

Implementing Hash Tables in C
source link: https://www.andreinc.net/2021/10/02/implementing-hash-tables-in-c-part-1
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
NOTE: Article is in “draft” status. The content was originally written in 2017.
Table of contentsPermalink
CodePermalink
If you don’t want to read the article, and you just want to jump directly into the code:
git clone [email protected]:nomemory/chained-hash-table-c.git
IntroductionPermalink
Outside the domain of computers, the word hash means to chop/mix something.
In Computer Science, a hash table is a fundamental data structure that associates a set of keys with a set of values. Each pair <key, value> is an entry in our hashtable. Given a key, we can get the value. Not only that, but we can add and remove <key, value> pairs whenever it is needed.
Not be confused with hash trees or hash lists.
In a way, a hash table share some similarities with the average “array”, so let’s look at the following code:
int arr[] = {100, 200, 300};
printf("%d\n", arr[1]);
If we were to run it, the output would be 200. As we write arr[<index>], we are peeping at the value associated with the given <index>, and in our case, the value associated with 1 is 200.
In this regard, a hash table can act very similar to an array, as it will allow us to map a value to a given key. But there’s a catch, compared to an array, the key can be everything - we are not limited to sorted numerical indexes.
Most modern computer programming languages have a hash table implementation in their standard libraries. The names can be different, but the results are the same.
For example in C++, we have something called std::unorderd_map:
#include <iostream>
#include <string>
#include <unordered_map>
int main() {
std::unordered_map<std::string, std::string> colors = {
/* associates to the key: */ {"RED", /* the value: */ "#FF0000"},
{"GREEN", "#00FF00"},
{"BLUE", "#0000FF"}
};
std::cout << colors["RED"] << std::endl;
}
// Output: #FF0000
In the Java world, there’s HashMap:
import java.util.Map;
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
Map<String, String> colors = new HashMap<>();
colors.put("RED", "#FF0000");
colors.put("GREEN", "#00FF00");
colors.put("BLUE", "#0000FF");
System.out.println(colors.get("RED"));
}
}
// Output: #FF0000
Or in languages like python, support for hash tables is “built-in” in the language itself:
colors = {
"RED" : "#FF0000",
"GREEN" : "#00FF00",
"BLUE" :"#0000FF"
}
print(colors["RED"])
# Output: #FF0000
So regardless of the name (unordered_map in C++, HashMap in Java, or dict in python), if we run all three code snippets, the result will be the same: "#FF0000".
Size doesn’t matter.
What is impressive about hash tables is they are very “efficient” in terms of (average) time complexities. Given a key, we can return the value associated with it in(almost) constant time, no matter how many pairs we have previously inserted. So they scale exceptionally well with size. In a way, for a hash table “size doesn’t matter”, as long as we keep things under control:
Think of it for a moment. For a binary tree, searching for an element is O(logn); if the trees grow, n grows, so searching for an element takes more time. But No!, not for hash tables. As long as we know the key, we can have almost instant access to the stored value.
Operation
Average Time Complexity
Worst-case scenario
Getting a value
O(1)
O(n)
Adding a new pair <key, value>
O(1)
O(n)
Updating a pair <key, value>
O(1)
O(n)
Removing a pair <key, value>
O(1)
O(n)
This remarkable data structure is internally powered by clever mathematical functions: called hash functions. They are the “force” behind the fantastic properties of hash tables: the ability to scale even if the number of pairs increases.
At this point, it wouldn’t be wise to jump directly to the implementation of a hash table, so we will make a short mathematical detour into the wonderful world of hash functions. They are less scary than you would typically expect, well, at least on the surface.
Hash FunctionsPermalink
In English, A hash function is a function that “chops” data of arbitrary size to data of fixed size.
From a mathematical perspective, A hash function is a function H:X→[0,M), that takes an element in x∈X and associates to it a positive integer H(x)=m, where m∈[0,M).
X can be bounded or an un-bounded set of values, while M is always a positive finite number 0<M<∞.
Let’s take a look at the following example:
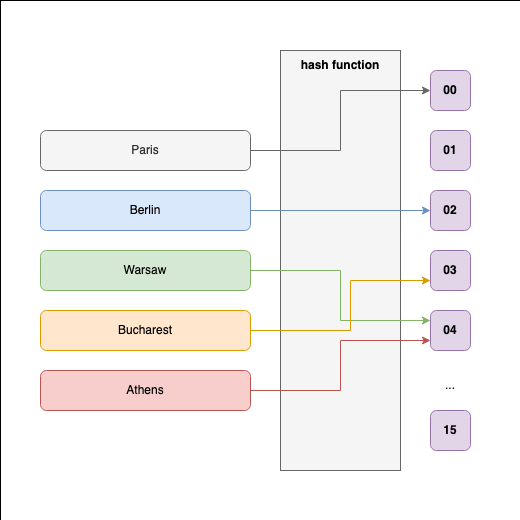
In the above diagram Paris, Berlin, Warsaw, Bucharest, Athens are all capitals that ∈X, where X is a set containing all European Capitals, so n(X)=48.
Our hashing function is H:X→[0,16), so that:
H("Paris")returns00;H("Berlin)returns01;H("Warsaw)returns04;H("Bucharest)returns03;H("Athens")returns04;
In total, there are around 48 countries in Europe, each with its capital. So the number of elements in X is 48, while M=16 so that the possible values are in the interval [0,1,2,...16).
Because 48>16, no matter how we write H, some European Capital Cities will share the same number m∈[0,1,...16).
For our hypothetical example, we can see that happening for H("Warsaw) = H("Athens") = 4.
Whenever we have two elements x1,x2∈X so that H(x1)=H(x2)=mx, we say we have a hash collision.
In our example we can say that H has a hash collision for x1=Warsaw and x2=Athens, because H(x1)=H(x2)=4.
Hash Collisions are not game-breaking per-se, as long as the n(X)>M they might happen. But it’s important to understand that a good hash function creates fewer hash collisions than a bad one.
Basically the worst hash function we can write is a function that returns a constant value, so that H(x1)=H(x2)=...=H(xn)=c, where n=n(X), and c∈[0,M). This is just another way of saying that every element x∈X will collide with the others.
Another way we can shoot ourselves in the foot is to pick a hash function that is not deterministic. When we call H(x) subsequently, it should render the same results without being in any way affected by external factors.
Cryptographic hash functions are a special family of hash functions. For security considerations, they exhibit an extra set of properties. The functions used in hash table implementations are significantly less pretentious.
Another essential aspect when picking the right hash function is to pick something that it’s not computationally intensive. Preferably it should be something close to O(1). Hash tables are using hash functions intensively, so we don’t want to complicate things too much.
Picking the proper hash function is a tedious job. It involves a lot of statistics, number theory, and empiricism, but generally speaking, when we look for a hash function, we should take into consideration the following requirements:
- It should have a reduced number of collisions;
- It should disperse the hashes uniformly in the [0,M) interval;
- It should be fast to compute;
We can talk about “families” of hashing functions. On one hand you have cryptographic hash functions that are computationally complex and have to be resistant to preimage attacks (that’s a topic for another day). Then you have simpler hash functions that are suitable to be used to implement hash tables:
- Cryptographic hash functions;
- All-around / general functions used for hash table implementations:
The advanced math behind hash functions eludes me. I am a simple engineer, no stranger to math, but not an expert. There are PHD papers on the subject, and for a select group of people, this is their actual job: finding better and faster ways of hashing stuff. So, in the next two paragraphs, I will try to keep things as simple as possible by avoiding making things more mathematical than needed.
Division hashingPermalink
The simplest hash function that we can write the mod % operation, and it’s called division hashing.
It works on positive numbers, so let’s suppose we can represent our initial input data x1,x2,...xn∈X⊂N as a non-negative integers.
Then, the formula for our hash function is Hdivision(x)=xmodM, where Hdivision:X→[0,M). In English this means that the hash of a given value x is the remainder of x divided with M.
Writing this function in C is trivial:
uint32_t hashf_division(uint32_t x, uint32_t M) {
return x % M;
};
On the surface, hashf_division() checks all the requirements for a good hashing function.
And it’s a good hashing function as long as the input data (x1,x2,...,xn) is guaranteed to be perfectly random, without obvious numerical patterns.
So let’s test how it behaves if we pick:
M=4;1000000uniformly distributed positive integers as input (X)
Without writing any code, we would infer that all the input will be evenly distributed between 4 hash values: 0, 1, 2 and 3. There are going to be collisions (as n(X) is 250000 bigger than 4), but theoretically, we can reduce them by increasing M further down the road.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define M_VAL 4
#define X_VAL 1000000
uint32_t hashf_division(uint32_t x, uint32_t M) {
return x % M;
};
int main(int argc, char* argv[]){
// initiate rand
srand(time(0));
unsigned int i, hash;
// buckets
int buckets[M_VAL];
for(i = 0; i < X_VAL; i++) {
hash = hashf_division(rand(), M_VAL);
buckets[hash]++;
}
for(i = 0; i < M_VAL; i++) {
printf("bucket[%u] has %u elements\n", i, buckets[i]);
}
}
If we run the above program, a possible output would be:
bucket[0] has 250146 elements
bucket[1] has 249361 elements
bucket[2] has 250509 elements
bucket[3] has 249984 elements
The results are OK:
- All input has been evenly distributed between the four values (buckets);
- The
%operation is quite efficient (although it’s usually two times more expensive than multiplication); - Collisions are there, but they can be controlled by increasing the value
Mto accommodate the input size.
We call the resulting hashes buckets, and once we start implementing the actual hash table, this will make more sense.
But what happens if our (input) data is not that random after all. What if the data follows a particular obvious (or not so obvious) pattern? How is this pattern going to affect the distribution of computed hashes?
Let’s change this line:
hash = hashf_division(rand(), M_VAL);
To this:
hash = hashf_division(rand()&-2, M_VAL)
Now, all our randomly generated numbers will be even. If that’s not an obvious pattern, I don’t know what is.
Let’s see how our hashing function behaves in this scenario and how well the hashes are distributed:
bucket[0] has 500810 elements
bucket[1] has 0 elements
bucket[2] has 499190 elements
bucket[3] has 0 elements
We see that values 1 and 3 are never used, which is unfortunate, but a normal consequence normal of the way our input was constructed. If all the input numbers are even, then their remainder is either 0 or 2.
Mathematically we can prove there’s not a single xi∈X⊂N, for our function Hdivision(x)=xmod4, where H:X→[0,4), so that Hdivision(xi)=1 or Hdivision(xi)=3.
So this means our function is not so good after all because it’s extremely sensitive to “input patterns” ?
Well the answer is not that simple, but what’s for sure is that changing M=4 to M=7 will render different results.
This time, the output will be:
bucket[0] has 142227 elements
bucket[1] has 143056 elements
bucket[2] has 143592 elements
bucket[3] has 142721 elements
bucket[4] has 142722 elements
bucket[5] has 142662 elements
bucket[6] has 143020 elements
The results look promising again. The hash values are again “evenly” distributed, but all kinds of (subtle) problems can appear based on our choice of M.
Normally, M should be a prime number, and some prime numbers will work in practice better than others, e.g.:
H′division(x)=xmod127H″division(x)=xmod511H‴division(x)=xmod2311
To make the results even better, Donald Knuth, proposed an alternative solution, where HKnuthdivision(x)=x(x+3)modM.
In practice, division hashing is not that commonly used. The reason is simple, even the results are satisfactory (especially when M is chosen wisely), division and modulo operations are more “expensive” than addition or multiplication.
Multiplicative hashingPermalink
A common (and practical) approach for generating relatively uniform hash values is called multiplicative hashing.
Similar to division hashing, the formula works for positive integers. So we assume that we have a mechanism that converts our input space to positive numbers only.
The following formula usually describes a multiplicative hash function:
Hmultip(x)=MW∗(AxmodW), where Hmultip:X∈N→[0,M).
- A∈R+∗ is a constant;
- M is usually a power of
2, so that M=2m. - W=2w, where w is the machine word size. In C we can look for the max value of an
unsigned intin the header filelimits.h:UINT_MAX. In this caseW=UINT_MAX+1.
So our function becomes:
Hmultip(x)=2m2w∗(Axmod2w)=2m−w∗(Axmod2w)=Axmod2w2w−m
By the magic of bitwise operations, Axmod2w is just a way of getting the w low order bits of Ax. Think of it for a second, x % 2 returns the last bit of x, x % 4 returns the last 2 bits of x, etc.
Dividing a number b by 2w−m actually means shifting right w-m bits. So our method actually becomes:
Hmultip(x)=A∗x >> (w−m)
If we were to write this in C:
uint32_t hashf_multip(uint32_t x, uint32_t p, uint32_t w, uint32_t m, uint32_t A) {
return (x * A) >> (w-m);
}
I won’t get into all the mathematical details, but a good choice for A is A=ϕ∗2w, where w is the word machine word size, and ϕ (phi) is the golden ratio.
ϕ, just like its more famous brother π (pi), is an irrational number, ϕ∈Q′, that is a solution to the equation: x2−x−1=0=>ϕ≈0.6180339887498948482045868343656.
Depending on the word size, A can be computed as follows:
w A=2w∗ϕ≈ 16 40,503 32 2,654,435,769 64 11,400,714,819,323,198,485
When we pick A=ϕ∗2w, our general multiplicative hash function is called a Fibonacci hash function.
Having this said, we can now simplify the signature of our C function. We don’t need A, m, w anymore as input params because they can be #defined as constants.
After the signature change, our function becomes:
#define hash_a (uint32_t) 2654435769
#define hash_w 32
#define hash_m 3
uint32_t hashf_multip(uint32_t x, uint32_t m) {
return (x * hash_a) >> (hash_w - m);
}
As it’s mentioned here, Fibonacci Hashing has one “small” issue. Poor diffusion happens as higher-value bits do not affect lower-value bits. In this regard, it can further be improved by shifting the span of retained higher bits and then XORing them to the key before the actual hash multiplication happens:
#define hash_a (uint32_t) 2654435769
#define hash_w 32
#define hash_m 3
uint32_t hashf_multip2(uint32_t x, uint32_t m) {
x ^= x >> (hash_w - m);
return (x * hash_a) >> (hash_w - m);
}
With hashf_multip2(), we achieve better diffusion with a price: more operations.
Hashing stringsPermalink
Converting non-numerical data to positive integers (uint3_t) is quite simple. After all, everything is a sequence of bits.
In K&R Book (1st ed) a simple (and ineffective) hashing algorithm was proposed: What if sum the numerical values of all characters from a string?
uint32_t hashf_krlose(char *str) {
uint32_t hash = 0;
char c;
while((c=*str++)) {
hash+=c;
}
return hash;
}
Unfortunately, the output for hashf_krlose will be “extremely” sensitive to input patterns. It’s easy to apply a little Gematria ourselves to create input that will return the identical hashes repeatedly again.
For example:
char* input[] = { "IJK", "HJL", "GJM", "FJN" };
uint32_t i;
for(i = 0; i < 4; i++) {
printf("%d\n", hashf_krlose(input[i]));
}
The hash values for "IJK", "HJL", "GJM", "FJN" are all 222.
A proposal to improve the function is to replace += (summing) with ^= (XORing), so that hash+=c becomes hash^=c. But again, patterns that break our hash function are easy to create, so it doesn’t make a big practical difference.
The good news is that there’s a common type of hash function that works quite well with strings (char*).
The template for those functions look like:
#define INIT <some_value>
#define MULTIP <some_value>
uint32_t hashf_generic(char* str) {
uint32_t hash = INIT;
char c;
while((c*=str++)) {
hash = MULTIP * hash + c;
}
return hash;
}
djb2Permalink
If INIT=5381 and MULT=33, the function is called Bernstein hash djb2, which dates back to 1991.
If you find better values, chances are your name will remain in the history books of Computer Science.
Implementing it in C is quite straight-forward:
#define INIT 5381
#define MULT 33
uint32_t hashf_djb2_m(char *str) {
uint32_t hash = INIT;
char c;
while((c=*str++)) {
hash = hash * MULT + c;
}
return hash;
}
If you look over the internet for djb2, you will find a different implementation that uses one clever simple trick. The code would be:
#define INIT 5381
uint32_t hashf_djb2(char *str) {
uint32_t hash = INIT;
char c;
while((c=*str++)) {
hash = ((hash << 5) + hash) + c;
}
return hash;
}
If we write a << x, we are shifting x bits of a to the left. By the magic of bitwise operations, this is equivalent to multiplying a * 2^x.
So, our expression hash = ((hash << 5) + hash) + c is equivalent to hash = (hash * 2^5) + hash + c, that is equivalent to hash = hash * (2^5 + 1) + c, that is equivalent hash = hash * 33 +c.
This is not just a fancy way of doing things. Historically speaking, most CPUs were performing bitshifts faster than multiplication or division. They still do.
In modern times, modern compilers can perform all kinds of optimizations, including this one. So it’s up to you to decide if making things harder to read is worth it. Also some benchmarking is recommended.
sdbmPermalink
If you search the internet for sdbm you won’t find a lot of details, except:
This algorithm was created for sdbm (a public-domain re-implementation of ndbm) database library. It was found to do well in scrambling bits, causing a better distribution of the keys and fewer splits. It also happens to be a good general hashing function with good distribution.
The function looks like this: z
uint32_t hashf_sdbm(char *str) {
uint32_t hash = 0;
char c;
while((c=*str++)) {
hash = c + (hash << 6) + (hash << 16) - hash;
}
return hash;
}
Reducing the number of collisions - FinalizersPermalink
After publishing the article draft on reddit/r/C_Programming, the community (u/skeeto) suggested the hash functions for strings can be improved even further with a simple trick: finalizers.
A common finalizer found in MurmurHash, looks like:
uint32_t ch_hash_fmix32(uint32_t h) {
h ^= h >> 16;
h *= 0x85ebca6b;
h ^= h >> 13;
h *= 0xc2b2ae35;
h ^= h >> 16;
return h;
}
In practice, we can improve results generated by djb2, sdbm by applying ch_hash_fmix32() on their output:
uint32_t final_hash = ch_hash_fmix32(hashf_sdbm("some string");
More explorationPermalink
What we’ve discussed so far about hash functions only scratches the surface of a vast subject. There are hundreds of functions, some of them better than others. But, as Software Engineers, we need to be pragmatic, know about them, ponder over their pros and cons and, in the end, take things for granted. Most of the time, simple is better.
For high(er)-level programming languages (C++, C#, Java, python), the “hashing” problem is already sorted out at “language” or “standard library” level, so we rarely have to write (or copy-paste) a hash function by hand.
If you want to explore this topic more, I suggest you also take a look at the following articles:
- FNV Hash - a popular hash function designed to be fast while maintaining a low collision rate;
- Murmurhash - is a non-cryptographic hash function suitable for general hash-based lookup. Source code here.
- Zobrist Hashing - a hash function used in computer programs that play abstract board games, such as chess and Go, to implement transposition tables, a special kind of hash table that is indexed by a board position and used to avoid analyzing the same position more than once.
- Integer hash function
- 4-byte Integer hashing
Implementing hash tablesPermalink
Hash tables are fundamental data structures that associate a set of keys with a set of values. Each <key, value> pair is an entry in the table. Knowing the key, we can look for its corresponding value (GET). We can also add (PUT) or remove (DEL) <key, value> entries just by knowing the key.
In a hash table, data is stored in an array (not surprisingly), where each pair <key, value> has its own unique index (or bucket). Accessing the data becomes highly efficient as long as we know the bucket.
The bucket is always computed by applying a hash function over a key: hashfunction(key)→bucket[<key, value>)].
Depending on how we plan to tackle potential hash collisions, there are two ways to implement a hash table:
- Separate Chaining
- Each bucket references a linked list that contains none, one or more
<key, value> entries; - To add a new entry (PUT) we compute the bucket (
hash(key)), and then we append the<key, value> to the corresponding linked list. If thekeyalready exists, we just update thevalue; - To identify an entry (GET), we compute the bucket, traverse the corresponding linked list until we find the
key.
- Each bucket references a linked list that contains none, one or more
- Open Addressing
- There are no linked lists involved - there’s only one
<key, value>entry per bucket; - In case of collisions, we probe the array to find another suitable bucket for our entry, and then we add the entry at this new-found empty location;
- Various algorithms for “probing” exists; the simplest one is called linear probing - in case of collision, we just jump to the next available bucket;
- Deleting an existing entry is a complex operation.
- There are no linked lists involved - there’s only one
Each strategy has its own PROs and CONs. For example, the creators of Java preferred to use Separate Chaining in their HashMap implementation, while the creators of python went with Open Addressing for their dict.
Separate Chaining is simpler to implement, and in case we have a high frequency hash collisions, performance degradation is more graceful - not as exacerbated as for Open Addressing.
Open Addressing is more complex to implement, but if we keep hash collisions at bay, it’s very cache-friendly.
Separate ChainingPermalink
To better understand how Separate Chaining works, let’s represent in a visual way a hash table that associates the capitals of Europe (the keys) to their corresponding countries (the values):
European Capital European Country “Paris” “France” “Berlin” “Germany” “Warsaw” “Poland” “Bucharest” “Romania” “Athens” “Greece”
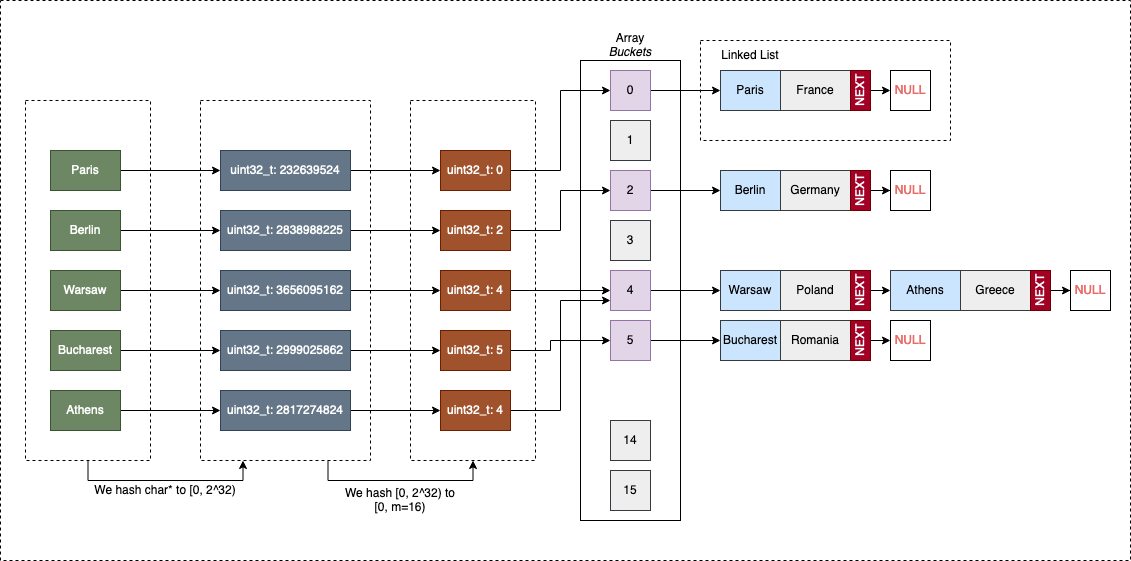
Both keys and values are strings (char*).
The first step is to reduce the keyspace to a numeric value to hash the keys further and associate them with buckets. For this, we can use something like djb2 to hash the string to a uint32_t value. We already know that djb works well with string inputs.
This step is not “part” of the hash table itself. It’s impossible for a hash table to understand all data formats and reduce them to 32-bit unsigned integers(uint32_t). In this regard, the data needs to come with its mechanisms for this. So except the keys are uint32_t, additional hash functions should be provided to the hash table (for the data, by the data).
After the keys are “projected” to the uint32_t space, we must map them to buckets (indices in our array). Another hash function will reduce the key-space further: from uint32_t to [0, M), where M is the total number of buckets. For simplicity, we can use division hashing, multiplicative hashing, or whatever hash function we think it’s good.
After the bucket is identified, we check if it’s empty (NULL). If it’s NULL, we create a new linked list, and add the pair <key, value> to it. If it’s not empty, we append the entry to the existing structure.
A generic implementationPermalink
Preferably, our hash table will be as generic as possible so that it can be re-used for various key/values combinations. We want to write code once and re-use it later. Writing a new hash table every time the key/value combination changes it’s not ideal.
The bad news, C is not exactly the most generic-friendly programming language there is.
The good news, C is flexible enough to make generic programming happen (with some effort) by:
- using
void*to pass data around, - using
#macrosthat generate specialized code after pre-processing (something similar to C++ templates).
I’ve recently found an interesting generic data structures library called STC; looking at the code can be pretty inspirational.
I am the camp that prefers #macros over void*, but not when it comes to writing tutorials. With #macros, everything becomes messy fast, and the code is hard to debug and maintain. So, for this particular implementation, we will use void* for passing/retrieving generic data to/from the hash table.
The modelPermalink
We start by defining the struct(s) behind hash tables. The main structure (ch_hash) will contain:
capacity- the total number of available buckets;size- the total number of elements;buckets- a dynamic (expandable if needed) array of linked lists;- Structures to keep tracking of data-specific operations (e.g., a function that checks if two values are equal, etc.);
typedef struct ch_hash_s {
size_t capacity;
size_t size;
ch_node **buckets;
ch_key_ops key_ops;
ch_val_ops val_ops;
} ch_hash;
As we said, the buckets are composed of linked lists:**
typedef struct ch_node_s {
uint32_t hash;
void *key;
void *val;
struct ch_node_s *next;
} ch_node;
The ch_node structure contains:
uint32_t hashis not the actual bucket index, but it’s the hash of the data that is going inside the hash table. For example, if our keys are strings,uint32_t hashis obtained by applying a hashing function that works for strings (e.g.: djb2). This is only computed once, and it’s (re)used whenever we need to re-hash our table;keyandvalof avoid*type. This gives us enough flexibility to store almost anything in the table.struct ch_node_s *nextwhich is a reference to the next node in the list.
The only thing left to explain are the two “unknown” members: ch_hash->ch_key_ops and ch_hash->ch_val_ops:
typedef struct ch_key_ops_s {
uint32_t (*hash)(const void *data, void *arg);
void* (*cp)(const void *data, void *arg);
void (*free)(void *data, void *arg);
void *arg;
} ch_key_ops;
typedef struct ch_val_ops_s {
void* (*cp)(const void *data, void *arg);
void (*free)(void *data, void *arg);
bool (*eq)(const void *data1, const void *data2, void *arg);
void *arg;
} ch_val_ops;
The two types, ch_key_ops and ch_val_ops are simple structures (struct) used to group functions specific to the data inserted in the hash table. As we previously stated, it’s impossible to think of all the possible combinations of keys/pairs and their types, so we let the user supply us with the truth.
In case the above code is confusing, please refer to the following article: Function pointers; it will explain you in great detail how we can pass functions around through “pointers”.
It’s funny to think C had its first functional programing feature implemented decades before Java…
Think of ch_key_ops and ch_val_ops as traits, bits of logic that are external to the hash table itself, but by defining them, we are creating a simple contract between our structure and the data we are inserting:
Look, if you want to add a
chr*as akeyin our hash table, please tell us first how do you: compute it’s hash, copy it and free the memory. Our table will do the heavy work for you, but first, we need to know this !?
As an example, the required functions for strings (chr*) can be implemented like this:
// Returns the uint32_t hash value of a string computed using djb2
uint32_t ch_string_hash(const void *data, void *arg) {
//djb2
uint32_t hash = (const uint32_t) 5381;
const char *str = (const char*) data;
char c;
while((c=*str++)) {
hash = ((hash << 5) + hash) + c;
}
// MurmurHash3 Fializer (mixer)
hash ^= hash >> 16;
hash *= 0x85ebca6b;
hash ^= hash >> 13;
hash *= 0xc2b2ae35;
hash ^= hash >> 16;
return hash;
}
// Returns a copy of the *data string
void* ch_string_cp(const void *data, void *arg) {
const char *input = (const char*) data;
size_t input_length = strlen(input) + 1;
char *result;
result = malloc(sizeof(*result) * input_length);
if (NULL==result) {
fprintf(stderr,"malloc() failed in file %s at line # %d", __FILE__,__LINE__);
exit(EXIT_FAILURE);
}
strcpy(result, input);
return result;
}
// Check if two strings are equal
bool ch_string_eq(const void *data1, const void *data2, void *arg) {
const char *str1 = (const char*) data1;
const char *str2 = (const char*) data2;
return !(strcmp(str1, str2)) ? true : false;
}
// Free the memory associated with a string
void ch_string_free(void *data, void *arg) {
free(data);
}
As you can see, even if our methods are going to be used for strings (chr*) we are forced to use void* instead and cast data manually.
Sadly, void* is not the T we know from C++ Templates or Java Generics. No compile-time validations are performed. It’s up to us to use it accordingly.
And then, what it remains is two keep two instances around (one for keys and one for values):
ch_key_ops ch_key_ops_string = { ch_string_hash, ch_string_cp, ch_string_free, NULL};
ch_val_ops ch_val_ops_string = { ch_string_cp, ch_string_free, ch_string_eq, NULL};
Now let’s retake a look at the initial diagram and how are structures fit together with the visual representation:

The interfacePermalink
Our hash table (ch_hash) will support and publicly expose the following functions (interface):
// Creates a new hash table
ch_hash *ch_hash_new(ch_key_ops k_ops, ch_val_ops v_ops);
// Free the memory associated with the hash (and all of its contents)
void ch_hash_free(ch_hash *hash);
// Gets the value coresponding to a key
// If the key is not found returns NULL
void* ch_hash_get(ch_hash *hash, const void *k);
// Checks if a key exists or not in the hash table
bool ch_hash_contains(ch_hash *hash, const void *k);
// Adds a <key, value> pair to the table
void ch_hash_put(ch_hash *hash, const void *k, const void *v);
// Prints the contents of the hash table
void ch_hash_print(ch_hash *hash, void (*print_key)(const void *k), void (*print_val)(const void *v));
// Get the total number of collisions
uint32_t ch_hash_numcol(ch_hash *hash);
As you might’ve noticed, there’s no function for deleting an entry. That’s intentionally left out as a proposed exercise.
Before implementing the enumerated methods, it’s good to clarify a few things that are not obvious from the interface itself.
Just for fun (best practices are fun!), our hash table will grow automatically if its size reaches a certain threshold. So every time we insert a new element, we check if the threshold has been reached and if it’s time to increase the capacity (and the number of available buckets). A re-hashing of everything will also be performed - old entries might go to new buckets.
In this regard let’s define the following constants (we can tweak their values later):
#define CH_HASH_CAPACITY_INIT (32)
#define CH_HASH_CAPACITY_MULT (2)
#define CH_HASH_GROWTH (1)
And then perform the following check each time we insert a new item:
// Grow if needed
if (hash->size > hash->capacity * CH_HASH_GROWTH) {
ch_hash_grow(hash);
// -> The function will perform a full rehashing to a new array of buckets
// of size [hash->capacity * CH_HASH_CAPACITY_MULT]
}
The ch_hash_grow(ch_hash *hash) function it’s not defined as part of the interface; it’s private. We won’t be exposing it to the header file.
Another function that’s not exposed in our (public) interface is: ch_node* ch_hash_get_node(ch_hash*, const void*). This one is used to check if a node exists or not. In case it exists, it retrieves the node. Otherwise, it returns NULL.
The reason we have two functions for retrieving data:
void* ch_hash_get(ch_hash *hash, const void *k);(public)ch_node* ch_hash_get_node(ch_hash *hash, const void *key)(private)
is simple. ch_hash_get_node works on an internal structure that we don’t want to expose: ch_node publicly.
Internally ch_hash_get will use ch_hash_get_node.
Creating/Destroying a hash tablePermalink
ch_hash_new is a constructor-like function that dynamically allocates memory for a new ch_hash.
ch_hash_free is a destructor-like function that frees all the memory associated with a ch_hash. ch_hash_free goes even deeper and de-allocates memory for the internal buckets and all the existing entries.
The code for ch_hash_new is:
ch_hash *ch_hash_new(ch_key_ops k_ops, ch_val_ops v_ops) {
ch_hash *hash;
hash = malloc(sizeof(*hash));
if(NULL == hash) {
fprintf(stderr,"malloc() failed in file %s at line # %d", __FILE__,__LINE__);
exit(EXIT_FAILURE);
}
hash->size = 0;
hash->capacity = CH_HASH_CAPACITY_INIT;
hash->key_ops = k_ops;
hash->val_ops = v_ops;
hash->buckets = malloc(hash->capacity * sizeof(*(hash->buckets)));
if (NULL == hash->buckets) {
fprintf(stderr,"malloc() failed in file %s at line # %d", __FILE__,__LINE__);
exit(EXIT_FAILURE);
}
for(int i = 0; i < hash->capacity; i++) {
// Initially all the buckets are NULL
// Memory will be allocated for them when needed
hash->buckets[i] = NULL;
}
return hash;
}
The code for ch_hash_free is:
void ch_hash_free(ch_hash *hash) {
ch_node *crt;
ch_node *next;
for(int i = 0; i < hash->capacity; ++i) {
// Free memory for each bucket
crt = hash->buckets[i];
while(NULL!=crt) {
next = crt->next;
// Free memory for key and value
hash->key_ops.free(crt->key, hash->key_ops.arg);
hash->val_ops.free(crt->val, hash->val_ops.arg);
// Free the node
free(crt);
crt = next;
}
}
// Free the buckets and the hash structure itself
free(hash->buckets);
free(hash);
}
In terms of what’s happening in ch_hash_free, things are quite straightforward, except for those two lines:
hash->key_ops.free(crt->key, hash->key_ops.arg);
hash->val_ops.free(crt->val, hash->val_ops.arg);
Because the hash table doesn’t know what type of data it holds in the entries (void* is not very explicit, isn’t it), it’s impossible to free the memory correctly.
So in this regard, we use the free functions referenced inside key_ops (for keys) and val_ops (for values).
Retrieving a value from the hash tablePermalink
For the sake of simplicity, the function that translates the uint32_t hash of the key to the [0, hash->capacity) space is %.
Basically, we will use division hashing in our implementation.
static ch_node* ch_hash_get_node(ch_hash *hash, const void *key) {
ch_node *result = NULL;
ch_node *crt = NULL;
uint32_t h;
size_t bucket_idx;
// We compute the hash of the key to check for it's existence
h = hash->key_ops.hash(key, hash->key_ops.arg);
// We use simple division hashing for determining the bucket
bucket_idx = h % hash->capacity;
crt = hash->buckets[bucket_idx];
while(NULL!=crt) {
// Iterated through the linked list found at the bucket
// to determine if the element is present or not
if (crt->hash == h && hash->val_ops.eq(crt->key, key, hash->val_ops.arg)) {
result = crt;
break;
}
crt = crt->next;
}
// If the while search performed in the while loop was successful,
// `result` contains the node
// otherwise it's NULL
return result;
}
ch_hash_get is just a wrapper function built on top of ch_hash_get_node. It has filtering purposes only: retrieving the value (ch_node->val) instead of the internal ch_node representation.
void* ch_hash_get(ch_hash *hash, const void *k) {
ch_node *result = NULL;
if (NULL!=(result=ch_hash_get_node(hash, k))) {
return result->val;
}
return NULL;
}
Adding an entry to the hash tablePermalink
The ch_hash_put method is responsible for adding new entries to the hash table.
void ch_hash_put(ch_hash *hash, const void *k, const void *v) {
ch_node *crt;
size_t bucket_idx;
crt = ch_hash_get_node(hash, k);
if (crt) {
// Key already exists
// We need to update the value
hash->val_ops.free(crt->val, hash->val_ops.arg);
crt->val = v ? hash->val_ops.cp(v, hash->val_ops.arg) : 0;
}
else {
// Key doesn't exist
// - We create a node
// - We add a node to the corresponding bucket
crt = malloc(sizeof(*crt));
if (NULL == crt) {
fprintf(stderr,"malloc() failed in file %s at line # %d", __FILE__,__LINE__);
exit(EXIT_FAILURE);
}
crt->hash = hash->key_ops.hash(k, hash->key_ops.arg);
crt->key = hash->key_ops.cp(k, hash->key_ops.arg);
crt->val = hash->val_ops.cp(v, hash->val_ops.arg);
// Simple division hashing to determine the bucket
bucket_idx = crt->hash % hash->capacity;
crt->next = hash->buckets[bucket_idx];
hash->buckets[bucket_idx] = crt;
// Element has been added successfully
hash->size++;
// Grow if needed
if (hash->size > hash->capacity * CH_HASH_GROWTH) {
ch_hash_grow(hash);
}
}
}
ch_hash_grow is an internal method (not exposed in the public API) responsible for scaling up the the number of buckets (hash->buckets) based on the number of elements contained in the table (hash->size).
ch_hash_grow allocates memory for a new array ch_node **new_buckets, and then re-hashes all the elements from the old array (hash->buckets) by projecting them in the new buckets.
In regards to this, 3 constants are being used:
#define CH_HASH_CAPACITY_INIT (31)
#define CH_HASH_CAPACITY_MULT (2)
#define CH_HASH_GROWTH (1)
CH_HASH_CAPACITY_INIT is the initial size of the array (hash->buckets). And because we’ve decided to use division hashing for determining the buckets, it is a prime number: 31.
CH_HASH_CAPACITY_MULT is the growth multiplier: hash->capacity *= CH_HASH_CAPACITY_MULT. Normally, it would’ve been better to grow to a bigger prime number (because of division hashing), but that would’ve been more complicated to implement in the code.
CH_HASH_GROWTH is the load factor - a constant that influences the growth condition: hash->size > hash->capacity * CH_HASH_GROWTH.
If allocating a new array (new_buckets) fails, we will keep the old one - that’s a pragmatic decision to make - so, instead of crashing the program, we accept a potential drop in performance.
static void ch_hash_grow(ch_hash *hash) {
ch_node **new_buckets;
ch_node *crt;
size_t new_capacity;
size_t new_idx;
new_capacity = hash->capacity * CH_HASH_CAPACITY_MULT;
new_buckets = malloc(sizeof(*new_buckets) * new_capacity);
if (NULL==new_buckets) {
fprintf(stderr, "Cannot resize buckets array. Hash table won't be resized.\n");
return;
}
for(int i = 0; i < new_capacity; ++i) {
new_buckets[i] = NULL;
}
// Rehash
// For each bucket
for(int i = 0; i < hash->capacity; i++) {
// For each linked list
crt = hash->buckets[i];
while(NULL!=crt) {
// Finding the new bucket
new_idx = crt->hash % new_capacity;
crt->next = new_buckets[new_idx];
new_buckets[new_idx] = crt;
crt = crt->next;
}
}
hash->capacity = new_capacity;
// Free the old buckets
free(hash->buckets);
// Update with the new buckets
hash->buckets = new_buckets;
}
Because there’s no
ch_hash_deletemethod, there’s noch_hash_shrinkmethod.
Printing the contents of a hash tablePermalink
And last but not least, ch_hash_print is a util method that allows us to print the contents of our chained hash table to stdout. Because we don’t know how the keys and values look like, we expect the user to supply us with the corresponding printing functions.
void ch_hash_print(ch_hash *hash, void (*print_key)(const void *k), void (*print_val)(const void *v)) {
ch_node *crt;
printf("Hash Capacity: %lu\n", hash->capacity);
printf("Hash Size: %lu\n", hash->size);
printf("Hash Buckets:\n");
for(int i = 0; i < hash->capacity; i++) {
crt = hash->buckets[i];
printf("\tbucket[%d]:\n", i);
while(NULL!=crt) {
printf("\t\thash=%" PRIu32 ", key=", crt->hash);
print_key(crt->key);
printf(", value=");
print_val(crt->val);
printf("\n");
crt=crt->next;
}
}
}
A possible implementation for the print_key function:
void ch_string_print(const void *data) {
printf("%s", (const char*) data);
}
Calling ch_hash_print is then as simple as: ch_hash_print(htable, ch_hash_print).
Calculating the number of collisions from the hash tablePermalink
The function (ch_hash_numcol) is quite simple to implement:
- We will create an internal function
uint32_t ch_node_numcol(ch_node* node)that counts the number of collisions per bucket; - We sum the number of collisions per bucket
The equivalent C code is:
static uint32_t ch_node_numcol(ch_node* node) {
uint32_t result = 0;
if (node) {
while(node->next!=NULL) {
result++;
node = node->next;
}
}
return result;
}
uint32_t ch_hash_numcol(ch_hash *hash) {
uint32_t result = 0;
for(int i = 0; i < hash->capacity; ++i) {
result += ch_node_numcol(hash->buckets[i]);
}
return result;
}
Further optimizations & ImprovementsPermalink
The current implementation is rather naive.
If you plan to create something that can be used in a more “productive” environment (read production), further improvements and optimizations can be performed on the code:
- Experiment with other data structures than linked lists. For example you can use:
- Dynamic expanding arrays (a structure similar to std::vector). In this case the memory model will be more cache-friendly.
- A variant of a binary tree, that theoretically gives us better search complexity (
O(logn)) inside the bucket;
- Use a better hash function for distributing the entries to buckets;
Using the hash tablePermalink
Using the hash table is quite trivial. Let’s take for example the following code:
ch_hash *htable = ch_hash_new(ch_key_ops_string, ch_val_ops_string);
ch_hash_put(htable, "Paris", "France");
ch_hash_put(htable, "Berlin", "Germany");
ch_hash_put(htable, "Warsaw", "Poland");
ch_hash_put(htable, "Bucharest", "Romania");
ch_hash_put(htable, "Athens", "Greece");
printf("%s\n", (char*) ch_hash_get(htable, "Athens"));
printf("%s\n", (char*) ch_hash_get(htable ,"Bucharest"));
ch_hash_print(htable, ch_string_print, ch_string_print);
return 0;
The output will be:
Greece
Romania
Hash Capacity: 32
Hash Size: 5
Hash Buckets:
bucket[0]:
bucket[1]:
hash=2838988225, key=Berlin, value=Germany
bucket[2]:
bucket[3]:
bucket[4]:
hash=232639524, key=Paris, value=France
bucket[5]:
bucket[6]:
hash=2999025862, key=Bucharest, value=Romana
bucket[7]:
bucket[8]:
hash=2817274824, key=Athens, value=Greece
bucket[9]:
bucket[10]:
bucket[11]:
bucket[12]:
bucket[13]:
bucket[14]:
bucket[15]:
bucket[16]:
bucket[17]:
bucket[18]:
bucket[19]:
bucket[20]:
bucket[21]:
bucket[22]:
bucket[23]:
bucket[24]:
bucket[25]:
bucket[26]:
hash=3656095162, key=Warsaw, value=Poland
bucket[27]:
bucket[28]:
bucket[29]:
bucket[30]:
bucket[31]:
Open AddressingPermalink
This part is still work in progress.
ReferencesPermalink
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK