

使用 Node 处理 I/O 密集型任务
source link: https://www.fly63.com/article/detial/11178
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
摩尔定律是由英特尔联合创始人戈登·摩尔(Gordon Moore)在 1965 年提出的,即集成电路上可容纳的元器件的数量每隔 18 至 24 个月就会增加一倍,性能也将提升一倍。也就是说,处理器(CPU)的性能每隔大约两年就会翻一倍。
距离摩尔定律被提出到现在,已经过去了 50 多年。如今,随着芯片组件的规模越来越接近单个原子的规模,要跟上摩尔定律的步伐变得越来越困难。
在 2019 年,英伟达 CEO 黄仁勋在 ECS 展会上说:“摩尔定律过去是每 5 年增长 10 倍,每 10 年增长 100 倍。而如今,摩尔定律每年只能增长几个百分点,每 10 年可能只有 2 倍。因此,摩尔定律结束了。”
单个处理器(CPU)的性能越来越接近瓶颈,想要突破这个瓶颈,则需要充分利用 多线程技术,让单个或多个 CPU 可以同时执行多个线程,更快的完成计算机任务。
Node 的多线程
我们都知道,Javascript 是单线程语言,Nodejs 利用 Javascript 的特性,使用事件驱动模型,实现了异步 I/O,而异步 I/O 的背后就是多线程调度,非常适合用来处理 I/O 密集型任务。
Node 异步 I/O 的实现可以参考朴灵的 《深入浅出 Node.js》
在 Go 语言中,可以通过创建 Goroutine 来显式调用一条新线程,并且通过环境变量 GOMAXPROCS 来控制最大并发数。
在 Node 中,可以使用 worker_threads 创建新的 Worker 来衍生新的工作线程。工作线程对于执行 CPU 密集型的 JavaScript 操作非常有用。它们在 I/O 密集型的工作中用途不大。 Node.js 的内置的异步 I/O 操作比工作线程效率更高。Node 本身实现了一些异步 I/O 的 api,例如 fs.readFile、http.request。这些异步 I/O 底层是调用了新线程执行异步任务,再利用事件驱动的模式来获取执行结果。
服务端开发、工具开发可能都会需要处理 I/O 密集型任务。比如处理复杂的爬虫任务,处理并发请求,进行文件处理等等...
在我们使用多线程来处理 I/O 密集型任务时,一定要控制最大同时并发数。因为不控制最大并发数,可能会导致 文件描述符 耗尽引发的错误,带宽不足引发的网络错误、端口限制引发的错误等等。
在 Node 中并没有用于控制最大并发数的 API 或者环境变量,所以接下来,我们就用几行简单的代码来实现。
我们先假设下面的一个需求场景,我有一个爬虫,需要每天爬取 100 篇掘金的文章,如果一篇一篇爬取的话太慢,一次爬取 100 篇会因为网络连接数太多,导致很多请求直接失败。
那我们可以来实现一下,每次请求 10 篇,分 10 次完成。这样不仅可以把效率提升 10 倍,并且可以稳定运行。
下面来看看单个请求任务,代码实现如下:
const axios = require("axios");
async function singleRequest(article_id) {
// 这里我们直接使用 axios 库进行请求
const reply = await axios.post(
"https://api.juejin.cn/content_api/v1/article/detail",
{
article_id,
}
);
return reply.data;
}为了方便演示,这里我们 100 次请求的都是同一个地址,我们来创建 100 个请求任务,代码实现如下:
// 请求任务列表
const requestFnList = new Array(100)
.fill("6909002738705629198")
.map((id) => () => singleRequest(id));接下来,我们来实现并发请求的方法。这个方法支持同时执行多个异步任务,并且可以限制最大并发数。在任务池的一个任务执行完成后,新的异步任务会被推入继续执行,以保证任务池的高利用率。代码实现如下:
const chalk = require("chalk");
const { log } = require("console");
/**
* 执行多个异步任务
* @param {*} fnList 任务列表
* @param {*} max 最大并发数限制
* @param {*} taskName 任务名称
*/
async function concurrentRun(fnList = [], max = 5, taskName = "未命名") {
if (!fnList.length) return;
log(chalk.blue(`开始执行多个异步任务,最大并发数: ${max}`));
const replyList = []; // 收集任务执行结果
const count = fnList.length; // 总任务数量
const startTime = new Date().getTime(); // 记录任务执行开始时间
let current = 0;
// 任务执行程序
const schedule = async (index) => {
return new Promise(async (resolve) => {
const fn = fnList[index];
if (!fn) return resolve();
// 执行当前异步任务
const reply = await fn();
replyList[index] = reply;
log(`${taskName} 事务进度 ${((++current / count) * 100).toFixed(2)}% `);
// 执行完当前任务后,继续执行任务池的剩余任务
await schedule(index + max);
resolve();
});
};
// 任务池执行程序
const scheduleList = new Array(max)
.fill(0)
.map((_, index) => schedule(index));
// 使用 Promise.all 批量执行
const r = await Promise.all(scheduleList);
const cost = (new Date().getTime() - startTime) / 1000;
log(chalk.green(`执行完成,最大并发数: ${max},耗时:${cost}s`));
return replyList;
}从上面的代码可以看出,使用 Node 进行并发请求的关键就是 Promise.all,Promise.all 可以同时执行多个异步任务。
在上面的代码中,创建了一个长度为 max 最大并发数长度的数组,数组里放了对应数量的异步任务。然后使用 Promise.all 同时执行这些异步任务,当单个异步任务执行完成时,会在任务池取出一个新的异步任务继续执行,完成了效率最大化。
接下来,我们用下面这段代码进行执行测试(代码实现如下)
(async () => {
const requestFnList = new Array(100)
.fill("6909002738705629198")
.map((id) => () => singleRequest(id));
const reply = await concurrentRun(requestFnList, 10, "请求掘金文章");
})();最终执行结果如下图所示:
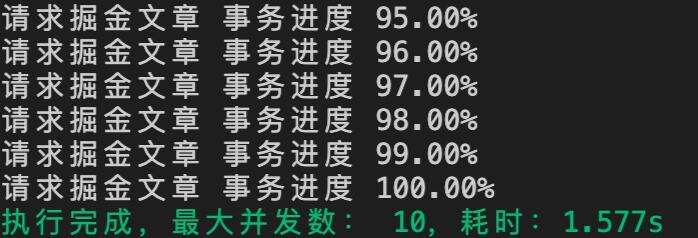
到这里,我们的并发请求就完成啦!接下来我们分别来测试一下不同并发的速度吧~ 首先是 1 个并发,也就是没有并发(如下图)
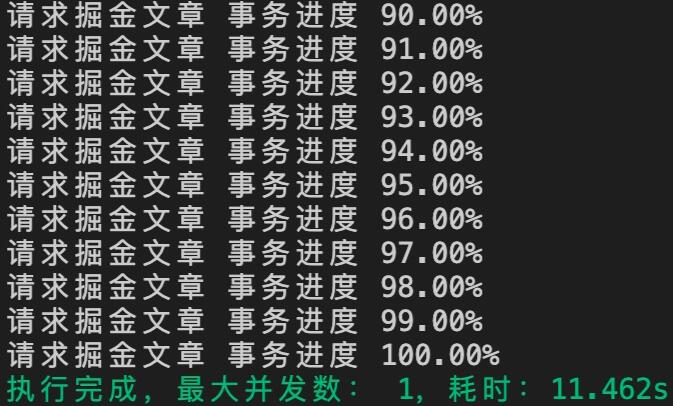
耗时 11.462 秒!当不使用并发时,任务耗时非常长,接下来我们看看在其他并发数的情况下耗时(如下图)

从上图可以看出,随着我们并发数的提高,任务执行速度越来越快!这就是高并发的优势,可以在某些情况下提升数倍乃至数十倍的效率!
我们仔细看看上面的耗时会发现,随着并发数的增加,耗时还是会有一个阈值,不能完全呈倍数增加。这是因为 Node 实际上并没有为每一个任务开一个线程进行处理,而只是为异步 I/O 任务开启了新的线程。所以,这个方案比较适合处理 I/O 密集型任务,如果是 CPU(计算)密集型任务则需要考虑使用 worker_threads 来处理。
到这里,我们的使用 Node 处理 I/O 密集型任务就介绍完了。如果想要程序完善一点的话,还需要考虑到任务超时时间、容错机制,大家感兴趣的可以自己实现一下。
来自:https://github.com/a1029563229/Blogs/tree/master/BestPractices/node/concurrent
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK