

计算机体系结构 [3]:编译与链接
source link: https://no5-aaron-wu.github.io/2022/01/10/ComputerArch-3-ELF/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
计算机体系结构 [3]:编译与链接
将一段程序源码运行起来一共需要几步?每一步都做了什么?
C语言源码能够跑起来大致可以分为两部分:

- 第一部分由编译(Compile),汇编(Assemble)以及链接(Link)三个阶段组成。其中编译器将C源码文件(*.c)编译成汇编代码文件(*.asm或*.S);汇编器将汇编代码文件转换成目标代码文件(机器码,*.o);链接器将多个目标文件及其调用的各种函数库文件(*.lib/*.a或*.dll/*.so)链接起来,得到可执行文件(*.elf/*.pe);
- 第二部分则是通过装载器(Loader)将可执行文件装载(Load)到内存中。CPU从内存中读取指令和数据,开始执行程序。
ELF文件格式
在 Linux 下,可执行文件和目标文件所使用的都是一种叫 ELF(Execuatable and Linkable File Format)的文件格式,中文名字叫可执行与可链接文件格式,这里面不仅存放了编译成的汇编指令,还保留了很多别的数据。
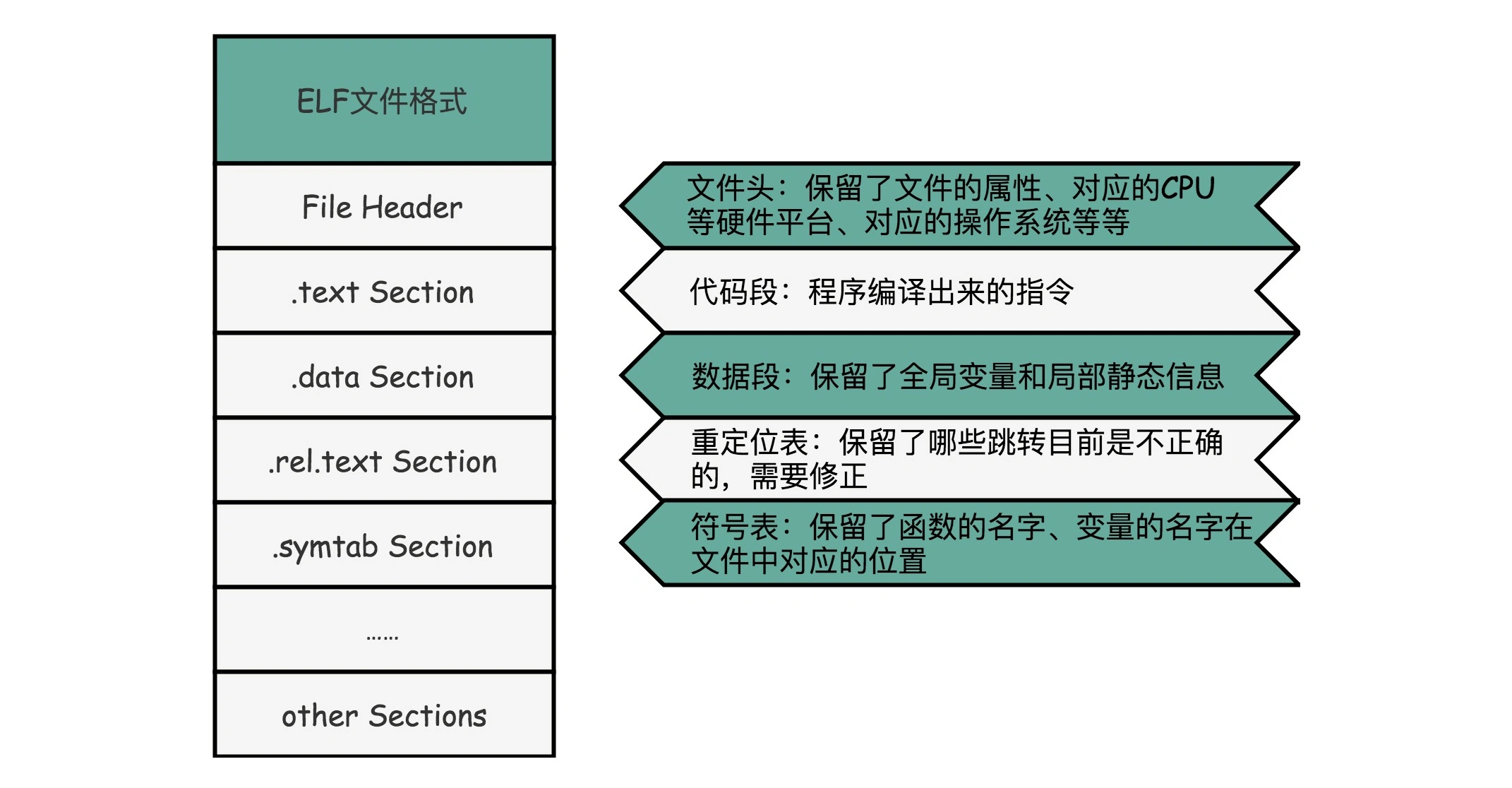
ELF 文件格式把各种信息,分成一个一个的段(Section)保存起来。ELF 有一个基本的文件头(File Header),用来表示这个文件的基本属性,比如是否是可执行文件,对应的 CPU、操作系统等等。除了这些基本属性之外,大部分程序还有这么一些 Section:
.text Section,也叫作代码段或者指令段(Code Section),用来保存程序的代码和指令;.data Section,也叫作数据段(Data Section),用来保存程序里面设置好的初始化数据信息;.rel.text Secion,叫作重定位表(Relocation Table)。重定位表里,保留的是当前的文件里面,哪些跳转地址其实是我们不知道的。比如在.o文件在链接之前,我们并不知道其中调用的其他.o文件或函数库中的函数该跳转到哪里,这些信息就会存储在重定位表里;.symtab Section,叫作符号表(Symbol Table)。符号表保留了我们所说的当前文件里面定义的函数名称和对应地址的地址簿。
当链接时,链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。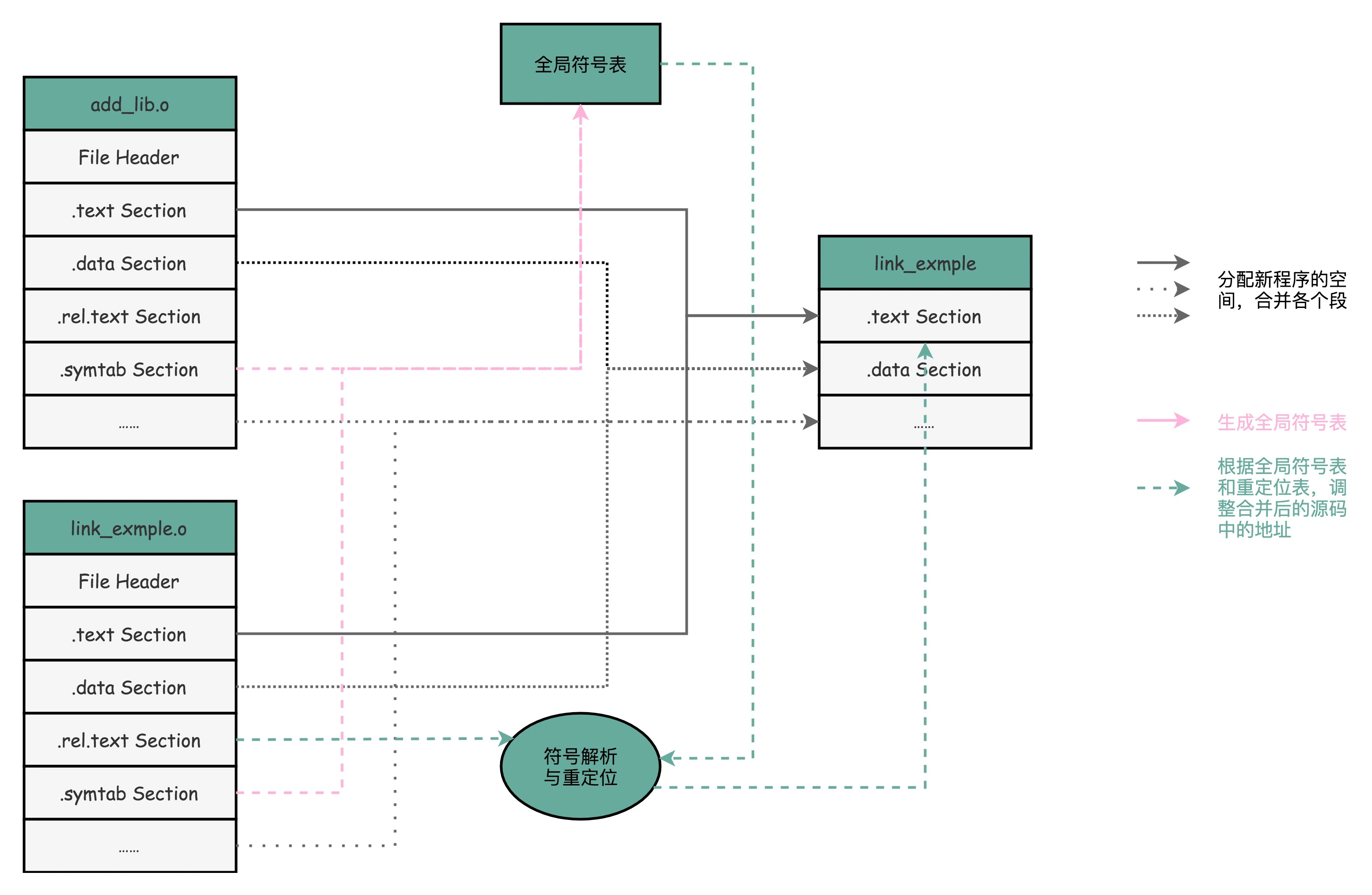
Windows 的可执行文件格式是一种叫作PE(Portable Executable Format)的文件格式。Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式,反之亦然。这也是不同操作系统下的可执行文件不能跨平台运行的原因。
可以通过objdump -d指令对目标文件或可执行文件进行反汇编,得到汇编代码:
objdump -d -M intel -S add_lib.o > add_lib.asm
其中-M intel选择intel反汇编器;-S会将源代码嵌入到汇编代码中,编译时需要gcc -g,即需要调试信息;
可以通过objdump -r指令查看目标文件的重定位表;
可以通过readelf -s指令查看符号表;
静态链接与静态库
在上面的表述中,程序的链接,是把不同的*.o目标文件中的对应段合并到一起,成为最终的可执行文件。其实这个链接方式是静态链接(Static Link),与此相对应的,静态库(Static Libraries)就可以认为是一组目标文件的集合打包而成。
-
优点:静态链接生成的可执行文件已经具备了程序运行的所有组件,与函数库再无瓜葛,因此移植起来比较方便。且运行时速度更快。
-
- 首先很明显的就是空间浪费。这个浪费可以从两个层次去看,第一,链接器在链接静态库或者目标文件时是以文件为单位的。若该目标文件中还有其他我们并没有用到的函数,也会一起被链接进可执行文件。第二,若多个可执行文件都有依赖同一份目标文件,则该目标文件会被合并到每个可执行文件中,即在每个可执行文件中都会存在一个副本。这都会导致代码空间的浪费。
- 其次静态库对于程序的部署,发布和更新都会带来困扰。如果一个可执行程序依赖的底层静态库有一个改动,则需要重新编译,再部署到设备或发布给用户。即全量更新。
动态链接与动态库
为了解决静态链接的缺点,引入了新的链接机制,即动态链接(Dynamic Link),与此相对应的,动态库(Dynamic Libraries)是动态链接时需要使用的库。在Windows下,动态库被称为Dynamic-Link Library(*.dll文件,动态链接库)。在Linux下,动态库被称为Shared Object(*.so文件,共享对象)。
动态链接的核心思想是动态库在程序编译时并不会被链接进可执行文件中,而是在程序运行时基于库的依赖关系去系统环境变量(linux下为LD_LIBRARY_PATH,windows下可以在VS工程属性中指定)指定的目录下(磁盘)去查找动态库是否存在,若存在,则会将其装载到内存中,与可执行文件链接成一个完整的程序。当然,若动态库也依赖其他动态库,也会递归地执行上述操作。
这样做的好处就是 ,若同时执行多个可执行文件,若他们依赖某个相同的动态库,则该动态库只需要被装载到内存中一次,多个可执行文件共享这个同一份副本;其次,程序更新也变得更加方便,若某个动态库内部出现改动,只要接口不变,则只需要发布补丁来替换这一个动态库,不需要重新编译整个程序包。即做到了增量更新。
当然动态链接也不是完全没有代价的,因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损失, 据估算,动态链接和静态链接相比,性能损失大约在5%以下。但这点性能损失用来换取程序在空间上的节省以及构建和升级时的灵活性是值得的。
地址无关码(Position-Independent Code)
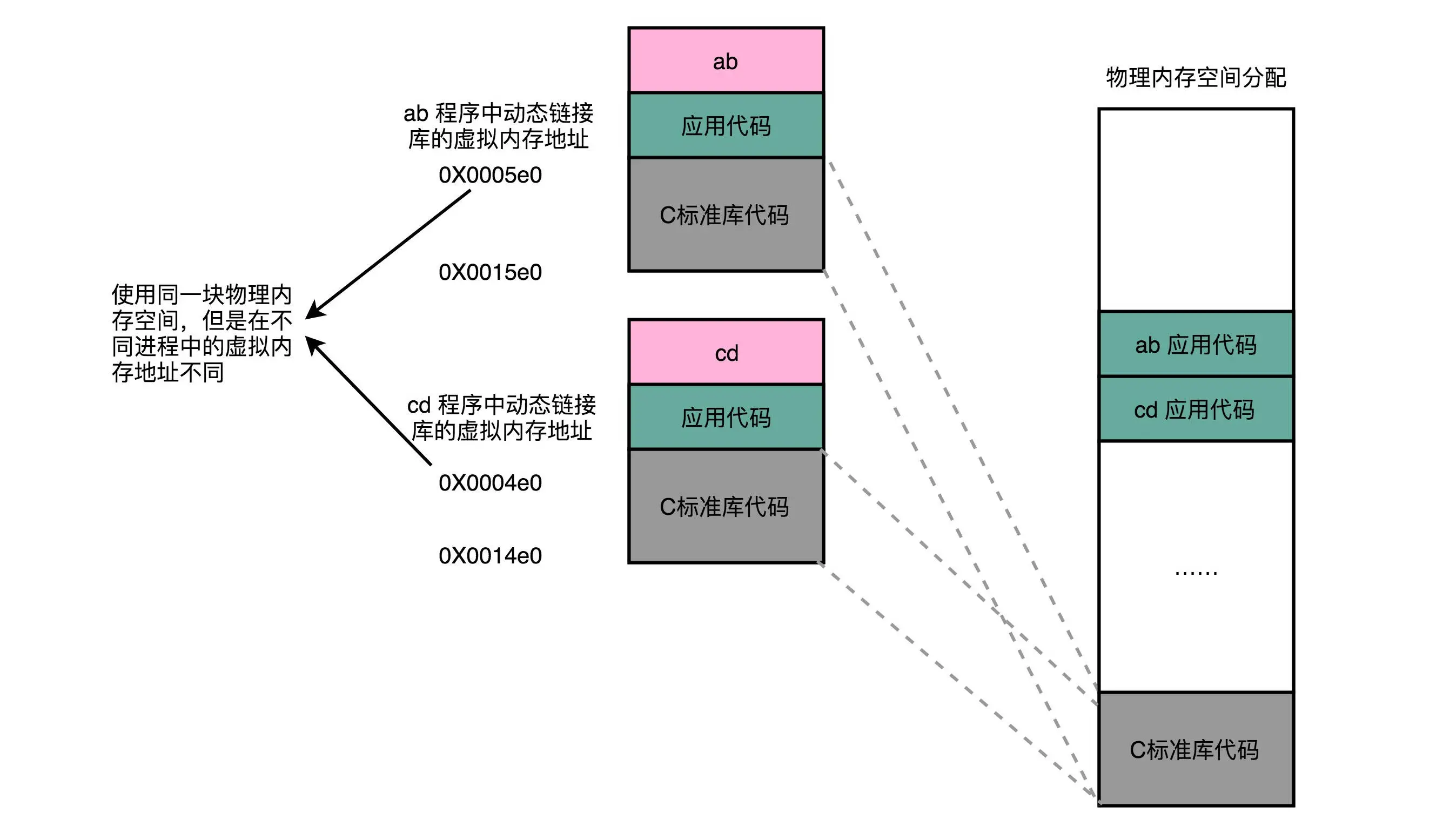
若想要实现动态库的代码共享,则需要编译出的动态库文件中的指令代码是地址无关的。也就是说,这段代码与装载到内存中的绝对地址无关,动态库内部指令使用的内存地址,都是一个相对于当前指令偏移量的相对地址。无论动态库链接到某个可执行程序后的起始(虚拟)内存地址是多少,动态库中指令都是可以正常执行的。示意图如下:
PLT与GOT
关于动态库在装载时重定位的过程,比较经典的解释就是延迟绑定机制,这里我们结合一个小例子来讲一下:
首先创建如下几个文件:
// lib.h
#ifndef LIB_H
#define LIB_H
void show_me_the_money(int money);
#endif
// lib.c
#include <stdio.h>
void show_me_the_money(int money)
{
printf("Show me USD %d from lib.c \n", money);
}
// show_me_poor.c
#include "lib.h"
int main()
{
int money = 5;
show_me_the_money(money);
}
然后把lib.c编译成一个动态库lib.so,然后再编译show_me_poor的可执行文件时动态链接lib.so:
gcc lib.c -fPIC -shared -g -o lib.so
gcc -g -o show_me_poor show_me_poor.c ./lib.so -z lazy
其中-fPIC参数就表示编译为地址无关码;-shared参数表示生成动态库;-g是为了生成调试信息,供gdb使用;-z lazy参数表示动态库链接时延迟加载,这个很重要,不加该选项,实测在动态库函数调用前(其实是在main函数前)就已经装载了动态库,装载过程如这个老哥分析的那样。
此时,我们可以使用objdump -d指令来执行反汇编生成汇编代码:
objdump -d -M intel -S show_me_poor > show_me_poor.asm
但是由于是动态链接,汇编代码是看不到GOT表的变化(这里先不用管GOT表是啥),我们选择用gbd调试代码,一些常用的命令见这里,先看下程序未开始执行时的情况:
# 安装gdb插件peda
git clone https://github.com/longld/peda.git ~/peda
echo "source ~/peda/peda.py" >> ~/.gdbinit
gdb show_me_poor
# 查看源代码
gdb-peda$ l
# 打印main函数的汇编代码
gdb-peda$ disass main
则有以下输出:
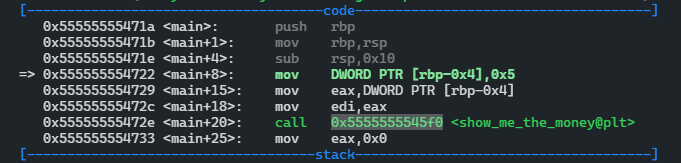
Dump of assembler code for function main:
0x000000000000071a <+0>: push rbp
0x000000000000071b <+1>: mov rbp,rsp
0x000000000000071e <+4>: sub rsp,0x10
0x0000000000000722 <+8>: mov DWORD PTR [rbp-0x4],0x5
0x0000000000000729 <+15>: mov eax,DWORD PTR [rbp-0x4]
0x000000000000072c <+18>: mov edi,eax
0x000000000000072e <+20>: call 0x5f0 <show_me_the_money@plt>
0x0000000000000733 <+25>: mov eax,0x0
0x0000000000000738 <+30>: leave
0x0000000000000739 <+31>: ret
End of assembler dump.
这其实与我们用objdump -d得到的汇编代码是一致的。这里可以看到调用show_me_the_money函数的对应代码为call 0x5f0 <show_me_the_money@plt>,其中有一个@plt的关键字,代表的就是PLT(Procedure Link Table)表,即程序链接表。PLT表由若干代码片段组成,每个代码片段对应一个需要动态链接的函数调用,我们姑且称之为模块。call指令相当于push和jmp两条指令的集合。这里就需要跳转到PLT表中的show_me_the_money模块继续执行。
那么我们继续看PLT表中都有啥,执行如下:
gdb-peda$ disass show_me_the_money
# or
gdb-peda$ disass 0x5f0
# or
gdb-peda$ x /30i 0x5f0 # 30代表要显示的个数,i表示用指令形式显示,如果改为x,则表示用16进制数显示
则有如下输出:
Dump of assembler code for function show_me_the_money@plt:
0x00000000000005f0 <+0>: jmp QWORD PTR [rip+0x200a22] # 0x201018
0x00000000000005f6 <+6>: push 0x0
0x00000000000005fb <+11>: jmp 0x5e0
End of assembler dump.
其中有3条指令,我们先看第一条无条件跳转指令,是跳转到0x201018处的值所代表的地址。即jmp *0x201018, 那么这个地址中的值到底是啥?
gdb-peda$ x /x 0x201018
0x201018: 0x000005f6
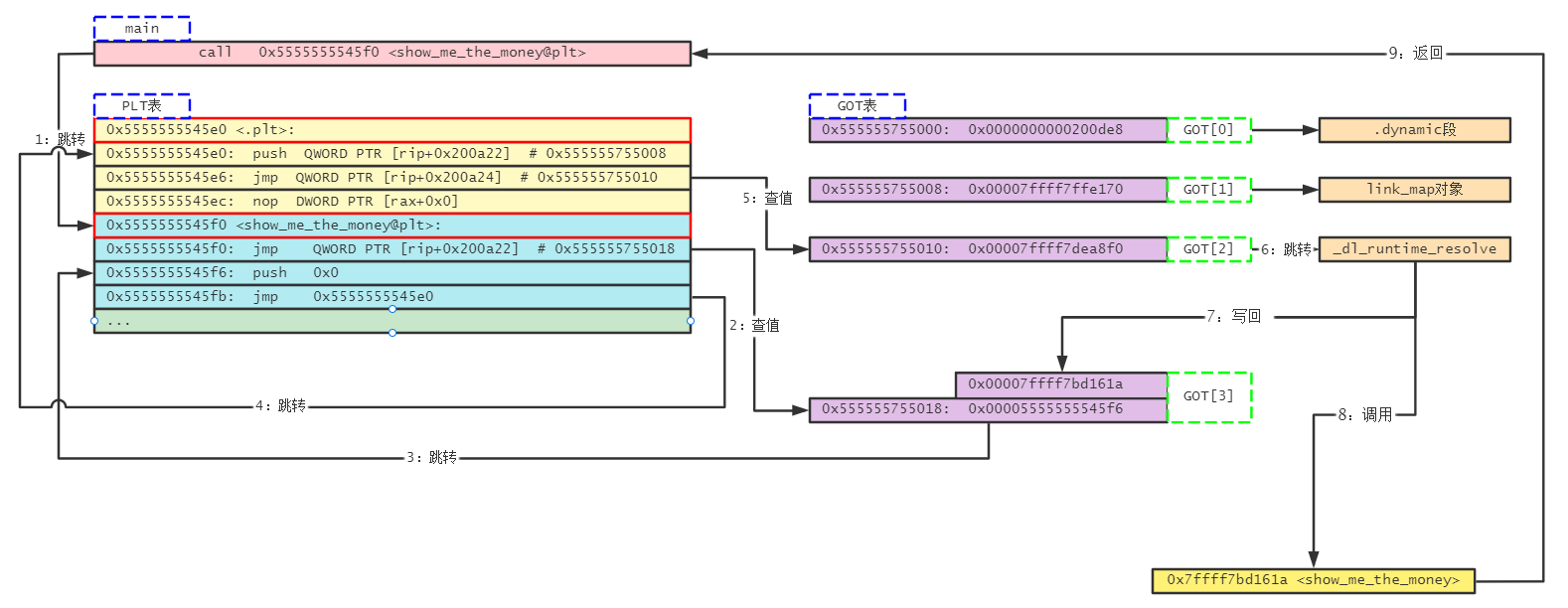
这不就是跳转到当前指令的的下一条指令push 0x0吗?为啥多此一举呢?因为这时还没有装载动态库,如果动态库装载后,0x201018地址处的值就会变成调用的动态库函数的入口地址(其实0x201018本身在可执行程序被装载到内存中时虚拟内存地址也是会变的,等下会看到)。这里用来保存外部动态库入口地址的表就是GOT(Global Offset Table)表,即全局偏移量表。*0x201018其实对应的时GOT[3],即GOT表的第4个值,GOT表的前3个值分别为.dynamic段地址,link_map对象地址和_dl_runtime_resolve函数的入口地址。这里不做深入探究,目前只需要关注_dl_runtime_resolve函数地址,即GOT[2],我们将通过它在装载时重定位动态库函数,即修改GOT[3]的值。
有了上面的铺垫,我们接在往下看jmp 0x5e0:
gdb-peda$ x /30i 0x5e0
有以下输出:
0x5e0: push QWORD PTR [rip+0x200a22] # 0x201008
0x5e6: jmp QWORD PTR [rip+0x200a24] # 0x201010
0x5ec: nop DWORD PTR [rax+0x0]
0x5f0 <show_me_the_money@plt>: jmp QWORD PTR [rip+0x200a22] # 0x201018
0x5f6 <show_me_the_money@plt+6>: push 0x0
0x5fb <show_me_the_money@plt+11>: jmp 0x5e0
0x600 <__cxa_finalize@plt>: jmp QWORD PTR [rip+0x2009f2] # 0x200ff8
0x606 <__cxa_finalize@plt+6>: xchg ax,ax
0x608: Cannot access memory at address 0x608
可以看到0x5e0其实就是PLT的表头,这里首先执行push *0x201008,其实就是push GOT[1],然后执行jmp *0x201010,即jmp GOT[2]。这就是我们前面说的跳转到_dl_runtime_resolve函数,执行加载时重定位,找到show_me_the_money函数的入口地址,将其写回GOT[3](以便下次再使用该函数时直接跳转),并且执行show_me_the_money函数。不过现在(未执行程序时)查看0x201010地址处的值:
gdb-peda$ x /x 0x201010
你会得到:
0x201010: 0x00000000
没错,是空的。因为_dl_runtime_resolve函数的入口地址也是要在运行时才能确定的。至此,我们基本摸清了动态链接的逻辑:利用PLT和GOT两级跳表的方式,实现了延迟加载。那么让我将程序跑起来看看是不是如我们所预期:
# main插入断点
gdb-peda$ b main
# 运行
gdb-peda$ r
# 单步步过执行
gdb-peda$ ni
# 单步步入执行
gdb-peda$ si
# 跳出当前函数
gdb-peda$ finish
通过上述操作可以单步调试代码:

这里看到PLT表中show_me_the_money模块的虚拟内存地址是0x5555555545f0,GOT[3]的虚拟内存地址0x555555755018,该地址处的值为0x5555555545f6,即push 0x0指令的地址(0x0其实是代表了show_me_the_money函数的序号,这里只有调用了一个动态库函数,如果有其他,会依此排序)。继续单步执行:
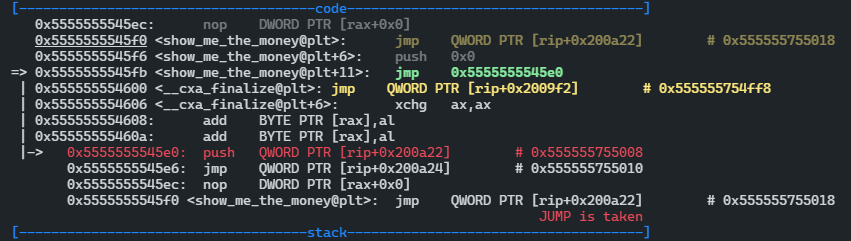

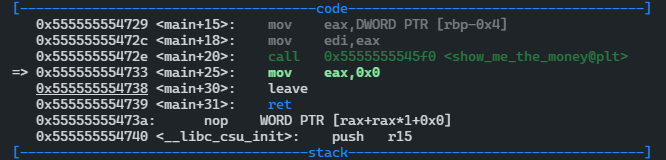
PLT表头的地址为0x5555555545e0,GOT[2]的地址为0x555555755010,GOT[2]的值为0x7ffff7dea8f0,即_dl_runtime_resolve函数的入口地址。跳出_dl_runtime_resolve函数便直接返回到call 指令的下一条指令。这时再去查看GOT[3]的值对应的映射关系:
gdb-peda$ xinfo 0x555555755018
则有以下输出:
0x555555755018 --> 0x7ffff7bd161a (<show_me_the_money>: push rbp)
Virtual memory mapping:
Start : 0x0000555555755000
End : 0x0000555555756000
Offset: 0x18
Perm : rw-p
Name : /home/aaron-wu/code/cpp_test/dl_test/show_me_poor
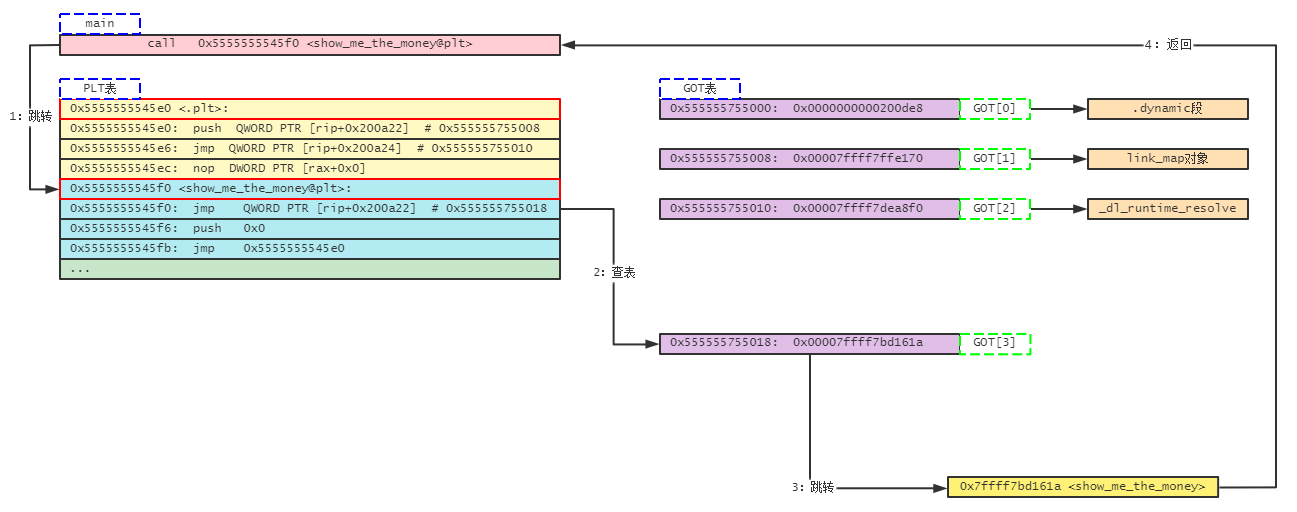
此时GOT[3]的值被修改为0x7ffff7bd161a ,而这对应的就是show_me_the_money的入口地址。下次再调用该函数时,可以在PLT表中直接跳转过去,而不需要再次装载。awesome!
首次动态装载的指令流程如下:
若再次调用show_me_the_money函数,则指令流程应当如下图所示:
装载器将可执行程序装载到内存中,但需要满足两个要求:
第一,可执行程序被加载后占用的内存空间应该是连续的。因为程序计数器(PC)是自增的,即一条条指令需要连续地存储在一起。
第二,允许同时加载多个程序,且程序间内存互不干扰。但是我们发现不同的程序中,编译得到的指令可能对应的是相同的内存地址,如果严格按照这个地址将程序加载到内存,则会出现内存地址冲突的情况。
那么如何做才能满足上面两个要求呢?
这里引入了虚拟内存映射的机制,我们把指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address),实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。在程序装载时,会在物理内存中找到一块连续的内存(内存分段,Memory Segmentation)分配给装载的程序,并将这段内存的地址与程序指令里指定的地址建立一个映射关系,维护在一个映射表中(因为是连续的内存,所以只需要维护起始地址和内存空间大小即可)。这样实际程序执行时,程序看到的只是虚拟内存地址,即使虚拟内存地址与其他程序相同,但通过映射表找到的是不同的的物理内存地址,就能正确取指令然后执行。分段的示意图如下:
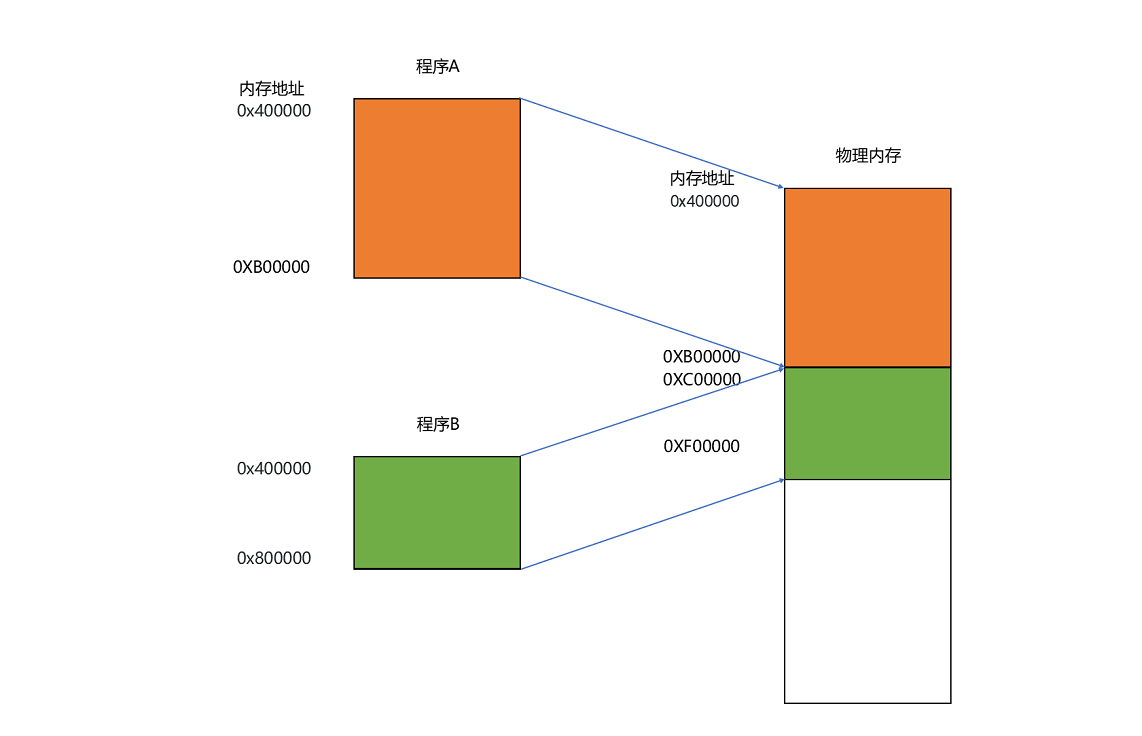
内存分段虽然解决了程序本身不需要关心具体的物理内存地址的问题,但也引入内存碎片(Memory Fragmentation)的问题。一个内存碎片的例子如下图所示:

内存碎片问题可以通过引入内存交换(Memory Swapping)机制来解决。所谓内存交换就是将上图中256MB的内存写回硬盘上,再重新读回内存。不过读回来时,不再读回原位置,而是紧挨着前面已被占用的512MB的内存。这样就可以消除碎片,有了新的连续的256M内存空间供新的程序使用。linux系统装机时,会有给swap硬盘分区,就是专门为内存交换分配的区域。
但是内存交换也是有问题的,就是硬盘的访问速度是要比内存慢很多的,如果内存交换的内存空间很大,就会导致 程序卡顿。那么如果能让内存交换时写回磁盘和重新装载的数据更少一些,就可以解决这个问题。于是现代计算机的内存管理中引入了内存分页(Paging)机制。
和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。页的尺寸一般远远小于整个程序的大小。在 Linux 下通常设置成 4KB。通过getconf PAGE_SIZE命令查看。
由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。这时候内存交换存在的意义更多是为了将不活跃的内存占用交换到硬盘,以释放内存,从而更有效的利用内存。即使内存空间真的不够了,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,以免程序执行被内存交换的过程给卡住。
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
实际上,我们的操作系统,的确是这么做的。当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。我们的操作系统会捕捉到这个错误,然后将对应的页,从硬盘上里读取出来,加载到物理内存里。这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
通过虚拟内存、内存交换和内存分页这三个技术的组合,我们最终得到了一个让程序不需要考虑实际的物理内存地址、大小和当前分配空间的解决方案。任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。
[1] 深入浅出计算机组成原理
[2] 深入理解GOT表和PLT表
[3] GOT表和PLT表
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK