

途家大数据平台基于 Apache DolphinScheduler 的探索与实践
source link: https://www.infoq.cn/article/dEVYskH5gAmjTrJuCxw5
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

途家在 2019 年引入 Apache DolphinScheduler,在不久前的 Apache DolphinScheduler 2 月份的 Meetup 上,途家大数据工程师昝绪超详细介绍了途家接入 Apache DolphinScheduler 的历程,以及进行的功能改进。
本文主要包括 4 个部分。第一部分是途家的平台的现状,介绍途家的数据的流转过程,如何提供数据服务,以及 Apache DolphinScheduler 在平台中扮演的角色。第二部分,调度选型,主要介绍调度的一些特性,以及接入的过程。第三部分主要介绍我们对系统的的一些改进和功能扩展,包括功能表依赖的支持,邮件任务扩展,以及数据同步的功能,第四部分是根据业务需求新增的一些功能,如 Spark jar 包支持发布系统,调度与数据质量打通,以及表血缘展示。
途家数据平台现状
01 数据架构
首先介绍一下途家数据平台的架构以及 Apache DolphinScheduler 在数据平台扮演的角色。
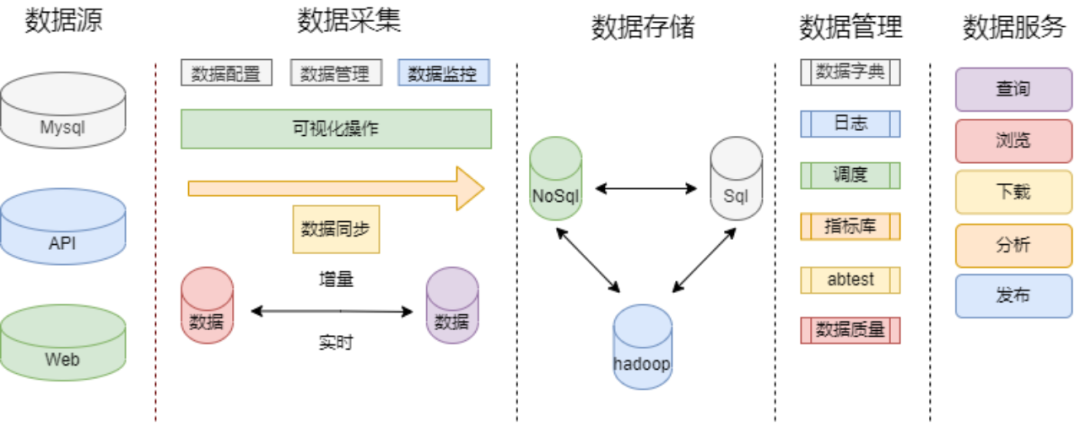
途家数据平台架构
上图为我司数据平台的架构,主要包括数据源,数据采集,数据存储,数据管理,最后提供服务。
数据源主要来源包括三个部分:业务库 MySQL API 数据同步,涉及到 Dubbo 接口、http 接口,以及 web 页面的埋点数据。
数据采集采用实时和离线同步,业务数据是基于 Canal 的增量同步,日志是 Flume,Kafka 实时收集,落到 HDFS 上。
数据存储过程,主要涉及到一些数据同步服务,数据落到 HDFS 后经过清洗加工,推送到线上提供服务。
数据管理层面,数据字典记录业务的元数据信息,模型的定义,各层级之间的映射关系,方便用户找到自己关心的数据;日志记录任务的运行日志,告警配置故障信息等。调度系统,作为大数据的一个指挥中枢,合理分配调度资源,可以更好地服务于业务。指标库记录了维度和属性,业务过程指标的规范定义,用于更好的管理和使用数据。Abtest 记录不同指标和策略对产品功能的影响;数据质量是数据分析有效性和准确性的基础。
最后是数据服务部分,主要包括数据的即席查询,报表预览,数据下载上传分析,线上业务数据支持发布等。
02 Apache DolphinScheduler 在平台的作用
下面着重介绍调度系统在平台扮演的角色。数据隧道同步,每天凌晨定时拉去增量数据。数据清洗加工后推送到线上提供服务。数据的模型的加工,界面化的配置大大提高了开发的效率。定时报表的服务,推送邮件,支持附件,正文 table 以及折线图的展示。报表推送功能,数据加工后,分析师会配置一些数据看板,每天 DataX 把计算好的数据推送到 MySQL,做报表展示。
第二部分介绍我们接入 Apache DolphinScheduler 做的一些工作。
Apache DolphinScheduler 具有很多优势,作为大数据的一个指挥中枢,系统的可靠性毋庸置疑,Apache DolphinScheduler 去中心化的设计避免了单点故障问题,以及节点出现问题,任务会自动在其他节点重启,大大提高了系统的可靠性。
此外,调度系统简单实用,减少了学习成本,提高工作效率,现在公司很多人都在用我们的调度系统,包括分析师、产品运营,开发。
调度的扩展性也很重要,随着任务量的增加,集群能及时增添资源,提供服务。应用广泛也是我们选择它的一个重要原因,它支持丰富的任务类型:Shell、MR、Spark、SQL(MySQL、PostgreSQL、Hive、SparkSQL),Python,Sub_Process,Procedure 等,支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill 任务等操作等。它的优势很多,一时说不完,大家都用起来才知道。
接下就是我们定时调度的升级。
在采用 Apache DolphinScheduler 之前,我们的调度比较混乱,有自己部署本地的 Crontab,也有人用 Oozie 做调度,还有部分是在系统做定时调度。管理起来比较混乱,没有统一的管理调度平台,时效性,和准确性得不到保障,管理任务比较麻烦,找不到任务的情况时有发生。此外,自建调度稳定性不足,没有配置依赖,数据产出没有保障,而且产品功能单一,支持的任务调度有限。
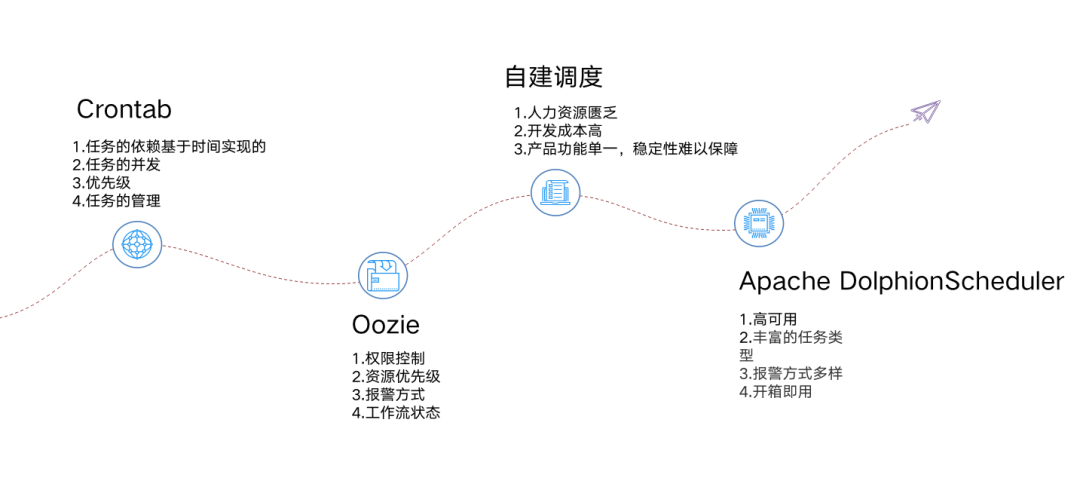
2019 年,我们引入 Apache DolphinScheduler ,到现在已经接近三年时间,使用起来非常顺手。
下面是我们迁移系统的一些数据。
我们搭建了 DS 集群 ,共 4 台实体机 ,目前单机并发支持 100 个任务调度。
算法也有专门的机器,并做了资源隔离。
Oozie 任务居多 ,主要是一些 Spark 和 Hive 任务 。还有 Crontab 上的一些脚本,一些邮件任务以及报表系统的定时任务。
基于 DS 的调度系统构建
在此之前,我们也对系统做过优化,如支持表级别的依赖,邮件功能的扩展等。接入 Apache DolphinScheduler 后,我们在其基础之上进行了调度系统构建,以能更好地提供服务。
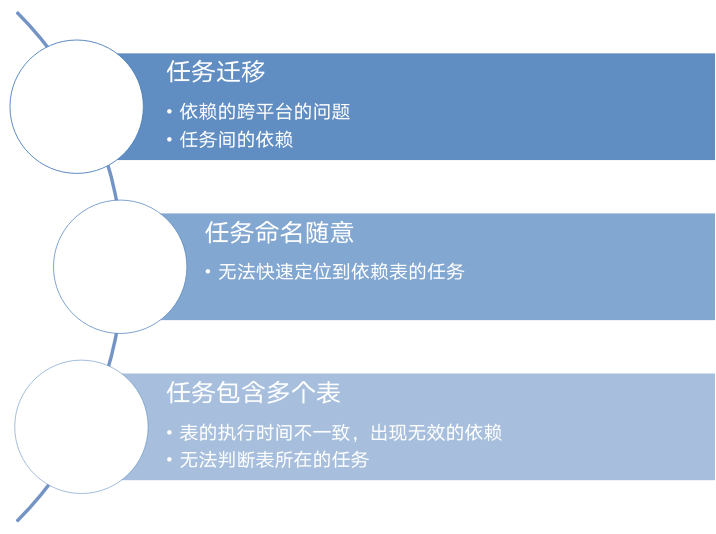
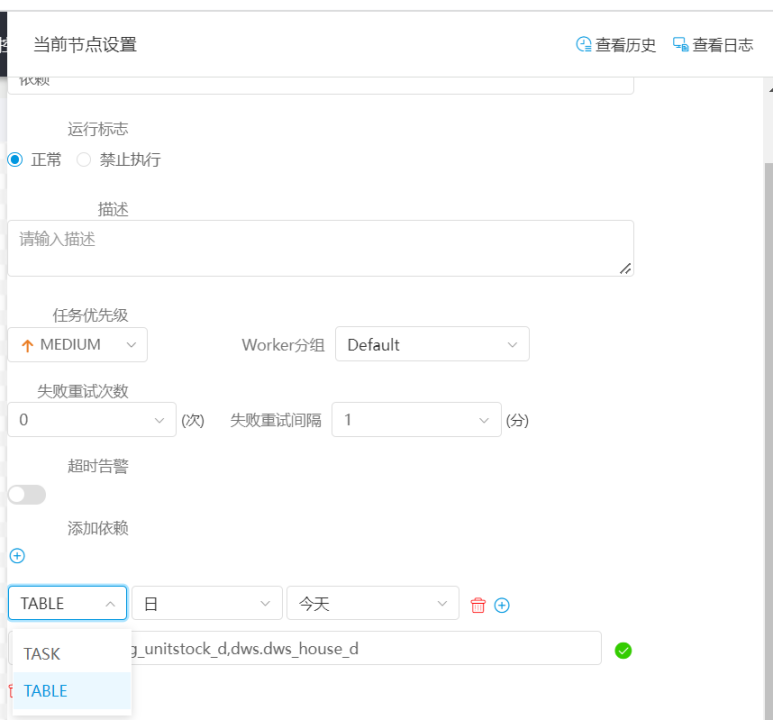
第一. 支持表依赖的同步,当时考虑到任务迁移,会存在并行的情况,任务一时没法全部同步,需要表任务运行成功的标记,于是我们开发了一版功能,解决了任务迁移中的依赖问题。然而,每个人的命名风格不太一样,导致配置依赖的时候很难定位到表的任务,我们也无法识别任务里面包含哪些表,无法判断表所在的任务,这给我们使用造成不小的麻烦。
第二. 邮件任务支持多 table。 调度里面自带邮件推送功能,但仅支持单个 table ,随着业务要求越来越多,我们需要配置多个 table 和多个 sheet,要求正文和附件的展示的的条数不一样,需要配置,另外还需要支持折线图的功能,丰富正文页面。此外,用户还希望能在正文或者每个表格下面加注释,进行指标的说明等。我们使用 Spark jar 包实现了邮件推送功能,支持异常预警、表依赖缺失等。

第三. 支持丰富的数据源同步。 由于在数据传输方面存在一些问题,在以前迁移的过程中,我们需要修改大量的配置代码,编译打包上传,过程繁琐,经常出现漏改,错该,导致线上故障,数据源不统一,测试数据和线上数据无法分开;在开发效率方面,代码有大量重复的地方,缺少统一的配置工具,参数配置不合理,导致 MySQL 压力大,存在宕机的风险;数据传输后,没有重复值校验,数据量较大的时候,全量更新,导致 MySQL 压力比较大。MySQL 传输存在单点故障问题,任务延迟影响线上服务。
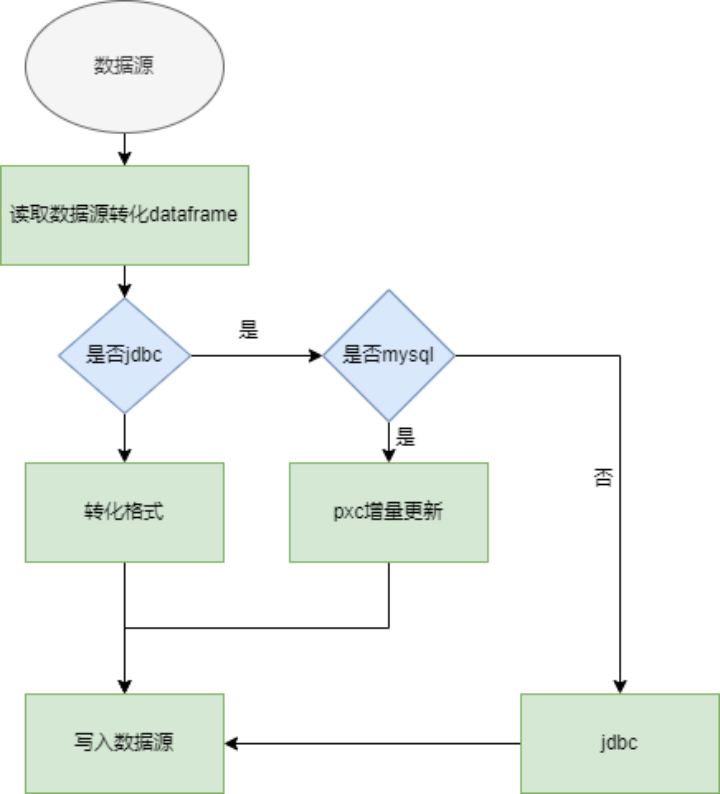

我们在此过程中简化了数据开发的流程,使得 MySQL 支持 pxc/mha 的高可用,提升了数据同步的效率。
我们支持输入的数据源支持关系型数据库,支持 FTP 同步,Spark 作为计算引擎,输出的数据源支持各种关系型数据库,以及消息中间件 Kafka、MQ 和 Redis。
接下来讲一下我们实现的过程。
我们对 Apache DolphinScheduler 的数据源做了扩展,支持 kafka mq 和 namespace 的扩展,MySQL 同步之前首先在本地计算一个增量,把增量数据同步到 MySQL,Spark 也支持了 MySQL pxc/qmha 的高可用。另外,在推送 MQ 和 Redis 时会有 qps 的限制,我们根据数据量控制 Spark 的分区数和并发量。
第四部分主要是对系统新增的一些功能,来完善系统。主要包含以下三点:
Spark 支持发布系统
数据质量打通
数据血缘的展示
01Spark 任务支持发布系统
由于我们平时的调度 80%以上都是 Spark jar 包任务,但任务的发布流程缺少规范,代码修改随意,没有完整的流程规范,各自维护一套代码。这就导致代码不一致的情况时有发生,严重时还会造成线上问题。
这要求我们完善任务的发布流程。我们主要使用发布系统,Jenkens 打包功能,编译打包后生成 btag,在测试完成后再发布生成 rtag ,代码合并到 master 。这就避免了代码不一致的问题,也减少了 jar 包上传的步骤。在编译生成 jar 包后,系统会自动把 jar 包推送到 Apache DolphinScheduler 的资源中心,用户只需配置参数,选择 jar 包做测试发布即可。在运行 Spark 任务时,不再需要把文件拉到本地,而是直接读取 HDFS 上的 jar 包。
02 数据质量打通
数据质量是保障分析结论的有效性和准确性的基础。我们需要要完整的数据监控产出流程才能让数据更有说服力。质量平台从四个方面来保证数据准确性,完整性一致性和及时性,并支持电话、企业微信和邮件等多种报警方式来告知用户。
接下来将介绍如何将数据质量和调度系统打通。调度任务运行完成后,发送消息记录,数据质量平台消费消息,触发数据质量的规则监控 根据监控规则来阻断下游运行或者是发送告警消息等。
03 数据血缘关系展示
数据血缘是元数据管理、数据治理、数据质量的重要一环,其可以追踪数据的来源、处理、出处,为数据价值评估提供依据,描述源数据流程、表、报表、即席查询之间的流向关系,表与表的依赖关系、表与离线 ETL 任务,调度平台、计算引擎之间的依赖关系。数据仓库是构建在 Hive 之上,而 Hive 的原始数据往往来自生产 DB,也会把计算结果导出到外部存储,异构数据源的表之间是有血缘关系的。
追踪数据溯源:当数据发生异常,帮助追踪到异常发生的原因;影响面分析,追踪数据的来源,追踪数据处理过程。
评估数据价值:从数据受众、更新量级、更新频次等几个方面给数据价值的评估提供依据。
生命周期:直观地得到数据整个生命周期,为数据治理提供依据。血缘的收集过程主要是 :Spark 通过监控 Spark API 来监听 SQL 和插入的表,获取 Spark 的执行计划 ,并解析 Spark 执行计划。
作者简介:
昝绪超,途家大数据工程师 数据开发工程师,主要负责大数据平台的开发,维护和调优。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK