

openGauss数据库源码解析系列文章——SQL引擎源码解析(一)
source link: https://my.oschina.net/gaussdb/blog/5139635
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


学习 探索 分享数据库知识 共建数据库技术交流圈
关注 SQL引擎作为数据库系统的入口,主要承担了对SQL语言进行解析、优化、生成执行计划的作用。对于用户输入的SQL语句,SQL引擎会对语句进行语法/语义上的分析以判断是否满足语法规则等,之后会对语句进行优化以便生成最优的执行计划给执行器执行。故SQL引擎在数据库系统中承担着承上启下的作用,是数据库系统的“大脑”。一、概述
SQL引擎负责对用户输入的SQL语言进行编译,生成可执行的执行计划,然后将执行计划交给执行引擎进行执行。SQL引擎整个编译的过程如图1所示,在编译的过程中需要对输入的SQL语言进行词法分析、语法分析、语义分析,从而生成逻辑执行计划,逻辑执行计划经过代数优化和代价优化之后,产生物理执行计划。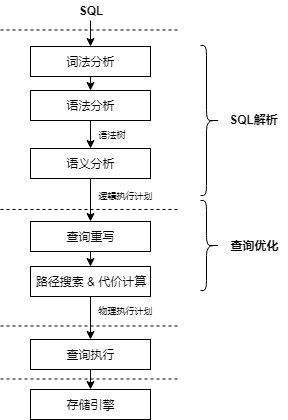
二、SQL解析
1970年,埃德加·科德(Edgar Frank Codd)发表了关系模型的论文,奠定了关系数据库的理论基础,随后在1974年,Boyce和Chamber在关系模型的基础上推出了Sequel语言,后来演进成了SQL(structured auery language,结构化查询语言)语言。SQL语言是一种基于关系代数和关系演算的非过程化语言,它指定用户需要对数据操作的内容,而不指定如何去操作数据,具有非过程化、简单易学、易迁移、高度统一等特点。因此,SQL语言在推出之后就快速地成为数据库中占比最高的语言。 SQL语句在数据库管理系统中的编译过程符合编译器实现的常规过程,需要进行词法分析、语法分析和语义分析。 (1) 词法分析:从查询语句中识别出系统支持的关键字、标识符、操作符、终结符等,确定每个词自己固有的词性。常用工具如flex。 (2) 语法分析:根据SQL语言的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个SQL语句能够匹配一个语法规则,则生成对应的抽象语法树(abstract synatax tree,AST)。常用工具如Bison。 (3) 语义分析:对抽象语法树进行有效性检查,检查语法树中对应的表、列、函数、表达式是否有对应的元数据,将抽象语法树转换为查询树。 openGuass的SQL解析代码主流程可以用图2来表示。执行SQL命令的入口函数是exec_simple_query。用户输入的SQL命令会作为字符串sql_query_string传给raw_parser函数,由raw_parser函数调用base_yyparse进行词法分析和语法分析,生成语法树添加到链表parsetree_list中。完成语法分析后,对于parsetree_list中的每一颗语法树parsetree,openGuass会调用parse_analyze函数进行语义分析,根据SQL命令的不同,执行对应的入口函数,最终生成查询树。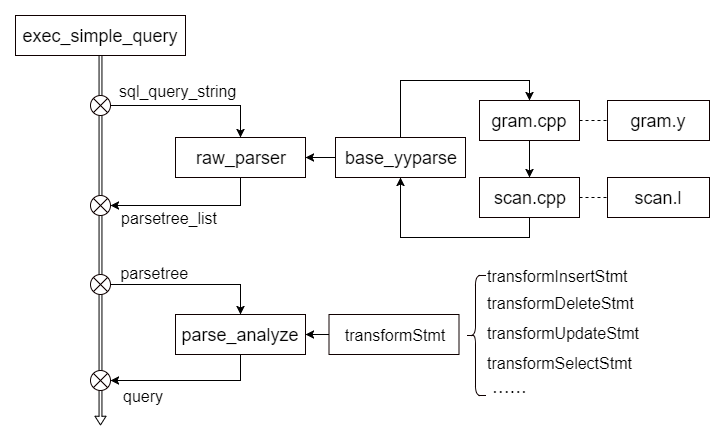
(一) 词法分析
openGauss采用flex和bison两个工具来完成词法分析和语法分析的主要工作。对于用户输入的每个SQL语句,它首先交由flex工具进行词法分析。flex工具通过对已经定义好的词法文件进行编译,生成词法分析的代码。 openGauss中的词法文件是scan.l,它根据SQL语言标准对SQL语言中的关键字、标识符、操作符、常量、终结符进行了定义和识别。代码如下:其中的operator即为操作符的定义,从代码中可以看出,operator是由多个op_chars组成的,而op_chars则是[\~\!\@\#\^\&\|\`\?\+\-\*\/\%\<\>\=]中的任意一个符号。 但这样的定义还不能满足SQL的词法分析的需要,因为并非多个op_chars的组合就能形成一个合法的操作符,因此在scan.l中会对操作符进行更明确的定义(或者说检查)。代码如下://定义操作符op_chars [\~\!\@\#\^\&\|\`\?\+\-\*\/\%\<\>\=]operator {op_chars}+//定义数值类型integer {digit}+decimal (({digit}*\.{digit}+)|({digit}+\.{digit}*))decimalfail {digit}+\.\.real ({integer}|{decimal})[Ee][-+]?{digit}+realfail1 ({integer}|{decimal})[Ee]realfail2 ({integer}|{decimal})[Ee][-+]
从operator的定义过程中可以看到其中有一些以yy开头的变量和函数,它是Lex工具的内置变量和函数,如表2所示。 表2 变量和函数说明 变量或函数名 yytext 变量,所匹配的字符串 yyleng 变量,所匹配的字符串的长度 yyval 变量,与标记相对应的值 yylex 函数,调用扫描器,返回标记 yyless 函数,将yytext中前n个以外的字符,重新放回输入流匹配 yymore 函数,将下次分析的结果词汇,接在当前yytext的后面 yywrap 函数,返回1表示扫描完成后结束程序,否则返回0 在编译的过程中,scan.l会被编译成scan.cpp文件,从parser目录的Makefile文件中可以看到编译的命令。具体代码如下:{operator} {// “/*”“--”不是操作符,他们起注释的作用int nchars = yyleng;char *slashstar = strstr(yytext, "/*");char *dashdash = strstr(yytext, "--");if (slashstar && dashdash){// 如果”/*”和”—”同时存在,选择第一个出现的作为注释if (slashstar > dashdash)slashstar = dashdash;}else if (!slashstar)slashstar = dashdash;if (slashstar)nchars = slashstar - yytext;// 为了SQL兼容,'+'和'-'不能是多字符操作符的最后一个字符,例如'=-',需要将其作为两个操作符while (nchars > 1 &&(yytext[nchars-1] == '+' ||yytext[nchars-1] == '-')){int ic;for (ic = nchars-2; ic >= 0; ic--){if (strchr("~!@#^&|`?%", yytext[ic]))break;}if (ic >= 0)break; // 如果找到匹配的操作符,跳出循环nchars--; // 否则去掉操作符 '+'和'-',重新检查}……return Op;}
通过对比scan.l和scan.cpp文件可以看出其中的关联关系。代码如下:Makefile片段scan.cpp: scan.lifdef FLEX$(FLEX) $(FLEXFLAGS) -o'$@' $<# @if [ `wc -l <lex.backup` -eq 1 ]; then rm lex.backup; else echo "Scanner requires backup, see lex.backup."; exit 1; fielse@$(missing) flex $< $@endif
词法分析将一个SQL划分成多个不同的token,每个token会有自己的词性,在scan.l中定义了如下词性。词性说明请参考表3。 表3 词法分析词性说明 keyword 如SELECT/FROM/WHERE等,对大小写不敏感 IDENT 用户自己定义的名字、常量名、变量名和过程名,若无括号修饰则对大小写不敏感 operator 操作符,如果是/*和--会识别为注释 ICONST/FCONST/SCONST /BCONST/XCONST 包括数值型常量、字符串常量、位串常量等 openGauss在kwlist.h中定义了大量的关键字,按照字母的顺序排列,方便在查找关键字时通过二分法进行查找,代码如下:scan.l840 {operator} {841 ……851 if (slashstar && dashdash)scan.cppcase 59:YY_RULE_SETUP#line 840 "scan.l"{……if (slashstar && dashdash)
在scan.l中处理“标识符”时,会到关键字列表中进行匹配,如果一个标识符匹配到关键字,则认为是关键字,否则才是标识符,即关键字优先。代码如下:PG_KEYWORD("abort", ABORT_P, UNRESERVED_KEYWORD)PG_KEYWORD("absolute", ABSOLUTE_P, UNRESERVED_KEYWORD)PG_KEYWORD("access", ACCESS, UNRESERVED_KEYWORD)PG_KEYWORD("account", ACCOUNT, UNRESERVED_KEYWORD)PG_KEYWORD("action", ACTION, UNRESERVED_KEYWORD)PG_KEYWORD("add", ADD_P, UNRESERVED_KEYWORD)PG_KEYWORD("admin", ADMIN, UNRESERVED_KEYWORD)PG_KEYWORD("after", AFTER, UNRESERVED_KEYWORD)……
{identifier} {……// 判断是否为关键词keyword = ScanKeywordLookup(yytext,yyextra->keywords,yyextra->num_keywords);if (keyword != NULL){……return keyword->value;}……yylval->str = ident;yyextra->ident_quoted = false;return IDENT;}
(二) 语法分析
openGuass中定义了bison工具能够识别的语法文件gram.y,同样在Makefile中可以通过bison工具对gram.y进行编译,生成gram.cpp文件。 在openGauss中,根据SQL语言的不同定义了一系列表达Statement的结构体(这些结构体通常以Stmt作为命名后缀),用来保存语法分析结果。以SELECT查询为例,它对应的Statement结构体如下。这个结构体可以看作一个多叉树,每个叶子节点都表达了SELECT查询语句中的一个语法结构,对应到gram.y中,它会有一个SelectStmt。代码如下:typedef struct SelectStmt {NodeTag type; // 节点类型List* distinctClause; // DISTINCT子句IntoClause* intoClause; // SELECT INTO子句List* targetList; // 目标属性List* fromClause; // FROM子句Node* whereClause; // WHERE子句List* groupClause; // GROUP BY子句Node* havingClause; // HAVING子句List* windowClause; // WINDOW子句WithClause* withClause; // WITH子句List* valuesLists; // FROM子句中未转换的表达式,用来保存常量表List* sortClause; // ORDER BY子句Node* limitOffset; // OFFSET子句Node* limitCount; // LIMIT子句List* lockingClause; // FOR UPDATE子句HintState* hintState;SetOperation op; // 查询语句的集合操作bool all; // 集合操作是否指定ALL关键字struct SelectStmt* larg; // 左子节点struct SelectStmt* rarg; // 右子节点……} SelectStmt;
simple_select除了上面的基本形式,还可以表示为其他形式,如VALUES子句、关系表达式、多个SELECT语句的集合操作等,这些形式会进一步的递归处理,最终转换为基本的simple_select形式。代码如下:simple_select:SELECT hint_string opt_distinct target_listinto_clause from_clause where_clausegroup_clause having_clause window_clause{SelectStmt *n = makeNode(SelectStmt);n->distinctClause = $3;n->targetList = $4;n->intoClause = $5;n->fromClause = $6;n->whereClause = $7;n->groupClause = $8;n->havingClause = $9;n->windowClause = $10;n->hintState = create_hintstate($2);n->hasPlus = getOperatorPlusFlag();$$ = (Node *)n;}……
从simple_select语法分析结构可以看出,一条简单的查询语句由以下子句组成:去除行重复的distinctClause、目标属性targetList、SELECT INTO子句intoClause、FROM子句fromClause、WHERE子句whereClause、GROUP BY子句groupClause、HAVING子句havingClause、窗口子句windowClause和plan_hint子句。在成功匹配simple_select语法结构后,将会创建一个Statement结构体,将各个子句进行相应的赋值。对simple_select而言,目标属性、FROM子句、WHERE子句是最重要的组成部分。 目标属性对应语法定义中的target_list,由若干个target_el组成。target_el可以定义为表达式、取别名的表达式和“*”等。代码如下:simple_select:……| values_clause { $$ = $1; }| TABLE relation_expr……| select_clause UNION opt_all select_clause{$$ = makeSetOp(SETOP_UNION, $3, $1, $4);}| select_clause INTERSECT opt_all select_clause{$$ = makeSetOp(SETOP_INTERSECT, $3, $1, $4);}| select_clause EXCEPT opt_all select_clause{$$ = makeSetOp(SETOP_EXCEPT, $3, $1, $4);}| select_clause MINUS_P opt_all select_clause{$$ = makeSetOp(SETOP_EXCEPT, $3, $1, $4);};
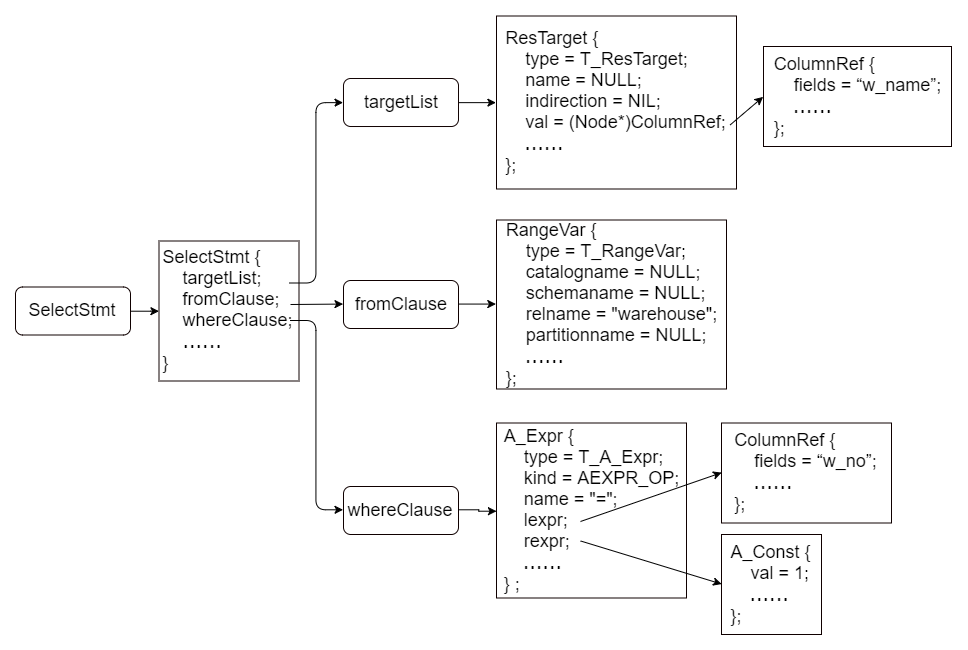
当成功匹配到一个target_el后,会创建一个ResTarget结构体,用于存储目标对象的全部信息。ResTarget结构如下。target_list:target_el { $$ = list_make1($1); }| target_list ',' target_el { $$ = lappend($1, $3); };target_el: a_expr AS ColLabel……| a_expr IDENT……| a_expr……| '*'……| c_expr VALUE_P……| c_expr NAME_P……| c_expr TYPE_P……;
FROM子句对应语法定义中的from_clause,由FROM关键字和from_list组成,而from_list则由若干个table_ref组成。table_ref可以定义为关系表达式、取别名的关系表达式、函数、SELECT语句、表连接等形式。代码如下:typedef struct ResTarget {NodeTag type;char *name; // AS指定的目标属性的名称,没有则为空List *indirection; // 通过属性名、*号引用的目标属性,没有则为空Node *val; // 指向各种表达式int location; // 符号出现的位置} ResTarget;
以FROM子句中的关系表达式为例,最终会定义为ColId的相关形式,表示为表名、列名等的定义。代码如下:from_clause:FROM from_list { $$ = $2; }| /*EMPTY*/{ $$ = NIL; };from_list:table_ref { $$ = list_make1($1); }| from_list ',' table_ref { $$ = lappend($1, $3); };table_ref: relation_expr……| relation_expr alias_clause……| relation_expr opt_alias_clause tablesample_clause……| relation_expr PARTITION '(' name ')'……| relation_expr BUCKETS '(' bucket_list ')'……| relation_expr PARTITION_FOR '(' maxValueList ')'……| relation_expr PARTITION '(' name ')' alias_clause……| relation_expr PARTITION_FOR '(' maxValueList ')'alias_clause……| func_table……| func_table alias_clause……| func_table AS '(' TableFuncElementList ')'……| func_table AS ColId '(' TableFuncElementList ')'……| func_table ColId '(' TableFuncElementList ')'……| select_with_parens……| select_with_parens alias_clause……| joined_table……| '(' joined_table ')' alias_clause……;
在捕获到ColId后,会创建一个RangeVar结构体,用来存储相关信息。RangeVar结构如下。relation_expr:qualified_name……| qualified_name '*'……| ONLY qualified_name……| ONLY '(' qualified_name ')'……;qualified_name:ColId……| ColId indirection……
WHERE子句给出了元组的约束信息,对应语法定义中的where_clause,由WHERE关键字和一个表达式组成。例如:typedef struct RangeVar {NodeTag type;char* catalogname; // 表的数据库名char* schemaname; // 表的模式名char* relname; // 表或者序列名char* partitionname; //记录分区表名InhOption inhOpt; // 是否将表的操作递归到子表上char relpersistence; / 表类型,普通表/unlogged表/临时表/全局临时表Alias* alias; // 表的别名int location; // 符号出现的位置bool ispartition; // 是否为分区表List* partitionKeyValuesList;bool isbucket; // 当前是否为哈希桶类型的表List* buckets; // 对应的哈希桶中的桶int length;#ifdef ENABLE_MOTOid foreignOid;#endif} RangeVar;
表达式可以为一个常量表达式或者属性,也可以为子表达式的运算关系。例如:where_clause:WHERE a_expr { $$ = $2; }| /*EMPTY*/ { $$ = NULL; };
对于运算关系,会调用makeSimpleA_Expr函数生成A_Expr结构体,存储表达式的相关信息。A_Expr结构如下,字段lexpr和rexpr分别保存左、右两个子表达式的相关信息。代码如下:a_expr: c_expr { $$ = $1; }| a_expr TYPECAST Typename{ $$ = makeTypeCast($1, $3, @2); }| a_expr COLLATE any_name……| a_expr AT TIME ZONE a_expr……| '+' a_expr……;
simple_select的其他子句,如distinctClause、groupClause、havingClause等,语法分析方式类似。而其他SQL命令,如CREATE、INSERT、UPDATE、DELETE等,处理方式与SELECT命令类似,这里不做一一说明。 对于任何复杂的SQL语句,都可以拆解为多个基本的SQL命令执行。在完成词法分析和语法分析后,raw_parser函数会将所有的语法分析树封装为一个List结构,名为raw_parse_tree_list,返回给exec_simple_query函数,用于后面的语义分析、查询重写等步骤,该List中的每个ListCell包含一个语法树。typedef struct A_Expr {NodeTag type;A_Expr_Kind kind; // 表达式类型List *name; // 操作符名称Node *lexpr; // 左子表达式Node *rexpr; // 右子表达式int location; // 符号出现的位置} A_Expr;
(三) 语义分析
语义分析模块在词法分析和语法分析之后执行,用于检查SQL命令是否符合语义规定,能否正确执行。负责语义分析的是parse_analyze函数,位于analyze.cpp下。parse_analyze会根据词法分析和语法分析得到的语法树,生成一个ParseState结构体用于记录语义分析的状态,再调用transformStmt函数,根据不同的命令类型进行相应的处理,最后生成查询树。 ParseState保存了许多语义分析的中间信息,如原始SQL命令、范围表、连接表达式、原始WINDOW子句、FOR UPDATE/FOR SHARE子句等。该结构体在语义分析入口函数parse_analyze下被初始化,在transformStmt函数下根据不同的Stmt存储不同的中间信息,完成语义分析后再被释放。ParseState结构如下。在语义分析过程中,语法树parseTree使用Node节点进行包装。Node结构只有一个类型为NodeTag枚举变量的字段,用于识别不同的处理情况。比如SelectStmt 对应的NodeTag值为T_SelectStmt。Node结构如下。struct ParseState {struct ParseState* parentParseState; // 指向外层查询const char* p_sourcetext; // 原始SQL命令List* p_rtable; // 范围表List* p_joinexprs; // 连接表达式List* p_joinlist; // 连接项List* p_relnamespace; // 表名集合List* p_varnamespace; // 属性名集合bool p_lateral_active;List* p_ctenamespace; // 公共表达式名集合List* p_future_ctes; // 不在p_ctenamespace中的公共表达式CommonTableExpr* p_parent_cte;List* p_windowdefs; // WINDOW子句的原始定义int p_next_resno; // 下一个分配给目标属性的资源号List* p_locking_clause; // 原始的FOR UPDATE/FOR SHARE信息Node* p_value_substitute;bool p_hasAggs; // 是否有聚集函数bool p_hasWindowFuncs; // 是否有窗口函数bool p_hasSubLinks; // 是否有子链接bool p_hasModifyingCTE;bool p_is_insert; // 是否为INSERT语句bool p_locked_from_parent;bool p_resolve_unknowns;bool p_hasSynonyms;Relation p_target_relation; // 目标表RangeTblEntry* p_target_rangetblentry; // 目标表在RangeTable对应的项……};
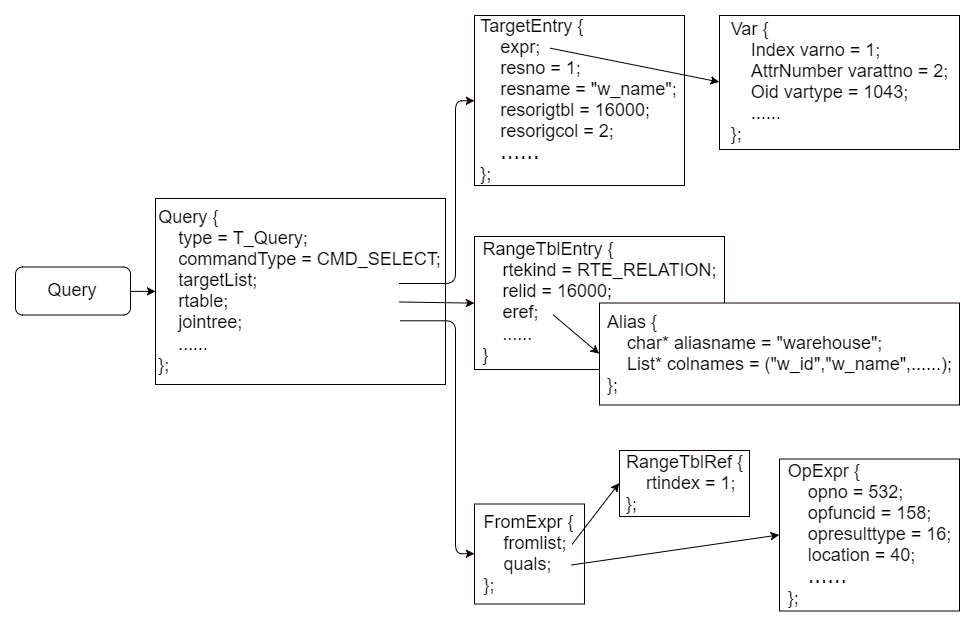
transformStmt函数会根据NodeTag的值,将语法树转化为不同的Stmt结构体,调用对应的语义分析函数进行处理。openGauss在语义分析阶段处理的NodeTag情况有九种,详细请参考表4。 表4 NodeTag情况说明 NodeTag 语义分析函数 T_InsertStmt transformInsertStmt 处理INSERT语句的语义 T_DeleteStmt transformDeleteStmt 处理DELETE语句的语义 T_UpdateStmt transformUpdateStmt 处理UPDATE语句的语义 T_MergeStmt transformMergeStmt 处理MERGE语句的语义 T_SelectStmt transformSelectStmt 处理基本SELCET语句的语义 transformValuesClause 处理SELCET VALUE语句的语义 transformSetOperationStmt 处理带有UNION、INTERSECT、EXCEPT的SELECT语句的语义 T_DeclareCursorStmt transformDeclareCursorStmt 处理DECLARE语句的语义 T_ExplainStmt transformExplainStmt 处理EXPLAIN语句的语义 T_CreateTableAsStmt transformCreateTableAsStmt 处理CREATE TABLE AS,SELECT INTO和CREATE MATERIALIZED VIEW等语句的语义 作为UTILITY类型处理,直接在分析树上封装Query返回 以处理基本SELECT命令的transformSelectStmt函数为例,其处理流程如下。 (1) 创建一个新的Query节点,设置commandType为CMD_SELECT。 (2) 检查SelectStmt是否存在WITH子句,存在则调用transformWithClause处理。 (3) 调用transformFromClause函数处理FROM子句。 (4) 调用transformTargetList函数处理目标属性。 (5) 若存在操作符“+”则调用transformOperatorPlus转为外连接。 (6) 调用transformWhereClause函数处理WHERE子句和HAVING子句。 (7) 调用transformSortClause函数处理ORDER BY子句。 (8) 调用transformGroupClause函数处理GROUP BY子句。 (9) 调用transformDistinctClause函数或者transformDistinctOnClause函数处理DISTINCT子句。 (10) 调用transformLimitClause函数处理LIMIT和OFFSET子句。 (11) 调用transformWindowDefinitions函数处理WINDOWS子句。 (12) 调用resolveTargetListUnknowns函数将其他未知类型作为text处理。 (13) 调用transformLockingClause函数处理FOR UPDATE子句。 (14) 处理其他情况,如insert语句、foreign table等。 (15) 返回查询树。 下面对FROM子句、目标属性、WHERE子句的语义分析过程进行说明,SELECT语句的其他部分语义分析方式与此类似,不做赘述。 处理目标属性的入口函数是transformTargetList,函数的传参包括结构体ParseState和目标属性链表targetlist。transformTargetList会调用transformTargetEntry来处理语法树下目标属性的每一个ListCell,最终将语法树ResTarget结构体的链表转换为查询树TargetEntry结构体的链表,每一个TargetEntry表示查询树的一个目标属性。 TargetEntry结构如下。其中resno保存目标属性的编号(从1开始计数),resname保存属性名,resorigtbl和resorigcol分别保存目标属性源表的OID和编号。typedef struct Node {NodeTag type;} Node;
FROM子句由transformFromClause函数进行处理,最后生成范围表。该函数的主要传参除了结构体ParseState,还包括分析树SelectStmt的fromClause字段。fromClause是List结构,由FROM子句中的表、视图、子查询、函数、连接表达式等构成,由transformFromClauseItem函数进行检查和处理。typedef struct TargetEntry {Expr xpr;Expr* expr; // 需要计算的表达式AttrNumber resno; // 属性编号char* resname; // 属性名Index ressortgroupref; // 被ORDER BY和GROUP BY子句引用时为正值Oid resorigtbl; // 属性所属源表的OIDAttrNumber resorigcol; // 属性在源表中的编号bool resjunk; // 如果为true,则在输出结果时去除} TargetEntry;
transformFromClauseItem会根据fromClause字段的每个Node生成一个或多个RangeTblEntry结构,加入ParseState的p_rtable字段指向的链表中,最终生成查询树的rtable字段也会指向该链表。RangeTblEntry结构如下。Node* transformFromClauseItem(……){if (IsA(n, RangeVar)) {……} else if (IsA(n, RangeSubselect)) {……} else if (IsA(n, RangeFunction)) {……} else if (IsA(n, RangeTableSample)) {……} else if (IsA(n, JoinExpr)) {……} else……return NULL;}
处理WHERE子句的入口函数是transformWhereClause,该函数调用transformExpr将分析树SelectStmt下whereClause字段表示的WHERE子句转换为一颗表达式树,然后将ParseState的p_joinlist所指向的链表和从WHERE子句得到的表达式树包装成FromExpr结构,存入查询树的jointree。typedef struct RangeTblEntry {NodeTag type;RTEKind rtekind; // RTE的类型……Oid relid; // 表的OIDOid partitionOid; // 如果是分区表,记录分区表的OIDbool isContainPartition; // 是否含有分区表Oid refSynOid;List* partid_list;char relkind; // 表的类型bool isResultRel;TableSampleClause* tablesample; // 对表基于采样进行查询的子句bool ispartrel; // 是否为分区表bool ignoreResetRelid;Query* subquery; // 子查询语句bool security_barrier; // 是否为security_barrier视图的子查询JoinType jointype; // 连接类型List* joinaliasvars; // 连接结果中属性的别名Node* funcexpr; // 函数调用的表达式树List* funccoltypes; // 函数返回记录中属性类型的OID列表List* funccoltypmods; // 函数返回记录中属性类型的typmods列表List* funccolcollations; // 函数返回记录中属性类型的collation OID列表List* values_lists; // VALUES表达式列表List* values_collations; // VALUES属性类型的collation OID列表……} RangeTblEntry;
transformStmt函数完成语义分析后会返回查询树。一条SQL语句的每个子句的语义分析结果会保存在Query的对应字段中,比如targetList存储目标属性语义分析结果,rtable存储FROM子句生成的范围表,jointree的quals字段存储WHERE子句语义分析的表达式树。查询树结构体定义如下。typedef struct FromExpr {NodeTag type;List* fromlist; // 子连接链表Node* quals; // 表达式树} FromExpr;
typedef struct Query {NodeTag type;CmdType commandType; // 命令类型QuerySource querySource; // 查询来源uint64 queryId; // 查询树的标识符bool canSetTag; // 如果是原始查询,则为false;如果是查询重写或者查询规划新增,则为trueNode* utilityStmt; // 定义游标或者不可优化的查询语句int resultRelation; // 结果关系bool hasAggs; // 目标属性或HAVING子句中是否有聚集函数bool hasWindowFuncs; // 目标属性中是否有窗口函数bool hasSubLinks; // 是否有子查询bool hasDistinctOn; // 是否有DISTINCT子句bool hasRecursive; // 公共表达式是否允许递归bool hasModifyingCTE; // WITH子句是否包含INSERT/UPDATE/DELETEbool hasForUpdate; // 是否有FOR UPDATE或FOR SHARE子句bool hasRowSecurity; // 重写是否应用行级访问控制bool hasSynonyms; // 范围表是否有同义词List* cteList; // WITH子句,用于公共表达式List* rtable; // 范围表FromExpr* jointree; // 连接树,描述FROM和WHERE子句出现的连接List* targetList; // 目标属性List* starStart; // 对应于ParseState结构体的p_star_startList* starEnd; // 对应于ParseState结构体的p_star_endList* starOnly; // 对应于ParseState结构体的p_star_onlyList* returningList; // RETURNING子句List* groupClause; // GROUP子句List* groupingSets; // 分组集Node* havingQual; // HAVING子句List* windowClause; // WINDOW子句List* distinctClause; // DISTINCT子句List* sortClause; // ORDER子句Node* limitOffset; // OFFSET子句Node* limitCount; // LIMIT子句List* rowMarks; // 行标记链表Node* setOperations; // 集合操作List *constraintDeps;HintState* hintState;……} Query;
(四) 解析流程分析
在了解了SQL解析的大致流程后,通过一个具体的案例了解一下SQL解析过程中的具体代码流程。首先创建基表warehouse,语句如下。warehouse表被创建之后,会在pg_class系统表中生成一条元数据,元数据中的OID属性用来用来代表这个表,比如在pg_attribute表中就通过这个OID来标明这些属性是属于哪个表的。假设warehouse的OID为16000,下面以查询语句SELECT w_name FROM warehouse WHERE w_no = 1为例,来分析SQL分析的整体流程。 如表5所示,scan.l会划分SQL语句中的各个token及其词性,利用关键字列表匹配到关键字SELECT、FROM、WHERE,并将其他单词w_name、warehouse、w_no标记为标识符,将符号“=”识别为操作符,“1”识别为整数型常量。 表5 token及其词性 Scan.l中的划分 SELECT、FROM、WHERE SELECT/FROM/WHERE w_name、warehouse、w_no IDENT ICONST 在完成SQL语句的词法分析后,scan.l生成词法分析结果,代码如下:CREATE TABLE warehouse(w_id SMALLINT PRIMARY KEY,w_name VARCHAR(10) NOT NULL,w_street_1 VARCHAR(20) CHECK(LENGTH(w_street_1)<>0),w_street_2 VARCHAR(20) CHECK(LENGTH(w_street_2)<>0),w_city VARCHAR(20),w_state CHAR(2) DEFAULT 'CN',w_zip CHAR(9),w_tax DECIMAL(4,2),w_ytd DECIMAL(12,2));
SELECT IDENT FROM IDENT WHERE IDENT “=” ICONST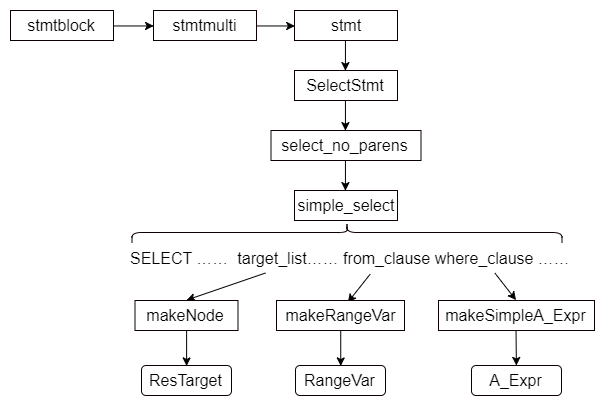
 END
END
 Gauss松鼠会
Gauss松鼠会
 汇集数据库从业人员及爱好者
互助解决问题 共建数据库技术交流圈
汇集数据库从业人员及爱好者
互助解决问题 共建数据库技术交流圈
 PC端阅读,请点击“阅读原文”
PC端阅读,请点击“阅读原文”
本文分享自微信公众号 - Gauss松鼠会(gh_18130286cd60)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
-
9
上一篇openGauss数据库源码解析系列文章--openGauss简介(上)中,从openGauss概述、应用场景、系统结构、代码结构四个方面对openGauss进行了初步介绍。其中,openGauss的代码结构介绍了数据库系统通信管理、SQL引擎两方面内容,本篇接着从代码结构第三方面的内...
-
9
在openGauss数据库源码解析系列文章——openGauss开发快速入门(中),介绍了openGauss基本使用,本篇将从openGauss的开发和编译、参与openGauss社区开源项目两方面展开具体介绍。 三、 开发和编译 作为openGauss数据库开发者,在基于openGauss...
-
7
OLTP、OLAP业务各自对数据库的存储引擎提出了不同的要求,而openGauss能够支持多个存储引擎来满足来自不同场景的业务诉求。本章将逐一介绍各种存储引擎和对应的源码。 4.1 存储引擎整体架构及代码概览 从整个数据库服务的组成构架来看,存...
-
2
上一篇详细讲述了“4.2.5 行存储索引机制”、“4.2.6 行存储缓存机制”及“4.2.7 cstore”等精彩内容。本篇我们详细讲述“4.3 内存表”相关内容。 4.3 内存表 MOT(memory-optimized tables,内存表)是事务性、基于行存储的存储引擎,针对众核和大...
-
6
本篇为小伙伴们带来第五章——事务机制源码解析的精彩内容。 事务是数据库操作的执行单位,需要满足最基本的ACID(原子性、一致性、隔离性、持久性)属性。 (1) 原子性:一个事务提交之后要么全部执行,要么全部不执行。 (2) 一致性:事...
-
7
上一篇为介绍完"5.1 事务整体架构和代码概览"及“5.2 事务并发控制”,本篇将继续介绍“5.3 锁机制”的精彩内容。 5.3 锁机制 数据库对公共资源的并发控制是通过锁来实现的,根据锁的用途不同,通常可以分为3种:自旋锁(spinlock)、轻量级锁...
-
3
上一篇文章介绍了SQL引擎源解析中“6.1 概述”及“6.2 SQL解析”的精彩内容,本篇我们开启“6.3 查询优化”及“6.4 小结”的相关内容的介绍。 6.3 查询优化 openGauss数据库的查询优化过程功能比较明晰,从源代码组织的角度来看,相关代码分布在不...
-
10
本篇我们开启第七章执行器解析中“7.1 执行器整体架构及代码概览”、“7.2 执行流程”及“7.3 执行算子”的相关精彩内容介绍。 执行器在数据库整个体系结构中起到承上启下的作用,对上承接优化器产生的最优执行计划,并按照执行计划进行流水线式的执行,对底...
-
14
上一篇介绍了第七章执行器解析中“7.4 表达式计算”及“7.5 编译执行”的相关内容,本篇将介绍“7...
-
5
openGauss数据库源码解析系列文章—— AI技术(一) 上一篇介绍了第七章执行器解析中“7.6...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK