

关于 Kafka 应用开发知识点的整理(二)
source link: https://pandaychen.github.io/2022/01/01/A-KAFKA-USAGE-SUMUP-2/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
0x00 前言
本篇文章,总结下在项目中使用 sarama-kafka 库的一些经验及对 Kafka 集群高可用的一些认识。核心围绕着:我们如何主动感知到 push 到 kafka 的消息哪些未被消费(生产到消费的各个环节)以及如何避免这种情况的
0x01 Kafka 的基本概念
回顾下 kakfa 的架构:
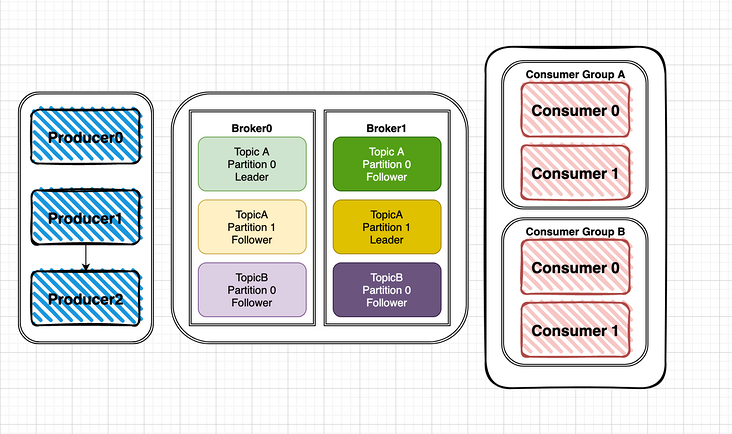
- Producer:生产者,可以将数据发布到所选择的 topic 中
- Consumer:消费者,可以使用 Consumer Group 进行标识,在 topic 中的每条记录都会被分配给订阅消费组中的一个消费者实例,消费者实例可以分布在多个进程中或者多个机器上
- Broker:消息中间件处理节点(服务器),一个节点就是一个 broker,一个 Kafka 集群由一个或多个 broker 组成
那么,对 Kakfa 的可用性主要着眼于下面几个环节:
- 集群中的部分或全部 Broker 故障引发的可用性问题,包括某个 broker 在消息尚未从内存缓冲区持久化到硬盘前就故障的情况
- Producer 发送消息的可靠性,包括下面几种
- producer 把消息发送给 broker,因为网络抖动,消息没有到达 broker,且开发人员无感知
- Consumer 成功 pull 到了消息未处理,然后 consumer 重启
0x02 Kafka 生产者的可靠性
Producer 可以认为 partition 是一个大的串行文件,msg 存储时被分配一个唯一的 offset。 Offset 是一个逻辑意义上的偏移,用于区分每一条消息;而 partition 本身作为文件,可以有多个多个副本 replica(leader/follower)。 多个 replica 分布在在不同的 broker 上。
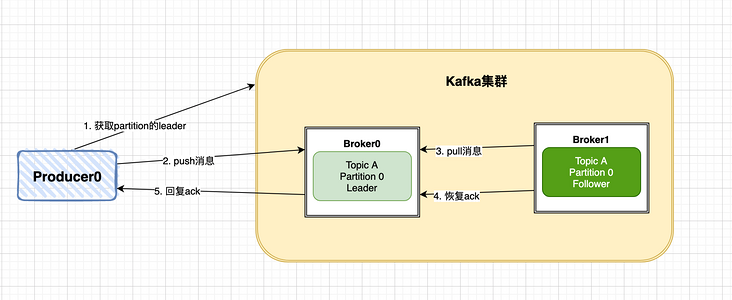
Producer 的写入流程大概如下,最终会返回一个 ack 来告知 producer 确认推送消息结果:
- producer 先从 kafka 集群找到该 partition 的 leader
- producer 将消息发送给 leader,leader 将该消息写入本地
- 各个 follwers 从 leader pull 消息,写入本地 log 后向 leader 发送 ack
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 high watermark,并向 producer 发送 ack
从上面可知,ack 的选择影响生产者的可靠性,kafka 支持如下几种 ack 模式:
Request.required.acks = -1 #全量同步确认,强可靠性保证(当所有的 leader 和 follower 都接收成功时)#WaitForAll
Request.required.acks = 1 #leader 确认收到, 默认(仅 leader 反馈)#WaitForLocal
Request.required.acks = 0 #不确认,但是吞吐量大(不 care 结果) #NoResponse
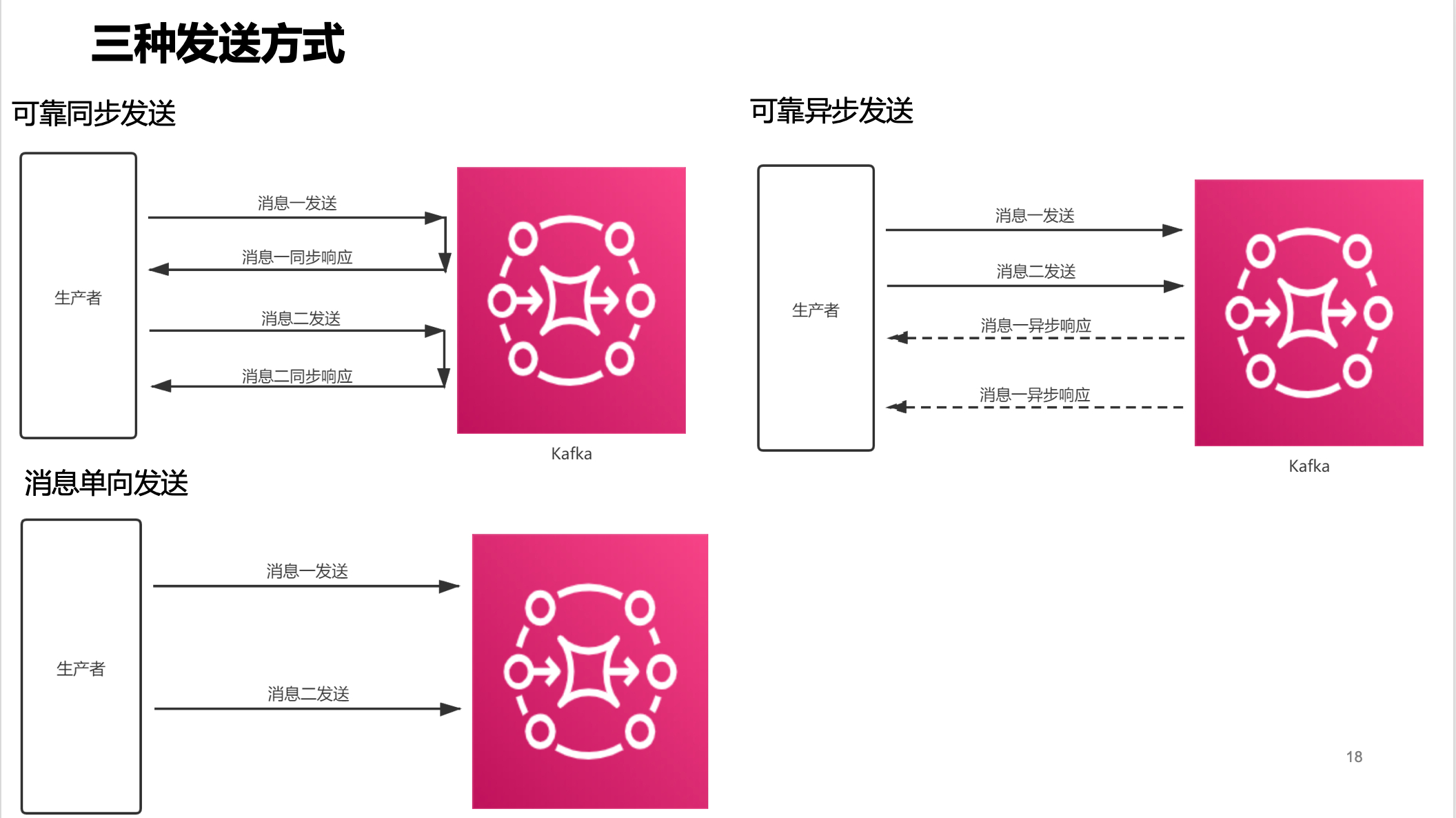
总结下 kafka 支持的三种发送方式(非 ack 模式)的对比以及使用场景如下:
- 可靠同步发送:适合场景最为广泛,如注册的短信、订单信息等
- 可靠异步发送:用于链路耗时比较长的场景,对 RT 较为敏感的业务
- 消息单向发送:适用于耗时非常短,但是对可靠性要求不高的场景,如日志收集等场景
| 发送方式 | 发送 TPS | 发送结果反馈 | 可靠性 |
|---|---|---|---|
| 可靠同步发送 | 快 | Yes | 不丢失 |
| 可靠异步发送 | 快 | Yes | 不丢失 |
| 消息单向发送(不确认) | 最快 | No | 可能丢失 |
sarama 库的设置
如上描述,在 sarama 库的 producer 实现中,通过采用 WaitForAll 方式再加重试逻辑来实现 producer 的可靠:
- 通过设置
RequiredAcks模式来解决,选用WaitForAll保证数据推送成功,不过会影响时延时 - 引入重试机制,设置重试次数和重试间隔
部分代码摘要如下:
const (
// NoResponse doesn't send any response, the TCP ACK is all you get.
NoResponse RequiredAcks = 0
// WaitForLocal waits for only the local commit to succeed before responding.
WaitForLocal RequiredAcks = 1
// WaitForAll waits for all in-sync replicas to commit before responding.
// The minimum number of in-sync replicas is configured on the broker via
// the `min.insync.replicas` configuration key.
WaitForAll RequiredAcks = -1
)
func NewAsyncProducer() sarama.AsyncProducer {
cfg := sarama.NewConfig()
version, err := sarama.ParseKafkaVersion(VERSION)
if err != nil{
return nil
}
cfg.Version = version
cfg.Producer.RequiredAcks = sarama.WaitForAll // 选择 Request.required.acks = -1
cfg.Producer.Partitioner = sarama.NewHashPartitioner
cfg.Producer.Return.Successes = true
cfg.Producer.Return.Errors = true
cfg.Producer.Retry.Max = 3 // 设置重试次数
cfg.Producer.Retry.Backoff = 100 * time.Millisecond
cli, err := sarama.NewAsyncProducer([]string{KAFKA_ADDR}, cfg)
if err != nil{
log.Fatal("NewAsyncProducer failed", err.Error())
return nil
}
return cli
}
0x03 kafka 的生产消息顺序问题
如何确保一个 topic 下的数据,在 Consumer 消费时如何确保逻辑有序?回想 Kafka 的消息在一个 partition 中是有序的,所以只要确保需要保序的数据流都在同一个 partition 中即可。有下面几种方案:
1、全局一个 partition,不推荐,失去了多 partition 的并发优点,此模型下 Kafka 的吞吐存在瓶颈
2、初始化多个 partition,手动指定消息生产 push 的分区,该方法的缺点是分区数是写死的,不利于动态分区调整
msg := &sarama.ProducerMessage{
Topic: "some_topic",
Value: sarama.StringEncoder("hellokafka"),
Partition: someId % 10, // 通过制定分区 partition,根据某个固定的 id 去模,这样该 id 的消息就会发送到一个 partition
}
partition, offset, err := producer.SendMessage(msg)
3、初始化多个 partition,通过 kafka 客户端内置的分区 hash 自动计算
// 初始化 sarama 库的时候,设置选择分区的策略为 Hash
p.config.Producer.Partitioner = sarama.NewHashPartitioner
// 在生成消息之前,设置消息的 Key 值
msg := &sarama.ProducerMessage{
Topic: "some_topic",
Value: sarama.StringEncoder("hellokafka"),
Key: sarama.StringEncoder(someId), // 注意!需要指定 key,Kafka 客户端会根据 Key 进行 Hash,someId 的消息会落到同一个 partition
}
关于分区的细节
这里特别需要注意 hash 算法的选择!由于 kafka 的 partition 计算,消费者组的 partition 指定都是依赖于 client 端的,所以不同语言(如 java/golang 等)对同一个 key,采用不同的 hash 算法计算得到的分区结果是不一定相同的,曾经遇见过这种 Case:用户侧产生的相同消息(key 相同)最终落到的不同的 partition,原因是因为使用了不同语言的客户端计算的消息,最终 key 的结果是不一样的(由于 Hash 算法不同,得到 key 不同,最终落到不同的 partition)。
一般记住下面的规则就好(以 java 客户端为例),三大类 partition 计算方案:
- 消息 msg 指定 partition 就使用指定的 partition(第二种方法)进行发送
- 消息 msg 没有指定 partition 且没有指定 Partitioner(partition 选择器),又分为
2种情况:- 指定 Key:对 key 进行 hash 取模 详见:
org.apache.kafka.clients.producer.internals.DefaultPartitioner - 没有指定 Key: 轮询方式
- 指定 Key:对 key 进行 hash 取模 详见:
- 自定义 Partitioner(partition 选择器,第三种方法)
0x04 Kafka 消费者的可靠性
Consumer 的一般消费流程如下:
消费者在 pull 到某个消息后,可以设置自动提交或者手动提交 commit,提交 commit 成功,消费者 offset 就会发生偏移,数据处理在提交 commit 前后,此时消费者发生了重启,就会导致消费者 offset 与预期不符。Consumer 需要关注如下问题:
- 何时消费,消费到什么?
- 消费是否会丢?
- 是否有重复消费?(单个 Msg 被消费至少
2次)
消费者语义
kafka 支持 3 种消息投递语义,Consumer 的可靠性策略集中在此 3 种语义上:
- At most once:最多一次,消息可能会丢失,但不会重复
- At least once:最少一次,消息不会丢失,可能会重复(在笔者项目中,目前均使用 At least once 的模型)
- Exactly once:只且一次,消息不丢失不重复,只且消费一次(不讨论)
At least once(手动 Commit,在业务逻辑中完成)
这是通常的消费者方法,先获取数据,再进行业务处理,业务处理成功后再提交 commit offset。不过,存在异常情况,如消费者处理消息,业务处理成功后,更新 offset 失败,此时消费者重启的话,会重复消费(从 partition 中读到的 offset 还是旧的)。配置如下:
enable.auto.commit = false
此场景下,业务开发需要在消费到消息业务逻辑处理整个流程完成后进行手动提交。如果在流程未处理结束时发生重启,则之前消费到未提交的消息会重新消费到。在 sarama-kafka 库中,有如下的配置选项:
sarama.offset.initial = OffsetNewest // 可选 OffsetOldest、OffsetNewest
offsets.retention.minutes = 1440s
- OffsetOldest:代表消费者可以访问到的 topic 里的最早的消息,大于 commit 的位置,但是小于 HW。同时也受到 broker 上消息保留时间的影响和位移保留时间的影响(不能保证一定能消费到 topic 起始位置的消息)
- OffsetNewest:代表访问 commit 位置的下一条消息
如果发生 consumer 重启且 enable.auto.commit 没有设置为 false, 则之前的消息会发生丢失,再也消费不到了。在业务环境不稳定或非持久化 consumer 实例的场景下,应特别注意。
At most once(自动提交,AutoCommit)
此方法下先获取数据,再提交 commit offset,最后进行业务处理。异常情况下,消费者处理消息,先更新 offset,再做业务处理,做业务处理失败,消费者重启,消息就丢了。配置选项如下:
enable.auto.commit = true
auto.commit.interval.ms = 1s #假设是 1s 提交一次
上述配置的 consumer 收到消息就返回正确给 broker, 但是如果业务逻辑没有走完中断了,实际上这个消息没有消费成功。这种场景适用于可靠性要求不高的业务。其中 auto.commit.interval.ms 代表了自动提交的间隔。比如设置为 1s 提交 1 次,那么在 1s 内的故障重启,会从当前消费 offset 进行重新消费时,1s 内未提交但是已经消费的 Msg, 会被重新消费。
Exactly once
最可靠的语义,不过实现较复杂。首先要保证消息不丢,再保证不重复(需要 msg 持久化且满足 commit 原子性)。即首先要消费消息并且提交保证不会重复投递,其次提交前要完成整体的业务逻辑关于消息的处理。一些折中的办法是在 At least once 的语义上优化:
- 保证生产者的幂等性
- 进行原子性的消息存储,业务逻辑异步慢慢的从存储中取出消息进行处理
消费者组提交 offset(位移)
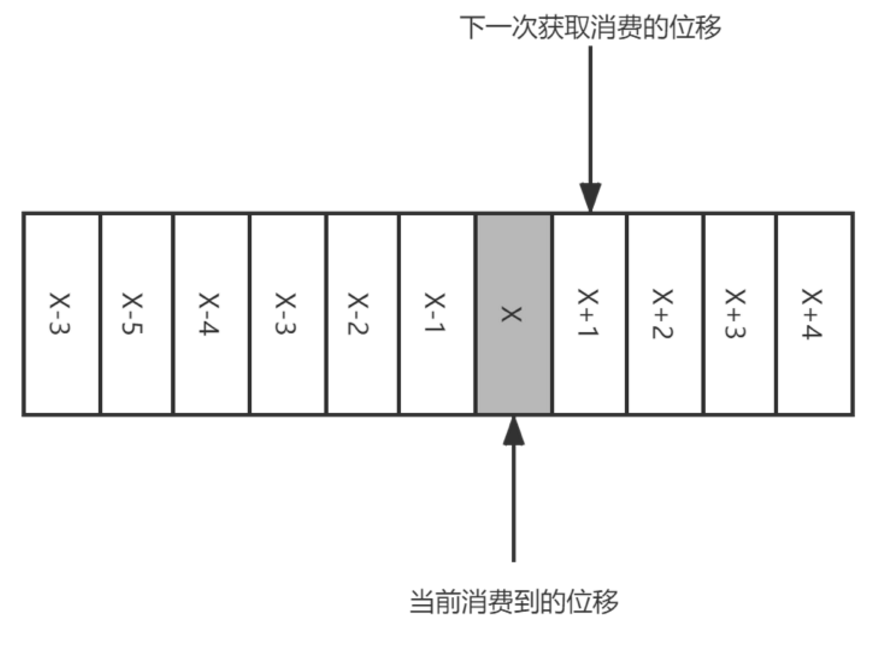
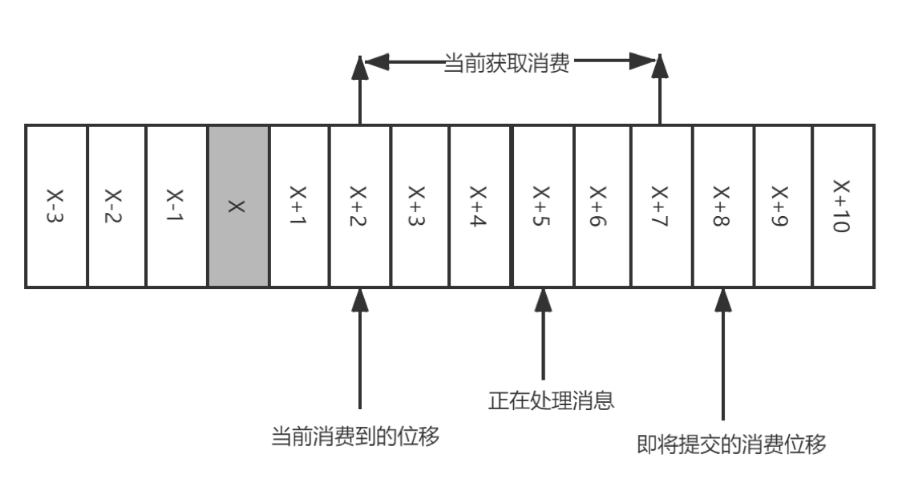
Consumr offset 代表了 kafka Consumer Group 保存其消费的进度,既然是主动提交,在临界点就会发生下面两种问题:
-
重复消费:如果提交的偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量直接的消息就会被重复处理。如,位移提交的动作在消费完所有拉取到的消息后才执行,那么当消费到
X+5时候遇到异常。当故障恢复后,重新拉取消息是从X+2开始,导致X+2至X+4之间的消息重新消费一遍 -
消息丢失:如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量直接的消息将会丢失。如,拉取完成消息后不等消息确认完成消费既执行提交。如图,拉取
[X+2,X+7]后提交位移X+8,当执行到X+5时候出现异常,当故障恢复后重新拉取消息是从X+8开始,那么[X+5,X+7]之间的消息是未能被消费
0x05 Kafka 的幂等性以及实现
在项目中,一般遵循的原则是,相比数据丢失,重复投递 / 消费是符合业务预期的,可以通过一些幂等性设计来规避这个问题。本小节来分析下如下设计 Kafka 的幂等性。
重复消费的问题以及解决
解决 Consumer 端幂等性的问题,得结合业务的特性来实现,举几个例子:
- 若数据不需要持久化(或者有
TTL的数据),可以使用 redis 的SET数据结构来实现重复消费的去重 - 数据需要持久化时,对数据绑定(或计算)
UUID,分布式的场景可以使用 snowflake 算法生成唯一 Id。然后再使用 MySQL 的UNIQUE KEY配合INSERT INTO ... ON DUPLICATE KEY UPDATE等方式来去重
0x06 让人讨厌的 Rebalance(重平衡)
Rebalance 介绍及弊端
什么是 Rebalance?多个 Consumer 订阅了一个 Topic 时,Coordinator 根据分区策略进行消费者订阅分区的重分配。Rebalance 本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 实例如何达成一致(共识),来分配订阅 Topic 的每个分区。Coordinator 即协调者,它专门为 Consumer Group 服务,负责为 Group 执行 Rebalance 以及提供位移管理和组成员管理等。
在整个 Rebalance 过程中,所有 Consumer 实例都不能消费任何消息,会影响到业务消息的正常消费。如果 Consumer Group 下的 Consumer 实例数量发生变化,这是 Rebalance 发生的最常见的原因(约 99%)。在现网中要尽量避免 Rebalance:
- Rebalance 会影响 Consumer 端 TPS,影响整体消费端性能
- Rebalance 过程耗时一般比较长,效率不高
- Rebalance 时所有 Consumer 都要参与,有可能每个 Consumer 都需要重新抢占分区来重新进行消费
Rebalance 的原因
Rebalance 触发的原因一般有如下几种:
- Case1:consumer group 的 topic 订阅发生变更,比如基于正则表达式订阅,当匹配到新的 topic 创建时,consumer group 的订阅就会发生变更
- Case2:consumer group 的 topic 分区 partition 数发生变更,通过命令行脚本增加了订阅 topic 的分区 partition 数
- Case3:consumer group 成员发生变更,成员数量发生变化,包含两种:
- 新加入组(增加同 groupId 的 Consumer 成员),为了增加 TPS / 提高伸缩性的需要,此时 Coordinator 会接纳这个新的 Consumer 实例,继而引发 Rebalance,这是符合预期的;
- 离开组(非预期的),成员减少
前两者都是主动操作触发的(不可避免),这里暂不讨论;这里主要讨论第 3 种,即如何优化(避免)组成员数量减少而引发的 Rebalance 的场景,一般又包含如下 2 种场景:
- 开发者自行停掉某些 Consumer 实例,这种属于正常现象
- Consumer 实例会被 Coordinator 错误地认为已停止从而被踢出 Group,这里讨论如何优化此类非必要 Rebalance 场景
先描述下和 rebalance 相关的几个 Consumer 的重要参数:
session.timeout.ms:此参数决定了 Consumer 存活性的时间间隔。当 Consumer Group 完成 Rebalance 之后,每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求,表明它还存活着。如果某个 Consumer 实例不能及时地发送这些心跳请求,Coordinator 就会认为该 Consumer 已经离线了,从而将其从 Group 中移除,然后开启新一轮 Rebalance。默认值为10s,即如果 Coordinator 在10s之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了。heartbeat.interval.ms:此参数提供了一个允许你控制发送心跳请求频率。该值设置得越小,Consumer 实例发送心跳请求的频率就越高。频繁地发送心跳请求会额外消耗带宽资源,但好处是能够更加快速地知晓当前是否开启 Rebalance,因为,目前 Coordinator 通知各个 Consumer 实例开启 Rebalance 的方法,就是将REBALANCE_NEEDED标志封装进心跳请求的响应体中max.poll.interval.ms:此参数用于控制 Consumer 实际消费能力对 Rebalance 的影响,默认为5min。它限定了 Consumer 端应用程序两次调用 poll 方法的最大时间间隔。当前的 Consumer 程序如果在5min之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起离开组的请求,Coordinator 也会开启新一轮 Rebalance
避免 Rebalance 的方法
在现网中,如何避免消费客户端频繁出现 Rebalance?基于以上描述,有两类非必要的 Rebalance 场景需要优化,如下:
- 因 Consumer 未能及时发送心跳,导致 Consumer 被踢出 Group 而引发的 Rebalance
- 设置
session.timeout.ms = 6s - 设置
heartbeat.interval.ms = 2s - 保证 Consumer 实例在被判定为离线之前,能够发送至少
3轮的心跳请求,即session.timeout.ms >= 3 *heartbeat.interval.ms
- 设置
- Consumer 消费时间过长(较重的消费逻辑)导致的 Rebalance。假设 Consumer 消费数据时需要将消息处理之后写入到 MySQL,如果写 Mysql 的最长时间是
3min,那么你可以将max.poll.interval.ms设置为4min左右或者足够大
0x07 Producer 实践心得
0x08 Consumer 实践心得
消费者 VS 消费者组?
在具体应用场景中,到底选择哪种呢?
- 消费者组(consumer group),多个消费者实例组成一个整体消费消息
- 独立消费者(standalone consumer),单独执行消费(某个指定 topic 的 partition)操作
基于笔者实战的总结,二者更有优劣,需要灵活选择。
消费者组(consumer group)
前文说过,Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制。组内可以有多个消费者或消费者实例(Consumer Instance),它们共享一个公共的 ID,这个 ID 被称为 Group ID。组内的所有消费者协调在一起来消费订阅主题(Subscribed Topics)的所有 partition。每个 partition 只能由同一个消费者组内的一个 Consumer 实例来消费,如下图单个消费者(组),消费 4 个 partition:
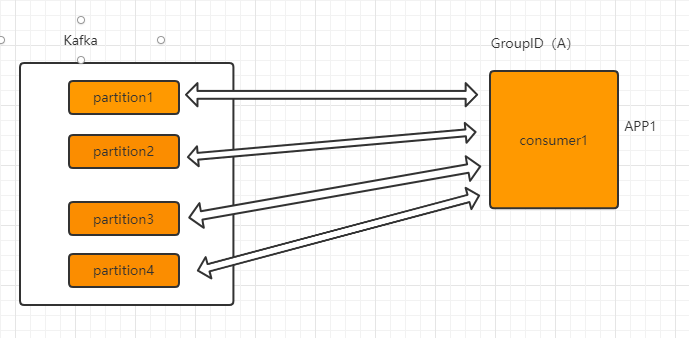
当有新增的 consumer 时(新增 partition),通过 Rebalance 机制,某个时刻的消费情况可能变成下面这样:
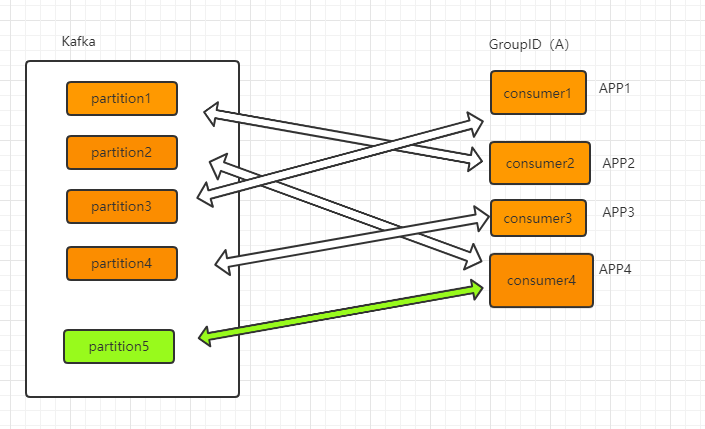
然而让人诟病的就是 Rebalance 机制。在 Rebalance 过程中,所有 Consumer 实例都会停止消费,等待 Rebalance 完成,对于一个高并发的场景中,这是很致命的。所以该机制即是 consumer group 的优点,也是其缺点。在现网项目中,可以通过调参来预防不必要的 Rebalance 发生,常用的调优参数有如下几个:
session.timeout.msgroupRebalanceTimeoutmax.poll.interval.ms
独立消费者(standalone consumer)
Standalone consumer,即独立消费者模式,消费者可以指定 topic 的分区进行消费,(即对某个 topic,每个消息源启动一个生产者,分别发往不同的分区,consumer 指定消费相关的 partition 即可),如下图 4 个多机消费者,每个消费者均指定了其中的 1 个 partition:
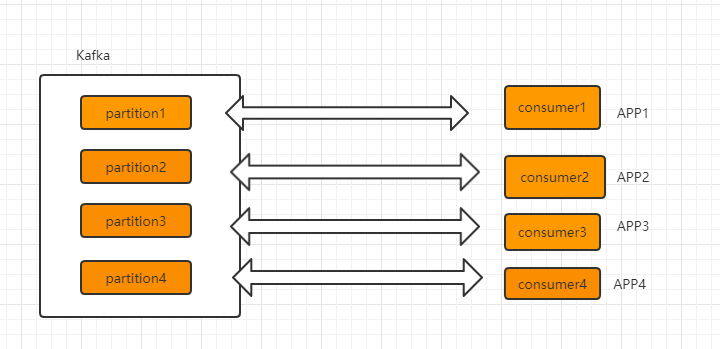
Standalone consumer 的限制:
- 此方式下,Kafka 集群并不会维护每个 consumer 的消费偏移量,需要每个 consumer 各自维护监听分区的消费偏移量
- 此方式建议勿与 consumer group 模式混合使用
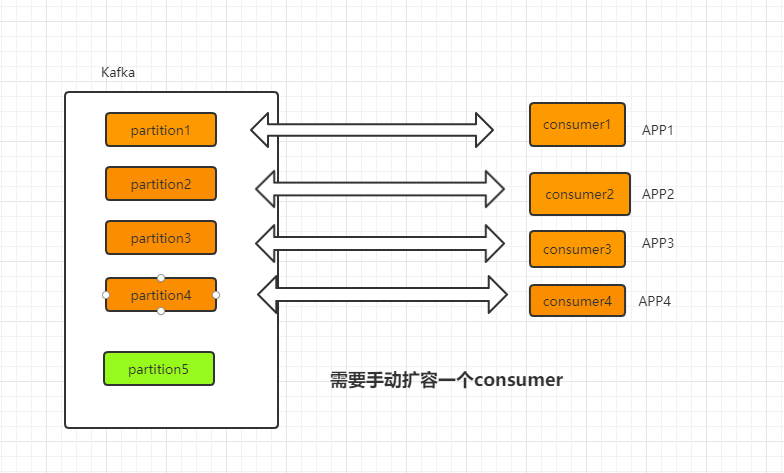
- 新增 partition 时,需要手动增加一个新的 Standalone consumer ,否则新建的 partition 不会被消费到,如下图
- 相较于 consumer group 模式的 Rebalance 机制,group 模式下在组内某个 consumer 异常时可将其监听的分区通过 Rebalance 重分配给其它正常的 consumer,使得这些 partition 不会停止被监听消费;但是 standalone consumer 由于是手动进行监听指定分区,因此某个 Standalone consumer 发生异常时,并不会将其监听的 partition 进行重分配,这就会造成某些 partition 消息堆积。因此,在该 standalone consumer 模式下,独立消费者需要开发者实现高可用机制,比如笔者的项目中对 standalone consumer 做了如下监控:
- 内置心跳上报,每个分区的 standalone consumer 都上报各自心跳,超时告警
- 部署在 tke 平台中,以 deployment 方式部署,加上健康检查
0x09 sarama 库的消费者用法
sarama 的自动提交模式
sarama 库的 consumer 语义和上述介绍的有略微不同,默认情况下,如下面的代码所示,sarama 是自动提交的方式,间隔为 1s,此处的自动提交,是基于被标记过的消息(先标记再提交):
// NewConfig returns a new configuration instance with sane defaults.
func NewConfig() *Config {
// ...
c.Consumer.Offsets.AutoCommit.Enable = true. // 自动提交
c.Consumer.Offsets.AutoCommit.Interval = 1 * time.Second // 间隔
c.Consumer.Offsets.Initial = OffsetNewest
c.Consumer.Offsets.Retry.Max = 3
// ...
}
基于被标记过的消息提交的 consumer group 示例(注意如果注释掉 MarkMessage,那么这里启动了自动提交也是无效的,下一次消费依然会从上一次的 offset 处开始):
type exampleConsumerGroupHandler struct{}
func (exampleConsumerGroupHandler) Setup(_ ConsumerGroupSession) error { return nil }
func (exampleConsumerGroupHandler) Cleanup(_ ConsumerGroupSession) error { return nil }
func (h exampleConsumerGroupHandler) ConsumeClaim(sess ConsumerGroupSession, claim ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("Message topic:%q partition:%d offset:%d\n", msg.Topic, msg.Partition, msg.Offset)
// 标记消息已处理,sarama 会自动提交
sess.MarkMessage(msg, "")
}
return nil
}
比如实际项目中的可能用法就是这样:
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
// 处理我们的业务逻辑,如写 mysql 等等
doOurBusinessLogic(msg)
// 正确:插入 mysql 成功后程序崩溃,下一次顶多重复消费一次,而不是因为 Offset 超前,导致应用层消息丢失了
sess.MarkMessage(msg, "")
}
return nil
}
sarama 的手动提交模式
sarama 的手动提交配置如下:
consumerConfig := sarama.NewConfig()
consumerConfig.Version = sarama.V2_8_0_0
consumerConfig.Consumer.Return.Errors = false
consumerConfig.Consumer.Offsets.AutoCommit.Enable = false // 禁用自动提交,改为手动
consumerConfig.Consumer.Offsets.Initial = sarama.OffsetNewest
手动 commit 的代码示例如下:
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("%s Message topic:%q partition:%d offset:%d value:%s\n", h.name, msg.Topic, msg.Partition, msg.Offset, string(msg.Value))
// 处理我们的业务逻辑,如写 mysql 等等
doOurBusinessLogic(msg)
// 手动提交模式下,也需要先进行标记
sess.MarkMessage(msg, "")
consumerCount++
if consumerCount%3 == 0 { // 假设每消费 3 条数据 commit 一次
// 手动提交,不能频繁调用
t1 := time.Now().Nanosecond()
sess.Commit()
t2 := time.Now().Nanosecond()
fmt.Println("commit cost:", (t2-t1)/(1000*1000), "ms")
}
}
return nil
}
consumer group 的并发机制
在现网中,有这样的问题,如何提高 sarama consumer group 的并发度及优先级处理呢?官方文档 中,Consumer group 让用户可以用消费组的方式进行消费 kafka 消息,如下代码片段 consumer.ConsumeClaim 方法中,调用方通过 for 循环,从 claim.Messages 中不断获取 message 进行消费,然后进行 MarkMessage 提交偏移量的操作:
type groupConsumer struct {
}
func (consumer *groupConsumer) Setup(s sarama.ConsumerGroupSession) error {
return nil
}
func (consumer *groupConsumer) Cleanup(s sarama.ConsumerGroupSession) error {
return nil
}
func (consumer *groupConsumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
//claim.Messages() 返回了一个存储消息体指针的 channel
for message := range claim.Messages() {
log.Info("consume msg. Topic=%s, partition=%d, offset=%d", message.Topic, message.Partition, message.Offset)
// 提交偏移量!(完成任务的时候给服务器发送一个 offset 的 ACK)
session.MarkMessage(msg, "")
}
return nil
}
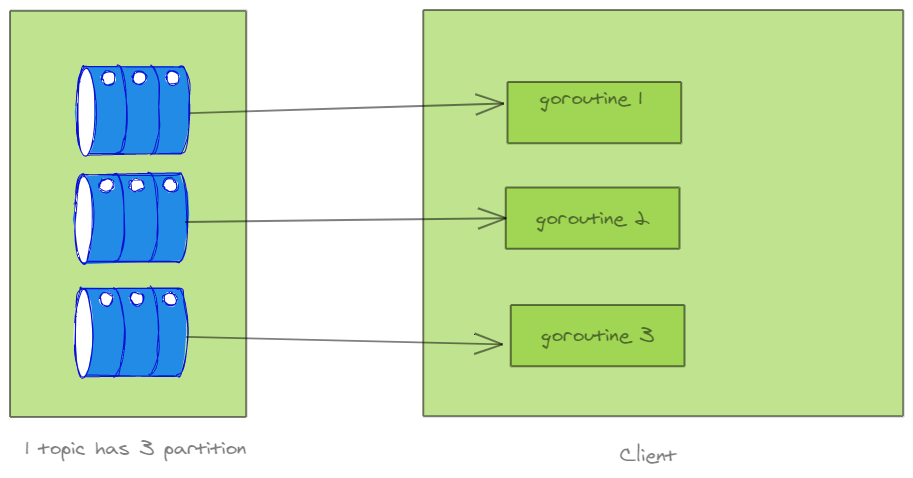
这里 ConsumeClaim 本身就是多 goroutine 机制,一个 partition 会开启一个 goroutine 进行处理。从 sarama 库的实现得知:在 sess.consume(topic, partition) 中,调用的就是上面的 ConsumeClaim。由此可知,sarama 为每个 topic 的每个 partition 都维护了一个 channel,并且为每个 channel 开了一个协程去处理。
func newConsumerGroupSession(ctx context.Context, parent *consumerGroup, claims map[string][]int32, memberID string, generationID int32, handler ConsumerGroupHandler) (*consumerGroupSession, error) {
// start consuming
for topic, partitions := range claims {
for _, partition := range partitions {
sess.waitGroup.Add(1)
go func(topic string, partition int32) {
defer sess.waitGroup.Done()
// cancel the as session as soon as the first
// goroutine exits
defer sess.cancel()
// consume a single topic/partition, blocking
sess.consume(topic, partition)
}(topic, partition)
}
}
return sess, nil
}
那么实现并发度提升可以在 ConsumeClaim 里面做文章,现网笔者采用固定 size 的 goroutine 协程池方式提高消费任务处理的进度,不过需要解决 session.MarkMessage 的问题,看下面这个例子:
// 使用 channel 方式实现并发
var maxLimit = make(chan int, 64)
func (consumer *groupConsumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for message := range claim.Messages() {
maxLimit <- 1
go doBusiness()
session.MarkMessage(msg, "")
}
return nil
}
这个例子是有问题的,异步化之后并不知道 doBusiness 执行的结果,session 就直接发送了 ACK 了,会导致非预期的结果。那么如何解决呢?见后文。
此外,还有另外一种思路,采用本地队列 + goroutine 方式实现,如下图:
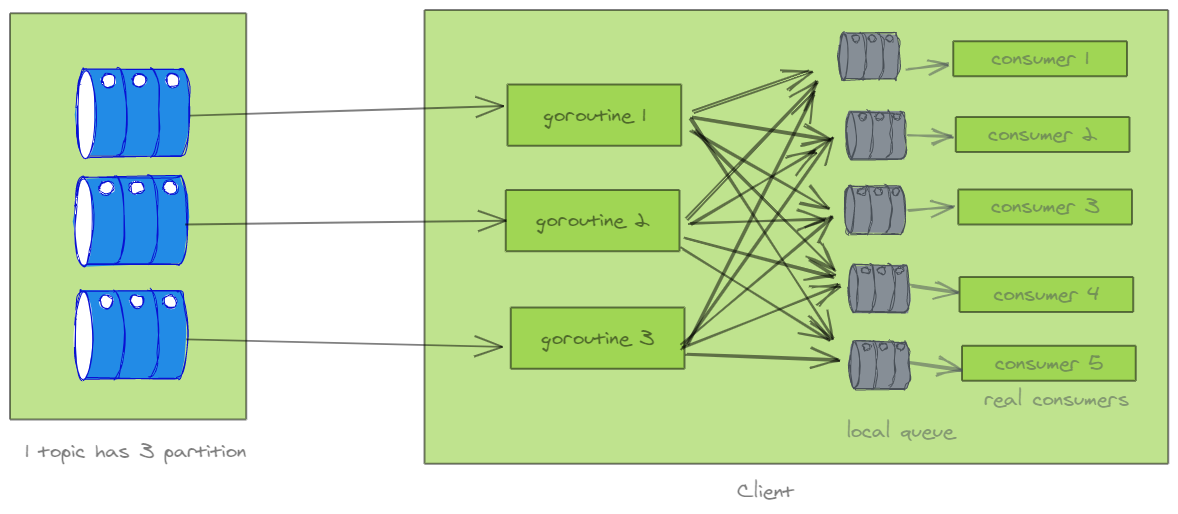
不过,这里介绍的方法仅适合于消费端消费慢,并行度过低的情况。建议还是通过增加 partition 的方式解决,直接用 kafka 的 partition 扩展性,避免在消费端增加逻辑复杂度。
consumer group /standalone consumer的消费 offset(位移)
在sarama库中,消费者提交offset有两种方式:
- consumer group模式,通过
session.MarkMessage(message, "")提交offset - standalone consumer模式,通过
partitionManager.MarkOffset(offset+1, "message")方式提交,代码示例
本质上,底层都是通过MarkOffset方法提交,注意提交的offset是当前的消息的下一个位置,即msg.Offset+1,表示小于msg.Offset+1的位置的数据均成功被消费(不管这之前的位置有没有被 commit):
func (s *consumerGroupSession) MarkMessage(msg *ConsumerMessage, metadata string) {
s.MarkOffset(msg.Topic, msg.Partition, msg.Offset+1, metadata)
}
注意!sess.Commit 的细节
0x0A sarama 库的问题:阿里云的建议
阿里云官方文档不推荐使用 sarama 库,见此文:为什么不推荐使用 Sarama Go 客户端收发消息,这里简单列举下原文,其中解决方案对项目实践还是有些指导意义。
不推荐的原因
Sarama Go 客户端存在以下已知问题:
- 当 Topic 新增分区时,Sarama Go 客户端无法感知并消费新增分区,需要客户端重启后,才能消费到新增分区
- 当 Sarama Go 客户端同时订阅两个以上的 Topic 时,有可能会导致部分分区无法正常消费消息
- 当 Sarama Go 客户端的消费位点重置策略设置为 Oldest(earliest) 时,如果客户端宕机或服务端版本升级,由于 Sarama Go 客户端自行实现 OutOfRange 机制,有可能会导致客户端从最小位点开始重新消费所有消息
对应的解决方案
- 建议尽早将 Sarama Go 客户端替换为 Confluent Go 客户端,后续参考其封装下。
- 如果无法在短期内替换客户端,请注意以下事项:
- 针对生产环境,请将位点重置策略设置为 Newest(latest);针对测试环境,或者其他明确可以接收大量重复消息的场景,设置为 Oldest(earliest),这点很重要
- 如果发生了位点重置,产生大量堆积,可以使用消息队列 Kafka 版控制台提供的重置消费位点功能,手动重置消费位点到某一时间点,无需改代码或换 Consumer Group(如果不重置的话会产生大量的重复数据)
0x0A 参考
转载请注明出处,本文采用 CC4.0 协议授权
Related Issues not found
Please contact @pandaychen to initialize the comment
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK