

这个自蒸馏新框架新SOTA,降低了训练成本,无需修改网络
source link: https://www.51cto.com/article/706052.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

深度学习促进人工智能(AI)领域不断发展,实现了许多技术突破。与此同时,如何在有限硬件资源下挖掘模型潜能、提升部署模型的准确率成为了学界和业界的研究热点。其中,知识蒸馏作为一种模型压缩和增强的方法, 将泛化能力更强的「大网络模型」蕴含的知识「蒸馏」到「小网络模型」上,来提高小模型精度,广泛地应用于 AI 领域的全监督、半监督、自监督、域迁移等各个方向。
近日, OPPO 研究院联合上海交通大学将视角聚焦到知识蒸馏的范式本身,提出了新的自蒸馏框架:DLB(Self-Distillation from Last Mini-Batch),模型无需额外的网络架构修改,对标签噪声具有鲁棒性,并大幅节约训练的空间复杂度。此外,在三个基准数据的实验中,模型达到了 SOTA 性能。相关论文「Self-Distillation from the Last Mini-Batch for Consistency Regularization」已被 CVPR 2022 收录。

论文链接:https://arxiv.org/pdf/2203.16172.pdf
DLB 自蒸馏框架
如何减少蒸馏计算复杂度?
知识蒸馏通常可以划分为三类,即离线蒸馏、在线蒸馏和自蒸馏。其中,自蒸馏具有训练轻量、知识迁移效率高的特点,最近受到更多研究者的重视。
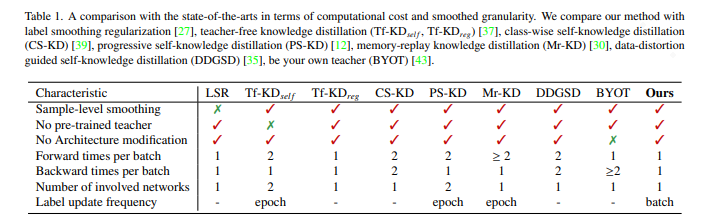
图 1:本文方法与其他自蒸馏方法的比较
但是传统的自蒸馏,例如 Be Your Own Teacher,在模型训练过程中需要对模型结构进行修改。除此以外,训练成本高、计算冗余且效率低下也是自蒸馏需要攻克的难题。
为了解决上述难题,让模型更好地部署到手机等终端设备中,OPPO 研究院和上海交通大学的研究员们提出了 DLB 自蒸馏框架。利用训练时前后 Batch 预测结果的一致性,在无需对模型进行网络结构修改的前提下,就能降低训练复杂度,增强模型泛化能力。
1. 本文的任务
提出更加轻量的自蒸馏方式,降低训练的计算复杂度,提高模型准确率和泛化性。
2. 本文创新与贡献
- 提出 DLB,通过保存与下个 Batch 部分样本重叠的软目标(soft targets)进行自蒸馏。节省计算内存,并且简化训练流程。
- 让训练样本的每次前向过程都与一次反向传播过程相关联,从而提升学习效率。
- 实验分析了 DLB 训练方法的动态影响,发现其正则化效果来源于即时生效的平滑标签带来的训练一致性,为自蒸馏的理论研究提供了实验基础。
DLB 自蒸馏框架训练机制
DLB 在训练阶段的每个 iteration 中,目标网络扮演着「教师」和「学生」的双重角色。其中,教师的作用是生成下一个 iteration 的软目标进行正则化;学生的作用是从前一个 iteration 平滑的标签中蒸馏,并最小化监督学习目标。
数据集定义为
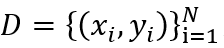
,包含 n 个样本的 Batch 定义为:
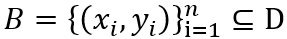
,以图像分类为例,图片先进行数据增强,然后将其输入神经网络,优化预测输出与真值间的交叉熵损失:
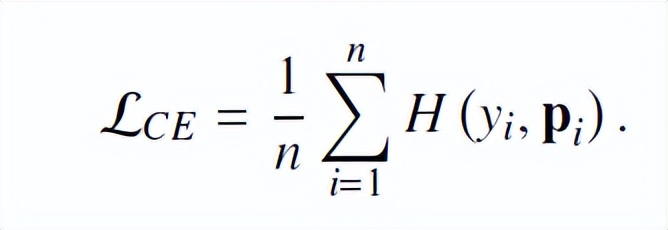
上式中 p_i 的表达式如下:
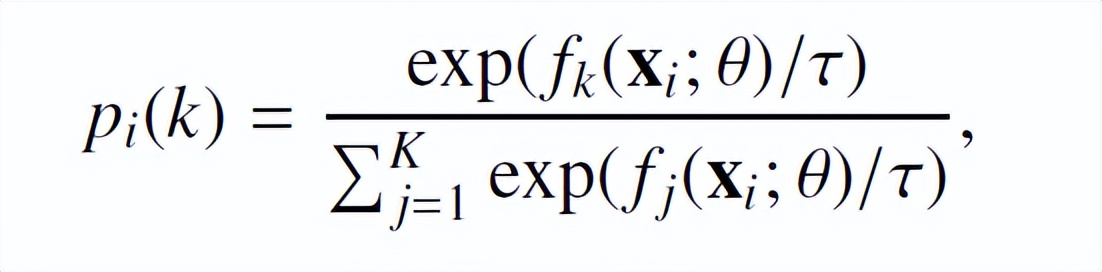
θ为网络参数,K 表示分类类别数,τ表示温度。
为了提高泛化能力,传统的 vanilla 知识蒸馏通过额外优化的 KL 散度损失来迁移预先训练好的 teacher 网络的知识,即:
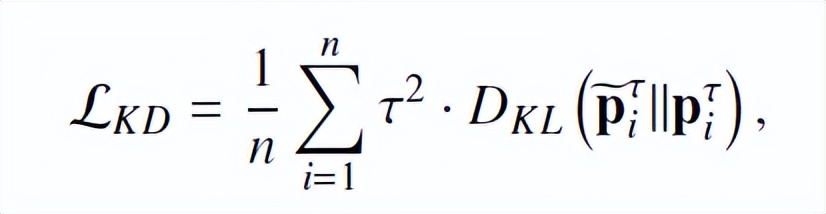
不同于以往采用预先训练 teacher 模型的方式生成(P_i^τ ) ̃,DLB 采用训练中前一个 Batch 蕴含的信息生成(P_i^τ ) ̃,并将其作为正则化的即时平滑标签。
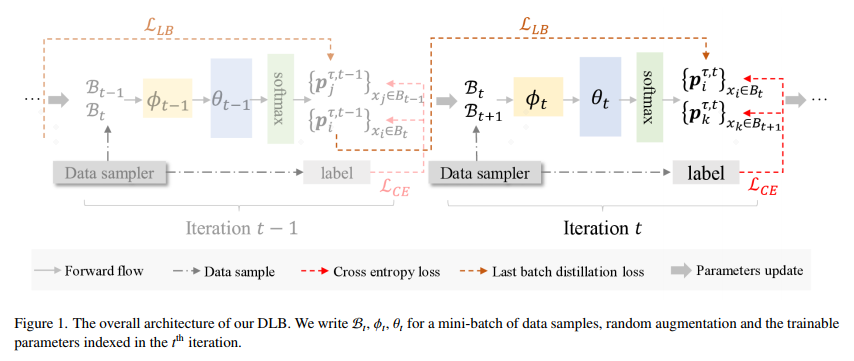
图 2:DLB 训练方式示意图
如图 2 所示,数据样本在第 t 次迭代时的定义为
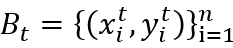
,神经网络的参数为θ_t。
B_t 和 B_(t-1)是通过使用数据采样器获得,在前向过程后计算 L_CE。每个小批次的一半限制为与上一个 iteration 一致,其余一半与下一个 iteration 一致。之后,前半部分小批次利用上一个 iteration 中生成的动态软目标进行学习。即
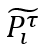
由 t-1 次迭代的软标签(soften labels)
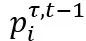
生成。因此,引入的正则化损失公式如下:
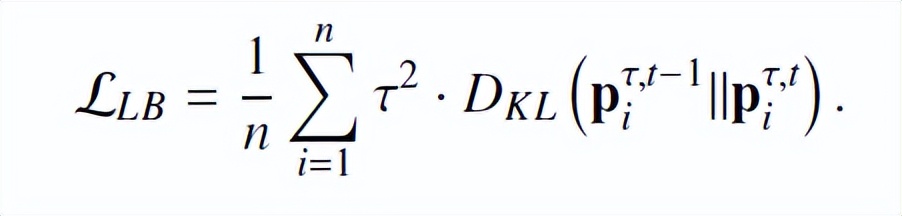
存储平滑标签只需要很少的额外内存成本,所以带来的额外计算成本很低。整体损失函数由下式表示:
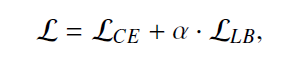
综上,DLB 算法整体的训练的伪代码如下所示:

研究员们采用三个图像分类基准数据集评估性能,包括 CIFAR-10、CIFAR-100TinyImageNet。实验结果都达到了最佳性能,如下表所示:
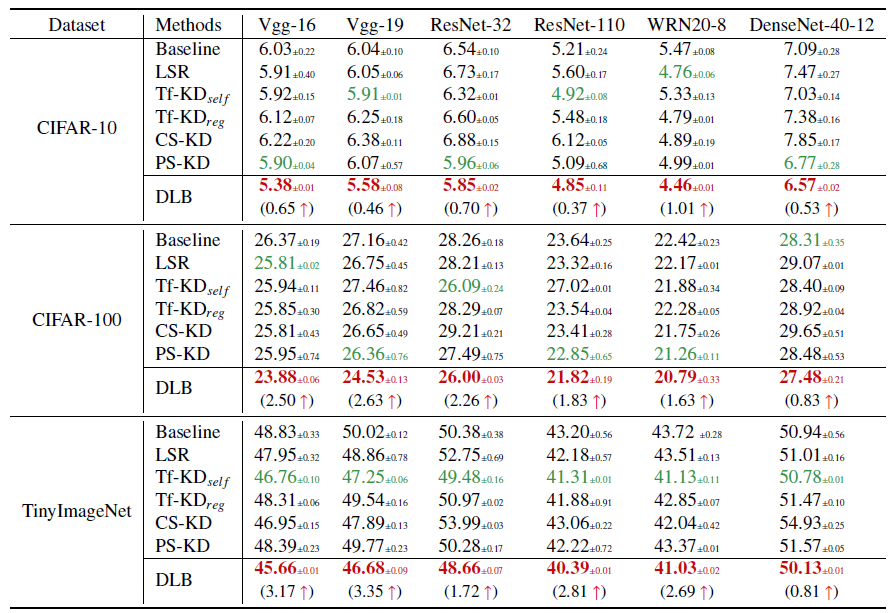
具体而言,在平均错误率层面, DLB 在 CIAFR-100 改进幅度为 0.83% 至 2.50%,在 CIFAR-10 上为 0.37% 至 1.01%,在 TinyImageNet 上为 0.81% 至 3.17。值得一提的是,DLB 的表现明显优于 Tf-KD 和 PS-KD,这证明了 DLB 在模型泛化提升上的优势。
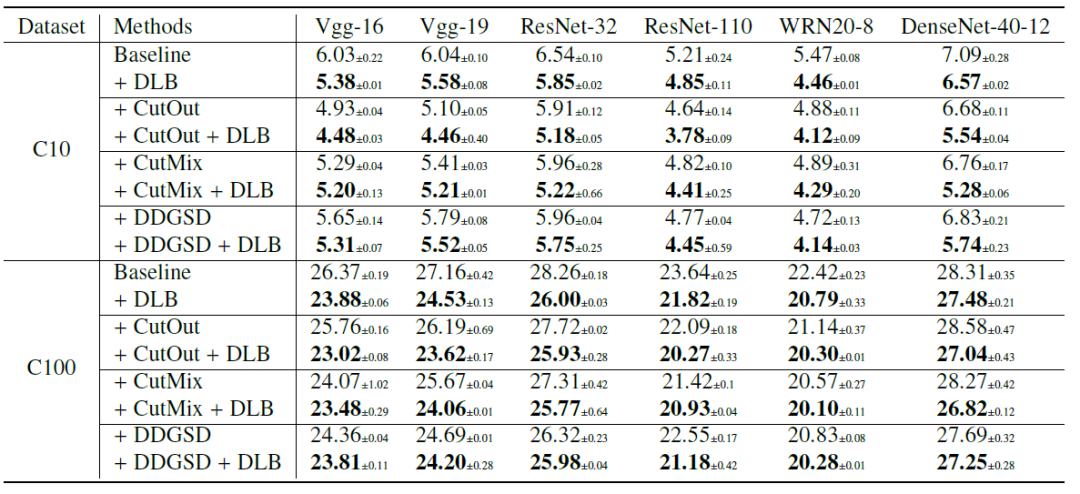
为了评估 DLB 与基于数据增强正则化方法的兼容性,研究员在 CIFAR-10 和 CIFAR-100 上将 DLB 与 CutMix、CutOut 和 DDGSD 相结合。如下所示,实验表明通过结合 DLB 和基于增强的正则化,可以实现额外的性能增益。
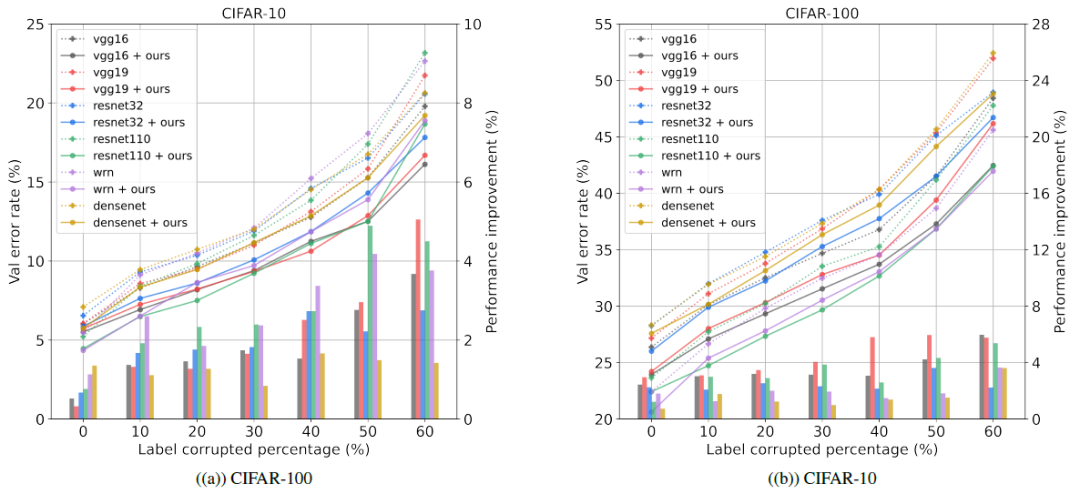
为了证明鲁棒性,研究员在训练之前向 CIFAR-100、CIFAR-10 随机注入标签噪声,实验结果如下图所示,DLB 可以有效地抵抗标签噪声并提高整体性能。
本文提出了一种基于自蒸馏思想的深度学习训练策略,将自蒸馏思想融入到模型训练过程中,对传统知识蒸馏进行改进,无需额外预先训练 teacher 的过程。通过在三个基准数据集上进行实验,多维度论证了 DLB 训练策略的有效性与普适性。
当下,深度学习网络模型结构复杂度不断提升,使用有限硬件资源开发和部署 AI 模型成为新的科研问题。在本文中,研究员设计的 DLB 训练策略,在某种程度上解决了「不增加模型复杂度,提高模型准确率」这一业界难题。
Recommend
-
20
-
31
作者 | Qingyong Hu 编辑 | Tokai 本文对牛...
-
17
在技术领域,尤其是 前端 领域,新 框架 出现的频率令人咋舌。新框架问世之初,...
-
18
本文介绍的是CVPR2020入选论文《HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection》,作者来自 元戎启行...
-
15
对于中国商业环境来说,有竞争不是坏事,但竞争需有度,高级的竞争能带来多赢局面,从提升自我去打赢商业战争才值得赞扬。同行竞争更不是坏事,你来我往之间反而能让所处领域产品更加完美、用户体现更加好。 文/三三 出品/新摘商...
-
7
Teacher模型线上授课,蒸馏训练速度提升2.3倍 - 飞桨PaddlePaddle的个人空间 - OSCHINA - 中文开源技术交流社区 ...
-
4
反思工业革命:究竟是降低了成本,还是提高了质量?神译局10分钟前技术推动效率。 神译局是36氪旗下编译团队,关注科技、...
-
10
热门评论 30条 个人觉得,国内某些基建可以暂缓一下,或者停一停,省下来的一些钱,可以投入国防开支中去。并不是说基建不重要,但某一些的基建,至少可以延后几年再搞也不迟。比如本人所在的城市,一条城郊...
-
6
Apache Iceber能将Amazon S3 成本降低了 90% 解道Jdon
-
4
运输成本更低了!沃尔玛向美国卖家开放SWW服务!北美电商资讯AMZ123旗下北美跨境电商新闻栏目,专注北美跨境电商热点资讯,为广大卖家提供北美跨境...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK