

深度学习之旅--Regression学习笔记
source link: http://blog.linrty.com/2021/12/17/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B9%8B%E6%97%85--Regression%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
深度学习之学Regression的学习总结
Regression的用途
Stock Market Forecast(股市预测)
输入前几天的股票行情,预测明天的股票行情
Self−driving Car(自动驾驶汽车)
输入汽车识别到附近的物体,来做出方向盘的角度
Recommendation(推荐系统)
输入使用者与物品,输出使用者是否会使用该物品
Regression解决问题的步骤
(例子:预测宝可梦进化后的CP值为多少,输入为宝可梦进化前的各项参数,输出为预测的宝可梦进化后的CP值)
Step 1: Model
找一个function set(Model)
我们先随意假设一个function,y=b+w∗xcp ,y 为进化后预测的CP值,xcp 为进化前的CP值,w和b可以为任何的数值,通过枚举许多的组合,我们的function set内可以有无穷无尽的的function,如下:
f1:y=10.0+9.0∗Xcp
f2:y=9.8+9.2∗Xcp
f1:y=−0.8−1.2∗Xcp
…..infinitea
我们可以发现,有些function不太可能是正确的,比如f3 ,因为我们知道CP值为正数,当正数作为f3 的输入时,它的输出为负数,所以接下来我们需要做的工作就是将这些function set中找出一个合理的function
其实我们假设的Model(y=b+w∗xcp)是一个Linear model(是线性的),因为我们还需要考虑宝可梦的其他因素,比如身高、体重等,所以我们又有一下式子:
y=b+w∗xheight
y=b+w∗xweight
所以我们可以把这些式子综合到一起,就变成了这个样子:
y=b+∑wixi
其中这个式子中的xi 指的是我们所指定的各种因素(会影响最终预测宝可梦进化值的因素),wi 叫做weight , b 叫做bias
Step 2: Goodness of Function
接下来我们需要training data用来帮助我们选择出最合理的式子
Training Data
假设我们收集了十个data,如下:
(x1,ˆy1)
(x2,ˆy2)
(x10,ˆy10)
所以我们就可以画出这个图像:
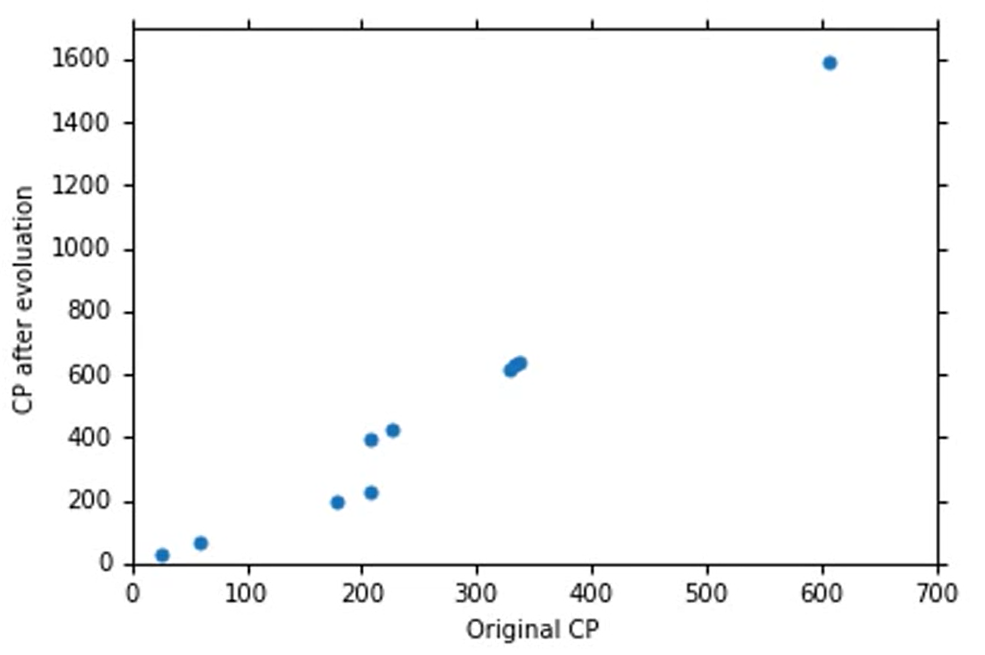
LossFunction
接下来,有了这些training data之后我们就可以定义这些function的好坏,对于每一个function我们都有一个function来评定这个function有多不好,Loss function ,简单的说Loss function就是输入一个function,输出评定这个function的好坏,我们可以把Loss function写成这样:
L(f)=L(w,b)
其实这个Loss function就相当于在评定这一组w和b的好坏,因为我们最终的目的就是找到一组最合理的w和b来评估宝可梦进化后的CP值
既然我们有了Loss Function的概念,接下来我们就是要定义一个Loss Function,随自己的喜好定义一个你觉得合理的function
我们使用比较常用的做法,如下:
L(w,b)10∑n=1(ˆyn−(b+w ⋅ xncp))2
(Latex语法待精进,打个公式耗半天)
Step 3: Best Function
因为我们已经有了LossFunction 所以我们需要做的就是找出一组w和b使得LossFunction的值最小,就是我们要找的最合理的Function
我们假设
w∗,b∗=arg minw,b L(w,b)=arg minw,b 10∑n=1(ˆyn − (b + w ⋅ xncp))2
也就是我们需要把所有的w和b代入这个function里面,看哪一个是最好的结果
Gradient Descent
先以一个比较简单的Function来解决
假设我们现在需要consider的LossFunction是L(w)
我们先随机选取一个初始的点w0
我们需要计算w0 在这个Loss Function的微分,也就是计算 dLdw|w=w0
我们知道微分就是函数在该点的切线斜率,我们需要找最小的值
如果切线斜率是负数,那么它就是左高右低,也就是我们需要把我们选取的参数w0 向右边移动一点,也就是增大我们的参数值
如果切线斜率是正数,那么它就是左低右高,也就是我们需要把我们选取的参数w0 向左边移动一点,也就是减小我们的参数值
确定需要增加/减少多少,引入一个后面的概念η (也被称作为Learning rate,后面会学习到,现在先不管)
所以我们确定我们需要移动的距离是 −η dLdw|w=w0
所以我们就更新了我们的参数,比如我们需要增加w0的值,那么久可以变成w1←w0−η dLdw|w=w0
然后继续回到步骤2进行计算
当到达Local minimun 微分为0 时,就是最好的,需要注意的是在Regression中不会出现Local minimum 不是Global minimum的情况
现在我们需要推广到两个参数的情形,其实和一个参数的情形一样,不同的点在于一开始我们需要随机选取两个参数,即w0,b0 ,以及接下来,我们需要计算两个参数的偏微分,也就是需要计算:
∂L∂w|w=w0,b=b0 和 ∂L∂b|w=w0,b=b0
之后我们分别更新两个参数的值
w1←w0−η∂L∂w|w=w0,b=b0
b1←b0−η∂L∂b|w=w0,b=b0
然后继续计算偏微分,更新参数,直到找到最小的值
我们不需要担心Local minimum不是Global minimum,因为在Linear Regression 中,我们定义的Loss Function是convex
How′s the result
我们根据training data 计算出b 和 w 的值
b=−188.4
w=2.7
画出图像是这样的:
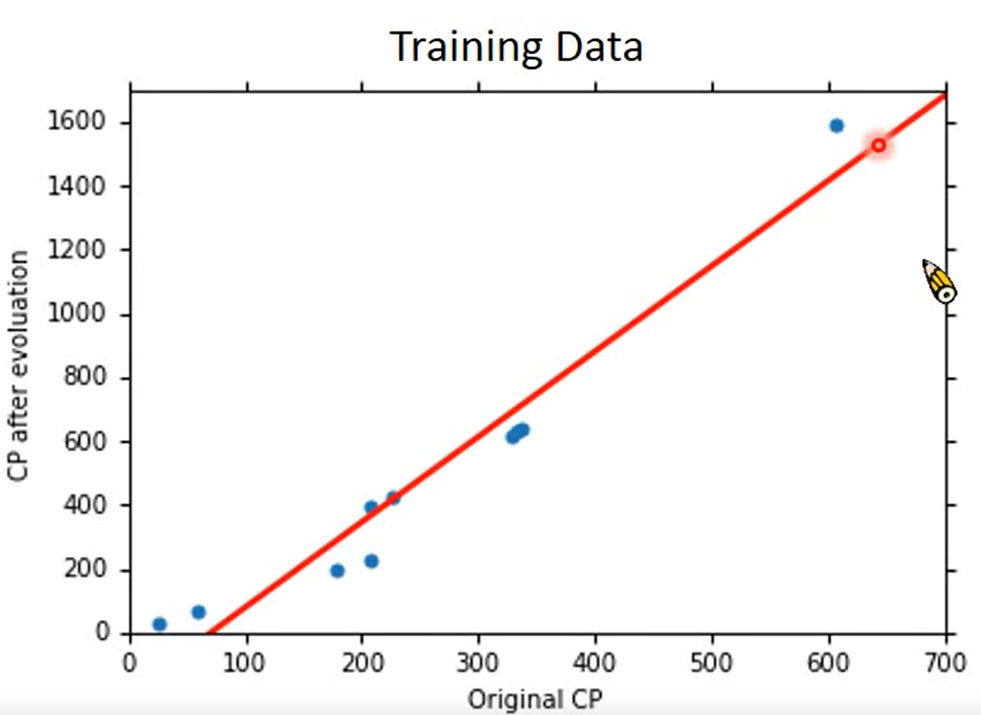
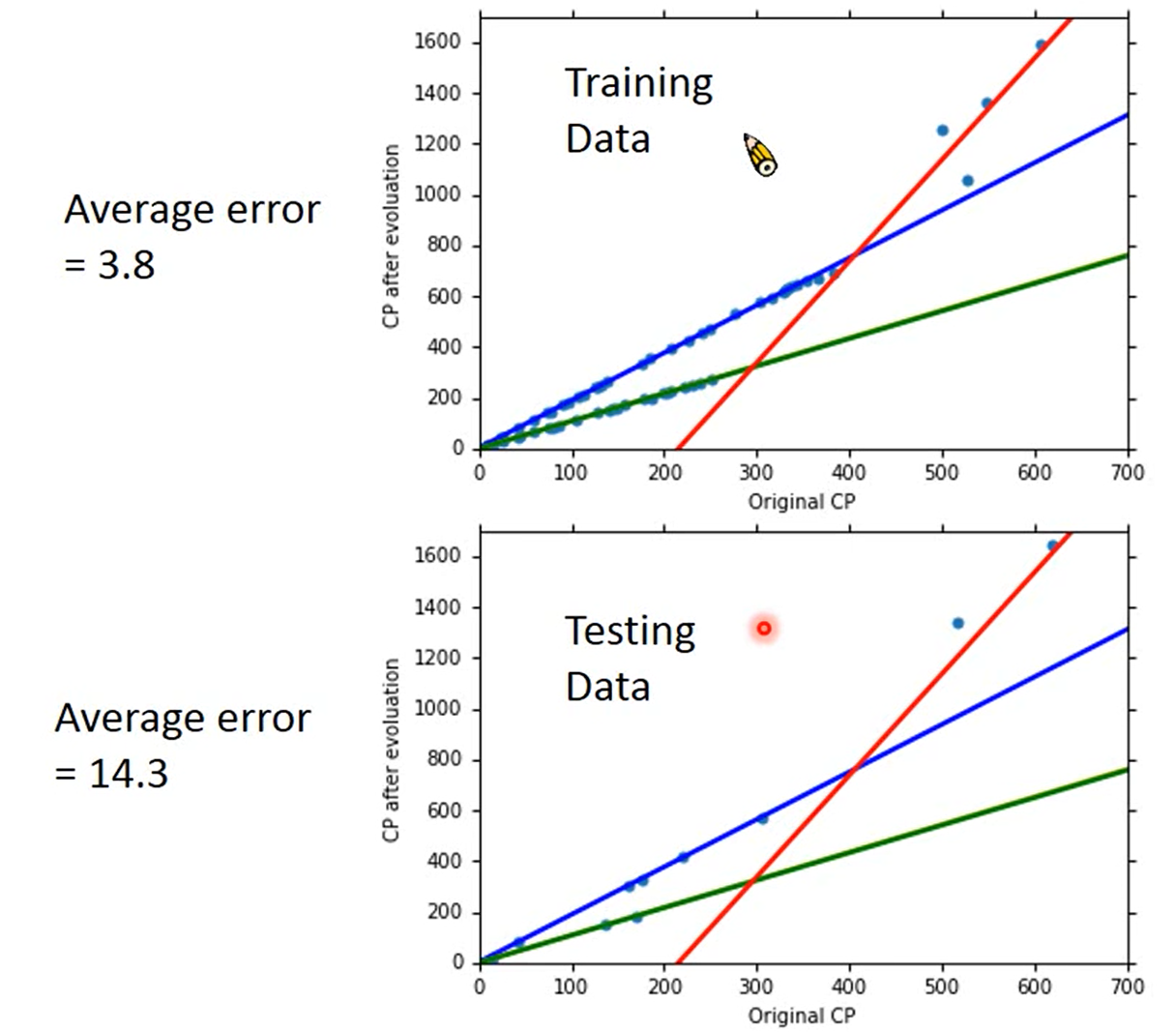
我们可以发现,这条红色的线没有办法完全正确的评定所有宝可梦的进化后的CP值,我们可以计算一下我们的error 就是计算一下每一个点和红色线的竖直距离,然后求和
然而我们主要的目的并不是training data的error,因为我们最终的目的是预测一只宝可梦的进化后的CP值,也就是我们真正需要关心的是generalization的case也就是平常的例子,而不是我们用来计算的例子,也称为testing data
所以我们再计算一下testing data的error
所以我们有没有办法让error更小呢?
所以我们需要一个更复杂的Model
我们重新设计一个Model , 也就是
y=b+w1⋅Xcp+w2⋅(Xcp)2
通过一样的计算方法,我们使用training data计算出最好的function 是
b=−10.3
w1=1.0,w2=2.7×10−3
然后画在图上是这样的:
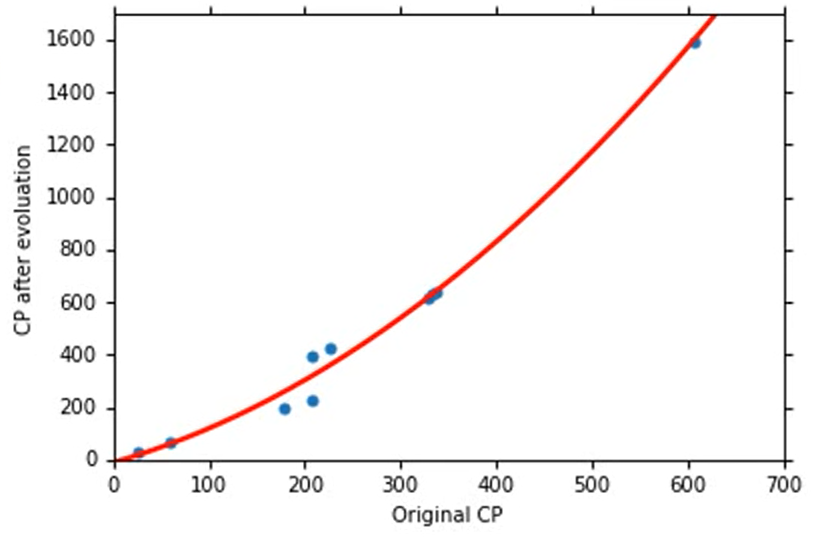
在training data和testing data上得出的error比之前的更小,说明这个model比之前的更好
我们继续将model变得更复杂一点:
y=b+w1⋅Xcp+w2⋅(Xcp)2+w3⋅(Xcp)3
这样我们算出的结果是:
b=6.4,w1=0.66
w2=4.3×10−3
w3=1.8×10−6
算出后的training data和testing data的error还是比之前的model要小一点
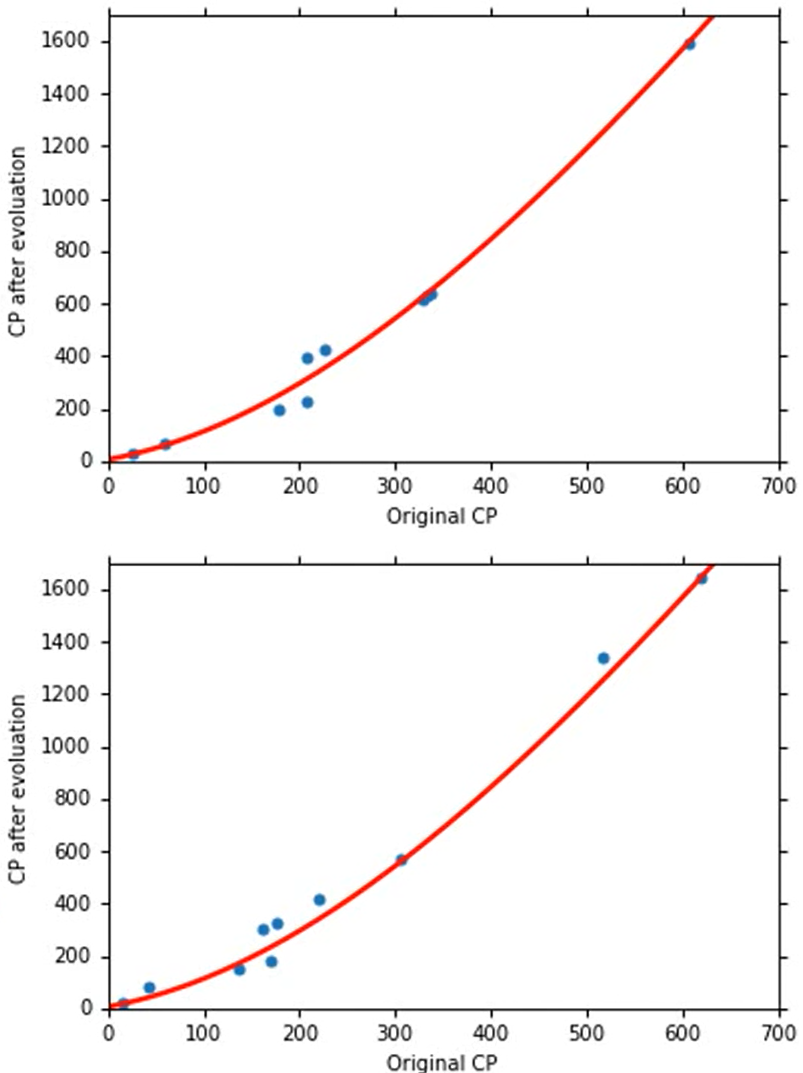
但是如果我们再继续考虑复杂一点的时候,比如加入x4cp 或者x5cp 我们会发现,training data的error还在下降,但是在testing data上error反而增大了
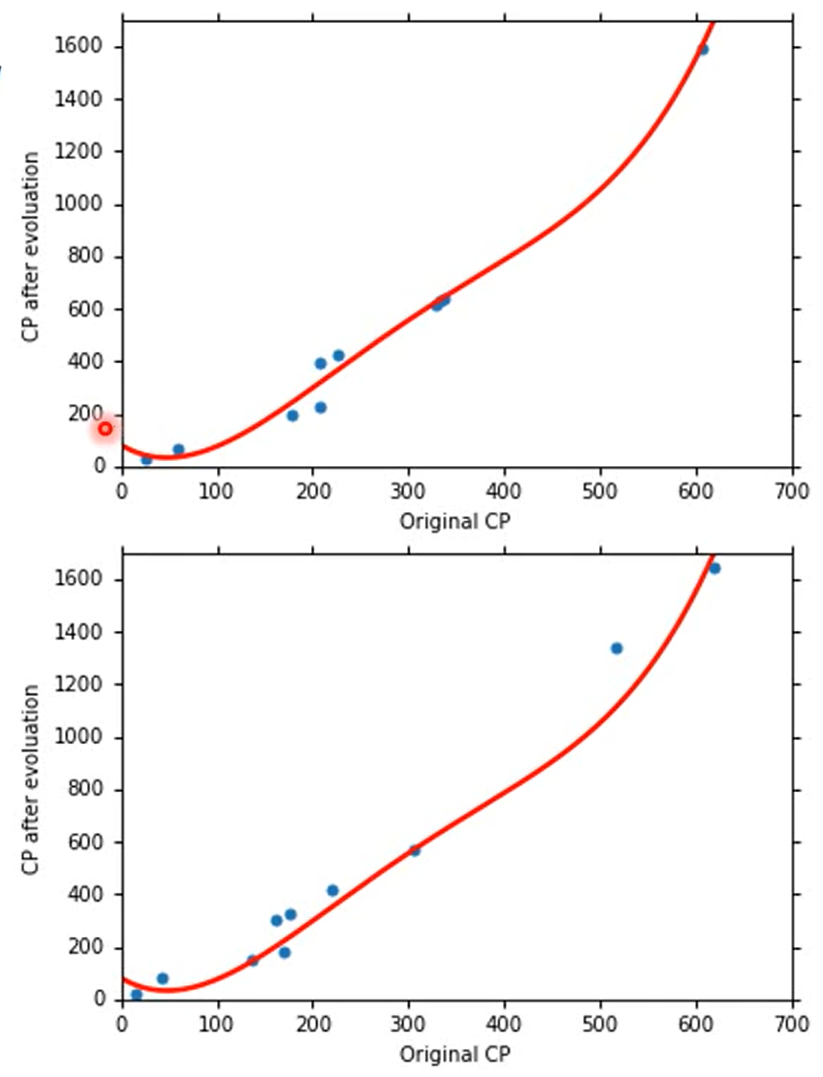
在考虑了五次方的时候甚至出现了不合理的结果
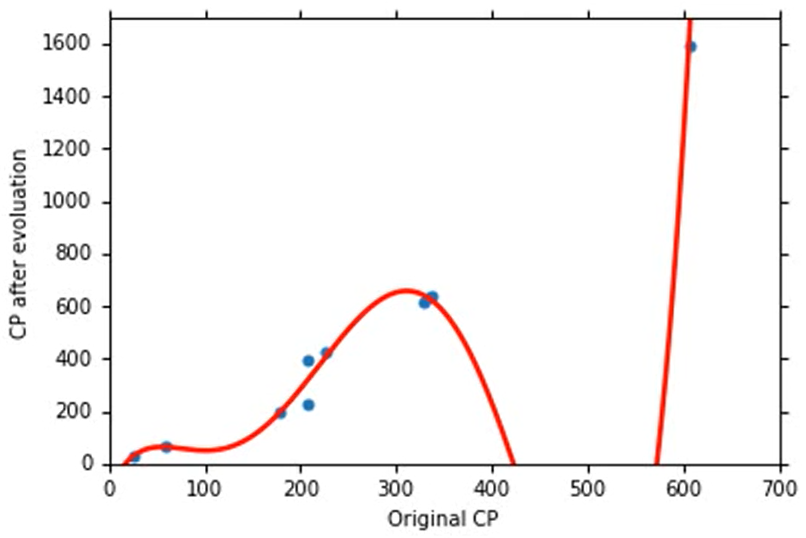
出现了负数的情况,虽然training data的error还在下降,但是testing data的error非常大
training data随着Model的复杂程度一直下降的原因–Overfiting
因为复杂的方程式总是包含着简单的方程式,比如说
式子(7)当w3为0时就相当于式子(6) ,所以复杂的式子是包含简单的式子的,也就越能拟合training data,但是我们的目的不是为了training data,我们需要的是预测数据,需要的是testing data更加的准确
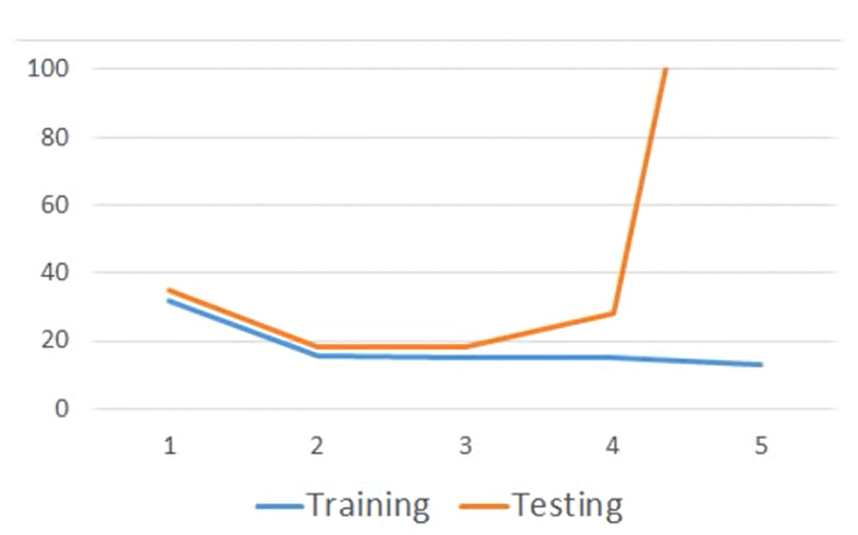
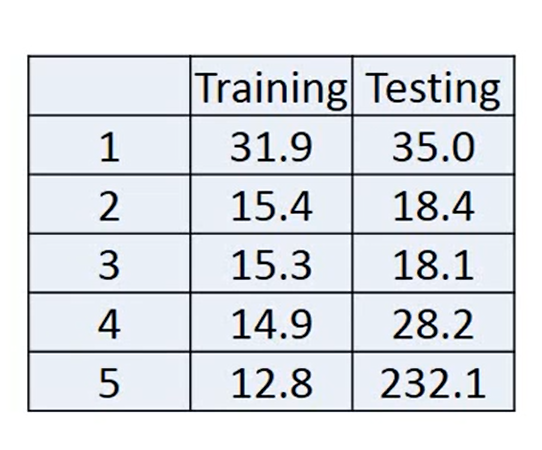
这种情况称为overfitting
What are the hidden factors?
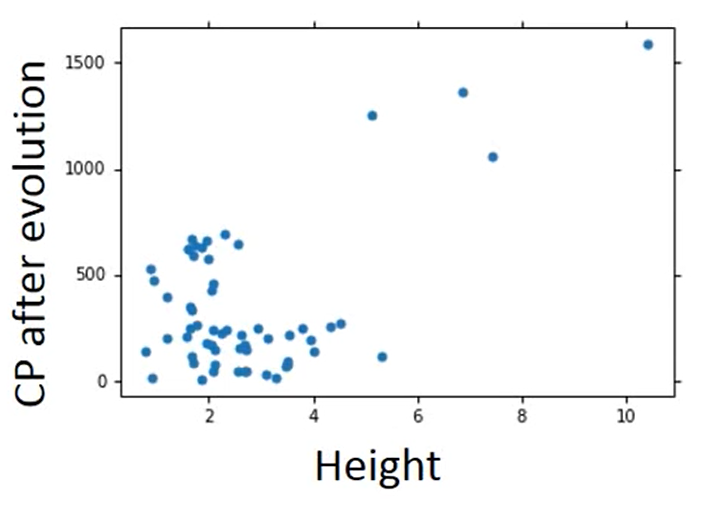
我们之前只考虑了宝可梦进化之前的CP值,但是我们手机数据会发现,有些我们未发现的因素在影响进化后的CP值
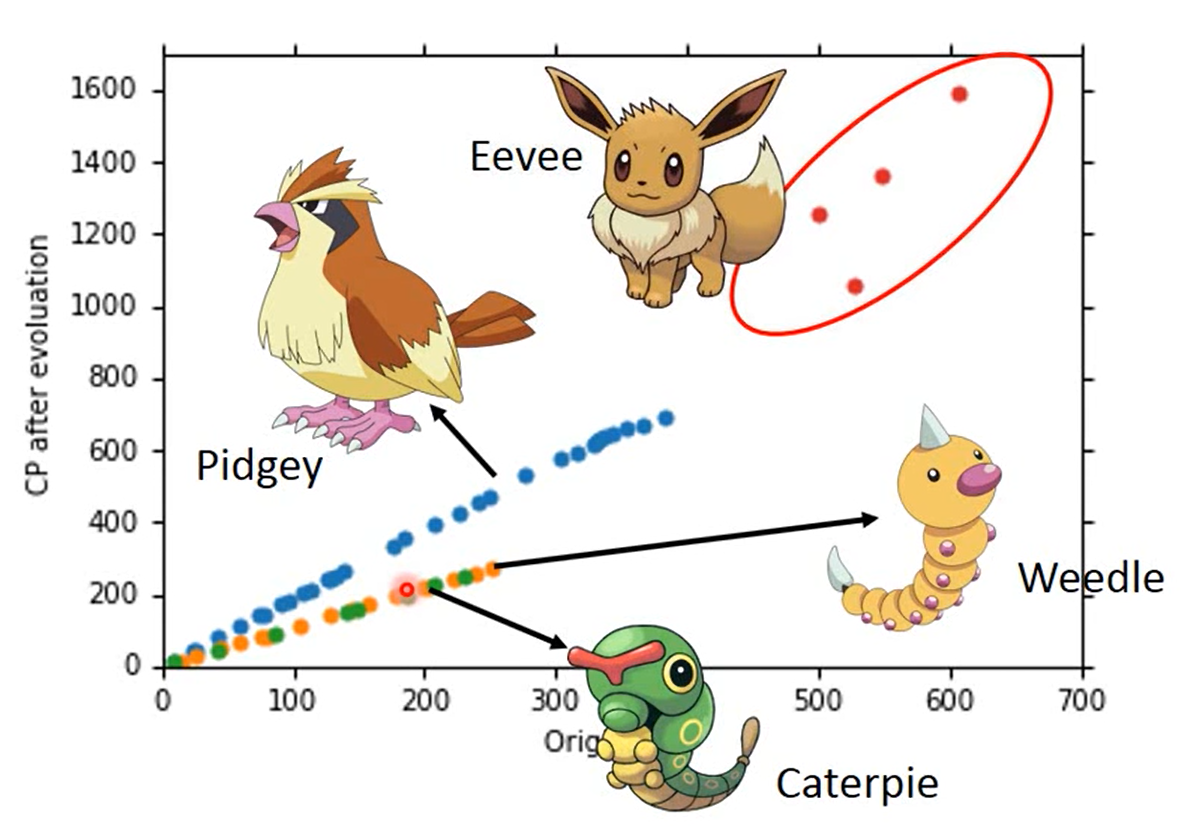
Back to step 1:
我们重新来设计一下Model ,我们根据物种来分类计算
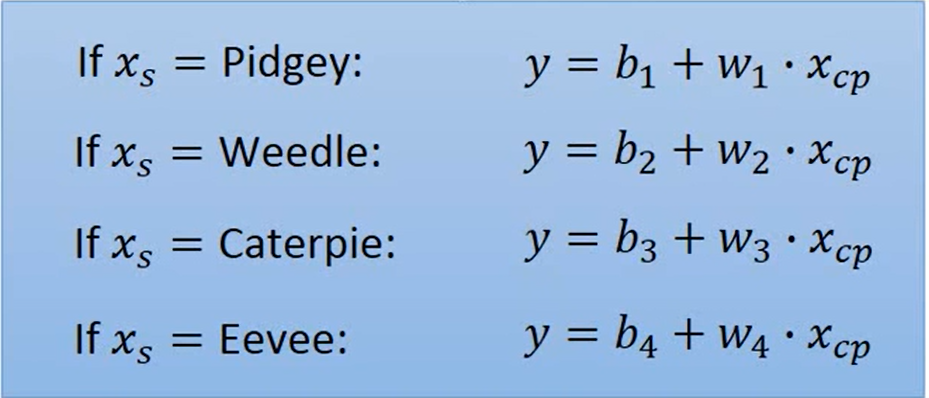
我们可以将这个式子改写成 Linear Model
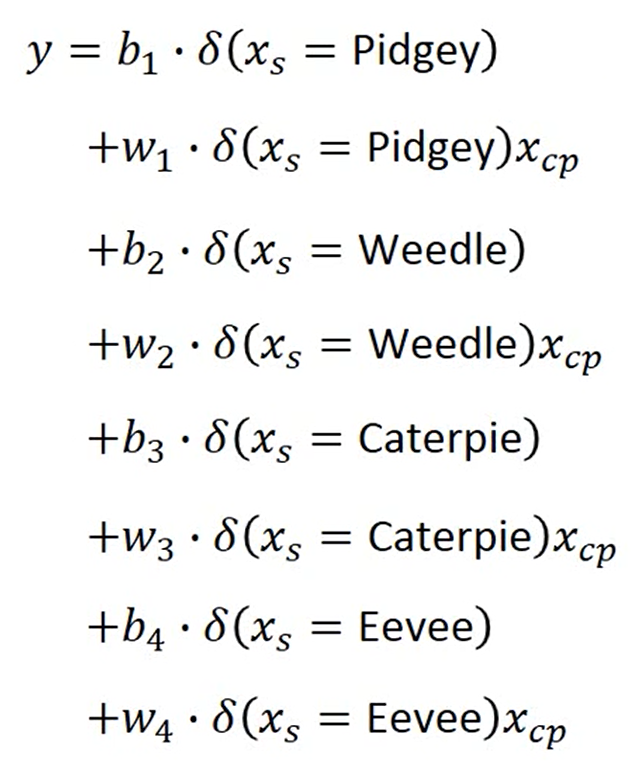
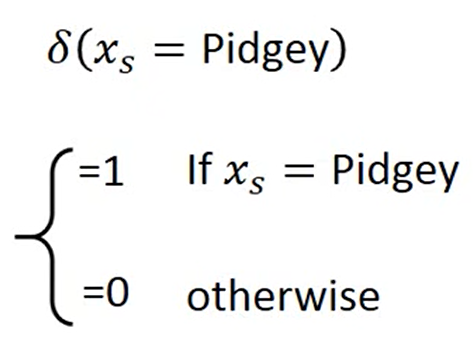
和之前一样的计算方法计算后,我们得出training data 和testing data 的error更加的小了
Are there any other hidden factors?
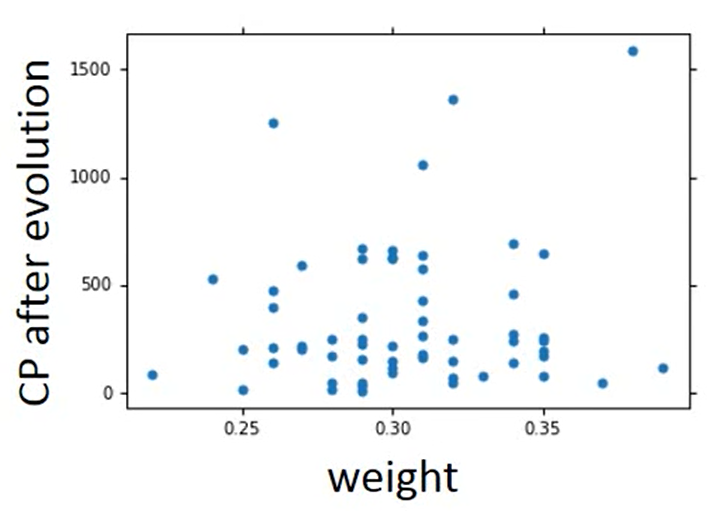
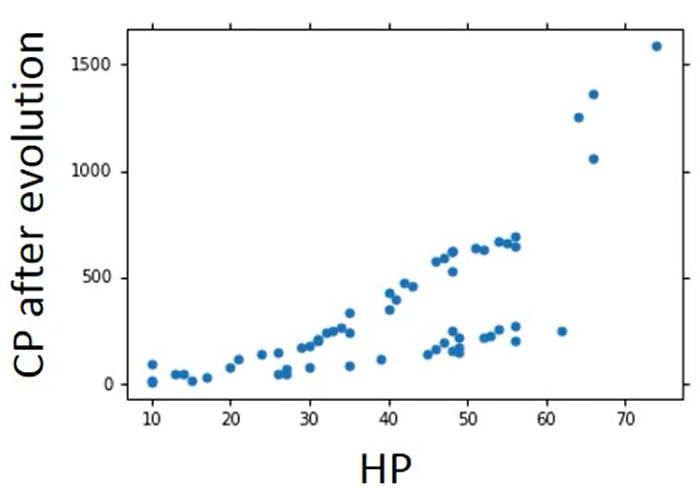
我们把我们想到的因素都加入方程中,形成一个新的Model
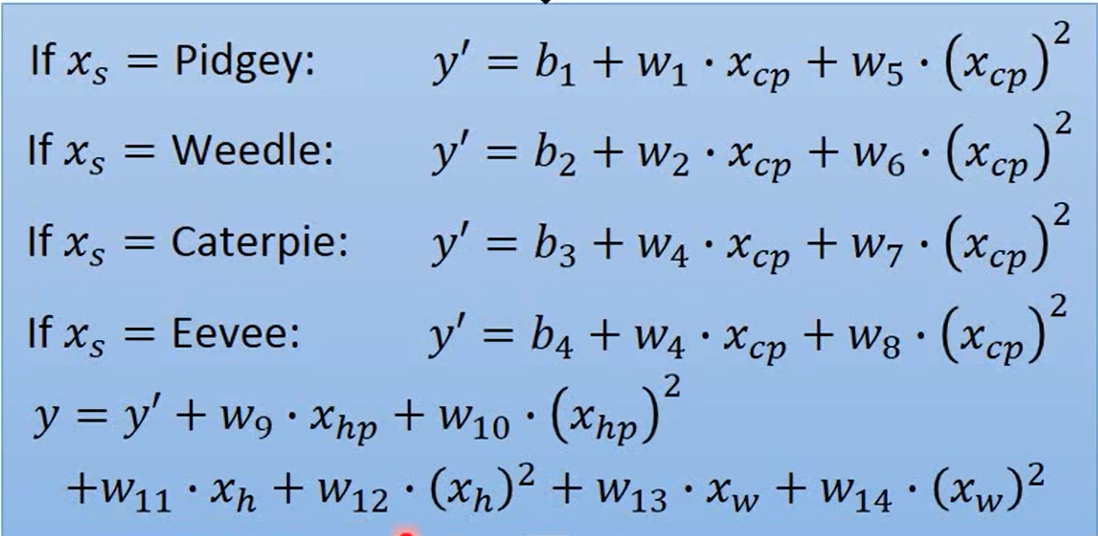
我们通过计算得到的training data的error的值非常的低
但是我们在testing data的error非常的大,也就是说我们Overfitting了
Back to step 2: Regularization
因为我们不可能真正的知道影响宝可梦进化后的CP值的因素,那我们如何避免Overfitting呢
我们重新定义Loss Function
对于Model
y=b+∑wixi
我们之前定义的Loss Function为
L=∑n(ˆyn−(b+∑wixi))2
可以发现,我们之前的Loss Function 只考虑了error这件事
接下来我们介绍Regularization ,其实Regularization 就是在对之前的Loss Function 进行完善,加入了另一项参数,如下:
L=∑n(ˆyn−(b+∑wixi))2+λ∑(wi)2
意思就是wi越小越好,这样的话Input变化时,Output变化不会特别大,也就时说,在图像上反应出来的结果就时越平滑越好
我们继续来讨论λ 的值,我们通过枚举它的值来进行比较
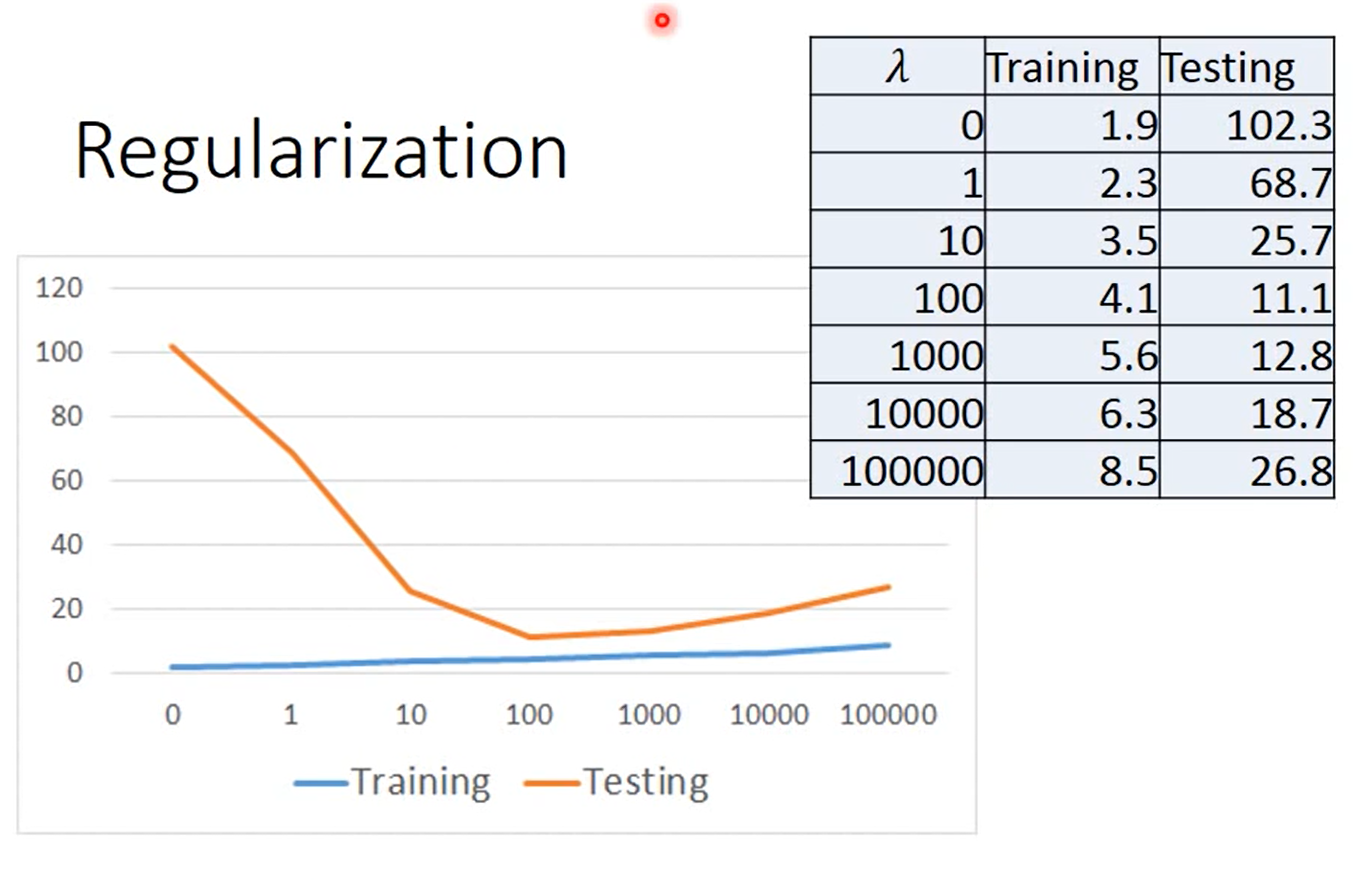
可以看出,当λ 的值越大的时候我们的function 就越平滑,但是我们可以发现,我们的function越平滑,我们在training data 上得到的error 就越大,但是这件事情时合理的,因为我们随着λ 增大的时候,w 的值的重要性也就越来越大,而error在function的重要性也就随之降低。
但是,我们发现,虽然在training data的error会随着λ 的增大而变大,但是在testing data上面,有的时候它的error反而时变小的。因为越λ 越大代表function越平滑,而越平滑的function它对noise(噪声)比较不sensitive(敏感)。
但是,我们不需要太平滑的function,比如最最平滑的function就是一条水平的线,如果function是一条水平线,那什么都预测不到了,输入什么,最终输出的结果都是一样的。所以我们的function如果过于的平滑的话,我们在testing data上面得到的error又会变得更糟糕。
所以我们需要选择一个合适的λ 来作为你的Model参数。
最后就可以得出结论了。
需要注意的是,我们使用的testing data是比较局限的,所以如果真正的使用起来,它的error rate会比我们现在计算的error会高。
本文链接: http://blog.linrty.com/2021/12/17/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B9%8B%E6%97%85--Regression%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK