

Kafka技术内幕-存储层(1)
source link: https://keys961.github.io/2020/07/03/Kakfa%E6%8A%80%E6%9C%AF%E5%86%85%E5%B9%95-%E5%AD%98%E5%82%A8%E5%B1%82(1)/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
由于Kafka消息需要落盘,而顺序操作一定是最快的,所以Kafka以“日志”的形式追加数据。
此外,为了降低磁盘空间使用,Kafka有后台线程会压缩合并日志,对于指定键,只保留最新的消息。
1. 日志读写
1.1. 分区、副本、日志、日志段
Kafka将一个topic以分区的形式保存,这些分区文件分布在多个服务端节点上。
每个分区可以配置复制因子,设置主副本和从副本,主副本负责读写,从副本负责从主副本拉取数据以同步。若主副本挂掉,会选择一个从副本接管成为主副本。
下面的代码定义了分区和副本:
class Partition(val topicPartition: TopicPartition, // topic分区标识
val replicaLagTimeMaxMs: Long, // 副本最长延迟时间
interBrokerProtocolVersion: ApiVersion,
localBrokerId: Int, // 本地broker id
time: Time,
stateStore: PartitionStateStore, // 存储在ZooKeeper的分区元数据存储
delayedOperations: DelayedOperations,
metadataCache: MetadataCache,
logManager: LogManager // 日志处理器
) extends Logging with KafkaMetricsGroup {
// ...
private val remoteReplicasMap = new Pool[Int, Replica] // 远程副本集合,维护ID-副本的映射
private val leaderIsrUpdateLock = new ReentrantReadWriteLock
private var zkVersion: Int = LeaderAndIsr.initialZKVersion
@volatile private var leaderEpoch: Int = LeaderAndIsr.initialLeaderEpoch - 1
@volatile private var leaderEpochStartOffsetOpt: Option[Long] = None
@volatile var leaderReplicaIdOpt: Option[Int] = None // 主副本的副本ID
@volatile var inSyncReplicaIds = Set.empty[Int] // 正在同步的副本集(ISR),以ID形式保存
@volatile var assignmentState: AssignmentState = SimpleAssignmentState(Seq.empty) // 分配给该分区的所有副本ID
@volatile var log: Option[Log] = None // 该分区的日志
@volatile var futureLog: Option[Log] = None
private var controllerEpoch: Int = KafkaController.InitialControllerEpoch
this.logIdent = s"[Partition $topicPartition broker=$localBrokerId] "
private val tags = Map("topic" -> topic, "partition" -> partitionId.toString)
// ...
}
class Replica(val brokerId: Int, // broker id
val topicPartition: TopicPartition // topic分区标识
) extends Logging {
// 日志尾部的offset值(本地副本即日志尾部,远程副本只会在从副本拉取后更新)
// 包含日志offset和文件偏移的位置
@volatile private[this] var _logEndOffsetMetadata = LogOffsetMetadata.UnknownOffsetMetadata
// 日志起始offset值(本地副本即日志头部,远程副本只会在从副本拉取后更新)
@volatile private[this] var _logStartOffset = Log.UnknownOffset
// 最近一次从副本请求拉取更新的日志尾offset值
@volatile private[this] var lastFetchLeaderLogEndOffset = 0L
// 上一次主副本收到从副本拉取请求的时间
@volatile private[this] var lastFetchTimeMs = 0L
// 从副本需要追上主副本所需要点最大时间
@volatile private[this] var _lastCaughtUpTimeMs = 0L
// 从副本上一次看到主副本的高水位值
@volatile private[this] var _lastSentHighWatermark = 0L
}
而分区会被保存到日志中,这里用Log定义,而日志会被分段,每一段定义为LogSegment,会以跳表的形式保存起来。下面列举了一些重要字段:
class Log(@volatile var dir: File, // 日志目录
@volatile var config: LogConfig,
@volatile var logStartOffset: Long, // 日志开头的offset
@volatile var recoveryPoint: Long, // 恢复点
scheduler: Scheduler,
brokerTopicStats: BrokerTopicStats,
val time: Time,
val maxProducerIdExpirationMs: Int,
val producerIdExpirationCheckIntervalMs: Int,
val topicPartition: TopicPartition,
val producerStateManager: ProducerStateManager,
logDirFailureChannel: LogDirFailureChannel) extends Logging with KafkaMetricsGroup {
private val lock = new Object
@volatile private var isMemoryMappedBufferClosed = false
// 上一次刷盘点时间
private val lastFlushedTime = new AtomicLong(time.milliseconds)
// 下一个消息对应的offset
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
// 第一个不稳定(未完成事务的)偏移量元数据
@volatile private var firstUnstableOffsetMetadata: Option[LogOffsetMetadata] = None
// 高水位元数据
@volatile private var highWatermarkMetadata: LogOffsetMetadata = LogOffsetMetadata(logStartOffset)
// 日志包括多个日志分段
// 它用一个有序Map(跳表)保存,键是起始偏移,最后一个就是最新、活跃的日志分段
private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
// 主副本的Epoch
@volatile var leaderEpochCache: Option[LeaderEpochFileCache] = None
}
class LogSegment private[log] (val log: FileRecords, // 数据文件
val lazyOffsetIndex: LazyIndex[OffsetIndex], // 索引文件
val lazyTimeIndex: LazyIndex[TimeIndex],
val txnIndex: TransactionIndex,
val baseOffset: Long, // 该分段最早的offset
val indexIntervalBytes: Int,
val rollJitterMs: Long,
val time: Time) extends Logging {
// ...
}
1.2. 写入日志
服务端将生产者产生的消息追加到日志中。
具体而言,追加日志会操作Log日志对象,它:
- 维护分区的所有日志分段
LogSegment - 活跃的分段只有1个
- 每个分段有一份数据文件和一份索引文件
消息最终会追加到活跃日志分段,底层使用FileChannel写入。
a) 消息集
生产者的消息集最终会被转换成MemoryRecords对象,它保存了一批RecordBatch,而一个RecordBatch包含了多个Record:
public class MemoryRecords extends AbstractRecords {
private final ByteBuffer buffer; // 消息数据
private final Iterable<MutableRecordBatch> batches = this::batchIterator; // 消息迭代器
private int validBytes = -1; //
// ...
@Override
public AbstractIterator<MutableRecordBatch> batchIterator() {
return new RecordBatchIterator<>(new ByteBufferLogInputStream(buffer.duplicate(), Integer.MAX_VALUE));
}
// ...
}
而这批消息在日志中的格式,定义在DefaultRecordBatch和DefaultRecord中,如下图所示:
引用自:https://blog.csdn.net/u013256816/article/details/80300225
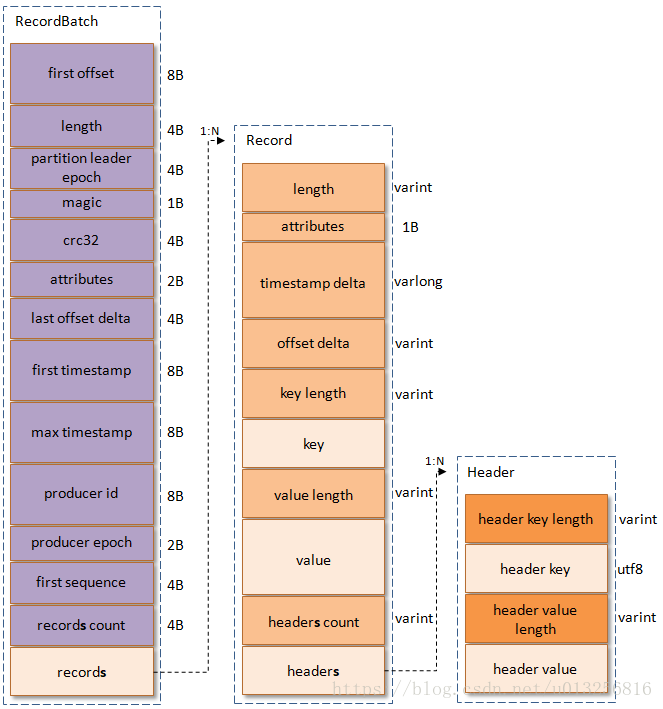
这里列举Record中重要的部分
length:消息长度attribute:弃用timestamp delta:消息的时间戳和first timestamp差值offset delta:消息的offset和first offset差值headers:用于支持应用扩展
- 这里
offset和timestamp应用了差值,这样做可以节省空间;此外调整offset时,只需要改RecordBatch头部的first offset即可 - 这里使用了
varint和varlong,整型数字使用变长存储,使用了Zigzag编码,数字越小,占用的空间越少(但不保证一定节省空间,例如varint最大会占5字节)
而RecordBatch中比较重要的是:
first offset:当前批的记录起始offsetlength:消息集的长度partition leader epoch:分区Leaderepochmagic:这里等于2attributes:属性,低3位表示压缩格式,第4位为时间戳类型,第5位为是否处于事务,第6位为是否为Control消息last offset delta:最后一个记录和第一个记录的offset差值first timestamp,last timestamp:第一个和最后一个记录的时间戳producer id:生产者IDproducer epoch:生产者epochrecords count:消息个数
而外部的记录,通过MemoryRecords#withRecords转换成二进制的MemoryRecords(代表了一批二进制的RecordBatch),追加记录前,该批消息的初始offset可能是不正确的,插入前,会对其进行修正,从而保证分区日志offset的有序性:
private def append(records: MemoryRecords, // 一批二进制的RecordBatch
origin: AppendOrigin,
interBrokerProtocolVersion: ApiVersion,
assignOffsets: Boolean,
leaderEpoch: Int): LogAppendInfo = {
maybeHandleIOException(s"Error while appending records to $topicPartition in dir ${dir.getParent}") {
// ...
var validRecords = trimInvalidBytes(records, appendInfo)
lock synchronized {
checkIfMemoryMappedBufferClosed()
if (assignOffsets) {
// 获取下一批写入应有的起始offset
val offset = new LongRef(nextOffsetMetadata.messageOffset)
appendInfo.firstOffset = Some(offset.value)
val now = time.milliseconds
// 修正设置每一个RecordBatch的start offset
val validateAndOffsetAssignResult = try {
LogValidator.validateMessagesAndAssignOffsets(validRecords,
topicPartition,
offset,
time,
now,
appendInfo.sourceCodec,
appendInfo.targetCodec,
config.compact,
config.messageFormatVersion.recordVersion.value,
config.messageTimestampType,
config.messageTimestampDifferenceMaxMs,
leaderEpoch,
origin,
interBrokerProtocolVersion,
brokerTopicStats)
} catch {
case e: IOException =>
throw new KafkaException(s"Error validating messages while appending to log $name", e)
}
// ...
}
}
}
}
b) 日志追加
消息总会追加到最新的LogSegment中(旧的依据一定大小和时间,会截断),每个LogSegment维护一个基准偏移量baseOffset,这个偏移量是分区全局级别的。
如a)所述,日志追加前,偏移量会被修正,这里大致说明流程:
- 验证消息集的每个消息偏移是否递增
- 验证每个消息是否有效
- 调整
RecordBatch的offset和其他值
修正offset后,则要准备追加日志了:
- 首先判断目前的
LogSegment是否满,若已满,则需要截断日志并创建新的LogSegment(底层调用的是FileChannel#truncate) - 然后追加日志到
LogSegment中(调用LogSegment#append,底层调用的是FileChannel#write) - 更新日志尾的
offset,此处会更新下一个记录的起始offset值,即nextOffsetMetadata(调用updateLogEndOffset) - 根据刷盘消息间隔,必要时刷盘(调用
flush,底层调用的是FileChannel#force)
c) 分析验证消息集
这部分代码在LogValidator#validateMessagesAndAssignOffsets中,如a)所述。
这里以非压缩的消息为例,这里会进入assignOffsetsNonCompressed方法中:
-
首先将
MemoryRecords解构成多个RecordBatch -
验证
RecordBatch,这里主要验证RecordBatch消息个数、属性配置、事务配置、幂等配置等 -
验证
RecordBatch的每一个Record,这里主要验证消息压缩和校验码、消息的键、消息的时间戳等 -
验证完成后,设置
RecordBatch的first offset,max timestamp,leader epoch,这些都是分区全局的
d) 分配绝对偏移量
上面第4步涉及最重要的偏移量分配,这里调用了DefaultRecordBatch#setLastOffset。它传入消息集最后一个消息的绝对偏移量,减去last offset delta,就得到了start offset,并将其设置:
private def assignOffsetsNonCompressed(records: MemoryRecords, // 多个RecordBatch
topicPartition: TopicPartition,
// 初始为分区全局的下一个Record的绝对偏移量,即nextOffsetMetadata
offsetCounter: LongRef,
now: Long,
compactedTopic: Boolean,
timestampType: TimestampType,
timestampDiffMaxMs: Long,
partitionLeaderEpoch: Int,
origin: AppendOrigin,
magic: Byte, // 等于2
brokerTopicStats: BrokerTopicStats): ValidationAndOffsetAssignResult = {
var maxTimestamp = RecordBatch.NO_TIMESTAMP
var offsetOfMaxTimestamp = -1L
val initialOffset = offsetCounter.value
val firstBatch = getFirstBatchAndMaybeValidateNoMoreBatches(records, NoCompressionCodec)
// 遍历RecordBatch
for (batch <- records.batches.asScala) {
// 验证RecordBatch
validateBatch(topicPartition, firstBatch, batch, origin, magic, brokerTopicStats)
var maxBatchTimestamp = RecordBatch.NO_TIMESTAMP
var offsetOfMaxBatchTimestamp = -1L
val recordErrors = new ArrayBuffer[ApiRecordError](0)
// 遍历Record
for ((record, batchIndex) <- batch.asScala.view.zipWithIndex) {
// 验证Record
validateRecord(batch, topicPartition, record, batchIndex, now, timestampType,
timestampDiffMaxMs, compactedTopic, brokerTopicStats).foreach(recordError => recordErrors += recordError)
// 增加offset值(每次+1),代表最新的Record偏移量
val offset = offsetCounter.getAndIncrement()
if (batch.magic > RecordBatch.MAGIC_VALUE_V0 && record.timestamp > maxBatchTimestamp) {
maxBatchTimestamp = record.timestamp
offsetOfMaxBatchTimestamp = offset
}
}
processRecordErrors(recordErrors)
if (batch.magic > RecordBatch.MAGIC_VALUE_V0 && maxBatchTimestamp > maxTimestamp) {
maxTimestamp = maxBatchTimestamp
offsetOfMaxTimestamp = offsetOfMaxBatchTimestamp
}
// 这里设置了RecordBatch的start offset
batch.setLastOffset(offsetCounter.value - 1)
// 设置其他字段...
// ...
}
// ...
ValidationAndOffsetAssignResult(...)
}
public void setLastOffset(long offset) {
// 最新的绝对offset - 最新的delta offset = 第一个的offset
buffer.putLong(BASE_OFFSET_OFFSET, offset - lastOffsetDelta());
}
可以看到,一个分区的日志,它的偏移量是严格单调递增的。
分配好绝对偏移量后,才可以将数据写入日志文件中。而写之前,如b)所述,需要检查日志是否需要分段,这在下面一节说明。
1.3. 日志分段和追加
一个分区日志Log维护了它所有的日志分段LogSegment,它保证:
- 任意时间,只有最新的
LogSegment活跃 LogSegment内,新旧LogSegment见,消息的偏移量单调递增
字段的参考可看1.1.节。
a) 日志偏移量元数据
日志偏移量元数据用LogOffsetMetadata表示,它包含:
messageOffset:消息偏移量segmentBaseOffset:当前分段的第一个消息偏移量relativePositionInSegment:消息在日志分段文件的物理位置
Log中有下面几个字段使用了这个类:
nextOffsetMetadata:下一个消息的起始偏移量元数据(也可以一定程度上代表日志尾偏移量)highWatermarkMetadata:最高水位偏移量元数据(读取时,偏移量不能超过最高水位)
b) 滚动创建日志分段
当日志满了后,就会滚动创建新的日志分段,这会引入文件截断操作。
而创建新分段的条件可以:
- 分段大小过大(
log.segment.bytes) - 分段维持了一定时间(
log.roll.ms) - 索引文件满(
log.index.size.max.bytes) - 追加消息的偏移量与当前分段的基准偏移量大于
Integer.MAX_VALUE
def shouldRoll(rollParams: RollParams): Boolean = {
val reachedRollMs = timeWaitedForRoll(rollParams.now, rollParams.maxTimestampInMessages) > rollParams.maxSegmentMs - rollJitterMs
// 创建分段的条件:
// 1. 分段大小过大(log.segment.bytes)
size > rollParams.maxSegmentBytes - rollParams.messagesSize ||
(size > 0 && reachedRollMs) || // 2. 分段维持了一定时间(log.roll.ms)
offsetIndex.isFull || timeIndex.isFull || // 3. 索引文件满(log.index.size.max.bytes)
!canConvertToRelativeOffset(rollParams.maxOffsetInMessages) // 4. 追加消息的偏移量与当前分段的基准偏移量大于Integer.MAX_VALUE
}
而创建新分段,则会调用roll方法,它会创建新的数据文件、索引(时间和偏移量)文件和事务文件。具体如下:
def roll(expectedNextOffset: Option[Long] = None): LogSegment = {
maybeHandleIOException(s"Error while rolling log segment for $topicPartition in dir ${dir.getParent}") {
val start = time.hiResClockMs()
lock synchronized {
checkIfMemoryMappedBufferClosed()
// 设置最新偏移量为新分段的起始偏移量
val newOffset = math.max(expectedNextOffset.getOrElse(0L), logEndOffset)
// 创建新分段数据文件,以起始偏移量作为文件名
val logFile = Log.logFile(dir, newOffset)
// ...
} else {
// 创建偏移量索引文件
val offsetIdxFile = offsetIndexFile(dir, newOffset)
// 创建时间索引文件
val timeIdxFile = timeIndexFile(dir, newOffset)
// 创建事务索引文件
val txnIdxFile = transactionIndexFile(dir, newOffset)
// ...
// 触发让分段不活跃的回调
Option(segments.lastEntry).foreach(_.getValue.onBecomeInactiveSegment())
}
// ...
// 创建新分段
val segment = LogSegment.open(dir,
baseOffset = newOffset,
config,
time = time,
fileAlreadyExists = false,
initFileSize = initFileSize,
preallocate = config.preallocate)
// 添加新分段到日志
addSegment(segment)
// 更新日志尾的偏移量
updateLogEndOffset(nextOffsetMetadata.messageOffset)
// 启动后台线程,将旧分段数据刷盘
scheduler.schedule("flush-log", () => flush(newOffset), delay = 0L)
segment
}
}
}
c) 追加数据
数据文件和索引文件都会被追加数据,只不过策略不一样:
-
数据文件会直接写入磁盘
-
索引文件会根据写入数据间隔大小
indexIntervalBytes,才会写入一项例如:索引每隔500字节写入一项索引,假如一个消息10字节,那么写50个消息后,才会写入1个索引项
def append(largestOffset: Long,
largestTimestamp: Long,
shallowOffsetOfMaxTimestamp: Long,
records: MemoryRecords): Unit = {
if (records.sizeInBytes > 0) {
// 读取文件物理位置
val physicalPosition = log.sizeInBytes()
if (physicalPosition == 0)
rollingBasedTimestamp = Some(largestTimestamp)
ensureOffsetInRange(largestOffset)
// 追加数据文件,返回写入字节数
val appendedBytes = log.append(records)
if (largestTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = largestTimestamp
offsetOfMaxTimestampSoFar = shallowOffsetOfMaxTimestamp
}
// 若距离上次写入索引项时,已经累积写入超过indexIntervalBytes的数据项,则写入索引项
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0 // 清零
}
bytesSinceLastIndexEntry += records.sizeInBytes // 累加数据项大小
}
}
注意索引项的写入:由于索引项属于小数据,因此不需要每次都写磁盘,可以累积一段时间再写,降低些磁盘的频率,这样可以提高性能。
而落盘的底层使用了FileChannel#write和FileChannel#force,这部分不赘述。
d) 索引文件
Kafka索引文件有如下特点:
- 索引项记录了偏移量和文件物理位置的映射,共8字节
- 稀疏:不会为所有数据项建立索引
- 有序:索引文件记录的偏移量是有序的,查找时使用二分法
- 偏移量存储的是相对偏移量,通过和基准偏移量相加,即可得到绝对偏移量,它使得存储占用的空间更少
- 索引文件使用
mmap进行读写,查询效率更高
1.4. 读取日志
如1.1.所述,一个分区的日志管理了所有的日志分段,并按起始偏移量有序保存,而日志分段的数据文件和索引文件也是按照偏移量有序保存,因此查找日志中的某个消息,可以使用二分法:
- 确定消息位于哪个日志分段
- 确定消息在日志分段的位置
而大体读取步骤如下:
- 根据起始偏移量,根据二分法查找对应分段的索引文件,得到数据文件的物理位置
- 从物理位置开始一条一条读取(先粗粒度按
RecordBatch读,再细粒度按Record读),直到读取到起始偏移量的消息 - 从2的位置开始,往后拉取数据
a) 查找日志分段
查找日志分段起始很简单,就是:根据给定的起始偏移量,从ConcurrentSkipListMap中找到对应的分段。这里调用floor,即找到的分段基准偏移量最大,但不超过给定的起始偏移量。
找到对应分段后,即可读取消息:
- 读取消息的范围是
startOffset ~ maxOffset,其中后者由isolation决定(可以是日志尾、最高水位、最新已提交的偏移量) - 若没有从分段中读到消息,则会尝试在下一个分段中读取
def read(startOffset: Long, // 给定的起始偏移量
maxLength: Int, // 最大拉取的数据大小
isolation: FetchIsolation, // 拉取隔离配置: LogEnd, HighWatermark, TxnCommitted
minOneMessage: Boolean // 若为true,若第一个消息大于maxLength,则会返回该消息
): FetchDataInfo = {
maybeHandleIOException(s"Exception while reading from $topicPartition in dir ${dir.getParent}") {
val includeAbortedTxns = isolation == FetchTxnCommitted
// 获取当前日志尾偏移量
val endOffsetMetadata = nextOffsetMetadata
val endOffset = nextOffsetMetadata.messageOffset
if (startOffset == endOffset)
// 若起始偏移=尾偏移,则没消息可拉取,直接返回
return emptyFetchDataInfo(endOffsetMetadata, includeAbortedTxns)
// 二分法,调用floor,从跳表中获取对应的日志分段
var segmentEntry = segments.floorEntry(startOffset)
// ...
// 根据isolation,确定拉取消息偏移量的上限,即:
// a) FetchLogEnd: 上限为日志尾偏移量
// b) FetchHighWatermark: 上限为最高水位(一般小于日志尾偏移量),该水位前的数据已经复制到了给定数量多从副本
// c) FetchTxnCommitted: 上限为最后一个事物提及的偏移量
val maxOffsetMetadata = isolation match {
case FetchLogEnd => nextOffsetMetadata
case FetchHighWatermark => fetchHighWatermarkMetadata
case FetchTxnCommitted => fetchLastStableOffsetMetadata
}
// 若给定的起始偏移量超过了最大偏移量,则没有消息读到,返回空
if (startOffset > maxOffsetMetadata.messageOffset) {
val startOffsetMetadata = convertToOffsetMetadataOrThrow(startOffset)
return emptyFetchDataInfo(startOffsetMetadata, includeAbortedTxns)
}
while (segmentEntry != null) {
val segment = segmentEntry.getValue
val maxPosition = {
if (maxOffsetMetadata.segmentBaseOffset == segment.baseOffset) {
maxOffsetMetadata.relativePositionInSegment
} else {
segment.size
}
}
// 从对应分段里读消息
val fetchInfo = segment.read(startOffset, maxLength, maxPosition, minOneMessage)
if (fetchInfo == null) {
// 若没读到数据,则从下一个分段里再读一次
segmentEntry = segments.higherEntry(segmentEntry.getKey)
} else {
// 否则,返回读取到的消息
return if (includeAbortedTxns)
addAbortedTransactions(startOffset, segmentEntry, fetchInfo)
else
fetchInfo
}
}
FetchDataInfo(nextOffsetMetadata, MemoryRecords.EMPTY)
}
}
b) 查找索引
查找索引发生在某个日志分段内的,给定一个起始偏移,从而找到消息在日志分段内的物理位置。这部分在translateOffset方法中实现:
- 首先利用
mmap和二分法,找到消息所在的物理位置 - 然后利用这个物理位置,遍历日志分段的
RecordBatch,返回包含该消息的RecordBatch的信息(RecordBatch最后一项消息的绝对偏移、RecordBatch物理位置、RecordBatch大小)
// In LogSegment
@threadsafe
private[log] def translateOffset(offset: Long, startingFilePosition: Int = 0): LogOffsetPosition = {
// 1. 利用mmap内存文件映射,使用二分法,返回目标消息的绝对偏移量和物理位置
val mapping = offsetIndex.lookup(offset)
// 2. 然后利用查询到的物理位置,返回其所在的RecordBatch的最后一项的绝对偏移、物理位置和大小
log.searchForOffsetWithSize(offset, max(mapping.position, startingFilePosition))
}
// In OffsetIndex
// 查询索引文件,找到目标offset在数据文件中的物理位置
def lookup(targetOffset: Long): OffsetPosition = {
maybeLock(lock) {
val idx = mmap.duplicate // 首先将mmap duplicate一份(逻辑复制)
val slot = largestLowerBoundSlotFor(idx, targetOffset, IndexSearchType.KEY) // 二分法找到索引项在索引文件中的下标
if(slot == -1)
OffsetPosition(baseOffset, 0)
else
// 转换成 (绝对偏移量, 物理位置),并返回
parseEntry(idx, slot)
}
}
override protected def parseEntry(buffer: ByteBuffer, n: Int): OffsetPosition = {
// 绝对偏移量 = 基准偏移量 + 相对偏移量(即mmap.getInt(slot * indexEntrySize))
// 物理位置 = mmap.getInt(slot * indexEntrySize + 4)
OffsetPosition(baseOffset + relativeOffset(buffer, n), physical(buffer, n))
}
// In FileRecords
public LogOffsetPosition searchForOffsetWithSize(long targetOffset, int startingPosition) {
// 从给定的起始位置开始遍历RecordBatch
for (FileChannelRecordBatch batch : batchesFrom(startingPosition)) {
// 返回第一个大于等于目标偏移的RecordBatch信息,即包含该消息的RecordBatch
// 包括:RecordBatch最后一个消息的绝对偏移、RecordBatch的物理位置、RecordBatch的大小
long offset = batch.lastOffset();
if (offset >= targetOffset)
return new LogOffsetPosition(offset, batch.position(), batch.sizeInBytes());
}
return null;
}
c) 搜索数据文件
确定好要读取的RecordBatch位置信息后,即可开始读取对应的信息。
这里会调用FileRecords#slice方法,返回一个文件消息集视图(和ByteBuf#slice非常像)。这部分非常简单,只需逻辑截取一段即可:
public FileRecords slice(int position, int size) throws IOException {
// ...
int end = this.start + position + size; // 设置文件末尾物理位置:原物理位置+新物理位置+长度
if (end < 0 || end >= start + sizeInBytes()) // 处理整数溢出
end = start + sizeInBytes();
// 返回一个FileRecords逻辑视图,起始位置设为:原物理位置+新物理位置,末尾位置如上所述
return new FileRecords(file, channel, this.start + position, end, true);
}
最后截取的这段视图,就会随着偏移量信息返回,日志分段内的读取结束。整体代码如下:
// In LogSegment
def read(startOffset: Long,
maxSize: Int,
maxPosition: Long = size,
minOneMessage: Boolean = false): FetchDataInfo = {
// 1. 查找索引,得到记录所在的RecordBatch最后一项的绝对偏移量、RecordBatch的物理位置和大小
val startOffsetAndSize = translateOffset(startOffset)
if (startOffsetAndSize == null)
return null
val startPosition = startOffsetAndSize.position
// 2. 设置偏移量元数据,包含: 所在RecordBatch的最后一项的绝对偏移量,当前日志分段的基准偏移量,所在RecordBatch的起始物理位置
val offsetMetadata = LogOffsetMetadata(startOffset, this.baseOffset, startPosition)
val adjustedMaxSize =
if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)
else maxSize
if (adjustedMaxSize == 0)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)
val fetchSize: Int = min((maxPosition - startPosition).toInt, adjustedMaxSize)
// 3. 调用slice,返回所需拉取数据的文件消息集视图,随着偏移量元数据,返回给上层
FetchDataInfo(offsetMetadata, log.slice(startPosition, fetchSize),
firstEntryIncomplete = adjustedMaxSize < startOffsetAndSize.size)
}
d) 零拷贝传输
Kafka利用量FileChannel#transferTo和FileChannel#transferFrom,实现了通道间的零拷贝传输。消息拉取的时候,就使用了这样的技巧。
关于这部分,可参考:https://developer.ibm.com/articles/j-zerocopy/,这里不再赘述。
2. 日志管理
日志管理LogManager负责日志的创建、检索、清理等管理操作,而日志读写操作由日志实例Log操作。
2.1. 创建日志
创建日志在getOrCreateLog方法中:
private val currentLogs = new Pool[TopicPartition, Log]() // 日志实例
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
logCreationOrDeletionLock synchronized {
// 获取日志,没有则创建
getLog(topicPartition, isFuture).getOrElse {
// ...
// 选择一个目录存储日志
val logDirs: List[File] = {
val preferredLogDir = preferredLogDirs.get(topicPartition)
if (preferredLogDir != null)
List(new File(preferredLogDir))
else
nextLogDirs()
}
// 根据topic和分区设置目录名
val logDirName = {
if (isFuture)
Log.logFutureDirName(topicPartition)
else
Log.logDirName(topicPartition)
}
// 创建目录
val logDir = logDirs
.toStream // to prevent actually mapping the whole list, lazy map
.map(createLogDirectory(_, logDirName))
.find(_.isSuccess)
.getOrElse(Failure(new KafkaStorageException("No log directories available. Tried " + logDirs.map(_.getAbsolutePath).mkString(", "))))
.get // If Failure, will throw
// 创建日志实例
val log = Log(
dir = logDir,
config = config,
logStartOffset = 0L,
recoveryPoint = 0L,
maxProducerIdExpirationMs = maxPidExpirationMs,
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
scheduler = scheduler,
time = time,
brokerTopicStats = brokerTopicStats,
logDirFailureChannel = logDirFailureChannel)
if (isFuture)
futureLogs.put(topicPartition, log)
else
// 将日志加入到currentLogs中管理
currentLogs.put(topicPartition, log)
// ...
preferredLogDirs.remove(topicPartition)
log // 返回日志实例
}
}
}
Kafka会给每个topic的每个分区建立一个目录,这个目录建立在log.dirs下(可提供多个),目录下包含:
- 偏移量索引
- 时间戳索引
而在log.dirs下,还会创建检查点文件,包含:
- 恢复检查点文件
recovery-point-offset-checkpoint - 副本日志起始偏移量检查点文件
log-start-offset-checkpoint
2.2. 加载日志
日志管理器启动后,会加载目录下的所有日志。它首先读取检查点,然后从检查点开始加载日志。而由于这个过程比较慢,加载日志放在后台线程池进行:
private def loadLogs(): Unit = {
val startMs = time.milliseconds
val threadPools = ArrayBuffer.empty[ExecutorService]
val offlineDirs = mutable.Set.empty[(String, IOException)]
val jobs = mutable.Map.empty[File, Seq[Future[_]]]
for (dir <- liveLogDirs) {
try {
// 给每个目录创建一个线程池
val pool = Executors.newFixedThreadPool(numRecoveryThreadsPerDataDir)
threadPools.append(pool)
// ...
// 读取检查点内容
var recoveryPoints = Map[TopicPartition, Long]()
try {
recoveryPoints = this.recoveryPointCheckpoints(dir).read
} catch {
case e: Exception =>
warn(s"Error occurred while reading recovery-point-offset-checkpoint file of directory $dir", e)
warn("Resetting the recovery checkpoint to 0")
}
// 读取检查点中每个分区的起始偏移量
var logStartOffsets = Map[TopicPartition, Long]()
try {
logStartOffsets = this.logStartOffsetCheckpoints(dir).read
} catch {
case e: Exception =>
warn(s"Error occurred while reading log-start-offset-checkpoint file of directory $dir", e)
}
// 设置加载日志的目录
val jobsForDir = for {
dirContent <- Option(dir.listFiles).toList
logDir <- dirContent if logDir.isDirectory
} yield {
// 创建加载日志的任务
val runnable: Runnable = () => {
try {
loadLog(logDir, recoveryPoints, logStartOffsets) // 加载日志
} catch {
case e: IOException =>
offlineDirs.add((dir.getAbsolutePath, e))
error(s"Error while loading log dir ${dir.getAbsolutePath}", e)
}
}
runnable
}
// 提交任务
jobs(cleanShutdownFile) = jobsForDir.map(pool.submit)
} catch {
case e: IOException =>
offlineDirs.add((dir.getAbsolutePath, e))
error(s"Error while loading log dir ${dir.getAbsolutePath}", e)
}
}
// ...
}
2.3. 后台管理服务
加载完日志后,LogManager会调用startUp方法,启动5个后台定时管理任务:
- 日志清理任务
kafka-log-retention - 日志刷盘任务
kafka-log-flush - 检查点任务
kafka-recovery-point-checkpoint - 日志起始偏移检查点任务
kafka-log-start-offset-checkpoint - 日志删除任务
kafka-delete-logs
这边主要说明前3个。
a) 检查点任务
检查点在日志管理和日志实例运行中,有重要的作用:
- 启动时,读取检查点,从检查点开始进行日志恢复,创建分区的日志实例
- 刷新分区日志时,最新的偏移量会作为该分区的检查点
- 日志管理器会定时扫描,将所有分区的检查点写入检查点文件
检查点定时任务代码如下:
def checkpointLogRecoveryOffsets(): Unit = {
// 遍历所有的log.dirs目录
logsByDir.foreach { case (dir, partitionToLogMap) =>
liveLogDirs.find(_.getAbsolutePath.equals(dir)).foreach { f =>
// 在该目录下,刷新对应topic分区的检查点
// partitionToLogMap.values是目录下所有的分区日志Log实例
checkpointRecoveryOffsetsAndCleanSnapshot(f, partitionToLogMap.values.toSeq)
}
}
}
private[log] def checkpointRecoveryOffsetsAndCleanSnapshot(dir: File, logsToCleanSnapshot: Seq[Log]): Unit = {
try {
// 写入检查点文件
checkpointLogRecoveryOffsetsInDir(dir)
logsToCleanSnapshot.foreach(_.deleteSnapshotsAfterRecoveryPointCheckpoint())
} catch {
// ..
}
}
private def checkpointLogRecoveryOffsetsInDir(dir: File): Unit = {
// 遍历每个分区,刷新检查点
// 写入的检查点即日志最新刷盘的偏移量
for {
partitionToLog <- logsByDir.get(dir.getAbsolutePath)
checkpoint <- recoveryPointCheckpoints.get(dir)
} {
checkpoint.write(partitionToLog.map { case (tp, log) => tp -> log.recoveryPoint })
}
}
而日志起始偏移检查点任务也比较类似,只是定期写入的是每个topic分区的起始偏移量。
b) 定时刷盘
Kafka会定期刷新脏日志到磁盘,以提高可靠性。
刷盘的频率可由大小和时间控制。而定时刷盘则由log.flush.interval.ms控制。
刷盘代码比较简单,遍历日志并检查刷盘时间是否满足要求即可。刷盘需要更新检查点,而底层调用的是FileChannel#force。
private def flushDirtyLogs(): Unit = {
for ((topicPartition, log) <- currentLogs.toList ++ futureLogs.toList) {
// 遍历所有日志
try {
// 若距离上次刷盘超过log.flush.interval.ms,则刷盘
val timeSinceLastFlush = time.milliseconds - log.lastFlushTime
if(timeSinceLastFlush >= log.config.flushMs)
log.flush // 刷盘
} catch {
// ...
}
}
}
def flush(offset: Long): Unit = {
maybeHandleIOException(s"Error while flushing log for $topicPartition in dir ${dir.getParent} with offset $offset") {
if (offset <= this.recoveryPoint)
return
// 遍历需要刷盘的分段,先刷盘
// 分段可能有多个(当上一个检查点不在最新的分段上时)
for (segment <- logSegments(this.recoveryPoint, offset))
segment.flush()
lock synchronized {
checkIfMemoryMappedBufferClosed()
if (offset > this.recoveryPoint) {
// 刷盘后,设置新检查点
this.recoveryPoint = offset
lastFlushedTime.set(time.milliseconds)
}
}
}
}
c) 日志清理
清理日志包含2个策略:
- 删除:超过日志大小阈值,直接删除整个日志分段
- 合并压缩:不删除日志分段,而是进行合并压缩
相关代码如下:
def cleanupLogs(): Unit = {
var total = 0
val startMs = time.milliseconds
// 得到没有压缩过的日志实例,作为可清理的对象
val deletableLogs = {
if (cleaner != null) {
// 首先暂停日志清理
// 然后返回没有压缩过,且没有正在清理的日志实例
// 返回的日志实例,在cleaner中会被暂停清理
cleaner.pauseCleaningForNonCompactedPartitions()
} else {
currentLogs.filter {
case (_, log) => !log.config.compact
}
}
}
try {
deletableLogs.foreach {
// 遍历可清理的日志对象
case (topicPartition, log) =>
// 删除日志的旧分段
total += log.deleteOldSegments()
val futureLog = futureLogs.get(topicPartition)
if (futureLog != null) {
total += futureLog.deleteOldSegments()
}
}
} finally {
// 重新恢复日志的清理
if (cleaner != null) {
cleaner.resumeCleaning(deletableLogs.map(_._1))
}
}
}
删除日志分段的方法定义在Log#deleteOldSegment:
def deleteOldSegments(): Int = {
if (config.delete) {
// 若配置策略为“删除”
deleteRetentionMsBreachedSegments() // 1. 删除保留时间过长的日志分段
+ deleteRetentionSizeBreachedSegments() // 2. 删除保留大小过大的日志分段,日志整个大小
// 删除的条件为: size - retentionSize - segment.size >= 0
+ deleteLogStartOffsetBreachedSegments() // 3. 删除分段末尾偏移量小于该分区日志(含多个分段)起始偏移量的日志分段
} else {
// 若配置策略为“压缩”
// 只能删除比日志起始偏移量小的日志分段,后面的分段将会被压缩
deleteLogStartOffsetBreachedSegments()
}
}
而删除分段会采用异步的方式:先将分段从Log#segments删除,然后异步删除分段文件。这部分代码在removeAndDeleteSegments中,这里不贴了。
合并压缩涉及到了LogCleaner,这部分比较繁琐,因此放到后面一节单独说明。
2.4. 日志合并压缩
这部分的核心角色时LogCleaner。日志压缩时,后台线程会扫描所有旧的日志分段,并保留每个键的最新的消息。
a) 清理点与删除点
日志清理需要引入2个概念:清理点和删除点。
日志压缩会将所有旧分段的消息,复制到新的日志分段上。为了降低复制的内存开心,Kafka会在压缩前,将日志按照“清理点”分成日志尾部和头部:
- 日志头部:清理点到活跃日志的基准偏移量(即未压缩)
- 日志尾部:起始到清理点(即已压缩部分)
每次压缩,会将日志头部和日志尾部一起压缩,成为新的日志尾部。
压缩的特征如下:
- 压缩前后,消息的偏移量不变,且有序
- 压缩后
- 消息的物理位置发生变化
- 偏移量不再连续(若消费者没追赶上,从压缩的部分开始拉取,可能会丢失消息)
日志压缩需要考虑删除消息的场景。当某个带有键的消息,它在旧日志分段的最新值为null,压缩时,需要删除之前的所有该键的消息,这就是“删除点”(墓碑标记)。
“删除点”保留的条件为:日志分段的最近修改时间大于deleteHorizonMs。该值的计算方法为:日志头部起始位置前的最后一个分段的最近修改时间,减去delete.retention.ms。可知,日志头部之后,“删除点”都会被保留。
结合上面,日志压缩的具体步骤如下:
- 选择日志头部与日志尾部比例最大的分区,进行日志压缩
- 对日志头部构建一个键到最新偏移量的映射,只保留最新偏移量的消息
- 重新复制每条消息到新文件中,若消息到键有更高的偏移量,则不会复制这条消息
- 产生新的日志分段,替换旧的未压缩的分段
b) 日志清理管理器与清理线程
之前提到,日志清理由LogCleaner处理,而里面关键的是LogCleanerManager。
LogCleanerManager会以日志目录列表和所有日志作为参数,而每个目录下,都有一个清理点检查点文件cleaner-offset-checkpoint,它记录了每个日志的“清理点”:
private[log] class LogCleanerManager(val logDirs: Seq[File], // 所有日志目录
val logs: Pool[TopicPartition, Log], // 所有日志
val logDirFailureChannel: LogDirFailureChannel) extends Logging with KafkaMetricsGroup {
import LogCleanerManager._
protected override def loggerName = classOf[LogCleaner].getName
// 清理点检查点文件名
private[log] val offsetCheckpointFile = "cleaner-offset-checkpoint"
// 所有日志的检查点文件
@volatile private var checkpoints = logDirs.map(dir =>
(dir, new OffsetCheckpointFile(new File(dir, offsetCheckpointFile), logDirFailureChannel))).toMap
// ...
}
而调用grabFilthiestCompactedLog会读取所有日志的检查点,选择最需要清理的日志LogToClean:
def grabFilthiestCompactedLog(time: Time, preCleanStats: PreCleanStats = new PreCleanStats()): Option[LogToClean] = {
inLock(lock) {
// ...
val lastClean = allCleanerCheckpoints // 读取记录了清理点检查点文件
// 过滤日志,过滤后得到的日志需要:
// 1. 配置“压缩”清理策略
// 2. 日志没有正在压缩中
// 3. 需要压缩的日志旧分段非空
val dirtyLogs = logs.filter {
case (_, log) => log.config.compact
}.filterNot {
case (topicPartition, log) =>
inProgress.contains(topicPartition) || isUncleanablePartition(log, topicPartition)
}.map {
// 为每个日志,创建LogToClean对象
case (topicPartition, log) =>
try {
val lastCleanOffset = lastClean.get(topicPartition)
val (firstDirtyOffset, firstUncleanableDirtyOffset) = cleanableOffsets(log, lastCleanOffset, now)
val compactionDelayMs = maxCompactionDelay(log, firstDirtyOffset, now)
preCleanStats.updateMaxCompactionDelay(compactionDelayMs)
LogToClean(topicPartition, log, firstDirtyOffset, firstUncleanableDirtyOffset, compactionDelayMs > 0)
} catch {
case e: Throwable => throw new LogCleaningException(log,
s"Failed to calculate log cleaning stats for partition $topicPartition", e)
}
}.filter(ltc => ltc.totalBytes > 0)
// 计算最大比例:日志头部大小(dirtyBytes)/日志大小
this.dirtiestLogCleanableRatio = if (dirtyLogs.nonEmpty) dirtyLogs.max.cleanableRatio else 0
// 选择上面比例最大的日志,并且必须要满足最小比例阈值
// 最后得到0或1个日志
val cleanableLogs = dirtyLogs.filter { ltc =>
(ltc.needCompactionNow && ltc.cleanableBytes > 0) || ltc.cleanableRatio > ltc.log.config.minCleanableRatio
}
// 返回
if(cleanableLogs.isEmpty) {
None
} else {
preCleanStats.recordCleanablePartitions(cleanableLogs.size)
val filthiest = cleanableLogs.max
inProgress.put(filthiest.topicPartition, LogCleaningInProgress) // 设置日志正在压缩
Some(filthiest)
}
}
}
返回的LogToClean定义如下:
private case class LogToClean(topicPartition: TopicPartition,
log: Log,
firstDirtyOffset: Long, // 日志头部第一个偏移量
uncleanableOffset: Long, // 第一个不可清理的第一个偏移量
needCompactionNow: Boolean = false) extends Ordered[LogToClean] {
// 日志尾部大小
val cleanBytes = log.logSegments(-1, firstDirtyOffset).map(_.size.toLong).sum
// 第一个不可清理的偏移量(它由活动分段确定),日志头部大小
val (firstUncleanableOffset, cleanableBytes) = LogCleanerManager.calculateCleanableBytes(log, firstDirtyOffset, uncleanableOffset)
// 待清理的日志总大小
val totalBytes = cleanBytes + cleanableBytes
// 比例计算
val cleanableRatio = cleanableBytes / totalBytes.toDouble
override def compare(that: LogToClean): Int = math.signum(this.cleanableRatio - that.cleanableRatio).toInt
}
而清理线程定义在CleanerThread,每个线程都有一个清理器Cleaner:
private[log] class CleanerThread(threadId: Int)
extends ShutdownableThread(name = s"kafka-log-cleaner-thread-$threadId", isInterruptible = false) {
protected override def loggerName = classOf[LogCleaner].getName
if (config.dedupeBufferSize / config.numThreads > Int.MaxValue)
warn("Cannot use more than 2G of cleaner buffer space per cleaner thread, ignoring excess buffer space...")
// 清理器Cleaner
val cleaner = new Cleaner(id = threadId,
offsetMap = new SkimpyOffsetMap(memory = math.min(config.dedupeBufferSize / config.numThreads, Int.MaxValue).toInt, hashAlgorithm = config.hashAlgorithm),
ioBufferSize = config.ioBufferSize / config.numThreads / 2,
maxIoBufferSize = config.maxMessageSize,
dupBufferLoadFactor = config.dedupeBufferLoadFactor,
throttler = throttler,
time = time,
checkDone = checkDone)
// 清理线程执行的任务
override def doWork(): Unit = {
val cleaned = tryCleanFilthiestLog() // 尝试执行日志压缩
if (!cleaned)
pause(config.backOffMs, TimeUnit.MILLISECONDS)
}
private def tryCleanFilthiestLog(): Boolean = {
try {
cleanFilthiestLog()
} catch {
// ...
}
}
// 清理/压缩日志
@throws(classOf[LogCleaningException])
private def cleanFilthiestLog(): Boolean = {
val preCleanStats = new PreCleanStats()
// 选择上面提及的比例最大的日志,进行清理/压缩
val cleaned = cleanerManager.grabFilthiestCompactedLog(time, preCleanStats) match {
case None =>
false
case Some(cleanable) =>
this.lastPreCleanStats = preCleanStats
try {
cleanLog(cleanable) // 清理/压缩日志
true
} catch {
// ...
}
}
// 删除旧日志分段,分段的偏移量小于日志(不是最新分段)的起始偏移
val deletable: Iterable[(TopicPartition, Log)] = cleanerManager.deletableLogs()
try {
deletable.foreach { case (_, log) =>
try {
log.deleteOldSegments() // 删除旧日志分段
} catch {
// ...
}
}
} finally {
cleanerManager.doneDeleting(deletable.map(_._1))
}
cleaned
}
}
c) 日志压缩
这部分在b)中的提到的函数cleanLog中,最后会调用的方法式doClean,参与的分段包括所有的旧日志分段,步骤如下:
- 从清理检查点开始,为日志头部构建键到最新偏移量的映射,所有相同键但低于最新偏移量的消息都会被直接删除
- 将剩余的消息复制到新的日志分段
- 将新的压缩后的分段,替换掉旧的日志分段
- 更新日志的清理检查点文件
首先是建立键到最新偏移量的映射,这里关键函数为buildOffsetMap,它以日志清理点(firstDirtyOffset)作为起始点,以当前日志活跃分段到基准偏移量(upperBoundOffset)为结束点,构建映射:
private[log] def buildOffsetMap(log: Log,
start: Long, // 起始点:日志清理点
end: Long, // 结束点:活跃日志分段到基准偏移量
map: OffsetMap,
stats: CleanerStats): Unit = {
map.clear()
val dirty = log.logSegments(start, end).toBuffer
val nextSegmentStartOffsets = new ListBuffer[Long]
if (dirty.nonEmpty) {
for (nextSegment <- dirty.tail) nextSegmentStartOffsets.append(nextSegment.baseOffset)
nextSegmentStartOffsets.append(end)
}
// ...
// Add all the cleanable dirty segments. We must take at least map.slots * load_factor,
// but we may be able to fit more (if there is lots of duplication in the dirty section of the log)
var full = false
for ( (segment, nextSegmentStartOffset) <- dirty.zip(nextSegmentStartOffsets) if !full) {
checkDone(log.topicPartition)
// 扫描所有的分段,构建映射,直到缓存满为止
full = buildOffsetMapForSegment(log.topicPartition, segment, map, start, nextSegmentStartOffset, log.config.maxMessageSize, transactionMetadata, stats)
// ...
}
info("Offset map for log %s complete.".format(log.name))
}
private def buildOffsetMapForSegment(topicPartition: TopicPartition,
segment: LogSegment,
map: OffsetMap,
startOffset: Long,
nextSegmentStartOffset: Long,
maxLogMessageSize: Int,
transactionMetadata: CleanedTransactionMetadata,
stats: CleanerStats): Boolean = {
var position = segment.offsetIndex.lookup(startOffset).position
val maxDesiredMapSize = (map.slots * this.dupBufferLoadFactor).toInt
while (position < segment.log.sizeInBytes) {
checkDone(topicPartition)
readBuffer.clear()
try {
// 将分段读入缓存中
segment.log.readInto(readBuffer, position)
} catch {
case e: Exception =>
throw new KafkaException(s"Failed to read from segment $segment of partition $topicPartition " +
"while loading offset map", e)
}
val records = MemoryRecords.readableRecords(readBuffer)
throttler.maybeThrottle(records.sizeInBytes)
val startPosition = position
// 遍历所有记录
for (batch <- records.batches.asScala) {
// ...
} else {
val isAborted = transactionMetadata.onBatchRead(batch)
// ...
else {
for (record <- batch.asScala) {
if (record.hasKey && record.offset >= startOffset) {
// 构建映射,只需要最大偏移量的记录
if (map.size < maxDesiredMapSize)
map.put(record.key, record.offset)
else
// 若满了,则直接返回
return true
}
stats.indexMessagesRead(1)
}
}
}
if (batch.lastOffset >= startOffset)
map.updateLatestOffset(batch.lastOffset)
}
val bytesRead = records.validBytes
position += bytesRead
stats.indexBytesRead(bytesRead)
// if we didn't read even one complete message, our read buffer may be too small
if(position == startPosition)
growBuffersOrFail(segment.log, position, maxLogMessageSize, records)
}
// In the case of offsets gap, fast forward to latest expected offset in this segment.
map.updateLatestOffset(nextSegmentStartOffset - 1L)
restoreBuffers()
false
}
而日志压缩会将多个日志分段合并成一个日志分段,因此会将日志分段分组,每个组的分段大小总和不能超过分段阈值:
- 日志尾部的小分段单独分组
- 日志头部的分段每个都等于分段阈值
这里会调用groupSegmentsBySize来对分段进行分组:
private[log] def groupSegmentsBySize(segments: Iterable[LogSegment], maxSize: Int, maxIndexSize: Int, firstUncleanableOffset: Long): List[Seq[LogSegment]] = {
var grouped = List[List[LogSegment]]()
var segs = segments.toList // 所有参与压缩的日志分段
while(segs.nonEmpty) {
var group = List(segs.head) // 每个分组,以第一个分段打底
var logSize = segs.head.size.toLong
var indexSize = segs.head.offsetIndex.sizeInBytes.toLong
var timeIndexSize = segs.head.timeIndex.sizeInBytes.toLong
segs = segs.tail // 剩余分段
// 添加分段到分组,直到满了才推出
while(segs.nonEmpty &&
logSize + segs.head.size <= maxSize &&
indexSize + segs.head.offsetIndex.sizeInBytes <= maxIndexSize &&
timeIndexSize + segs.head.timeIndex.sizeInBytes <= maxIndexSize &&
lastOffsetForFirstSegment(segs, firstUncleanableOffset) - group.last.baseOffset <= Int.MaxValue) {
group = segs.head :: group // 追加日志分段到组中
logSize += segs.head.size
indexSize += segs.head.offsetIndex.sizeInBytes
timeIndexSize += segs.head.timeIndex.sizeInBytes
segs = segs.tail
}
grouped ::= group.reverse
}
grouped.reverse
}
之后,对每个分组进行清理压缩,每个分组都会生成一个新的日志分段,并替代组中旧的多个分段。这里调用cleanSegments方法。清理每个分段时,若满足下面的条件,则会删除消息:
- 消息偏移量比映射表中的低
- 消息是一个删除点(墓碑标记)
private[log] def cleanSegments(log: Log,
segments: Seq[LogSegment],
map: OffsetMap,
deleteHorizonMs: Long,
stats: CleanerStats,
transactionMetadata: CleanedTransactionMetadata): Unit = {
// 创建一个新分段
val cleaned = LogCleaner.createNewCleanedSegment(log, segments.head.baseOffset)
transactionMetadata.cleanedIndex = Some(cleaned.txnIndex)
try {
val iter = segments.iterator
var currentSegmentOpt: Option[LogSegment] = Some(iter.next())
val lastOffsetOfActiveProducers = log.lastRecordsOfActiveProducers
// 遍历分组中的每个日志分段,将其清理到新的日志分段中
// 由于有映射,所以只需要追加即可
while (currentSegmentOpt.isDefined) {
val currentSegment = currentSegmentOpt.get
val nextSegmentOpt = if (iter.hasNext) Some(iter.next()) else None
val startOffset = currentSegment.baseOffset
val upperBoundOffset = nextSegmentOpt.map(_.baseOffset).getOrElse(map.latestOffset + 1)
val abortedTransactions = log.collectAbortedTransactions(startOffset, upperBoundOffset)
transactionMetadata.addAbortedTransactions(abortedTransactions)
val retainDeletesAndTxnMarkers = currentSegment.lastModified > deleteHorizonMs
try {
// 这里执行清理(压缩)
cleanInto(log.topicPartition, currentSegment.log, cleaned, map, retainDeletesAndTxnMarkers, log.config.maxMessageSize, transactionMetadata, lastOffsetOfActiveProducers, stats)
} catch {
// ...
}
currentSegmentOpt = nextSegmentOpt
}
// 触发回调,这里是非活跃的(本来就是非活跃的)
cleaned.onBecomeInactiveSegment()
// 刷盘
cleaned.flush()
// 更新最近更新时间为组中最后一个分段的更新时间
val modified = segments.last.lastModified
cleaned.lastModified = modified
// 用新的压缩过的分段替换旧日志分段
log.replaceSegments(List(cleaned), segments)
} catch {
// ...
}
}
上面核心是cleanInto,如下所述,它会将分段的信息读到读缓存中,然后遍历消息并过滤,然后写到写缓存中,之后刷盘。而消息过滤后,依旧有效的条件为下列之一:
- 消息偏移大于映射中的最大偏移量(可包含没有键的消息)
- 消息必须有键且
- 消息的偏移不小于映射中的偏移
- 消息不能是“删除点”(墓碑标记),且已经过期
private[log] def cleanInto(topicPartition: TopicPartition,
sourceRecords: FileRecords,
dest: LogSegment,
map: OffsetMap,
retainDeletesAndTxnMarkers: Boolean,
maxLogMessageSize: Int,
transactionMetadata: CleanedTransactionMetadata,
lastRecordsOfActiveProducers: Map[Long, LastRecord],
stats: CleanerStats): Unit = {
val logCleanerFilter: RecordFilter = new RecordFilter {
var discardBatchRecords: Boolean = _
// ...
override def shouldRetainRecord(batch: RecordBatch, record: Record): Boolean = {
if (discardBatchRecords)
false
else
// 消息过滤的条件
Cleaner.this.shouldRetainRecord(map, retainDeletesAndTxnMarkers, batch, record, stats)
}
}
var position = 0
// 扫描分段中的记录
while (position < sourceRecords.sizeInBytes) {
checkDone(topicPartition)
readBuffer.clear()
writeBuffer.clear()
// 先将消息加载到读缓存中
sourceRecords.readInto(readBuffer, position)
val records = MemoryRecords.readableRecords(readBuffer)
throttler.maybeThrottle(records.sizeInBytes)
// 根据规则过滤记录,得到压缩后的记录
val result = records.filterTo(topicPartition, logCleanerFilter, writeBuffer, maxLogMessageSize, decompressionBufferSupplier)
stats.readMessages(result.messagesRead, result.bytesRead)
stats.recopyMessages(result.messagesRetained, result.bytesRetained)
position += result.bytesRead
val outputBuffer = result.outputBuffer
// 将压缩后的记录写到写缓存中,等待刷盘
if (outputBuffer.position() > 0) {
outputBuffer.flip()
val retained = MemoryRecords.readableRecords(outputBuffer)
dest.append(largestOffset = result.maxOffset,
largestTimestamp = result.maxTimestamp,
shallowOffsetOfMaxTimestamp = result.shallowOffsetOfMaxTimestamp,
records = retained)
throttler.maybeThrottle(outputBuffer.limit())
}
if (readBuffer.limit() > 0 && result.bytesRead == 0)
growBuffersOrFail(sourceRecords, position, maxLogMessageSize, records)
}
restoreBuffers()
}
// 过滤消息的条件
private def shouldRetainRecord(map: kafka.log.OffsetMap,
retainDeletes: Boolean,
batch: RecordBatch,
record: Record,
stats: CleanerStats): Boolean = {
// 1. 若消息偏移大于映射中的最大偏移,则保留消息
val pastLatestOffset = record.offset > map.latestOffset
if (pastLatestOffset)
return true
if (record.hasKey) {
val key = record.key
val foundOffset = map.get(key) // 获取映射中的最大偏移
// 要满足:
// 1. 消息必须有键
// 2. 消息的偏移不小于映射中的偏移
// 3. 消息不能是“删除点”(墓碑标记),且已经过期
val latestOffsetForKey = record.offset() >= foundOffset
val isRetainedValue = record.hasValue || retainDeletes // hasValue为true表示不是墓碑标记
latestOffsetForKey && isRetainedValue
} else {
stats.invalidMessage()
false
}
}
本文主要整理了Kafka日志的数据、索引的读写、管理和清理/压缩:
- 日志数据项的格式随版本演进有很大的变化,目前的版本上每条消息会被塞入一个
RecordBatch中 - 日志写会创建数据文件、索引文件,并配有检查点文件供恢复
- 数据文件使用
FileChannel,按照偏移量有序排列 - 索引文件使用
mmap,依旧按偏移量有序排列,且是稀疏索引(不为所有消息创建索引) - 当数据文件、索引文件满,或者时间到期后,会滚动创建新分段
- 数据文件使用
- 日志读基本思路是根据偏移量进行二分法+顺序读:
- 先二分找分段,再二分找索引,得到消息的位置,最后返回消息集的视图,返回时顺序读取
- 返回数据时,数据拷贝底层采用零拷贝,即
Channel#transferTo
- 日志管理包含:
- 检查点管理
- 定时清理日志
- 日志清理包含2种策略
- 删除:直接删除旧分段
- 压缩:保留键的最新消息,将未压缩的旧分段合并成新的压缩分段,压缩线程会根据“清理点”,将日志分成日志头部和日志尾部
Related Issues not found
Please contact @keys961 to initialize the comment
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK