

TDSQL交易型分布式数据库背景分析
source link: https://my.oschina.net/u/4788009/blog/5275133
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
随着各行各业电子信息化的不断加深,线上交易数据保持了长时间高速增长的态势,对数据存储的需求越来越大,数据库管理系统(DBMS)面临越来越大的性能、空间和稳定性压力。在此过程中,得利于计算&存储&网络等硬件领域的不断进步,业界流行的数据库管理系统逐步从单机架构向分布式架构演变。笔者希冀从梳理数据库管理系统所面临的一个又一个实际挑战及业界所提出的诸多解决方案的过程中,发现片缕灵感以指引未来的数据库开发工作。
二、从单机数据库到分布式数据库
业界起步阶段诞生的第一代交易型数据库具有以下主要特点:和程序一起运行在大型机/小型机为代表的高端计算机上; 利用硬件层面大量冗余设计带来的强大可靠性来保障数据库可用性,通过直接升级硬件规格的方式来扩容数据库性能容量。即使到今天仍然有很多银行核心系统以这样的方式运行。 很快,这种堆硬件模式来获取提升的模式局限性就暴露出来了。首先,数据库可用性对硬件层面冗余的依赖抬高了大型机等存储型设备的造价,动辄单台上千万美元的价格是诸多中小客户难以承受的负担。次之,由于性能扩容只能通过提升硬件规格的方式实现,而硬件规格的10%性能容量提升,往往需要客户付出成倍的购买成本,且整体性能极限也受限于当时的硬件发展的天花板。由于上述所说的诸多成本原因,业界一直没有停止过尝试以x86服务器为代表的“廉价”硬件替换大型机来提供交易型数据库服务的努力。
三、基于共享存储的分布式数据库方案
1. 共享存储方案 
首当其冲要解决的是,如何保障数据库服务的可用性。由于交易型业务往往都是企业中较为核心的往往会涉及金钱相关的线上业务,因此对数据库服务的可用性有比较高的要求。最简单地,通过把数据库架设在共享存储系统,将数据文件存储在共享存储,实现数据库实例和存储介质的解耦,从而实现数据库服务的高可用。
当数据库所在机器出现故障时,另一台备用机器通过接管共享存储的数据文件并快速对外继续提供数据库服务,从而保障数据库可用性。 不过,传统的共享存储也是一种高昂的硬件设备,其本身的成本&可用性&容量同样面临着硬件的限制,所以采用共享存储的数据库方案一直难以大规模流行开来。直到后来分布式文件存储系统的日益成熟,这种数据库方案才真正地流行开来。时至今日,事实证明云盘产品能在云分布式环境提供稳定可靠的存储服务,以RDS为代表的各类云数据库产品普遍通过云盘的可用性来保障数据库服务的可用性。
共享存储方案的缺点也很明显。一方面,数据放在远端的共享存储意味着数据库需要通过网络才能访问数据,这导致比单机数据库更明显的访问延迟和性能开销。数据库方案引入共享存储,意味着额外引入了对网络&共享存储等更多的外部依赖,进而导致整个数据库的稳定性有所降低。
另一方面,共享存储方案需要另一台备用机器时刻等待着接管数据库服务,意味着一个数据库服务需要两台机器但却只能有一台机器在提供服务,无法充分利用备用机器资源。因此,如何更好地将闲置的备用机器利用起来,也是一个重要的技术课题。与此同时,当前互联网时代流量特点除海量数据/海量吞吐外,还包括写入修改只占据请求总览的一小部分,用户请求绝大部分都是对内容的查询展示,内容查询场景对数据实时性的要求并不高。基于上述特点,既然另一台备用机器本身空闲又能访问到所有的数据,那是不是可以让它也同时提供一些历史版本的只读查询服务呢?是的,云盘存储方案就能通过只读节点的方式把原本灾备用的节点对外提供只读服务,从而提升整个数据库系统的查询能力。
2. 共享存储方案的演进 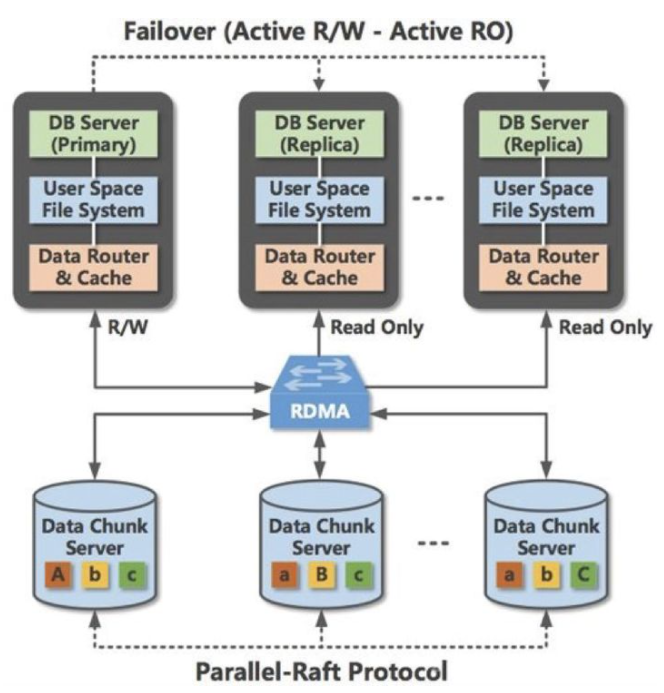
然而,云盘存储方案只是相对简单地将数据库服务架构在云盘上,只读节点无法和读写节点同时访问共享存储的同一份数据文件,只能通过单独使用一份共享存储文件后再通过额外机制来和主节点进行同步来实现。共享存储中的数据文件本身就是有多副本的,这意味着数据库层面的多节点会带来乘法效应,浪费更多的存储资源。这和提高机器资源利用率的初衷是想违背的,而且没有利用上共享存储可以被多个机器访问到的天然优势。那么,有没有办法让数据库实例的主节点和多个只读节点同时使用一份共享存储数据文件呢?
共享盘存储方案,通过在数据库层实现多节点间的协调同步,规避多个节点各自对数据文件的变更冲突,从而实现一份数据存储多个节点服务的数据库架构。共享盘存储方案在利用存储产品高可用性保障数据库可用性之余,又很好地利用了共享存储的数据共享优势提供多节点服务。
3. 可计算存储 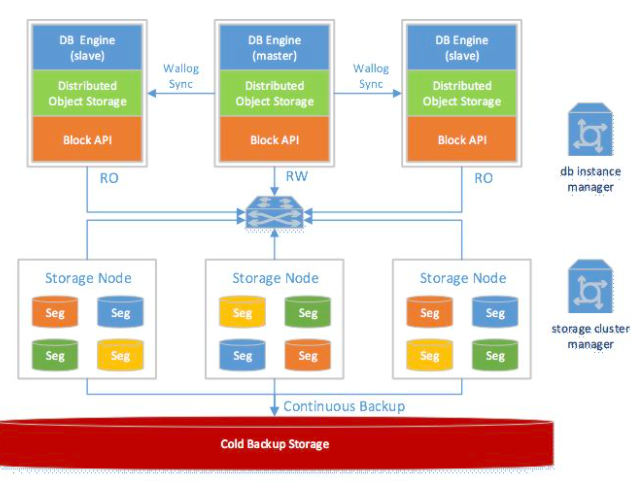
共享盘存储方案的查询性能可以通过多个只读实例进行扩展,但写入请求只有一个读写节点可以提供服务。而读写节点的性能极限仍然受限于单机硬件的性能上限,特别是网络IO设备的性能上限,不仅没从分布式架构中获得收益,甚至由于共享存储的额外开销反而有所下滑。那么,要怎么样才能让数据库服务的写入性能从分布式共享存储中获益呢? 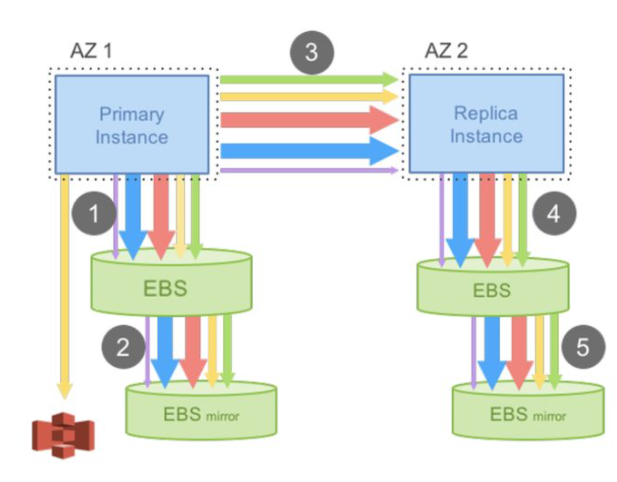
可计算存储方案即是业界对这一问题给出的一份答卷。经过长时间的观察研究,工程师们发现线上数据库服务的写入性能瓶颈通常都在网络IO。特别是RDS数据库在运行期间需要不停刷写预写日志(write ahead log)/数据文件(data file)等多种数据到远端的分布式共享存储,占用了大量机器IO容量。但与此同时,RDS数据库持久化到分布式共享存储的预写日志/数据文件等数据中包含了大量的冗余信息。比如,针对MySQL/innodb数据库架构下的binlog/redolog这两种预写日志,虽然日志格式各不相同(逻辑日志/物理日志),但二者都是对同一份数据修改的记录,却占用两倍IO流量。再比如数据库以页为单位持久化数据文件,而数据文件的页大小通常是16KB,意味着即使只修改某一页中的一行记录,在写数据文件的时候数据库实例也会产生16KB IO流量,存在比较大的写放大现象。甚至更近一步地,这一行记录的数据变更其实已经随着之前的预写日志写到分布式共享存储,写数据文件的脏页数据完全没有必要,是一种浪费!!
单机数据库之所以采用预写日志技术,是为了通过把数据脏页的随机写操作变成预写日志的顺序写操作,从而提升单机数据库整体性能。但预写日志技术只能推迟并尽可能合并对数据文件的随机写入操作,却不能完全避免对数据文件的随机写入。单机数据库需要不断地把脏页逐步刷写到数据文件来推进检查点,从而释放出更多的日志容量&控制实例故障的恢复时长。而刷脏页通常属于磁盘随机写操作,特别在随机写入的业务场景下,非常影响数据库性能,是单机数据库的一大性能瓶颈点。 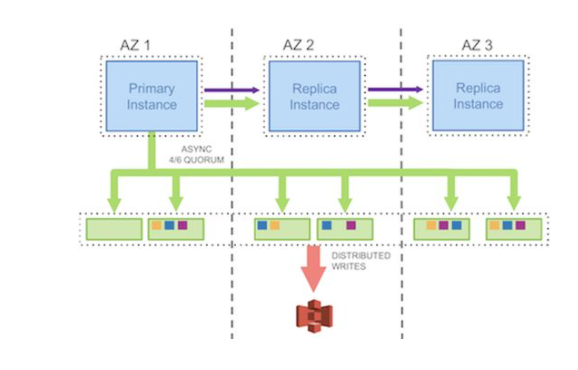
因此,工程师们提出了Log is Database的技术理念,这也是可计算存储方案的核心理念。数据库读写节点只通过必要的预写日志把数据库数据变更信息传递给分布式共享存储,而不再需要传递数据文件脏页等额外信息,读写节点机器的IO开销大大减少。那么,数据文件的数据变更怎么办呢?既然预写日志里面已经有所有的数据变更信息,那分布式共享存储系统可以直接从预写日志里获取到数据变更信息,直接将其更新到相应的数据文件中。针对MySQL/innodb数据库架构,更是可以进一步把binlog日志直接省略,单单传递redolog日志就足以把整个数据库的数据变更传递到共享存储系统,大大减少了RDS MySQL数据库实例的IO流量,有效提升了MySQL数据库的性能上限。
在此方案中,数据库读写节点只需要负责传递必要的预写日志给存储系统,不再需要处理数据文件更新维护的任务。而这部分数据维护任务由于涉及大量缓慢的数据IO操作,往往正是整个数据库系统的性能瓶颈所在。数据库读写节点从维护数据文件的高昂开销中脱身后,也得以拥有了极高的数据写入性能。而分布式共享存储系统在处理数据维护任务时,由于自身的分布式架构优势,天然可以通过添加新节点的方式进行水平扩展,不断提升整个系统的吞吐性能上限。
在海量写入的场景中,数据库通常会延缓推进检查点&保留较多预写日志,尽量避免频繁刷脏页导致影响数据库性能。而数据库在故障恢复时又必须回放在检查点后的所有预写日志,以保障数据一致性。因此,数据库在海量写入场景故障恢复中可能会因回放预写日志而消耗大量时间,导致数据库服务较长时间无法服务。由于存储系统的分布式架构优势,可计算存储方案预写日志回放操作被打散到多个存储节点上并行执行,极大提升故障恢复的速度,有效减少数据库服务的不可用时间。
更进一步的,由于拥有数据库全量历史信息,分布式存储系统能够提供历史版本数据页内容。在读取历史版本数据的时候,数据库节点只需要在数据页请求中带上历史版本信息。分布式存储系统在收到历史版本请求时,通过读取该数据页当前的数据文件和历史相关的回滚日志(undolog),然后将两者处理生产历史版本数据页后返回。由此,数据库历史数据处理任务也被下沉到存储系统,得以利用分布式存储系统的水平扩展优势来提升数据库的历史数据查询性能。
至此可以看到,与共享盘存储方案相比,可计算存储方案虽然写入请求只有一个读写节点可以提供服务,但该读写节点只需要负责请求解析、查询执行、事务管理、缓存管理等任务,而数据文件更新维护、数据页版本维护这部分数据库中开销极重的部分流程却拥有了水平扩展的能力。这意味着可计算存储方案在保证可用性的基础上,已经在一定程度上摆脱了传统单机数据库面临的硬件瓶颈,大大提升了服务能力上限。
文章篇幅所限,本文简单地介绍了基于共享存储的架构下数据库产品从单机数据库逐步向分布式数据库眼睛的发展历程中逐步面对的问题和对应的解决思路。后续文章中,笔者将尝试探讨数据库的另一条发展路线,即基于独立存储的架构下数据库产品如何从单机数据库逐步走向分布式数据库。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK