

QCon-OPPO大规模CV预训模型技术及实践
source link: https://my.oschina.net/u/4273516/blog/5334567
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

QCon-OPPO大规模CV预训模型技术及实践 - OPPO数智技术的个人空间 - OSCHINA - 中文开源技术交流社区
1 什么是预训练模型?为什么我们需要预训练模型?


那么我们为什么需要预训练模型呢?在这里做一个比喻,如果把深度学习算法比作武侠的话,那预训练模型就是他的内功,有了扎实的内功基础,就能够更容易、更快速的掌握各种武功招式,并发挥其最大效用。预训练模型的过程就是深度学习算法修炼内功的过程。
2 OPPO自研大规模cv预训练模型
2.1 概述
之所以要自研预训练模型主要是两点原因:首先,当前数据科学家们使用的预训练模型都是网上开源的,每年都有变化,最新的一些研究往往不开源,无法保证效果最优;其次就是网上开源的预训练模型,都是基于开源数据集数据集训练得到的,比如大家熟知的imagenet。没有充分利用公司自有数据的优势。因此,自研预训练模型是十分有意义的。
OPPO自研大规模cv预训练模型技术方案主要包括以下三大部分:
1)网络架构创新:主要是研究当前cv界主流模型架构如CNN,Transformer和MLP等,对不同结构当前SOTA的网络架构进行组合、优化的探索,尽可能的得到性能最优的网络架构作为预训练模型的主干网络。
2)自监督学习训练:主要是希望能够充分利用oppo自有的海量无标注数据,在海量无标注数据下进行预训练,从而得到更加通用的特征表达,让模型能够更好地克服OOD(与训练集分布不同)情况,得到更加鲁棒的预训练模型。
3)有监督微调训练:当利用具体的任务数据集(标注样本)对预训练模型的网络参数进行微调训练时,使用合适的训练方法及正则方法,可以使模型在具体下游任务达到最优效果。
2.2 关键技术
2.2.1 网络架构设计
在网络架构方面,我们的目标是设计合适的网络架构,缩小特征探索空间,提升网络性能。为了能够更适合接入不同的稠密场景视觉任务,我们的网络架构需要设计成一种多阶段的层次结构来提供多尺度的特征图,并且我们的网络要易于拓展成不同参数量级的变体模型,以满足不同业务场景的需求同时要在参数量和浮点数计算量更低的条件下尽可能的提升网络的性能。
当前计算机视觉领域三大主流模型架构包括卷积神经网络CNN,Transfomer以及多层感知机MLP。其中CNN多年来一直是计算机视觉任务中占据主导地位的网络架构,CNN擅长提取局部细节特征,并且具有形变、平移及缩放不变性等优点。Transformer在NLP领域取得了巨大的成功,去年首次在CV界亮相开始引领新的趋势,Transformer的优点是擅长捕获全局信息, 具有更大的模型容量,且其运作机制更接近人类。在Transformer崛起的同时,一部分研究聚焦于MLP替代Transformer组件构建网络的研究,开辟了另一个研究方向,MLP 在小的模型规模下可以实现接近Transformer的性能,但当规模扩大时,它就会受到严重的过拟合影响。
通过对这三种主流模型架构进行研究分析后,我们得到了以下一些结论:对于MLP 来说,它的研究聚焦在替换 Transformer组件来获得相对有竞争力的结果,但是实际效果并没有超越基于transformer的方法,这系列工作只是一定程度上开拓了一个新的思路。CNN中的卷积操作擅长提取图片的局部信息,而Transformer通过构造图像tokens提取到图片的全局表示,因此CNN和Transformer在一定程度上可以形成良好的互补。还有就是Transformer 在三种架构中具有最大的模型容量,更适合做大规模预训练模型。因此,Transformer 加 CNN的架构或许是最优的解决方案。
既然我们要聚焦于Transformer方法,我们就先要对Transformer的基本原理有一定的了解,以便对其进行改进。所以接下来我先对Transformer进行简单介绍。Transformer结构是google在17年的Attention Is All You Need论文中提出的,在NLP的多个任务上取得了非常好的效果。它最大特点是整个网络结构完全是由Self-Attention机制组成。如图一所示,Transformer采用Encoder-Decoder结构,输入经过 embedding后,要做位置编码,然后是多头自注意力机制,再经过Feed Forward,每个子层有残差连接,最后要经过Linear和softmax输出概率。
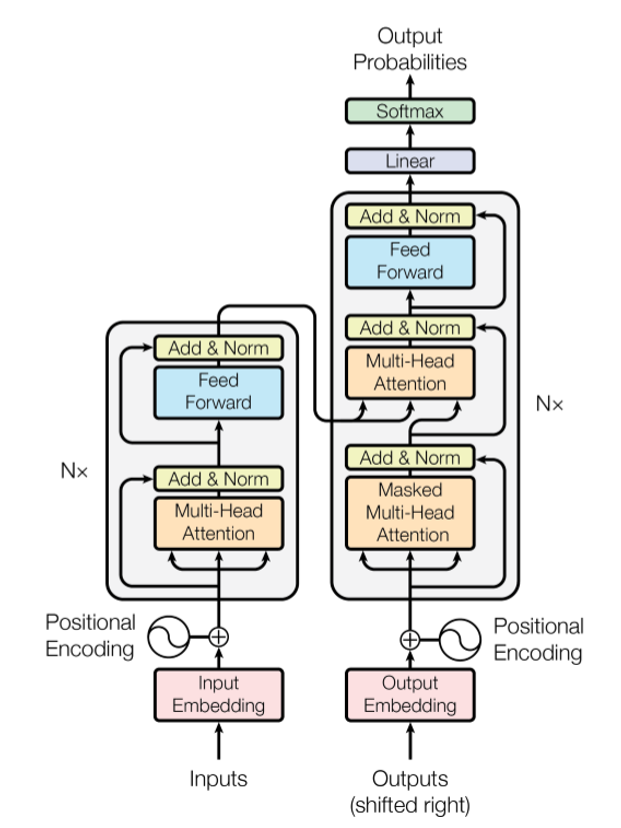
图1 Tranformer 模型结构
1)残差结构是为了解决梯度消失问题,可以增加模型的复杂性。
2)其中的Norm指的是LayerNorm操作,LayerNorm是为了对attention层的输出进行分布归一化。计算机视觉中经常会用的batchNorm是对一个batchsize中的样本进行一次归一化,而LayerNorm则是对一层进行一次归一化,二者的作用是一样的,只是针对的维度不同。
3)Feed Forward是两层全连接加激活函数的结构。是为了使用非线性函数来拟合数据。其中第一层全连接用来进行非线性性函数拟合,第二层全连接用于调整输出维度。
4)加入位置编码(Positional Encoding)主要是由于self-attention机制没法捕捉位置信息,因此需要通过位置编码来改善。
Transformer结构中我们最需要关注的是self Attention机制的原理,所谓Self Attention就是句子中的某个词对于句子本身的所有词做一次Attention。当以一个词为中心进行Self Attention时,每个词都要通过三个矩阵Wq, Wk, Wv进行一次线性变换,一分为三,生成每个词自己的query, key, value三个向量,也就是公式中的大Q,K,V,然后通过如下公式进行计算,作为这个词的输出。最终每个Self Attention接受n个词向量的输入,输出n个聚合的向量。这么做的目的是保留关注词的value值,削弱非相关词的value值。
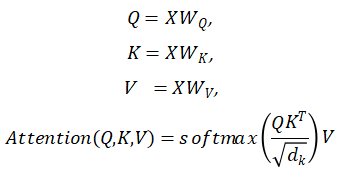
而Multi-Head self- Attention就是将上述的Attention做h遍,然后将h个输出进行concat得到最终的输出。Transformer的工程实现中,为了提高Multi-Head的效率,将W扩大了h倍,然后通过reshape和transpose操作将相同词的不同head的Q、K、V排列在一起进行同时计算,完成计算后再次通过reshape和transpose完成拼接,相当于对于所有的head进行了一个并行处理。到此为止我们对Transformer结构有了初步的了解。
在20年,提出的ViT是首个基于纯Transformer的结构来做图像分类任务的网络,算是transformer在图像上应用的开山之作,后续所有基于Transformer的网络架构都是基于此模型进行的改造。
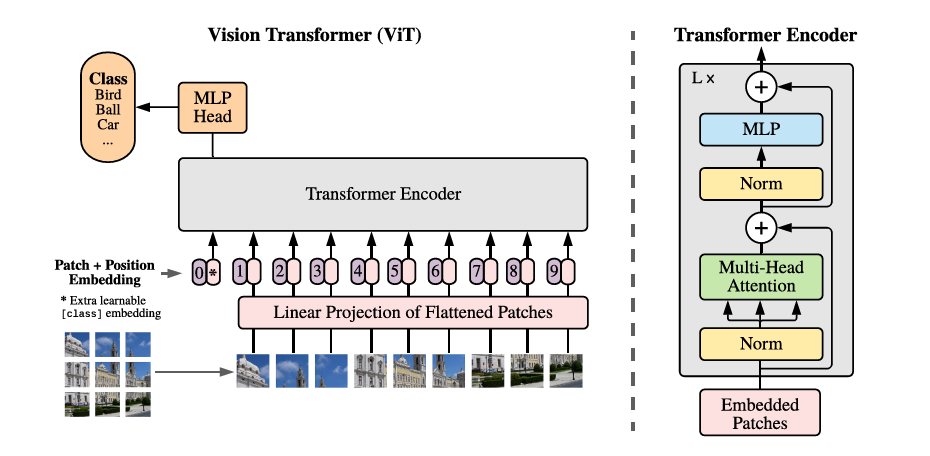
图2 Vision Transformer
ViT的结构如图二所示,它就是前面讲到的一个典型的Transformer结构:
首先将一张的图像,分成互不交叠相等大小图像块,然后将每个图块进行展平并对每一个展平后的图块向量做一个线性变换进行降维,作为Transformer的输入。这里的每一个图块就是一个Token,也就是NLP中句子中的一个词。
ViT给输入的Token追加了一个分类向量,用于Transformer训练过程中的类别信息学习,与其他图块向量一起输入到Transformer编码器中,最后取第一个向量作为类别预测结果。
为了保持输入图像块之间的空间位置信息,对图像块中添加一个位置编码向量,这种在进行self-attention之前就加入了位置信息的方式叫做绝对位置编码,后面还会对位置编码进行一些介绍,此处不再赘述。
由于ViT是一个非层次结构的网络,不适合用于稠密场景的视觉任务,并且计算复杂度相对较高。在后续的研究中,研究者们用各种办法去从不同的角度对他进行改进。
那么我们是如何做的呢?
第一点,我们希望得到一种更通用的主干网络架构,而不是针对不同的视觉任务设计不同的网络,因此要设计一种层次结构的网络,可以提供多尺度的特征图。实现层次结构的方式可以采用pixelShuffle, 卷积降采样等手段,来调整特征图尺度与输出维度,从而得到多个阶段的层次结构网络;
第二点,我们要对对注意力机制进行改造。原始的Transformer在计算注意力机制时需要计算一个Token与其他所有Token之间的关系,计算复杂度为Token数量的二次型。为了能更高效的建模,部分研究对注意力机制的计算进行了改造,主要包括:halo,shifted window,CrossShape等;
第三点就是将Transformer与CNN进行有效的融合。视觉任务中局部特征建模是非常有效且至关重要的,而局部特征建模是CNN所擅长的。已有研究证实,以适当的方式叠加卷积层和Transformer层,可以有效地提升网络的整体性能。也有研究将卷积融入到Transformer中,用卷积代替线性变换来计算Q,K,V矩阵,可以使Transformer对局部特征的建模能力得到提升。最后是对位置编码的改进。由于自注意力机制具有排列不变性,即不同排列的输出结果是一样的。为了弥补这个缺陷。如图三(a)所示,绝对位置编码是在进行Self-attention之前就加入了位置信息。图三(b)所示为相对位置编码,是在计算权重矩阵的过程中加入相对位置信息。图三(c)所示为位置增强编码,它直接将位置信息加入到Value中,具体实现是用一个Depth-wise Conv对value进行卷积,然后将结果加入到了self attention的结果中。

图3 位置编码
对于我们的网络架构,可以看做是一个四个阶段的体系结构:
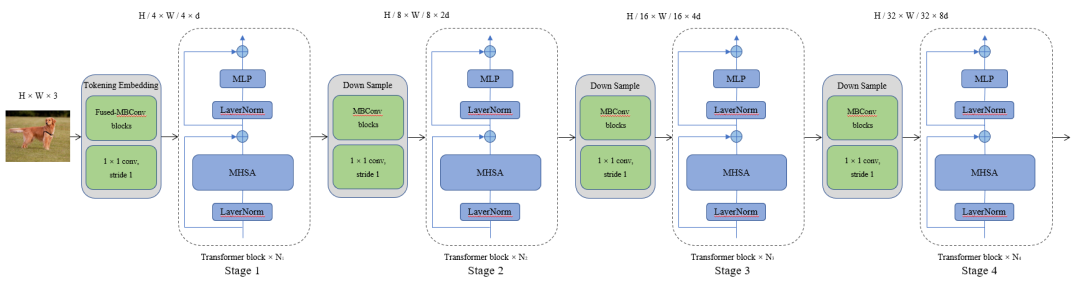
图4 OPPO的网络架构
首先通过一组卷积序列对图像进行分块操作生成Tokens,为了产生层次表示,相邻的两个阶段之间我们采用另一组卷积序列是Tokens数量减半,通道维数加倍。这样就产生了多阶段的层次结构,可提供多尺度特征图,方便作为主干网络接入到稠密场景视觉任务中。
从与CNNs结合的角度去看,可以看做是一个多阶段Transformer模块与一个EfficientNetV2-like的结构嵌套组合而成,实现了卷积与Transfomer的有效融合,在模型参数量和浮点数计算量更低的情况了大幅提升了网络性能。
在计算多头自注意力时,我们使用改进的计算机制,shifted-window + conv 和CrossShape两种方法,提升Trasnformer计算效率的同时,网络性能也得到了进一步提升。
对于位置编码部分我们使用了相对位置编码和局部增强位置编码两种方式,经实验验证这两种位置编码方式在分类任务上基本无差别,但在稠密场景任务(如检测、分割等)时,局部增强位置编码性能更优。
最后我们通过不同的深度或宽度的配置,设计了三组不同量级的模型架构:Tiny模型,Small模型 和 Base模型,以适应不同业务场景的需要。
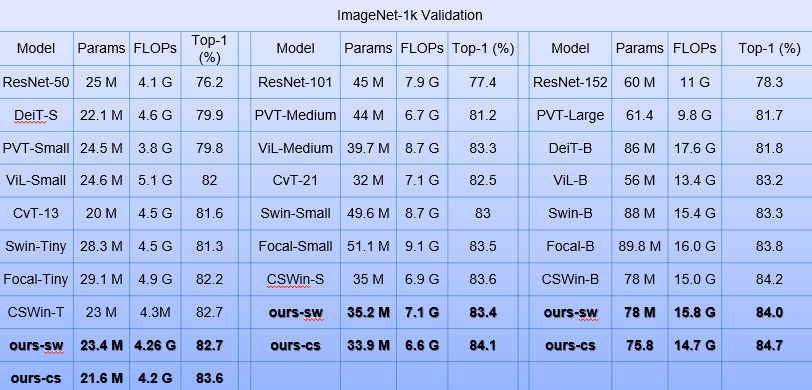
表1 OPPO的网络在ImageNet数据集上的表现
表1是我们的网络架构在Imagenet数据集上的表现,我们分别与不同参数量级下最新的网络架构进行了对比,可以看到我们设计的网络架构在参数量更低、计算量更小的情况下,三种量级的变体模型都能取得最优的成绩。
2.2.2 自监督学习
接下来介绍预训练模型的另一个关键技术自监督学,所谓自监督学习就是无监督学习的一种。在第 43 届国际信息检索年会深度学习之父上Hinton 提出下一代人工智能属于无监督对比学习。对于三种学习任务Hinton的得意弟子Yann LeCun将其比作蛋糕,强化学习仅仅是蛋糕上的一颗樱桃,有监督学习可比作蛋糕上的奶油,而无监督学习是蛋糕胚,以示其基础性的作用和重要性。
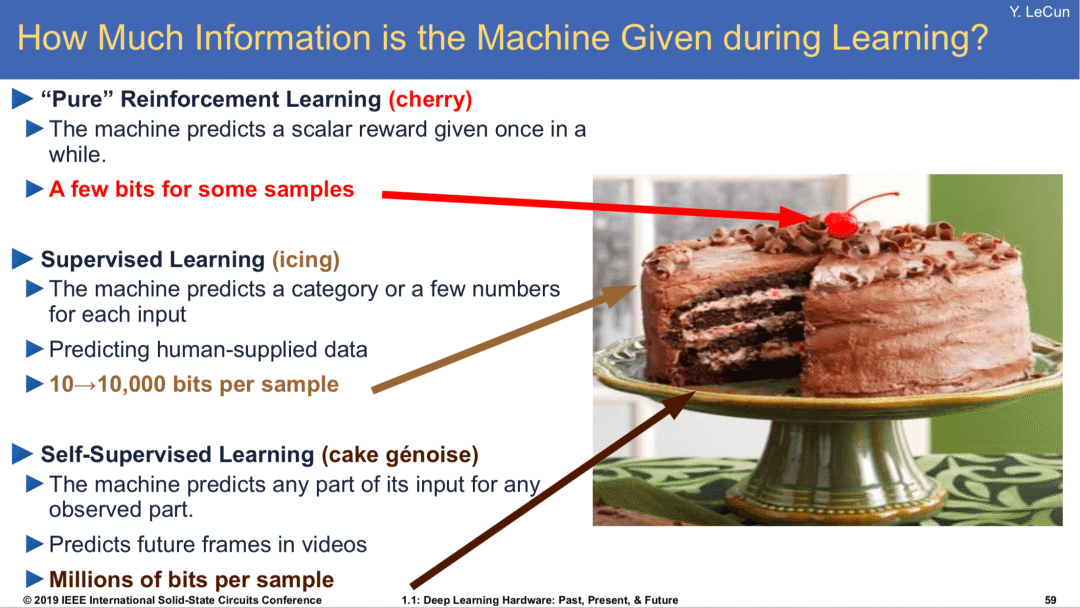
图5 三种学习方法比作蛋糕
以我们人类为例,当我们看到一个东西的时候,所有的知觉都潜移默化地在给我们灌输海量的数据,供我们学习,推理和判断。我们遇到的“题目”很多,无时无刻不在接受信息,但是我们的“答案”却很少。我们可能看过,各种各样的动物,直到某一天才有人用3个字告诉我们,“这是猫”。可能一生中,别人给你指出这是猫的次数,都是屈指可数的。但是,仅仅通过这一两次提示,你就能在一生中记得这些概念。甚至别人从不告诉这是猫,你也知道这应该不是狗或者其他动物,这种没有答案的学习就是无监督学习,别人告诉了我们答案的学习就是有监督学习,可见无监督学习的基础性是多么重要。由于监督学习严重依赖于人工标注数据,而我们希望神经网络能够在大量无标注数据中学习到更多内容,从而提高数据学习效率以及模型泛化能力,因此将基于自监督学习的预训练改进作为重点方向之一。
自监督学习可以分为基于Pretext Task的方法、基于Contrastive Learning的方法、基于Clustering的方法和基于Contrastive + Cluster的方法。基于Pretext Task的方法让神经网络去解决一个pretext task,在这个过程中模型能够学习到丰富的特征表示,然后用于下游任务但是只靠单个前置任务来学习特征表示将不是最好的选择并且不同前置任务之间的设计差异非常大,难度也不相同。基于Contrastive Learning的方法通过将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示,由于需要显示的去对pair对进行feature级别对比导致计算量非常大。基于Clustering的方法在特征空间进行聚类,看下哪些图片在特征空间上是相像的,特征聚类 + 预测集群分配,根据image feature在全部数据集做cluster(codes),在一个训练step中会对很多image views做cluster,这种方法通常需要扫很多遍数据集。我们主要基于facebook的最新研究SwAV方法对模型进行自监督学习预训练改进,它是一种基于Contrastive + Cluster的方法。
SwAV方法与之前的一些对比学习方法的不同之处,主要就是在features对比,SwAV使用了一个codes去表达features进而来保持一致性。
通常基于clustering法一般是根据image feature在全部数据集做cluster(codes),在一个训练step中会对很多image views做cluster。而Swav方法并不考虑用codes作为目标,而是通过一张图片不同的views的codes需要保持一致来进行学习,可以理解为是一张图片的多个不同views需要对应相同的code而不是直接用他们feature来做。
训练主要包括两部分:
z(features)如何通过c(prototypes)映通过射得到Q(codes);
有了 z 和 q 之后,理论上同一张图片不同view所产生的 z 和 q 也可以相互预测,于是作者便定义了新的loss如公式所示。

其中z是feature,q是codes,s和t下标表示通过不同的augmentations对image进行转换的,而分项loss的计算公式为:
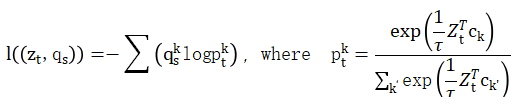
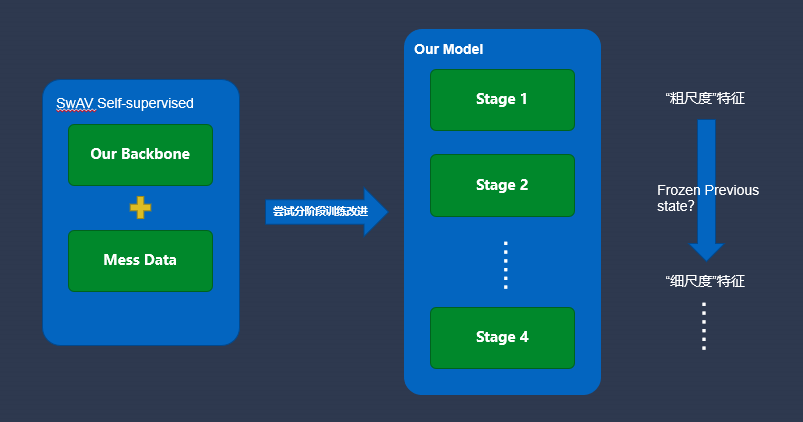
图6 自监督学习分阶段训练
我们主要采用SwAV方法对我们的设计的网络架构进行自检自监督学习预训练。并尝试“分阶段训练”的方式,将学习过程分解为逐步完成的相关子任务,逐步将信息注入网络,以便在训练的初级阶段捕获数据的“粗尺度”特征,而在后续阶段学习“细尺度”特征,并且每个阶段的训练结果都可以作为下一阶段的先决条件,这样会产生正则化效果并增强泛化能力。目前这一部分的工作目前还在进行中,性能统计结果即将到来。
2.2.3 有监督微调
视觉模型的性能是网络架构、训练方法和正则方法的综合结果,在做具体任务时,有监督微调旨在利用其标注样本对预训练网络的参数进行调整。加载网络结构并利用预训练好的权重去初始化网络后需要设置合理的超参配置、优化方法、数据增强方法、和正则方法等。新的网络架构往往是促成诸多进展的基础,与新网络架构同时出现的通常还有更加先进的训练方法、数据增强方法和正则方法等。此处仅对一些过去和近期新出现的方法进行列举,针对具体的视觉任务,可根据自己经验或他人已有的经验进行配置。
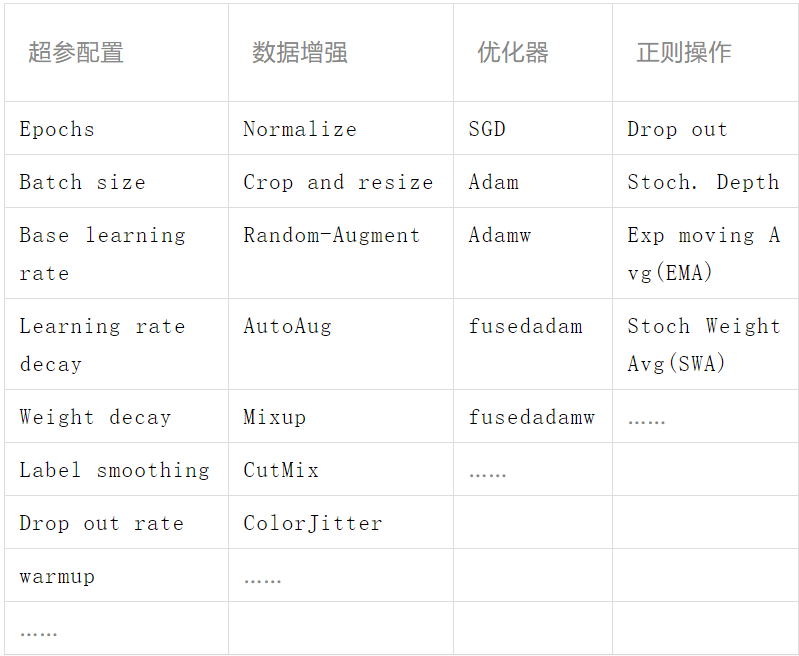
表2 有监督微调配置
3 业务应用
目前我们寻找了两个内部已有业务,尝试使用我们的预训练模型对齐进行优化升级,主要包括主题资源风格全场景打标和PGC小视频一二级分类。在主题资源风格全场景打标业务中,使用了我们的tiny预训练模型来做主题风格多标签分类任务;与原始基于EfficientNet的版本相比,模型的参数量和浮点数运算量仅小幅增加的情况下,打标准确率由87.7%提升到95%,大幅提升了7.3%。另外在PGC小视频一二级分类业务使用base预训练模型+BERT来做多模态融合分类;
小视频一二级分类精度与原方法相比均得到了提升,一级精度由86.5%提升到89.7%,提升了3.2%;二级精度61.6%提升到75.4%,提升了13.8%。充分的验证了我们预训练模型的有效性及业务价值。
4 总结
预训练模型是深度学习网络架构 + 海量数据上训练好的权重,是提升某一具体任务算法性能的一种常用手段。预训练模型的关键技术包括:网络架构、自监督预训练和有监督微调,各部分都有很多值得研究的地方。另外,不同业务场景需要的预训练模型规模往往不同,需要设计多种变体模型分别进行预训练,以实现预训练模型应用到更多的业务当中实现更多的价值。
5 参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
[2] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, ylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[3] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learningof visual features by contrasting cluster assignments.
arXiv preprint arXiv:2006.09882, 2020.
作者简介
Darren OPPO高级算法工程师
深耕计算机视觉算法领域多年,目前专注于cv模型架构与训练方法研究。
PS: 回复本公众号“OPPO QCon”
即可获取OPPO QCon专场"OPPO亿级用户背后的技术创新实践"PPT。
本文版权归OPPO公司所有,如需转载请在后台留言联系。本文分享自微信公众号 - OPPO互联网技术(OPPO_tech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK