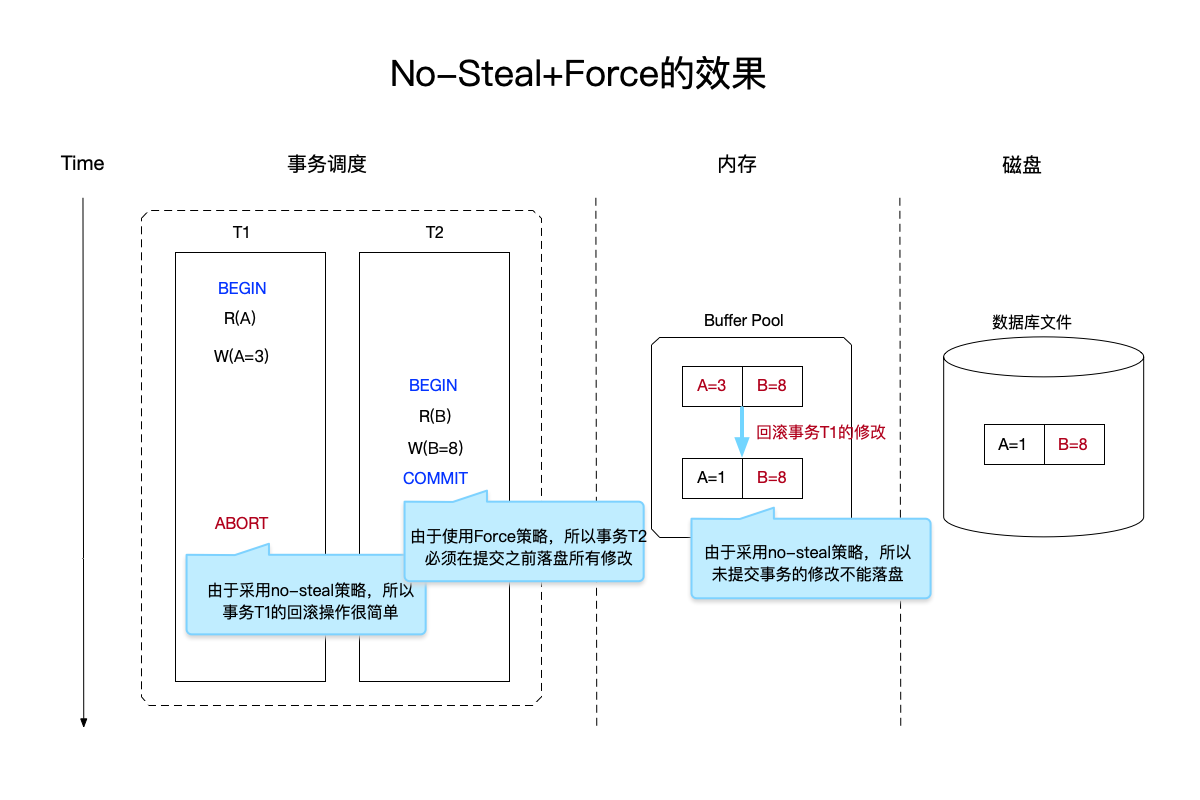
在上图中:
- 事务T1:由于采用no-steal策略,所以对于未能提交的事务T1而言,该事务的修改顶多到内存的buffer pool中,不会在磁盘上生效,因此回滚事务的操作只需要将内存的buffer pool中的数据撤销即可。
- 事务T2:由于采用force策略,因此在事务提交之前,必须将所有修改都同步到磁盘的数据库文件上。
可以看到,使用no-steal+force的策略是相对简单的,因为:
undo操作只需要回滚内存中的数据即可,因为还未同步到磁盘的数据库文件上。- 对于已提交事务而言,无需
redo操作,这是因为事务提交之前必须强制同步所有修改到数据库文件上。
但是,这个策略组合的问题在于:无法支撑一个修改了大量数据的事务。比如假设内存中的buffer pool仅能容纳1K大小的修改缓冲区,而某一个事务一共修改了2K的数据,这时候超过buffer pool大小的数据,是否应该即时落盘?按照这个策略是解决不了这个问题的。
接下来看看两种最常见的做法:
- 影子页面(shadow page)。
- WAL(Write Ahead Log)。
影子页面(shadow page)
影子页面的原理是这样的,维护两个独立的数据库文件的拷贝:
- 主拷贝:只保存已提交事务的修改。
- 影子拷贝:拷贝待修改页面的内容,保存未提交事务的修改。
- 有了两份不同的数据,在进行中的事务只需要修改影子拷贝即可,当未提交事务需要提交时,切换影子拷贝变成主拷贝。
以下图来解释影子页面的工作原理:
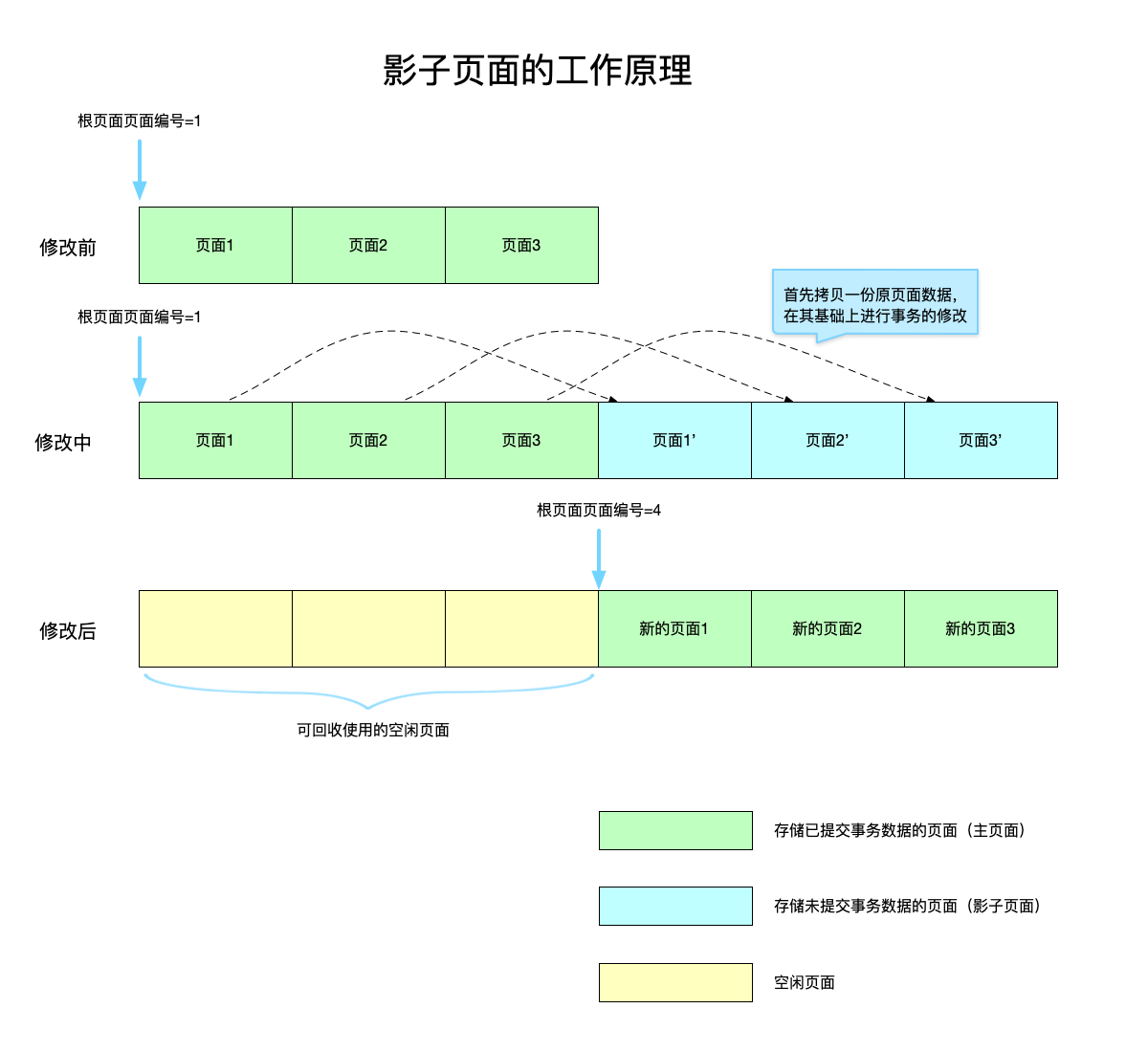
- 分别用三种颜色标记了不同类型的页面:主页面、影子页面、空闲页面,其中空闲页面是被替换出去的主页面,由于已经有新的主页面产生,所以之前的主页面就变成了空闲页面可以重新在下一次生成影子页面的时候使用上。
- 在修改之前,已经存在3个主页面,其中的页面1为当前的根页面。
- 假设一个事务,需要同时修改这三个主页面,系统发现当前没有可用的空闲页面,于是扩展数据库文件生成三个新的物理页面,首先拷贝原页面内容,然后再这个基础上进行事务的修改。
- 当事务修改完成之后,只需要修改根页面为最新的页面1即可,而这次修改中涉及到几个之前的主页面就变成了空闲页面,下一次修改时可以回收利用。
根据前面对两种策略的定义,影子页面属于采用no-steal+force策略的方案:
- no-steal:未提交的时候,不能直接修改变成主页面。
- force:事务提交之前,必须把修改后的影子页面切换为新的主页面。
我们看一看,影子页面的重做和撤销是怎么做的:
- 撤销:只需要将写事务时多分配出来的物理页面再次变成空闲页面即可,下一次可以回收利用。由于没有切换根页面编号,并不需要多做什么其它的工作了。
- 重做:不需要重做操作,因为只要完成了影子页面切换到主页面的操作,就相当于这个事务的修改可见了。
来看看影子页面的问题:
- 既然是“影子”,那么就要求这些页面在修改之前,必须先拷贝一份原始页面的数据,这个代价是很重的。
- 对于类似B-Tree这样的数据结构,这个修改会一直从下往上进行,路径中经过的节点都需要一个影子页面来存储修改。
- 被替换的主页面会产生空闲页面,对应的就需要垃圾回收策略把这些空闲页面给回收利用上。
- 页面内容会碎片化,因为写入的影子页面可能是新增的物理页面,还可能是被回收利用的空闲页面,如果逻辑上相邻的页面在物理上分散,对于读写缓存是不友好的。
- 最后,当数据落盘到影子页面时,本质上还是针对文件的一个随机写,随机写的代价是很大的:需要首先寻址到指定位置,然后再进行修改。
- 同一时间,只允许有一个写事务在进行,因为如果存在多个写事务,而不同写事务又修改了同一个页面的话,是无法处理的。
采用影子页面的例子
之前的博客中分析过boltdb的实现,以及sqlite的journal实现,这两者都是影子页面的例子:
- boltdb 1.3.0实现分析(一):在boltdb中,修改页面之前,首先使用mmap机制复制出来待修改的页面,修改完毕之后统一切换主页面和影子页面,同时将修改之前的主页面设置为空闲页面可供下一次回收利用。
- sqlite3.36版本 btree实现(三)- journal文件备份机制:sqlite的journal文件,负责备份修改的页面在修改前的数据,事务提交之后这些备份的数据就无用了,如果中间事务中断可以直接用journal备份文件的内容来恢复数据库。
感兴趣的,可以由这两篇文章了解更详细的影子页面的实现。不过,影子页面机制的使用已经不多,更多的是下面介绍的WAL。
WAL(Write Ahead Log)
除了shadow paging策略以外,另一种保存修改的策略就是使用WAL(Write Ahead Log),对比前者而言,WAL最大的好处是:由于将修改添加到日志中就可以认为保存修改完成,而在文件尾追加(append)操作对比随机写是相对快很多的。
对于一个写事务而言,如果采用WAL机制,WAL日志的格式有以下三类(后面还会扩展):
- 事务开始时,写入一条
BEGIN表示写事务开始。 - 记录事务的修改操作:对于写事务中的每一条修改操作,都要记下以下四个数据:
- 事务ID,这样在同一时间进行多个写事务时,可以知道对应的是哪个事务。
- 修改的键值。
- 修改之前的值,用于撤掉事务时使用。
- 修改之后的值,用于重做事务时使用。
- 事务提交时,写入一条
COMMIT表示事务结束。
如下图中演示了之前的两个写事务使用WAL策略:
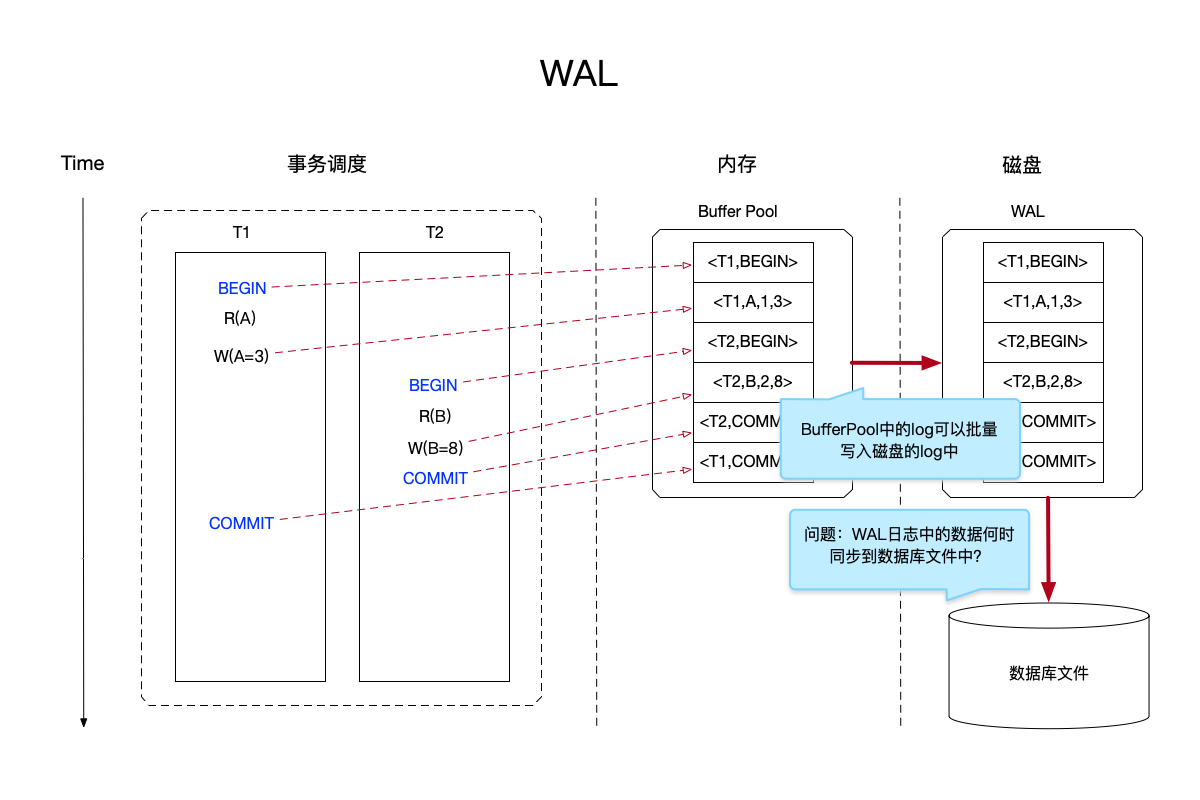
在上图中:
- 同时并发了两个写事务,每个写事务的三类不同的日志,都需要写到内存的buffer pool中,日志的格式已经在上面给出来。
- 磁盘上存储的文件,除了之前的数据库文件之外,新增了一个叫WAL的日志文件,这个文件不会随机写,只会按照buffer pool中记录的日志顺序添加到文件结尾处。
- 一个写事务的操作日志,首先会记录到buffer pool中,而不必立即同步到wal日志中,buffer pool中的日志同步到wal的操作,可以批量一次性写多多条记录,又进一步提升了写操作的效率。
- 采用WAL策略之后,一个写操作完成不要求一定要将修改同步到数据库文件中,只需要所有该事务的操作都写入WAL文件即可。
这里需要说明的是,前面提到steal以及force这两个维度的策略时,都与是否需要同步数据到持久化存储有关。但是,在WAL中,由于新增了WAL文件,而这个文件本身也是保存在持久化存储中的,所以持久化存储文件这个概念的范畴,从仅有数据库文件,扩展到了数据库文件和WAL文件。
于是,从上面对WAL的分析可以看到,WAL是steal+no-force的策略:
- steal:允许未提交事务的修改操作同步到磁盘的WAL文件中。
- no-force:事务提交之前,必须所有的修改操作都写入磁盘的WAL中才能提交,但并不要求一定要落入数据库文件。
由于持久化存储包括了WAL文件和数据库文件,即可以认为任意时刻的数据为:数据库文件 + WAL中的已提交事务数据,于是查询一个数据时就需要在这两类文件中依次查询:
- 首先到WAL中查询已提交的事务数据。
- 如果第一步没有查到,说明WAL中并没有对这个数据的修改,于是到数据库文件中查询数据。
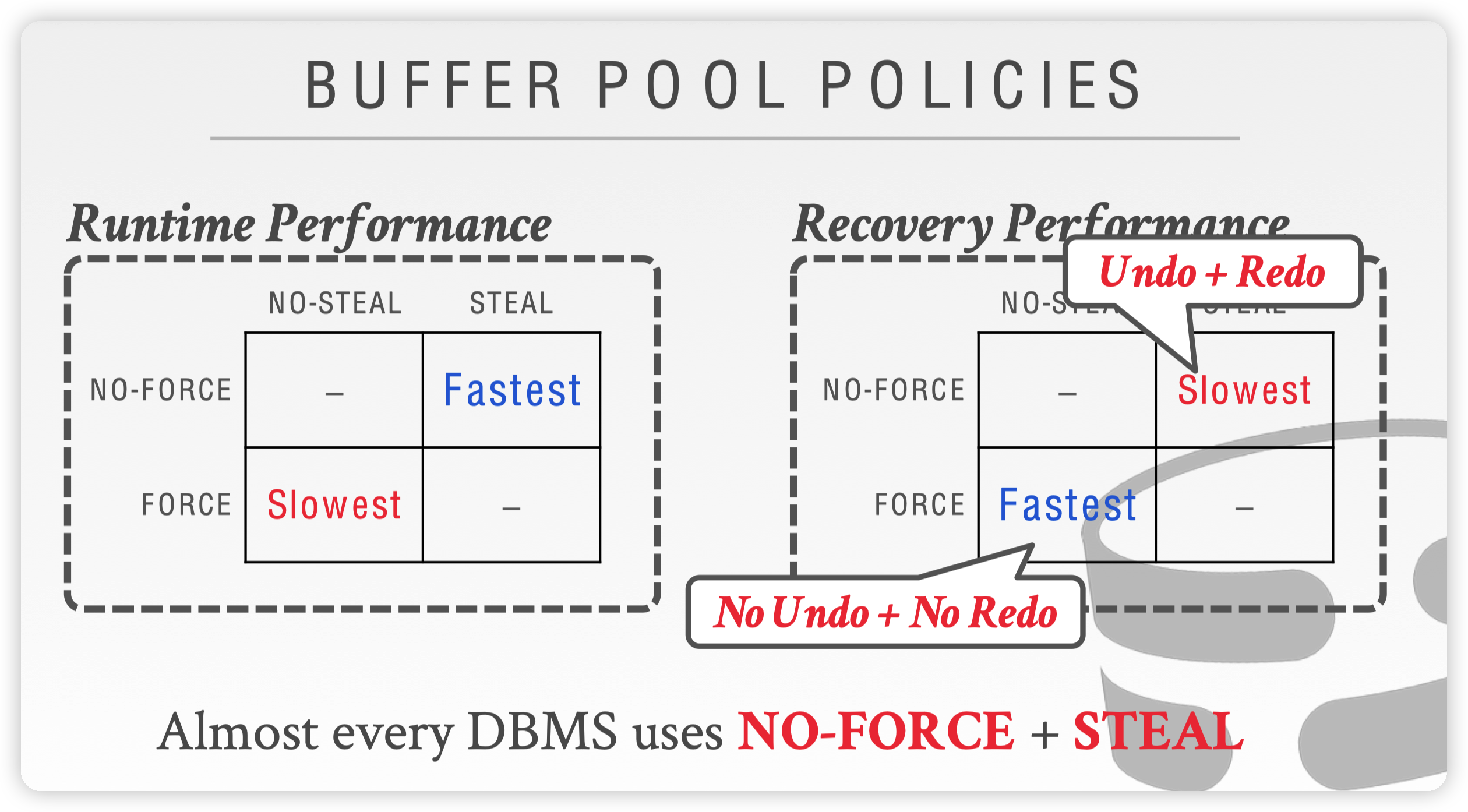
从上面对影子页面和WAL的分析可以看出来,以steal和force两个策略的维度组合(一共四个组合,见下图)来看:
- 运行时效率:
steal+no-force是最快的,而no-steal+force则是最慢的。 - 恢复时效率:对比运行时效率,恢复时的效率就反过来了,
steal+no-force是最慢的,而no-steal+force则是最快的,原因在于前者需要执行undo、redo操作,而后者则不需要。
Checkpoint(检查点)
前面提到过,采用了WAL策略的数据库,任意时刻的数据为:数据库文件 + WAL中的已提交事务数据。
但是WAL文件不可能一直增长下去,否则一来文件太大,导致影响读性能,二来数据恢复的时候时间过长。所以,每隔一段时间,都需要将WAL文件中的已提交事务数据落盘到数据库文件中,这个流程被称为checkpoint。
为了做checkpoint操作,需要新增一类checkpoint日志,结合前面提到的几类WAL日志,如下:
- 事务开始时,写入一条
BEGIN表示写事务开始。 - 记录事务的修改操作:对于写事务中的每一条修改操作,都要记下以下四个数据:
- 事务ID,这样在同一时间进行多个写事务时,可以知道对应的是哪个事务。
- 修改的键值。
- 修改之前的值,用于撤掉事务时使用。
- 修改之后的值,用于重做事务时使用。
- 事务提交时,写入一条
COMMIT表示事务结束。 - 做
checkpoint时,写入一条CHECKPOINT表示在这个点做了checkpoint操作。
来看看有了checkpoint操作之后,如何处理恢复问题,如下图所示:
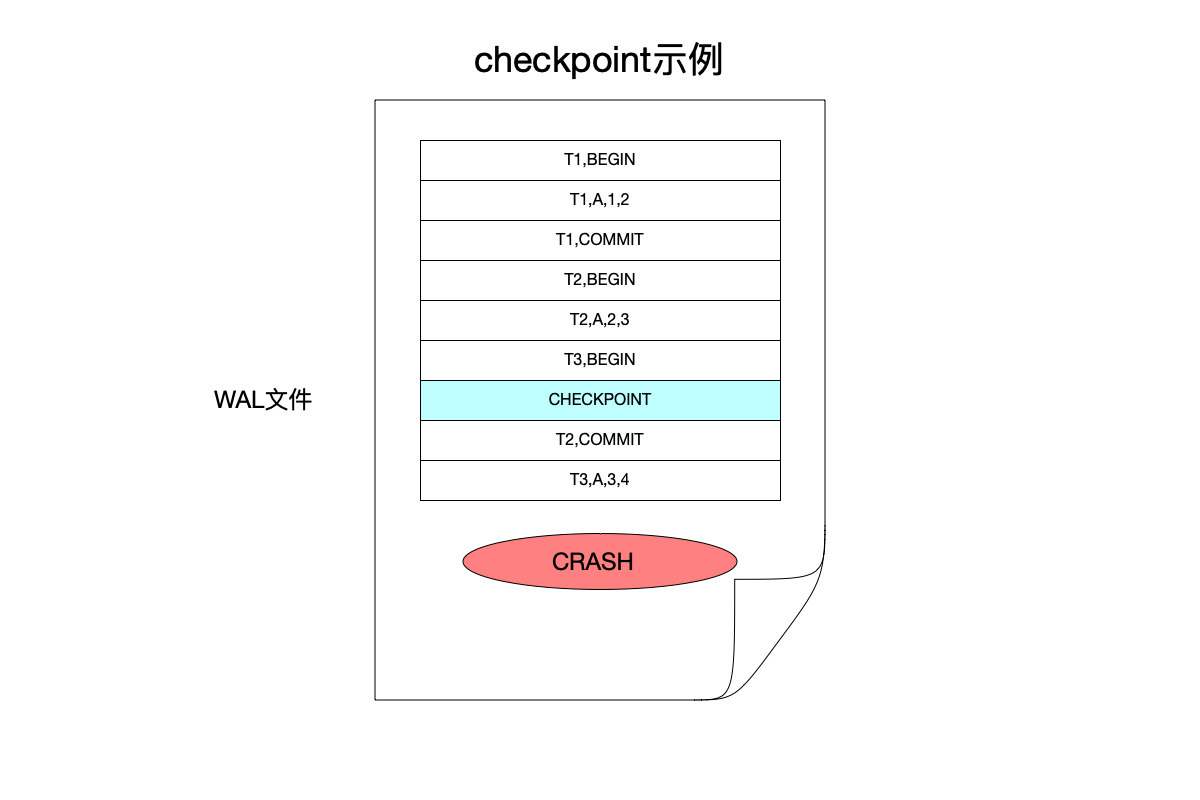
在上图中:
- 事务T1提交之后,又开始了事务T2、T3,在T2、T3未提交之前,开始了一个
checkpoint操作。 checkpoint完成之后,T2完成提交。但是在T3修改之后,就发生了宕机。
此时,如果进行数据恢复的话:
- 数据库文件中已经有事务T1的修改了,因为T1是在
checkpoint之前提交的事务,所以这个事务的修改会在checkpoint的时候同步到数据库文件中。但是T2、T3这两个在checkpoint时还未完成的事务,并不会在这一次checkpoint时同步到数据库文件。 - 由于WAL中存在事务T2的
COMMIT日志,表示事务T2已经完成提交,所以在系统恢复时:- 找到崩溃之前最后一次
checkpoint的位置,针对这个checkpoint之后的日志,进行如下的操作。 - 对于存在
COMMIT日志的事务,比如事务T2,只需重放其WAL日志即可。 - 对于不存在
COMMIT日志的事务,比如事务T3,不能重放这个事务,因为在崩溃之前没有落盘所有的修改在WAL中。
- 找到崩溃之前最后一次
这里的checkpoint流程中,存在一个明显的问题:要求checkpoint在进行的时候,不得有任何的写事务在进行,换言之checkpoint操作会影响写事务的进行。所以,如果checkpoint的频率太高,影响写事务;频率太低,又会让单次checkpoint时间很长。
下一期周刊会在此基础上介绍ARIES论文的思想,论文中给出了checkpoint的优化做法。
使用WAL的例子
在sqlite的3.7.0版本之后,就采用了WAL机制,之前也写过文章分析,见sqlite3.36版本 btree实现(四)- WAL的实现
- 按照落盘的策略,分为了
steal和force这两个维度。 - shadow page采用的是
no-steal+force策略,而WAL采用的是steal+no-force策略。
《纳瓦尔宝典》
《纳瓦尔宝典》是投资人Naval Ravikant的箴言记录,最早知道此人是因为他的那篇被和菜头翻译成中文的文章《如何不靠运气致富》:
再后来, Eric Jorgenson将Naval的推特文字整理成了《Almanack of Naval Ravikant》,免费电子版在网上完全公开:Almanack of Naval Ravikant
最近,中文版的《纳瓦尔宝典》也被翻译出版了:纳瓦尔宝典 (豆瓣)
《C语言编程透视》
C的语法糖不多,语法层面要学习的东西也实在不多,但是C的难点主要是和系统打交道层面的,这篇文档就专注在这方面的解释上,算是这方面比较少见的文档了。
github地址:https://github.com/tinyclub/open-c-book
《Rust, Databend and the Cloud Warehouse(5)从 Git 到 Fuse Engine 存储引擎》
虎哥的大作Rust, Databend and the Cloud Warehouse(5)从 Git 到 Fuse Engine 存储引擎 [ 虎哥的博客 ]
这名“业余”程序员,曾用50张1080Ti对抗癌症。
一位业余程序员,使用人工智能的算法来识别肿瘤,很佩服他的行动力。
作者在V2EX的原贴:记得 4 年前我做的 AI 乳腺平台吗?这是我的新项目 - V2EX
四年前的原贴:在 D 版发过了,不过因为不少朋友看不到 D 版,我就放在这里吧,说说我最近做的这个 Project - V2EX
</article
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK