

携程酒店搜索引擎AWS上云实践
source link: https://www.51cto.com/article/706584.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者简介:宮娴,携程高级后端开发工程师;Spike,携程高级后端开发专家。
随着携程国际化业务的快速推进,搜索引擎作为用户体验中至关重要的一环,上云变得志在必行。本文主要分享酒店搜索引擎迁移AWS的探索与实践过程,内容将涵盖一个HTTP请求的全链路处理过程:包括从APP发出请求到网关,再到内网错综复杂的微服务,最后到所依赖的各种持久化存储。
一、微服务架构带来的挑战
这次上云的是爆款业务,用户直观的感受是点击TRIP APP的Hotel搜索页的Hotel Staycation Deals。
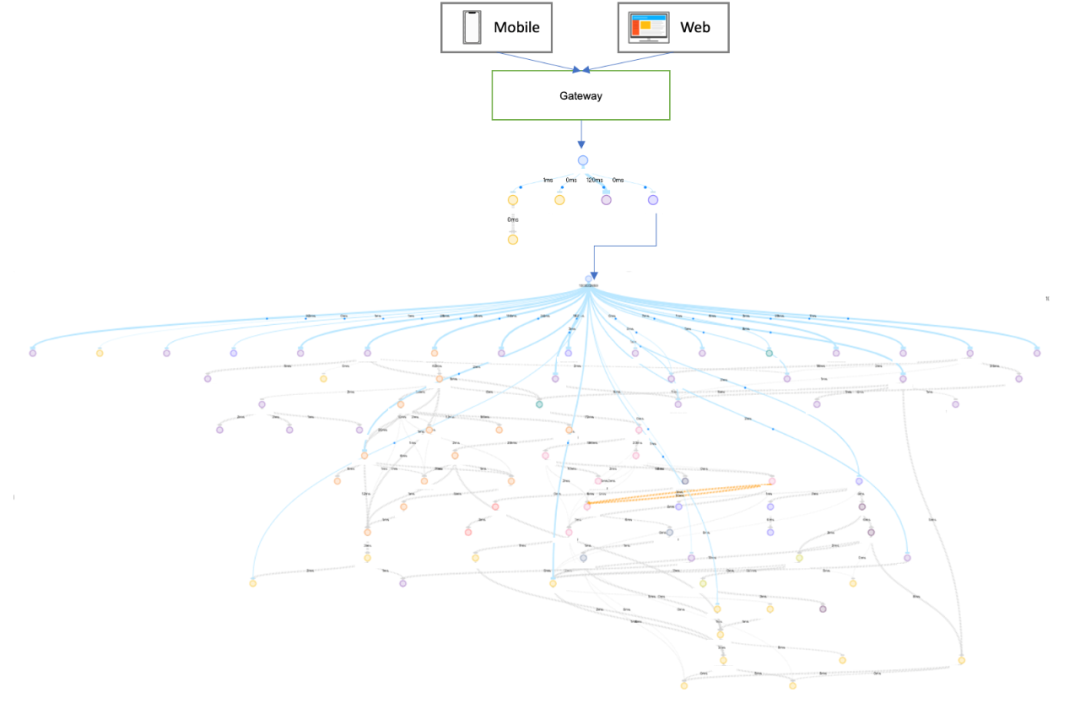
携程采用主流的微服务架构,看似简单的一个搜索功能,通过BAT调用链的监控,实则底下牵涉到上百个应用。BAT是携程对开源CAT的改进版,下图是爆款应用在BAT中的整个调用链:(如果想通过CAT整理出这个关系,是非常耗时的。因为CAT的UI只能显示一个应用依赖的下游一级应用,需要用户逐个手工遍历)
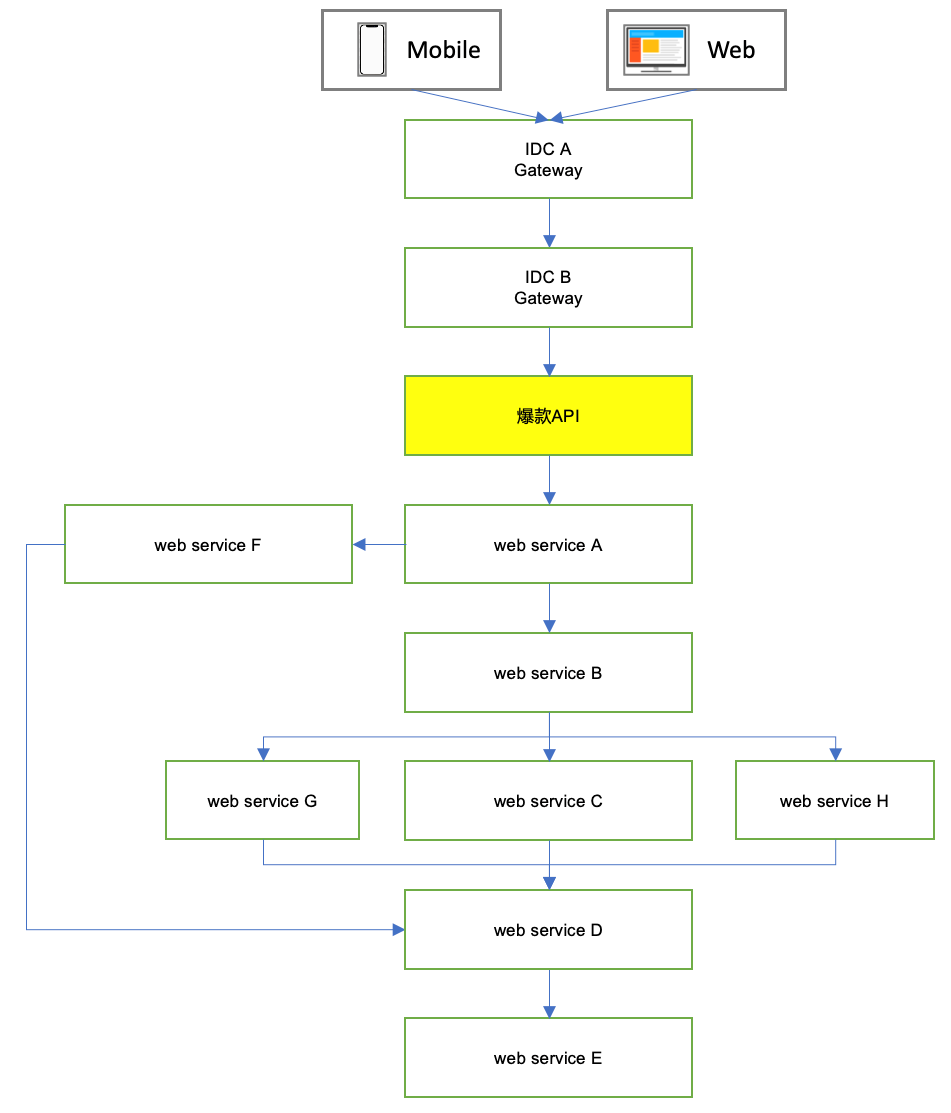
原封不动地把所有依赖应用都迁移至云,无论从开发成本,还是从硬件成本考量,都不太合理。侧面也反映出微服务架构在迁移时,不得不面对的挑战。虽然入口应用依赖了上百个下游应用,但是通常一个应用会包含多个API,而爆款业务经过调研,实际只使用了一个API。所以是否可以只部署一个API来落地迁移呢?
感谢BAT能够支持API维度的依赖查询(CAT只支持应用维度)。调研后,爆款API实际依赖的应用数为仅为八个,曙光咋现。
下一步便是部署。记得几年前在使用AWS时,使用命令行发布。当时有些顾虑权限问题,一条命令打错,可能拉挂一个集群。同时每个云厂商都会有一套自己的发布系统,学习成本也不可忽略。值得庆幸是携程自己开源的发布系统TARS已经与AWS、阿里等云发布打通,现在对于我们而言,无论是部署什么云,都使用统一的一套UI界面。
成功部署9个应用之后,我们遇到了新问题:
1)目前携程GATEWAY只能按照服务的维度转发流量,而无法基于API转发。换言之,当流量从AWS的IDCA进入GATEWAY时,无法支持只转发爆款API到IDC A,其余API转发到IDC B。
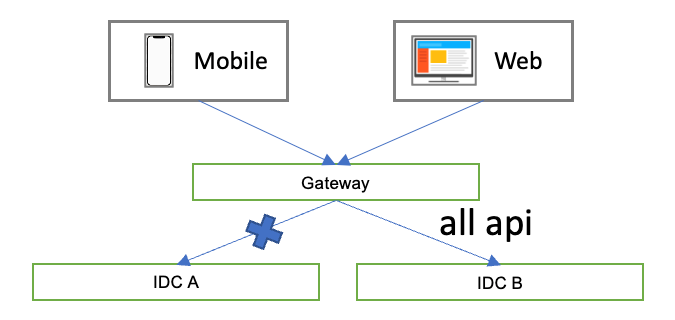
2)应用本身点火时会依赖十多个Redis、MySQL以及其他服务,但是AWS IDC之间的存储由于安全问题,是无法直接相互访问的,最终导致应用启动失败。当然我们也可以请各个框架组件排期支持点火动态配置,根据当前IDC的配置,判断哪些组件需要点火。但是这无疑会让框架和应用本身都变得很笨重,合理性值得探讨。反之如果把这些存储依赖在每个IDC都重复部署一次,势必会导致硬件和开发成本的浪费。
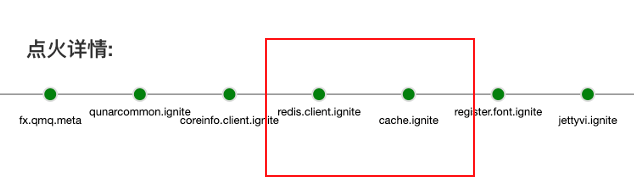
介于以上两个问题,原先维护一个代码仓库,同时发布多个IDC的架构变得不可行。那提取爆款API到一个单独的应用是否可行?试想一下,提取后,业务核心业务代码将会分布在多个应用、多个仓库。是否可以每个IDC都独立一套代码?但这会导致日后的日常开发维护重复且易错。
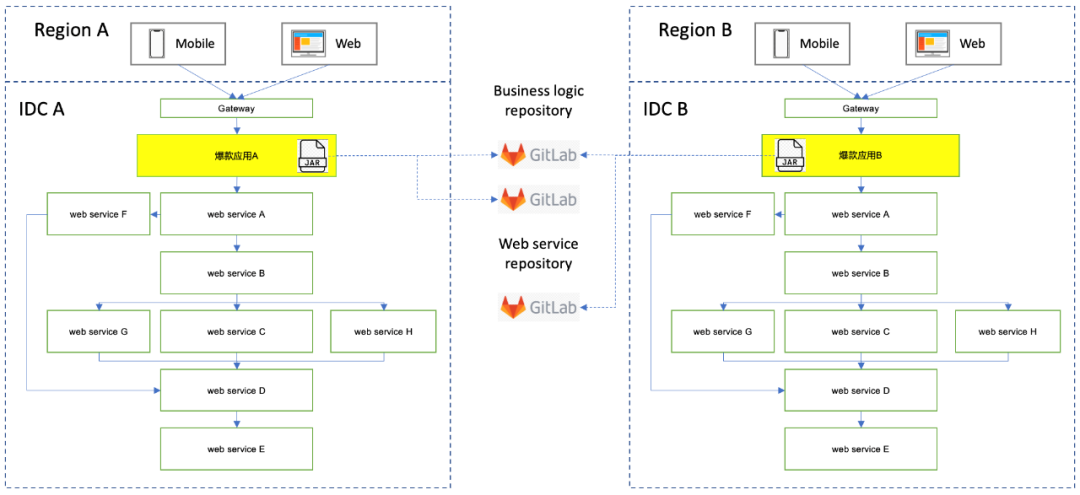
所以我们尝试把核心业务逻辑提取到一个单独的JAR,为各个IDC单独创建一个代码仓库。新建的应用只是一个web service的壳,内部访问业务的JAR。如此一来,代码不再重复,应用的责任也得到了抽象与分离。
但这又给开发带来一个问题:每次开发新功能,先要在业务jar的仓库完成编写,然后再通过web service应用引用最新的jar进行调试。每改一次代码,都要重新生成一个jar,上传到中央maven仓库,然后再升级POM引用版本下载到本地,这样开发效率势必低效。不过值得庆幸的是,携程现有的单元测试率都强制80%以上,所以这会反向推动开发编写出质量更高的单元测试,同时降低和webservice进行集成测试时的开发成本。方案不完美,但也算是一个权衡。
二、云上数据的持久化
新应用抽取后,虽然避开了点火中无关Redis和MySQL的依赖,但并没有避开爆款API本身依赖的2个Redis和1个MySQL。一种方案是直接通过在IDC之间架设专线,通常Redis响应都是几毫秒,而网络延迟都具有不稳定的特点,极端可能要几百毫秒,所以专线的网络延迟对实时业务来说是不可接受的。退一步,即使部分业务能够接受网络延迟,整个携程业务都以这种方法进行数据访问,这条专线未来会变成一个瓶颈。
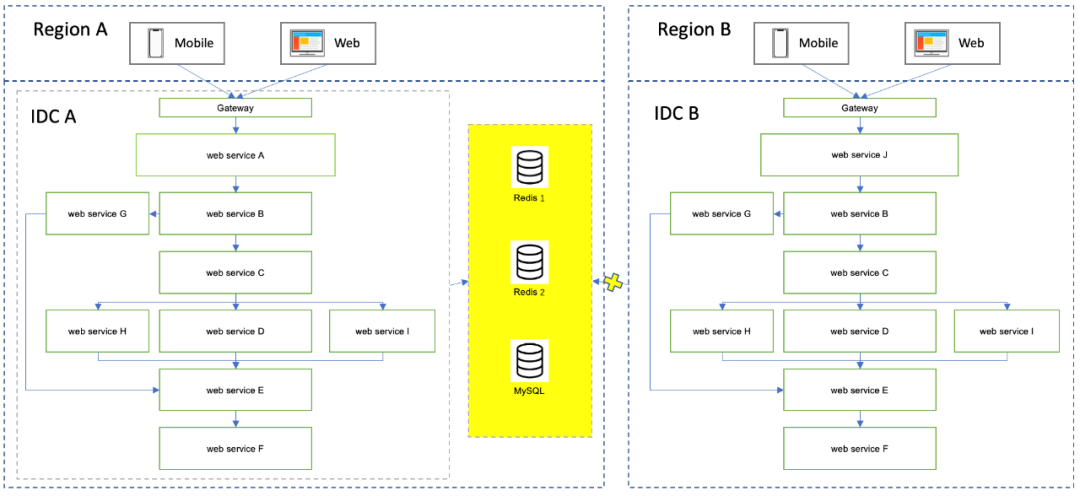
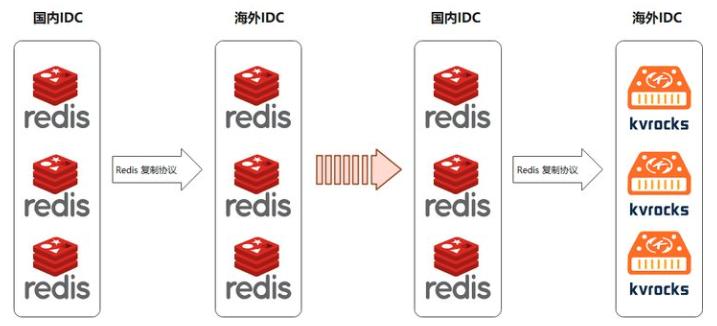
所以我们尝试把爆款依赖的Redis和MySQL部署到多个AWS IDC。部署过程中,我们用携程自研的持久化KV存储Trocks替代了Redis,达到降低了硬件成本的目标。
应用虽然点火成功了,接下来就是数据同步的问题:是否需要同步?如何同步?单向复制?双向复制?延迟容忍度如何?
爆款依赖2个Redis。1个Redis负责基于http请求的cache,所以不需要同步,框架代码也无需做改变,默认访问IDC本地机房Redis。换言之,IDC A的应用读写IDCA的Redis实例,IDC B的应用读写IDC B的Redis实例。
另外1个Redis和MySQL供搜索引擎使用。业务特点只读不写,实时同步大量从其他数据源的数据,所以只需单向同步,并且对延迟性要求低。存储的最终架构如下:
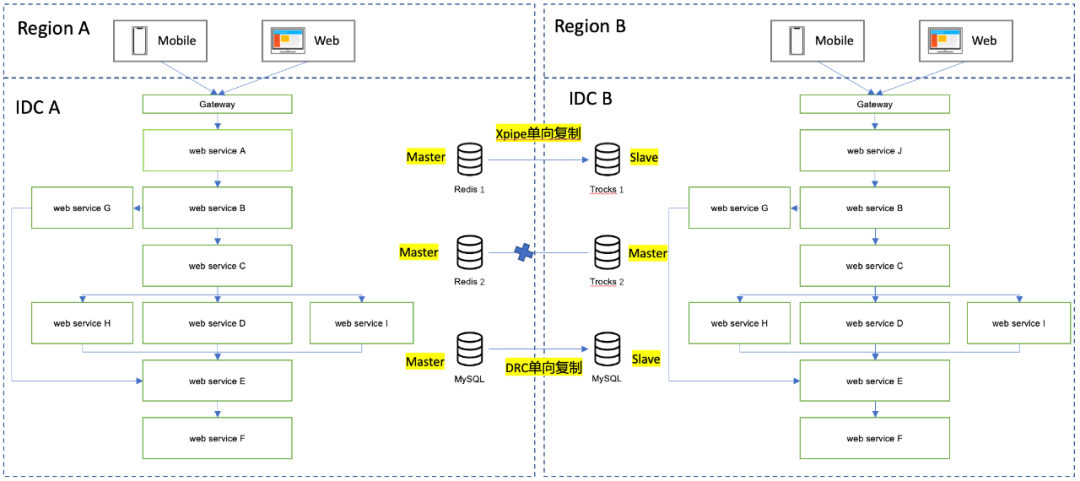
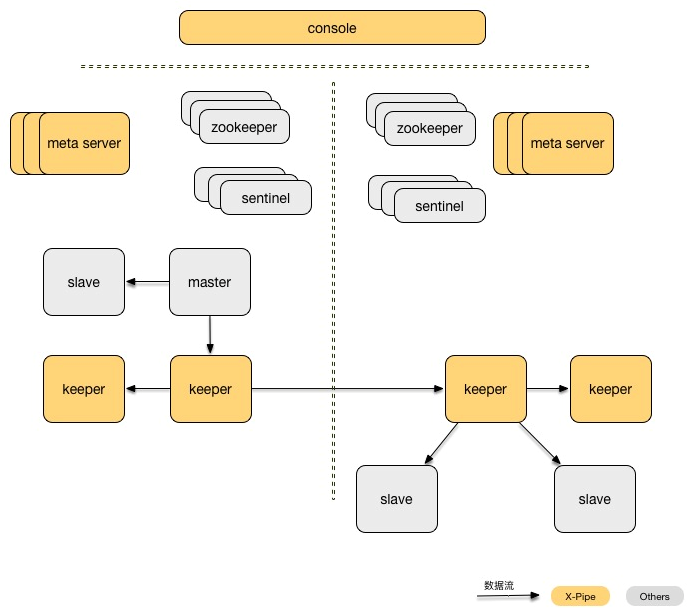
Redis的单向复制分发使用的是携程自研开源的XPipe。
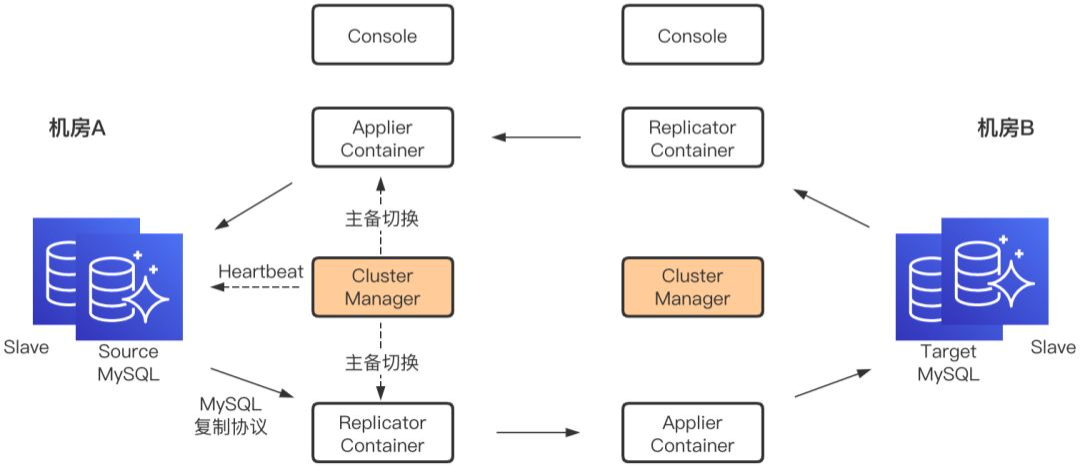
MySQL的单向复制分发技术使用的是携程自研的DRC。我们这个项目只用到了它的单向复制能力,其实它也支持双向复制。
全部部署完成后,应用能够正常启动与工作了。复制分发的延迟一般都在几百毫秒,极端会到秒级,符合预期。
三、云上文件的存储与共享
在爆款API的核心搜索引擎中,用到了读写本地文件的技术。应用会在IDC内网传输共享这些文件,而这些文件有些很大,可达10个G。那不同的机房如何共享呢?一种方案是把这些应用在各个AWS IDC都部署一次,但是迁移上去后,背后依赖的数据库是否需要部署,甚至是数据库后面庞大的Hadoop集群也一并重复部署一次?
基于KISS原则,我们首先尝试让AWS IDC A的服务通过专线直接访问IDC B的文件。但是由于网络不知名的原因,文件可以传输,却始终无法成功。但是即使成功,仍然带来很多隐患,例如:如此大的文件会瞬间把专线带宽长期占满,而真正有实时需求的通讯会卡顿受阻。最后我们尝试通过AWS S3的服务在不同IDC之间共享文件,结果成功了,性能也满足业务要求。
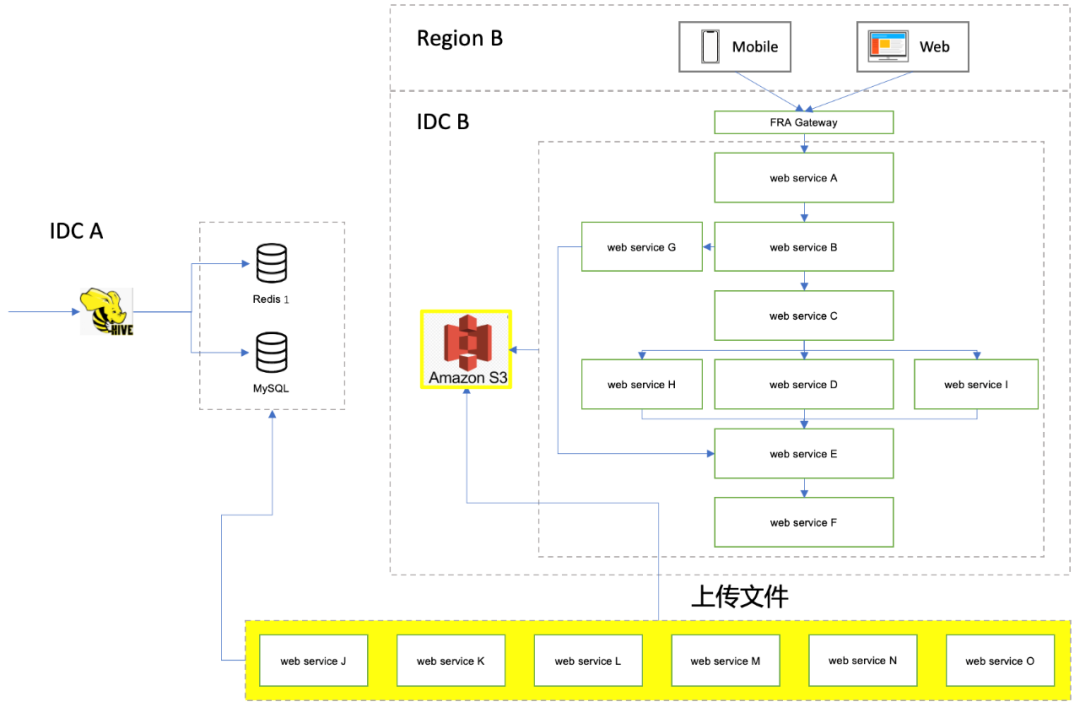
从方案的选择上来看,AWS S3的使用场景是值得商讨的。用云上产品一般都会有一个顾虑,就是太过依赖某种云的一个具体产品,当后期如果要换成其他云时,会有大量的迁移成本。例如AWS的S3 API就是定制化的:

甚至像携程会同时使用多种云时,那就意味着会有多套代码的维护成本。我们现在的解决方案就是公司内部统一出一个JAR,兼容各种云文件存储的API,使用时只要配置相关云的安全密文即可。
受益于前期携程技术平台部门为上云做的大量基础设施研发,降低了业务部门上云的门槛。爆款业务的上云只是冰山一角,随着越来越多业务的出海,会有更多的挑战等待着我们。希望这篇文章能够为有迁移云计划的团队开拓思路。
有了这次上云经历之后,现在每次在设计新架构的时候,我们都会不假思索问自己几个问题:这个架构设计未来有上云的需求么?是否方便上云?是否方便跨云部署?
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK