

RP-VIO:面向动态环境的基于平面的鲁棒视惯融合里程计(IROS2021)
source link: https://zhuanlan.zhihu.com/p/433158403
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
RP-VIO:面向动态环境的基于平面的鲁棒视惯融合里程计(IROS2021)
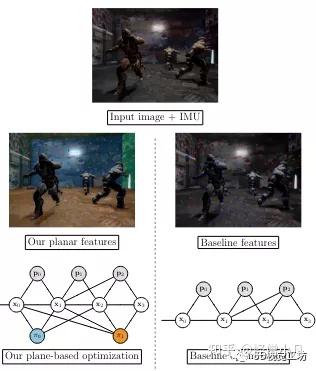
RP-VIO: Robust Plane-based Visual-Inertial Odometry for Dynamic Environments
来源:Ram K, Kharyal C, Harithas S S, et al. RP-VIO: Robust Plane-based Visual-Inertial Odometry for Dynamic Environments[J]. IROS 2021
单位:印度海得拉巴机器人研究中心;
代码开源:https://github.com/karnikram/rp-vio
作者:Maple|来源微信公众号:3D视觉工坊
针对问题:
面向动态场景的鲁棒视惯融合里程计
提出方法:
充分利用场景中的平面约束,在初始化、滑窗优化中对自身位姿进行优化
达到效果:相较于VINS-Mono、VINS-Mask,RP-VIO在论文自建数据集、VIODE、OpenLORIS-Scene、ADVIO数据集上实现了鲁棒且准确的定位效果。
Abstract
VINS系统在实际部署中面临着一个关键的挑战:它们需要在高度动态的环境中可靠而鲁棒地运行。目前最好解决方案根据物体的语义类别将动态物体作为外点剔除。这样的方法无法扩展,因为它要求语义分类器包含所有可能移动的物体类别;这很难定义,更不用说部署了。另一方面,许多实际环境以平面的形式表现出强烈的结构规律性,如墙壁和地面。文章提出了RP-VIO,系统利用这些平面信息,在具有挑战性的动态环境中提升了系统鲁棒性和准确性。由于现有数据集的动态元素数量有限,文章还提出了一个高度动态、逼真的仿真数据集,以便更有效地评估VINS系统的能力。文章在这个数据集和来自标准数据集的三个不同序列(包括两个实际场景的动态序列)上评估了文章的方法,相较于最先进的单目视觉里程计,系统表现出在鲁棒性和准确性上得到显著的改善。
Introduction
现有VIO系统具有一些局限性,首先除了需要精确同步和校准的额外硬件外而且该系统还需要进行足够的旋转和加速运动以保持重力和尺度的可观察性。另一个重要的限制是他们在有多个独立运动物体的动态环境中的表现。基本的多视角几何约束只适用于静态点,当应用于动态点时就会导致错误。这个问题在单目VINS的初始化阶段尤其重要,在这个阶段,来自视觉SFM的姿态估计通常直接与IMU预积分结果测量一致,以初始化尺度和IMU参数。在这个阶段,不正确的视觉姿态估计会导致完全的跟踪失败。一个可行的方法是通过语义信息,直接识别场景中的静态部分,以进行特征跟踪。我们注意到,平面是日常人造环境中最丰富的静态区域。重要的是,平面还提供了一个简单的几何形状,可以进一步利用它来改善估计。基于这一观点,文章提出了RP-VIO,一个为动态环境定制的基于平面的单目视觉里程计。RP-VIO只使用场景中一个或多个平面的特征,由一个平面分割模型识别,并使用平面单应性进行运动估计。我们用我们提出的单应性约束增强了最先进的单目VIO系统,并在仿真以及实际场景数据集上显著提高了性能。
Main Contributions
RP-VIO是一个在初始化和滑动窗口估计过程中只使用平面特征及其导出的单应性约束的单目VIO系统,以提高动态环境中的鲁棒性和准确性。构建了一个逼真的包含视觉以及IMU信息的数据集,与现有的数据集不同,它包含了整个序列(包括初始化)中的动态人物,并有足够的IMU激励。在自建数据集上对所提出方法进行了广泛的评估,一个来自最近发布的VIODE数据集的户外模拟序列,以及来自OpenLORIS-Scene和ADVIO的两个具有挑战性的真实世界序列,使用了一个基于CNN的平面分割模型。
Method
我们提出的方法足够通用,可以集成到任何视惯融合里程计或SLAM系统中,在这项工作中,我们以VINS-Mono为基础。VINSMono是一个最先进的单目VIO,它是基于预集成的IMU测量和视觉特征的紧耦合的滑动窗口优化。我们认为它是一个纯粹的VIO系统,忽略了它的重新定位和闭环模块。我们在其前端的基础上,只检测和跟踪场景中的平面特征,并在初始化和优化模块中引入平面单应性约束。
1.符号定义
2.前端
我们的系统将灰度图像、IMU测量值和平面分割掩码作为输入。这些平面分割遮罩是从一个基于CNN的模型中获得的,我们在第三章E节中描述。我们在原始图像上应用获得的平面实例分割掩码,只检测和跟踪属于场景中(静态)平面区域的特征,同时还保持每个被跟踪特征属于哪个平面的信息。为了避免检测到可能属于动态物体的面具边缘的任何特征,我们对原始面具进行了侵蚀操作。此外,我们使用RANSAC对每个平面的特征进行单独的平面同构模型,以抛弃任何异常值。这些离群值可能是由KLT光流算法的不正确匹配产生的特征,或者是不属于更大的父平面的不准确的片段。图像帧之间的原始IMU测量值被转换为预集成测量值,具有足够视差和特征轨迹的图像帧被选作关键帧。
3.初始化
视觉-惯性滑窗优化在给定状态初值下通过迭代求解。为了获得一个良好的初始估计,而不对起始配置做任何假设,使用了一个单独的松耦合初始化程序,其中视觉测量和惯性测量被分别处理成各自的位姿估计,然后对齐求解其中未知参数。我们首先求解相机位姿、三维点和平面参数。从一个初始图像帧的窗口中,选择两个具有足够视差的基本帧。在它们之间的所有关联上的特征中,我们选择产生于场景中最大平面的匹配点对。我们将具有最多特征的平面确定为最大的平面。利用这些对应关系,我们使用RANSAC拟合了一个与两个相机位姿和最大平面相关的平面单应性矩阵H。将单应性矩阵H归一化后使用OpenCV中已经实现的Malis和Vargas的分析方法将其分解为旋转、平移和平面法向量。然而,该方法最多可以返回四个不同的解,这些解必须进行条件判断筛选。我们首先通过强制执行正深度约束将这个解集减少到两个,也就是说,所有的平面特征必须位于相机的前面。这个约束实现为:
即使IMU预积分旋转内部的陀螺仪偏置还没有被估计出来,但因为其幅度通常很小,不会特别影响结果。分解出的位姿用来对两个基本帧之间的对应特征点进行三角化,获得一个初始点云。窗口内其余帧的位姿使用PnP进行估计。在此注意到由于两个基准帧之间的位姿是以平面距离d为尺度的,所以三角化的点云和推导出的位姿也具有相同的尺度。所有的位姿随后被送入一个BA优化中,除了标准的3D-2D重投影残差外,我们还包括以下由平面单应性产生的2D-2D重投影残差。
用平面单应性矩阵从第一帧中映射其对应的图像位置ul得到的。BA的输出是按尺度(d)得到的相机位姿和三维点,以及平面法向量。这些经过BA调整的视觉估计仍然不足以初始化,因为还需要估计未知的尺度、重力矢量、速度和IMU的偏置。这些参数的估计方法与VINS-Mono中一致。视觉估计和IMU预积分之间尺度因子是到最大平面的距离d。加速计的偏置,通常需要更多的测量,为了将初始化时间限制在2秒以内,没有进行解算。一旦所有的惯性量被估计出来,相机位姿和三维特征点被重新缩放为公制单位,世界坐标系被重新对齐,使其Z轴处于重力方向。对于场景中除最大平面外的其他平面,包括操作过程中可能新观察到的平面,我们同样计算它们各自的平面单应性矩阵并对其进行分解。但我们避免重新进行视觉BA,以及用IMU测量值重新调整它们的位姿,以及估计它们的尺度dp。我们直接将dp估计为每个分解的平移tp与对应公制平移tp的反比,这在之前已经用最大的平面和惯性测量进行了估计。有了这个结果,当前状态下的所有视觉和惯性量都已进行求解,这些估计值被送入滑窗内作为优化的初始种子点。
4.滑窗优化
批量优化位姿、地图点、惯性测量和平面参数的整个历史结果不能保证实时性,所以采用一个固定大小的滑窗进行优化。优化目标函数如下所示:
系统构建的因子图如上图所示,整个非线性目标函数通过使用Ceres Solver中实现的Dogleg算法和Dense-Schur线性求解器迭代求解。在优化结束时,窗口向前移动一帧以纳入最新帧。最新帧的状态是通过传播前一帧的惯性测量值进行初始化。如同VINS-Mono中的做法,丢弃的帧被边缘化。而优化后的平面参数并没有被丢弃或边缘化,而是在再次观察到该平面时重新使用。
5.平面分割
为了从每个输入的RGB图像中分割出平面,文章基于Pane-Recover实施。他们的模型使用结构约束进行训练,以同时预测平面分割掩码和它们的三维参数,只有语义标签,没有明确的三维标注。该模型在单个Nvidia GTX Titan X (Maxwell)GPU上能以30 FPS运行适合于实时VIO。尽管他们的模型很有效,但我们在实验中注意到,预测的片段往往不连续,单一的大平面被分割成多个独立的平面。为了克服这个问题,我们引入了一个额外的损失函数,将之间相对方向小的平面约束为一个平面。
有了这个新增的损失函数,我们用他们提供的来自SYNTHIA的训练数据重新训练网络,另外我们还对室内ScanNet数据集的两个序列(00,01)进行训练。为了进一步改善分割的边界细节,我们采用随机场模型来完善网络的分割结果。下图显示了我们在评估中使用的一个未见过的实际场景的分割结果。
在这一节中,我们描述了如何从场景中检测和跟踪平面特征,如何利用IMU将平面单应性矩阵分解成各自的运动和平面估计,以及如何将平面参数作为附加约束引入初始化和滑窗优化中。在下一节中,我们展示了这种方法在动态环境中的有效性。
Experiments
1.自建仿真数据集
RPVIO模拟数据集是我们生成仿真数据集,其中有准确的轨迹帧值,并且在整个序列中有足够的IMU激励。我们逐步在这些序列中加入动态元素,并使它们在序列的所有部分都可见,甚至在初始化期间也是如此。这使我们能够分离出它们对整个系统精度的影响。四旋翼飞机被控制沿着半径为15米的圆圈移动,同时沿着垂直方向的正弦波移动。沿着高度的正弦激励是为了确保非恒定的加速度,并保持尺度的可观性。我们进一步命令它在开始运动时,进行垂直加速,以帮助初始化。总的轨迹长度为200米,持续时间为80秒,最大速度为3米/秒。在四旋翼飞机形成的圆圈内,我们引入了正在进行重复性舞蹈运动的动态人物。我们在每个序列中逐步加入更多的动态角色,其他都是固定的,从静态场景开始,到8个动态物体,总共记录了6个序列。四旋翼飞机的偏航方向也是固定的,以保持相机指向圆心,这样,在整个序列中,人物都在相机的视野范围内。四旋翼飞机和人物是通过程序控制的,以确保他们的运动在所有序列中都是同步的。VINS-Mono、Mask-VINS和RP-VIO在静态和存在一个动态物体的序列上表现相似。因为静态点的数量远远大于动态点的数量,RANSAC的效果与应用Mask相同。在存在两个动态物体序列中,我们注意到VINS-Mono的精度比Mask-VINS和RP-VIO低得多,而Mask-VINS和RP-VIO的精度相似。当其中一个动态物体太相机时,VINS-Mono在初始化过程中积累了大部分的误差,如下图所示,
然而,在存在4(C4)个、6(C6)个和8(C8)个动态物体的序列中,VINS-Mono完全跟丢。在C4和C6中,Mask-VINS和RP-VIO仍然能够成功跟踪,但RP-VIO-Single是精度较高,这表现出了增加的单应性约束在改善鲁棒性方面的作用。在C8序列中,我们的仍然能够像其他序列一样成功跟踪,但Mask-VINS完全跟丢。这可能是因为场景非常杂乱,剩下的少数特征只来自初始化时的单一平面,这对VINS-Mono的基于基本矩阵的SfM初始化来说是一种退化的情况。在这个序列中,RP-VIO-Multi显示出比RP-VIO-Single更好的准确性,这可能是RP-VIO-Multi相较于RP-VIO-Single有更多的观测。
2.标准数据集
我们在VIODE、OpenLORIS-Scene、ADVIO三个序列上评估了我们系统的鲁棒性。第一个数据集使用AirSim生成的,是一个有许多移动车辆的户外城市环境中拍摄的,由一架正在进行包括急剧旋转在内的无人机拍摄。我们使用他们提供的分割图像,只沿着道路追踪特征。第二个数据集是在现实世界的超市里从一个扫地机器人上采集的,其中包含许多动态的人物,如移动的人、手推车等。第三个数据集是在一个真实世界的地铁站里用手持智能手机拍摄的,是三个序列中视觉上最有挑战性的一个,它的视野很窄,动作很快,动态人物的形式是一辆移动的火车和移动的人。其中VIODE序列的总长度为166米,OpenLORIS序列为145米,而ADVIO序列为136米。我们对三个序列使用我们方法的单平面版本进行测试。我们使用了与仿真实验相同的特征参数,没有进行任何调整。其与GT和其它方法相比得到的RMSE误差如下表所示:
在这里,由于在所有三个序列中,所有被遮挡的特征主要来自一个平面,我们没有与先前评估中使用的Mask-VINS进行比较,因为来自一个平面的特征对VINS-Mono初始化来说形成了一个退化情况。没有一个现成的语义分类器可以准确地分割两个序列中的所有动态物体,这也使得不能近似公平的对比。ADVIO序列中的图像具有非常高的分辨率1280×720,采集频率为60HZ,这导致了VINS前端的大量丢帧。出于这个原因,对这个序列的评估是在一个更强大的CPU上运行的,它有32GB内存和一个SSD。
讨论:
我们的方法在所有三个序列上都比VINS-Mono有明显的提升。在OpenLORIS和VIODE序列中,我们的方法使用了比VINS-Mono更少的特征但得到了更高的准确性。这使我们相信,与跟踪所有可能的特征相比,跟踪少数稳定的特征可能就足够了,因为其中许多特征可能是有噪声的。在这两个真实世界的序列中,尽管使用的是没有经过图像训练的通用平面检测网络,但该网络和CRF能够提供可靠的平面分割,足以让我们的方法准确跟踪。如果有训练数据,我们希望能有更准确的分割和更好的整体轨迹估计。对于包含动态平面的场景,如车辆,必须训练并使用特定的地面或墙壁表面分类器。但对特定的平面进行训练仍然比对所有可能移动的物体类别进行语义分类器的训练更可行。我们的方法应该被认为是对通用的基于点的系统的补充,而不是作为一个完全的替代。
Conclusion
我们提出了一个单目VIO系统,该系统只使用环境中的一个或多个平面以及它们的结构规律性来进行动态环境中的精确位姿估计。我们在不同的仿真和实际动态环境中验证了其提升性能,同时在静态场景中评估了它与baseline相同性能。对于现实世界的环境,只使用一个通用的平面分割模型,我们得到比最先进的单目VIO系统精度提高了45%。在我们与Mask-VINS的比较中,我们的方法比简单的动态特征剔除方法取得了更好的准确性,这意味着了增加的结构约束在提高鲁棒性方面的作用。这项工作的未来范围是将其扩展到一个完整的SLAM系统中,以获得干净和一致的基于平面的地图,没有任何平面外的噪声特征,这反过来可以用来进一步改善运动估计。此外,还可以研究来自分割模型预测的三维平面参数是否可以直接用于改进初始化。该方法还可以扩展到包括从分割的平面中产生的相应的线特征约束融合到系统中。
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:CV_LAB,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK