

Graphcore Bow IPU正式发布:性能提升40%,电源效率提升16%,无需更改代码
source link: https://server.51cto.com/article/703159.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
性能提升40%,电源效率提升16%,无需更改任何代码就能运行上一代平台上的任何应用,且价格保持不变。以上这些,就是最近Graphcore全新发布的第三代IPU所展现出来的与上一代产品相比的各项优势。命名为Bow IPU的第三代IPU,也是全球第一款基于台积电的3D Wafer-on-Wafer的处理器。

Graphcore大中华区总裁兼全球首席营收官卢涛
在Graphcore近期举办的一场线下媒体沟通会上,Graphcore大中华区总裁兼全球首席营收官卢涛详细介绍了新一代产品的各种优势。他表示,与上一代产品相比,Bow IPU不但有了非常明显的性能提升,给用户带来了更好的产品选择,并且产品发布即上市,合作伙伴已经能够买到新的产品,并将其应用到企业的各种计算场景当中。
全球首款基于台积电3D Wafer-on-Wafer的处理器
作为全球第一款基于台积电3D Wafer-on-Wafer的处理器,Bow IPU采用了台积电SoIC-WoW技术,7nm工艺制程,将两颗die叠在一起。这种3D封装的设计使得单个封装芯片中的晶体管数量超过了600亿个,具有350 TeraFLOPS的人工智能计算的性能。

根据卢涛的介绍,与上一代MK2 IPU 250 TeraFLOPS相比,Bow IPU在性能上得到了40%的提升,并且通过对供电系统进行优化,每瓦性能也有了更好的表现。在片上存储方面,与上一代MK2 IPU相比,并没有任何没有变化,仍旧是0.9 GB的容量,但是吞吐量从47.5TB/s提高到65TB/s。除此之外,处理器内核的个数、独立线程个数、接口等,与上一代的处理器相比都没有变化。

以Bow-2000为例,IPU-Machine与上一代IPU Machine:M2000(IPU-M2000)保持一致,使用了4颗Bow IPU。不同的是,上一代产品在1U刀片中能够提供1 PetaFLOPS的算力,Bow-2000则能够提供1.4 PetaFLOPS的算力。除此之外,Bow-2000 1U刀片具有3.6 GB的处理器内存储,吞吐量为260TB/s,IPU流存储多达256 GB,并具有2.8 Tbps IPU-Fabric。
卢涛表示,Bow IPU是Graphcore与台积电联合创新的产品,与上一代产品相比,能够提供更好的每瓦特性能,拥有更高的性能比,是AI计算的首选产品。
丰富的软件栈生态系统是性能提升的关键
除了在硬件上的创新之外,丰富的软件栈生态系统也是Bow IPU性能提升的关键因素。

Graphcore中国工程副总裁、AI算法科学家金琛
据Graphcore中国工程副总裁、AI算法科学家金琛介绍,在Poplar SDK中,不但有Graphcore研发的图编译器、驱动,而且还有上层的XLA backend。这些软件的加持使得Bow IPU在不同应用的性能上能够得到广泛的提升。
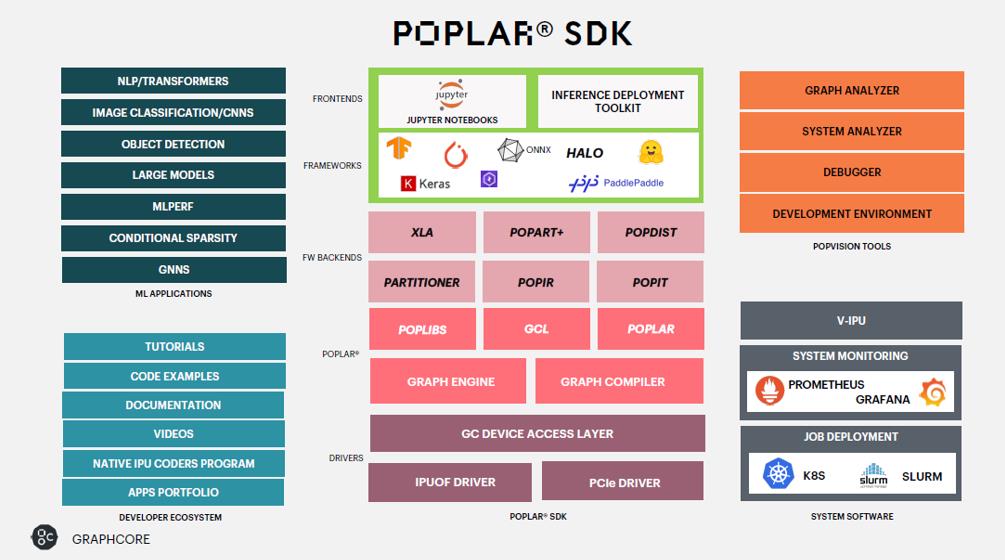
在此之上,Graphcore还提供了比较丰富的生态,例如在AI软件框架上,能够支持PyTorch、TensorFlow、HALO、PaddlePaddle,以及高层API Keras等等。在用户方面,支持Jupyter Notebook,以及Inference Deployment Toolkit等等,帮助客户实现推算一体的部署。
除此之外,Graphcore还在加速推进开发者社区的建设,并在其中提供了广泛的代码用例,以及各种文档、视频示范。
金琛表示,Graphcore在机器学习应用上提供了特别多的模型范例,覆盖不同的AI垂直领域,包含大模型、语音模型、语言模型等等的模型库还在不停进行迭代和增加。另外,在云上,Graphcore也提供了广泛的部署、监控,以及管理软件集成。
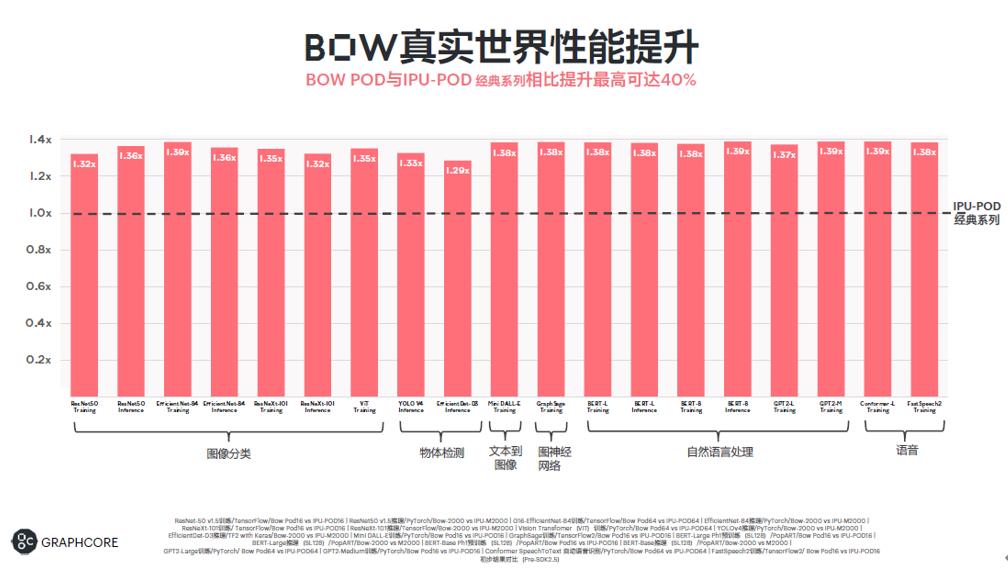
金琛还用一些数据展现了Bow IPU的性能优势。例如在ASR模型以及TextToSpeech(文本转语音)的模型上,性能实现了39%左右的提升。
除了能够保证较高的性能提升之外,大部分模型可以实现接近96%的电源效率,更加环保节能。
全新一代的Bow IPU,在性能上实现了大幅度的提升,有着更好的功耗,但相应的价格却没有变化。沟通会上卢涛针对这一问题进行了回应。他表示,“我们针对已经下了IPU-M2000订单的老用户准备了一些优惠方案,确保这些老客户也可以获得相似的每美元性能。”
正式官宣:Good Computer(古德计算机)
在此次媒体沟通会上,Graphcore还正式对外宣布了下一代的超级计算机:Good Computer(古德计算机)。

卢涛表示,人的大脑里大概有860亿个神经元,有100万亿个突触。这个突触相当于人工智能里面模型的参数个数。他强调,目前最大的人工智能模型的参数跟真正的人脑比较起来,可能还有100倍左右的差距。因此,Graphcore目前正在开发一款可以用来超越人脑处理的超级智能机器。
据介绍,这款命名为Good Computer(古德计算机)的计算机具有两层含义。一是好的计算机,希望计算机能够带来正面的影响;二也是向前辈致敬,Good是一位非常知名的计算机科学家。
“Good Computer大概能够达到8192个Graphcore未来的IPU,能够提供超过10 Exa-Flops的AI算力,也许会继续往3D Wafer-on-Wafer演进,可以实现4 PB存储,能够助力超过500万亿参数规模的人工智能模型的开发,而Graphcore Poplar SDK完全支持。”卢涛表示,取决于不同的配置,大概价格在100万美元到1.5亿美元。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK