

RfD-Net:基于语义实例重构的点云场景理解(CVPR2021)
source link: https://zhuanlan.zhihu.com/p/422091202
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
RfD-Net:基于语义实例重构的点云场景理解(CVPR2021)
论文标题:RfD-Net: Point Scene Understanding by Semantic Instance Reconstruction
论文地址:https://arxiv.org/abs/2011.14744
项目地址:https://github.com/yinyunie/RfDNet
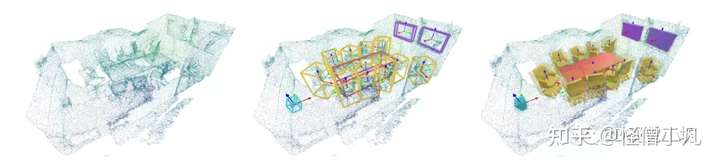
摘要
从点云中理解语义场景具有一定发挑战性,因为这些点仅反映了稀疏的底层三维几何体。以前的工作经常将点云转换为规则网格,并采用基于网格的卷积来理解场景。在本研究工作中,研究人员引入了RfD-Net,它可以直接从原始点云中联合检测和重建密集的物体表面。RfD-Net利用点云数据的稀疏性,重点预测具有高对象性的形状。通过这种设计,研究人员将实例重构解耦为全局对象定位和局部形状预测。它不仅减轻了从稀疏三维空间学习二维表面的难度,而且点云中传达了支持隐函数学习的形状细节,以重建任何高分辨率曲面。实验表明,实例检测和重建呈现出互补的效果,其中shape prediction head对使用现有网络主干来改善对象检测具有一致效果。定性和定量评估进一步表明,研究人员的方法始终优于现有的方法,并且在对象重建中提高了超过11个网格IoU。
作者:夏初,来源微信公众号:3D视觉工坊
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
研究贡献
- 研究人员提供了一种新的语义姿态重建学习模式。据研究人员所知,它是第一种直接从点云中用几何预测实例语义的学习方法。
- 研究人员提出了一种新的端到端架构,即RfDNet,从稀疏点云中学习对象语义和形状。它将语义实例重建分解为全局对象定位和局部形状预测,通过这种方式,shape generator支持隐式学习,直接克服了现有技术中的分辨率瓶颈。
- 联合学习对象的姿势和形状具有互补的优势。它对backbones具有一致的影响,并在实例检测和完成方面达到了最先进的水平,在对象重建中提高了超过11网格IoU。
研究方法
下图说明了RfD-Net的架构。研究方法遵循“从检测中重建”来理解3D场景的基本原则。在此之上,研究人员设计了由3D detector,Spatial transformer和Shape generator组成的网络。研究人员构建的架构,用于从点云中学习实例形状。
具体来说,从输入点云,3D detector生成框从稀疏三维场景中定位候选对象。然后,研究人员设计了一个Spatial transformer来进行框选,并对本地点云进行分组和对齐,用于下一个对象形状生成。Shape generator独立地学习occupancy function来表示形状。
(1) 3D detector
3D detector可以从点云中学习object proposals。首先,对于输入的点云,研究人员采用VoteNet作为框架来产生box proposals,并以此为特征来预测参数,包括object proposals中心,尺度,角度,语义标签和objectness score,当一个box proposals中心与真实值之间的差距小于0.3m时,分值取正;当与真实值之间的差距大于0.6m时取负。最后研究人员使用了两层的多层感知机来回归box的参数。
(2) Spatial transformer
该模块分为两部分:Objectness dropout和点云的Group&align。Objectness dropout部分的输入为3D detector的输出,即所有box proposals的参数,输出为物体空间占有分数较高的box proposals。Group&align的目的是将原始点云聚类到box proposals中,并转换到局部坐标系。首先,由于之前提取出的box proposals过多,研究人员采用top-N dropout保留得分较高的box proposals;研究人员对原始点云进行采样,用一个group layer对每个box的点进行采样,最后每个cluster输出Mp个点,将这些点带入对齐公式中,然后先把每个cluster的点云移到原点,然后旋转到正位。
(3) Shape generator
该模块具体细节如下图所示,分为Skip propogation,Shape decoder和Marching cubes三部分。
在Skip propogation中,研究人员使用PointNet,将每个box proposal中的点分为前景和背景,提取前景中的点之后,与三维目标检测提取出的proposal特征合并,再使用带有残差连接的PointNet将合并后的特征编码成新的特征,可以将这部分特征看作融合了局部信息与全局信息(如三维形状,语义标签等)。然后,在Shape decoder部分,如下图所示:
研究人员采用Batch Normalization层回归出occupancy values,将其与点和proposal特征一起送入latent encoder中,回归出一个高斯分布的均值与标准差,再从这个分布上采样,得到一个隐式编码。最后,将上述计算结果送入conditional block,回归occupancy value,以表示该点是否被占据,然后采用marching cubes算法生成最终的网格。
(4)端到端的学习
端到端的学习的损失函数分两部分,分别为Box loss和Shape loss。
Box loss:3D detector是用来预测物体空间objectness score、object proposals中心、尺度、角度等特征,对于objectness score,研究人员设定阈值选取objectness score为正的点;对于object proposals中心,选用Smooth- L1 loss函数进行处理;研究人员将尺度与角度的损失函数设为一个分类损失函数(交叉熵)与一个回归损失函数(Smooth- L1 loss)的混合;对于语义标签,研究人员使用的是交叉熵损失函数。
Shape loss:对于每个proposal里的点,使用交叉熵损失函数来监督前景分割,Shape generator从latent code来学习均值和方差去近似训练中的标准正态分布。
实验设置与结果
1.数据集:实验中使用了两个数据集,ScanNet v2和Scan2CAD。
2.实验结果
定性比较:与RevealNet进行比较。下图的结果表明,本研究中的方法呈现出更好的对象框和形状细节质量。研究人员进一步通过在单个任务上的结果进行定量评估,主要使用两种网络模型的配置:3D detector和Shape generator之间的互补效应,即,端到端地训练网络;单独训练3D detector和Shape generator,另一个模块固定。
定量比较:
研究人员同样进行了定量比较,相关的实验结果如上图所示。
1.3D物体检测:与现有3D-SIS、ML CVNet和RevealNet进行比较来评估本文中3D检测。从结果中,研究人员观察到,通过联合训练,本研究中shape generator改进了网络主干。
2.对象重建:研究人员使用3D网格IoU进一步评估单个对象重建质量,RevealNet中的所有预测和真实情况共享相同的坐标系,即TSDF网格。
3.语义实例完成情况:研究人员在语义实例级别评估研究中的场景完成方法,即测量预测的对象网格在3D场景中覆盖地面实况的程度。
本文仅做学术分享,如有侵权,请联系删文。
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:CV_LAB,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK