

openGauss数据库源码解析系列文章—— 事务机制源码解析(二)
source link: https://my.oschina.net/gaussdb/blog/5175028
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
上一篇为介绍完"5.1 事务整体架构和代码概览"及“5.2 事务并发控制”,本篇将继续介绍“5.3 锁机制”的精彩内容。
5.3 锁机制
数据库对公共资源的并发控制是通过锁来实现的,根据锁的用途不同,通常可以分为3种:自旋锁(spinlock)、轻量级锁(LWLock,light weight lock)和常规锁(或基于这3种锁的进一步封装)。使用锁的一般操作流程可以简述为3步:加锁、临界区操作、放锁。在保证正确性的情况下,锁的使用及争抢成为制约性能的重要因素,下面先简单介绍openGauss中的3种锁,最后再着重介绍openGauss基于鲲鹏架构所做的锁相关性能优化。
5.3.1 自旋锁
自旋锁一般是使用CPU的原子指令TAS(test-and-set)实现的。只有2种状态:锁定和解锁。自旋锁最多只能被一个进程持有。自旋锁与信号量的区别在于,当进程无法得到资源时,信号量使进程处于睡眠阻塞状态,而自旋锁使进程处于忙等待状态。自旋锁主要用于加锁时间非常短的场合,比如修改标志或者读取标志字段,在几十个指令之内。在编写代码时,自旋锁的加锁和解锁要保证在一个函数内。自旋锁由编码保证不会产生死锁,没有死锁检测,并且没有等待队列。由于自旋锁消耗CPU,当使用不当长期持有时会触发内核core dump(核心转储),openGauss中将许多32/64/128位变量的更新改用CAS原子操作,避免或减少使用自旋锁。
与自旋锁相关的操作主要有下面几个:
(1) SpinLockInit:自旋锁的初始化。
(2) SpinLockAcquire:自旋锁加锁。
(3) SpinLockRelease:自旋锁释放锁。
(4) SpinLockFree:自旋锁销毁并清理相关资源。
5.3.2 LWLock轻量级锁
轻量级锁是使用原子操作、等待队列和信号量实现的。存在2种类型:共享锁和排他锁。多个进程可以同时获取共享锁,但排他锁只能被一个进程拥有。当进程无法得到资源时,轻量级锁会使进程处于睡眠阻塞状态。轻量级锁主要用于内部临界区操作比较久的场合,加锁和解锁的操作可以跨越函数,但使用完后要立即释放。轻量级锁应由编码保证不会产生死锁。但是由于代码复杂度及各类异常处理,openGauss提供了LWLock的死锁检测机制,避免各类异常场景产生的LWLock死锁问题。
与轻量级锁相关的函数有如下几个。
(1) LWLockAssign:申请一个LWLock。
(2) LWLockAcquire:加锁。
(3 )LWLockConditionalAcquire:条件加锁,如果没有获取锁则返回false,并不一直等待。
(4) LWLockRelease:释放锁。
(5) LWLockReleaseAll:释放拥有的所有锁。当事务过程中出错了,会将持有的所有LWLock全部回滚释放,避免残留阻塞后续操作。
相关结构体代码如下:
#define LW_FLAG_HAS_WAITERS ((uint32)1 << 30)
#define LW_FLAG_RELEASE_OK ((uint32)1 << 29)
#define LW_FLAG_LOCKED ((uint32)1 << 28)
#define LW_VAL_EXCLUSIVE ((uint32)1 << 24)
#define LW_VAL_SHARED 1 /* 用于标记LWLock的state状态,实现锁的获取和释放*/
typedef struct LWLock {
uint16 tranche; /* 轻量级锁的ID标识 */
pg_atomic_uint32 state; /* 锁的状态位 */
dlist_head waiters; /* 等锁线程的链表 */
#ifdef LOCK_DEBUG
pg_atomic_uint32 nwaiters; /* 等锁线程的个数 */
struct PGPROC *owner; /* 最后独占锁的持有者 */
#endif
#ifdef ENABLE_THREAD_CHECK
pg_atomic_uint32 rwlock;
pg_atomic_uint32 listlock;
#endif
} LWLock;
5.3.3 常规锁
常规锁是使用哈希表实现的。常规锁支持多种锁模式(lock modes),这些锁模式之间的语义和冲突是通过冲突表来定义的。常规锁主要用于业务访问的数据库对象加锁。常规锁的加锁遵守数据库的两阶段加锁协议,即访问过程中加锁,事务提交时释放锁。
常规锁有等待队列并提供了死锁检测机制,当检测到死锁发生时选择一个事务进行回滚。
openGauss提供了8个锁级别分别用于不同的语句并发:1级锁一般用于SELECT查询操作;3级锁一般用于基本的INSERT、UPDATE、DELETE操作;4级锁用于VACUUM、analyze等操作;8级锁一般用于各类DDL语句,具体宏定义及命名代码如下:
#define AccessShareLock 1 /* SELECT语句 */
#define RowShareLock 2 /* SELECT FOR UPDATE/FOR SHARE语句 */
#define RowExclusiveLock 3 /* INSERT, UPDATE, DELETE语句 */
#define ShareUpdateExclusiveLock \
4 /* VACUUM (non-FULL),ANALYZE, CREATE INDEX CONCURRENTLY语句 */
#define ShareLock 5 /* CREATE INDEX (WITHOUT CONCURRENTLY)语句 */
#define ShareRowExclusiveLock \
6 /* 类似于独占模式, 但是允许ROW SHARE模式并发 */
#define ExclusiveLock \
7 /* 阻塞ROW SHARE,如SELECT...FOR UPDATE语句 */
#define AccessExclusiveLock \
8 /* ALTER TABLE, DROP TABLE, VACUUM FULL, LOCK TABLE语句 */
这8个级别的锁冲突及并发控制如表5-7所示,其中 表示两个锁操作可以并发。
表5-7 锁冲突及并发控制
锁级别 1 2 3 4 5 6 7 8 1.ACCESS SHARE - 2.ROW SHARE - - 3.ROW EXCLUSIVE - - - - 4.SHARE UPDATE EXCLUSIVE - - - - - 5.SHARELOCK - - - - - 6.SHARE ROW EXCLUSIVE - - - - - - 7.EXCLUSIVE - - - - - - - 8.ACCESS EXCLUSIVE - - - - - - - -加锁对象数据结构,通过对field1->field5赋值标识不同的锁对象,使用locktag_type标识锁对象类型,如relation表级对象、tuple行级对象、事务对象等,对应的代码如下:
typedef struct LOCKTAG {
uint32 locktag_field1; /* 32比特位*/
uint32 locktag_field2; /* 32比特位*/
uint32 locktag_field3; /* 32比特位*/
uint32 locktag_field4; /* 32比特位*/
uint16 locktag_field5; /* 32比特位*/
uint8 locktag_type; /* 详情见枚举类LockTagType*/
uint8 locktag_lockmethodid; /* 锁方法类型*/
} LOCKTAG;
typedef enum LockTagType {
LOCKTAG_RELATION, /* 表关系*/
/* LOCKTAG_RELATION的ID信息为所属库的OID+表OID;如果库的OID为0表示此表是共享表,其中OID为openGauss内核通用对象标识符 */
LOCKTAG_RELATION_EXTEND, /* 扩展表的优先权*/
/* LOCKTAG_RELATION_EXTEND的ID信息 */
LOCKTAG_PARTITION, /* 分区*/
LOCKTAG_PARTITION_SEQUENCE, /* 分区序列*/
LOCKTAG_PAGE, /* 表中的页*/
/* LOCKTAG_PAGE的ID信息为RELATION信息+BlockNumber(页面号)*/
LOCKTAG_TUPLE, /* 物理元组*/
/* LOCKTAG_TUPLE的ID信息为PAGE信息+OffsetNumber(页面上的偏移量) */
LOCKTAG_TRANSACTION, /* 事务ID (为了等待相应的事务结束) */
/* LOCKTAG_TRANSACTION的ID信息为事务ID号 */
LOCKTAG_VIRTUALTRANSACTION, /* 虚拟事务ID */
/* LOCKTAG_VIRTUALTRANSACTION的ID信息为它的虚拟事务ID号 */
LOCKTAG_OBJECT, /* 非表关系的数据库对象 */
/* LOCKTAG_OBJECT的ID信息为数据OID+类OID+对象OID+子ID */
LOCKTAG_CSTORE_FREESPACE, /* 列存储空闲空间 */
LOCKTAG_USERLOCK, /* 预留给用户锁的锁对象 */
LOCKTAG_ADVISORY, /* 用户顾问锁 */
LOCK_EVENT_NUM
} LockTagType;
常规锁LOCK结构,tag是常规锁对象的唯一标识,procLocks是将该锁所有的持有、等待线程串联起来的结构体指针。对应的代码如下:
typedef struct LOCK {
/* 哈希键 */
LOCKTAG tag; /* 锁对象的唯一标识 */
/* 数据 */
LOCKMASK grantMask; /* 已经获取锁对象的位掩码 */
LOCKMASK waitMask; /* 等待锁对象的位掩码 */
SHM_QUEUE procLocks; /* 与锁关联的PROCLOCK对象链表 */
PROC_QUEUE waitProcs; /* 等待锁的PGPROC对象链表 */
int requested[MAX_LOCKMODES]; /* 请求锁的计数 */
int nRequested; /* requested数组总数 */
int granted[MAX_LOCKMODES]; /* 已获取锁的计数 */
int nGranted; /* granted数组总数 */
} LOCK;
PROCLOCK结构,主要是将同一锁对象等待和持有者的线程信息串联起来的结构体。对应的代码如下:
typedef struct PROCLOCK {
/* 标识 */
PROCLOCKTAG tag; /* proclock对象的唯一标识 */
/* 数据 */
LOCKMASK holdMask; /* 已获取锁类型的位掩码 */
LOCKMASK releaseMask; /* 预释放锁类型的位掩码 */
SHM_QUEUE lockLink; /* 指向锁对象链表的指针 */
SHM_QUEUE procLink; /* 指向PGPROC链表的指针 */
} PROCLOCK;
t_thrd.proc结构体里waitLock字段记录了该线程等待的锁,该结构体中procLocks字段将所有跟该锁有关的持有者和等着串起来,其队列关系如图5-16所示。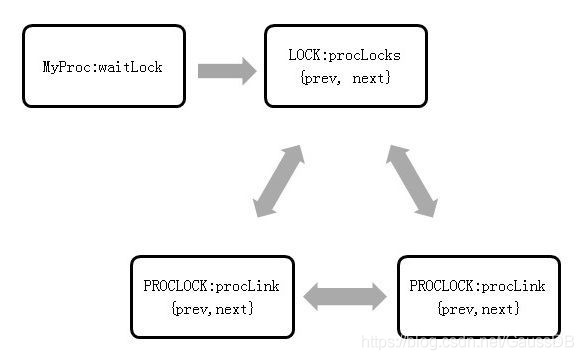
图5-16 t_thrd.proc结构体队列关系图
常规锁的主要函数如下。
(1) LockAcquire:对锁对象加锁。
(2) LockRelease:对锁对象释放锁。
(3 )LockReleaseAll:释放所有锁资源。
5.3.4 死锁检测机制
死锁主要是由于进程B要访问进程A所在的资源,而进程A又由于种种原因不释放掉其锁占用的资源,从而数据库就会一直处于阻塞状态。如图5-17中,T1使用资源R1去请求R2,而T2事务持有R2的资源去申请R1。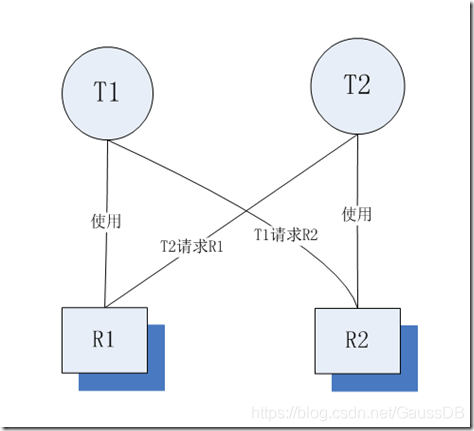
图5-17 死锁状态
形成死锁的必要条件是:资源的请求与保持。每一个进程都可以在使用一个资源的同时去申请访问另一个资源。打破死锁的常见处理方式:中断其中的一个事务的执行,打破环状的等待。openGauss提供了LWLock的死锁检测及常规锁的死锁检测机制,下面简单介绍一下相关原理及代码。
1. LWLock死锁检测自愈
openGauss使用一个独立的监控线程来完成轻量级锁的死锁探测、诊断和解除。工作线程在请求轻量级锁成功之前会写入一个时间戳数值,成功获得锁之后置该时间戳为0。监测线程可以通过快速对比时间戳数值来发现长时间获得不到锁资源的线程,这一过程是快速轻量的。只有发现长时间的锁等待,死锁检测的诊断才会触发。这么做的目的是防止频繁诊断影响业务正常执行能。一旦确定了死锁环的存在,监控线程首先会将死锁信息记录到日志中去,然后采取恢复措施使得死锁自愈,即选择死锁环中的一个线程报错退出。机制如图5-18所示。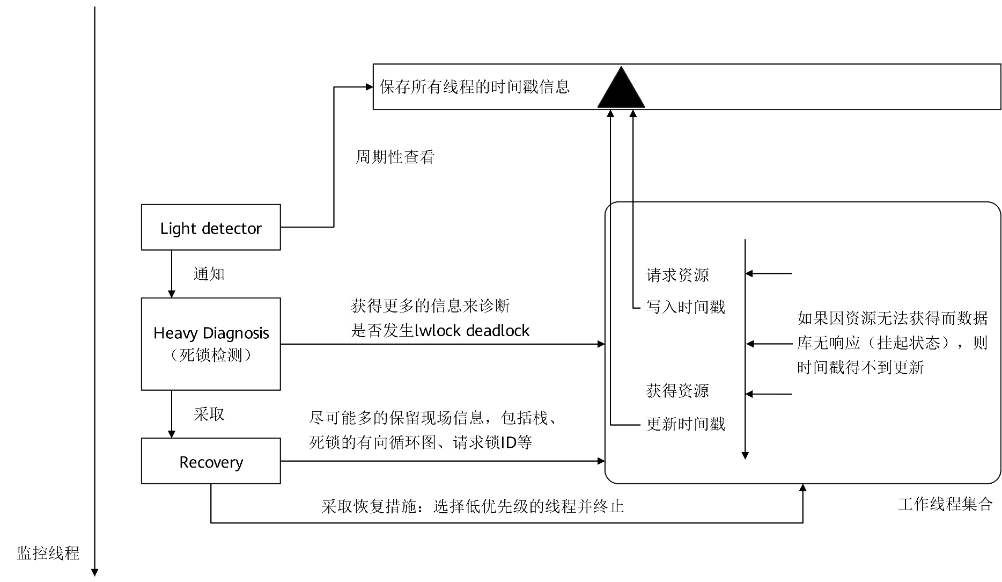
图5-18 LWLock死锁检测自愈
因为检测死锁是否真正发生是一个重CPU操作,为了不影响数据库性能和运行稳定性,轻量级死锁检测使用了一种轻量式的探测,用来快速判断是否可能发生了死锁。采用看门狗(watchdog)的方法,利用时间戳来探测。工作线程在锁请求进入时会在全局内存上写入开始等待的时间戳;在锁请求成功后,将该时间戳清0。对于一个发生死锁的线程,它的锁请求是wait状态,时间戳也不会清0,且与当前运行时间戳数值的差值越来越大。由GUC参数fault_mon_timeout控制检测间隔时间,默认为5s。LWLock死锁检测每隔fault_mon_timeout去进行检测,如果当前发现有同样线程、同样锁id,且时间戳等待时间超过检测间隔时间值,则触发真正死锁检测。时间统计及轻量级检测函数如下。
(1) pgstat_read_light_detect:从统计信息结构体中读取线程及锁id相关的时间戳,并记录到指针队列中。
(2) lwm_compare_light_detect:跟几秒检测之前的时间对比,如果找到可能发生死锁的线程及锁id则返回true,否则返回false。
真正的LWLock死锁检测是一个有向无环图的判定过程,它的实现跟常规锁类似,这部分会在下面一小节中详细介绍。死锁检测需要两部分的信息:锁,包括请求和分配的信息;线程,包括等待和持有的信息,这些信息记录到相应的全局变量中,死锁监控线程可以访问并进行判断。相关的函数如下。
(1) lwm_heavy_diagnosis:检测是否有死锁。
(2) lwm_deadlock_report:报告死锁详细信息,方便定位诊断。
(3) lw_deadlock_auto_healing:治愈死锁,选择环中一个线程退出。
用于死锁检测的锁和线程相关数据结构如下。
(1) lock_entry_id记录线程信息,有thread_id及sessionid是为了适配线程池框架,可以准确的从统计信息中找到相应的信息。对应的代码如下:
typedef struct {
ThreadId thread_id;
uint64 st_sessionid;
} lock_entry_id;
(2) lwm_light_detect记录可能出现死锁的线程,最后用一个链表的形式将当前所有信息串联起来。对应的代码如下:
typedef struct {
/* 线程ID */
lock_entry_id entry_id;
/* 轻量级锁检测引用计数 */
int lw_count;
} lwm_light_detect;
(3) lwm_lwlocks 记录线程相关的锁信息,持有锁数量,以及等锁信息。对应的代码如下:
typedef struct {
lock_entry_id be_tid; /* 线程ID */
int be_idx; /* 后台线程的位置 */
LWLockAddr want_lwlock; /* 预获取锁的信息 */
int lwlocks_num; /* 线程持有的轻量级锁个数 */
lwlock_id_mode* held_lwlocks; /* 线程持有的轻量级锁数组 */
} lwm_lwlocks;
2. 常规锁死锁检测
openGauss在获取锁时如果没有冲突可以直接上锁;如果有冲突则设置一个定时器timer,并进入等待,过一段时间会被timer唤起进行死锁检测。如果在某个锁的等锁队列中,进程T2排在进程T1后面,且进程T2需要获取的锁与T1需要获取的锁资源冲突,则T2到T1会有一条软等待边(soft edge)。如果进程T2的加锁请求与T1进程所持有的锁冲突,则有一条硬等待边(hard edge)。那么整体思路就是通过递归调用,从当前顶点等锁的顶点出发,沿着等待边向前走,看是否存在环,如果环中有soft edge,说明环中两个进程都在等锁,重新排序,尝试解决死锁冲突。如果没有soft edge,那么只能终止当前等锁的事务,解决死锁等待环。如图5-19所示,虚线代表soft edge,实线代表hard fdge。线程A等待线程B,线程B等待线程C,线程C等待线程A,因为线程A等待线程B的是soft edge,进行一次调整成为图5-19右边的等待关系,此时发现线程A等待线程C,线程C等待线程A,没有soft edge,检测到死锁。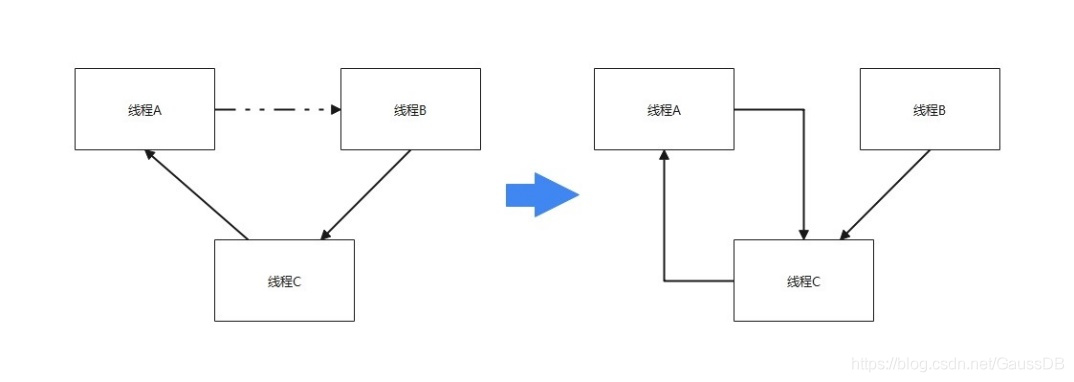
图5-19 常规锁死锁检测示意图
主要函数如下。
(1) DeadLockCheck:死锁检测函数。
(2) DeadLockCheckRecurse:如果死锁则返回true,如果有soft edge,返回false并且尝试解决死锁冲突。
(3) check_stack_depth:openGauss会检查死锁递归检测堆栈(死锁检测递归栈过长,会引发在死锁检测时,长期持有所有锁的LWLock分区,从而阻塞业务)。
(4) CheckDeadLockRunningTooLong:openGauss会检查死锁检测时间,防止死锁检测时间过长,阻塞后面所有业务。对应的代码如下:
static void CheckDeadLockRunningTooLong(int depth)
{ /* 每4层检测一下 */
if (depth > 0 && ((depth % 4) == 0)) {
TimestampTz now = GetCurrentTimestamp();
long secs = 0;
int usecs = 0;
if (now > t_thrd.storage_cxt.deadlock_checker_start_time) {
TimestampDifference(t_thrd.storage_cxt.deadlock_checker_start_time, now, &secs, &usecs);
if (secs > 600) { /* 如果从死锁检测开始超过十分钟,则报错处理。 */
#ifdef USE_ASSERT_CHECKING
DumpAllLocks();/* 在debug版本时,导出所有的锁信息,便于定位问题。 */
#endif
ereport(defence_errlevel(), (errcode(ERRCODE_INTERNAL_ERROR),
errmsg("Deadlock checker runs too long and is greater than 10 minutes.")));
}
}
}
}
(5) FindLockCycle:检查是否有死锁环。
(6) FindLockCycleRecurse:死锁检测内部递归调用函数。
相应的数据结构有:
(1) 死锁检测中最核心最关键的有向边数据结构。对应的代码如下:
typedef struct EDGE {
PGPROC *waiter; /* 等待的线程 */
PGPROC *blocker; /* 阻塞的线程 */
int pred; /* 拓扑排序的工作区 */
int link; /* 拓扑排序的工作区 */
} EDGE;
(2) 可重排的一个等待队列。对应的代码如下:
typedef struct WAIT_ORDER {
LOCK *lock; /* the lock whose wait queue is described */
PGPROC **procs; /* array of PGPROC *'s in new wait order */
int nProcs;
} WAIT_ORDER;
(3) 死锁检测最后打印的相应信息。对应的代码如下:
typedef struct DEADLOCK_INFO {
LOCKTAG locktag; /* 等待锁对象的唯一标识 */
LOCKMODE lockmode; /* 等待锁对象的锁类型 */
ThreadId pid; /* 阻塞线程的线程ID */
} DEADLOCK_INFO;
5.3.5 无锁原子操作
openGauss封装了32、64、128的原子操作,主要用于取代自旋锁,实现简单变量的原子更新操作。
(1) gs_atomic_add_32:32位原子加,并且返回加之后的值。对应的代码如下:
static inline int32 gs_atomic_add_32(volatile int32* ptr, int32 inc)
{
return __sync_fetch_and_add(ptr, inc) + inc;
}
(2) gs_atomic_add_64:64位原子加,并且返回加之后的值。对应的代码如下:
static inline int64 gs_atomic_add_64(int64* ptr, int64 inc)
{
return __sync_fetch_and_add(ptr, inc) + inc;
}
(3) gs_compare_and_swap_32:32位CAS操作,如果dest在更新前没有被更新,则将newval写到dest地址。dest地址的值没有被更新,就返回true;否则返回false。对应的代码如下:
static inline bool gs_compare_and_swap_32(int32* dest, int32 oldval, int32 newval)
{
if (oldval == newval)
return true;
volatile bool res = __sync_bool_compare_and_swap(dest, oldval, newval);
return res;
}
(4) gs_compare_and_swap_64:64位CAS操作,如果dest在更新前没有被更新,则将newval写到dest地址。dest地址的值没有被更新,就返回true;否则返回false。对应的代码如下:
static inline bool gs_compare_and_swap_64(int64* dest, int64 oldval, int64 newval)
{
if (oldval == newval)
return true;
return __sync_bool_compare_and_swap(dest, oldval, newval);
}
(5) arm_compare_and_swap_u128:openGauss提供跨平台的128位CAS操作,在ARM平台下,使用单独的指令集汇编了128位原子操作,用于提升内核测锁并发的性能,详情可以参考下一小结。对应的代码如下:
static inline uint128_u arm_compare_and_swap_u128(volatile uint128_u* ptr, uint128_u oldval, uint128_u newval)
{
#ifdef __ARM_LSE
return __lse_compare_and_swap_u128(ptr, oldval, newval);
#else
return __excl_compare_and_swap_u128(ptr, oldval, newval);
#endif
}
#endif
(6) atomic_compare_and_swap_u128:128位CAS操作,如果dest地址的值在更新前没有被其他线程更新,则将newval写到dest地址。dest地址的值没有被更新,就返回新值;否则返回被别人更新后的值。需要注意必须由上层的调用者保证传入的参数是128位对齐的。对应的代码如下:
static inline uint128_u atomic_compare_and_swap_u128(
volatile uint128_u* ptr,
uint128_u oldval = uint128_u{0},
uint128_u newval = uint128_u{0})
{
#ifdef __aarch64__
return arm_compare_and_swap_u128(ptr, oldval, newval);
#else
uint128_u ret;
ret.u128 = __sync_val_compare_and_swap(&ptr->u128, oldval.u128, newval.u128);
return ret;
#endif
}
5.3.6 基于鲲鹏服务器的性能优化
本章着重介绍openGauss基于硬件结构的锁相关的函数及结构体的性能优化。
1. WAL Group inset优化
数据库redo日志缓存系统指的是数据库redo日志持久化的写缓存,数据库redo日志落盘之前会写入到日志缓存中再写到磁盘进行持久化。日志缓存的写入效率是决定数据库整体吞吐量的主要因素,而各个线程之间写日志时为了保证日志顺序写存在锁争抢,锁的争抢就成为了性能的主要瓶颈点。openGauss针对鲲鹏服务器ARM CPU的特点,通过group的方式进行日志的插入,减少锁的争抢,提升WAL日志的插入效率,从而提升整个数据库的吞吐性能。group的方式主要流程如图5-20所示。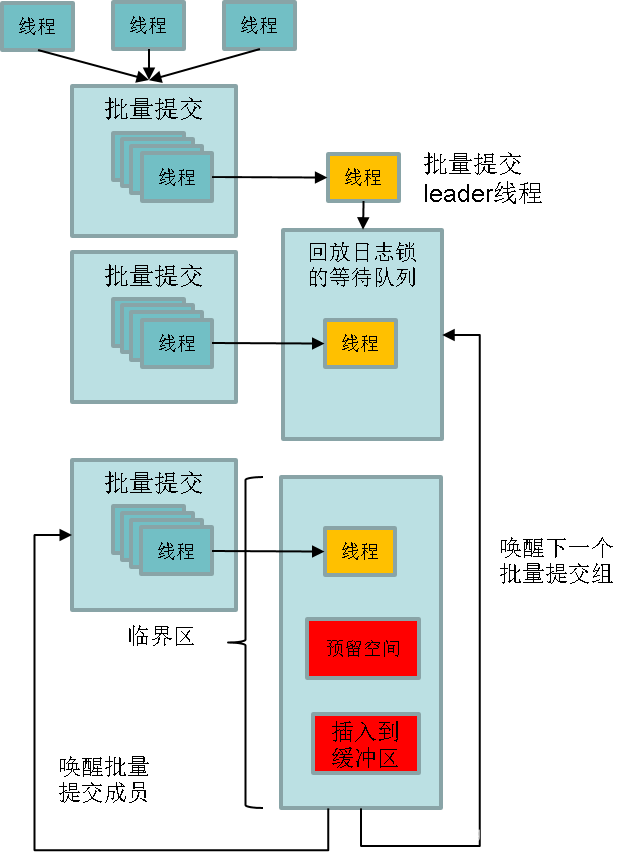
图5-20 group的方式日志插入
(1) 不需要所有线程都竞争锁。
(2) 在同一时间窗口所有线程在争抢锁之前先加入到一个group中,第一个加入group的线程作为leader。通过CAS原子操作来实现队列的管理。
(3) leader线程代表整个group去争抢锁。group中的其他线程(follower)开始睡眠,等待leader唤醒。
(4) 争抢到锁后,leader线程将group里的所有线程想要插入的日志遍历一遍得到需要空间总大小。leader线程只执行一次reserve space操作。
(5) leader线程将group中所有线程想要写入的日志都写入到日志缓冲区中。
(6) 释放锁,唤醒所有follower线程。
(7) follower线程由于需要写入的日志已经被leader写入,不需要再争抢锁,直接进入后续流程。
关键函数代码如下:
static XLogRecPtr XLogInsertRecordGroup(XLogRecData* rdata, XLogRecPtr fpw_lsn)
{
…/* 初始化变量以及简单校验 */
START_CRIT_SECTION(); /* 开启临界区 */
proc->xlogGroupMember = true;
…
proc->xlogGroupDoPageWrites = &t_thrd.xlog_cxt.doPageWrites;
nextidx = pg_atomic_read_u32(&t_thrd.shemem_ptr_cxt.LocalGroupWALInsertLocks[groupnum].l.xlogGroupFirst);
while (true) {
pg_atomic_write_u32(&proc->xlogGroupNext, nextidx); /* 将上一个成员记录到proc结构体中 */
/* 防止ARM乱序:保证所有前面的写操作都可见 */
pg_write_barrier();
if (pg_atomic_compare_exchange_u32(&t_thrd.shemem_ptr_cxt.LocalGroupWALInsertLocks[groupnum].l.xlogGroupFirst,
&nextidx,
(uint32)proc->pgprocno)) {
break;
} /* 这一步原子操作获取上一个成员的proc no,如果是invalid,说明是leader。 */
}
/* 非leader成员不去获取WAL Insert锁,仅仅进行等待,直到被leader唤醒 */
if (nextidx != INVALID_PGPROCNO) {
int extraWaits = 0;
for (;;) {
/* 充当读屏障 */
PGSemaphoreLock(&proc->sem, false);
/* 充当读屏障 */
pg_memory_barrier();
if (!proc->xlogGroupMember) {
break;
}
extraWaits++;
}
while (extraWaits-- > 0) {
PGSemaphoreUnlock(&proc->sem);
}
END_CRIT_SECTION();
return proc->xlogGroupReturntRecPtr;
}
/* leader成员持有锁 */
WALInsertLockAcquire();
/* 计算每个成员线程的xlog record size */
…
/* leader线程将所有成员线程的xlog record插入到缓冲区 */
while (nextidx != INVALID_PGPROCNO) {
localProc = g_instance.proc_base_all_procs[nextidx];
if (unlikely(localProc->xlogGroupIsFPW)) {
nextidx = pg_atomic_read_u32(&localProc->xlogGroupNext);
localProc->xlogGroupIsFPW = false;
continue;
}
XLogInsertRecordNolock(localProc->xlogGrouprdata,
localProc,
XLogBytePosToRecPtr(StartBytePos),
XLogBytePosToEndRecPtr(
StartBytePos + MAXALIGN(((XLogRecord*)(localProc->xlogGrouprdata->data))->xl_tot_len)),
XLogBytePosToRecPtr(PrevBytePos));
PrevBytePos = StartBytePos;
StartBytePos += MAXALIGN(((XLogRecord*)(localProc->xlogGrouprdata->data))->xl_tot_len);
nextidx = pg_atomic_read_u32(&localProc->xlogGroupNext);
}
WALInsertLockRelease(); /* 完成工作放锁并唤醒所有成员线程 */
while (wakeidx != INVALID_PGPROCNO) {
PGPROC* proc = g_instance.proc_base_all_procs[wakeidx];
wakeidx = pg_atomic_read_u32(&proc->xlogGroupNext);
pg_atomic_write_u32(&proc->xlogGroupNext, INVALID_PGPROCNO);
proc->xlogGroupMember = false;
pg_memory_barrier();
if (proc != t_thrd.proc) {
PGSemaphoreUnlock(&proc->sem);
}
}
END_CRIT_SECTION();
return proc->xlogGroupReturntRecPtr;
}
2. Cache align消除伪共享
CPU在访问主存时一次会获取整个缓存行的数据,其中x86典型值是64字节,而ARM 1620芯片L1和L2缓存都是64字节,L3缓存是128字节。这种数据获取方式本身可以大大提升数据访问的效率,但是假如同一个缓存行中不同位置的数据频繁被不同的线程读取和写入,由于写入的时候会造成其他CPU下的同一个缓存行失效,从而使得CPU按照缓存行来获取主存数据的努力不但白费,反而成为性能负担。伪共享就是指这种不同的CPU同时访问相同缓存行的不同位置的性能低效的行为。
以LWLock为例,代码如下所示:
#ifdef __aarch64__
#define LWLOCK_PADDED_SIZE PG_CACHE_LINE_SIZE(128)
#else
#define LWLOCK_PADDED_SIZE (sizeof(LWLock) <= 32 ? 32 : 64)
#endif
typedef union LWLockPadded
{
LWLocklock;
charpad[LWLOCK_PADDED_SIZE];
} LWLockPadded;
当前锁逻辑中LWLock的访问仍然是最突出的热点之一。如果LWLOCK_PADDED_SIZE是32字节,且LWLock是按照一个连续的数组来存储的,对于64字节的缓存行可以同时容纳两个LWLockPadded,128字节的缓存行则可以同时含有4个LWLockPadded。当系统中对LWLock竞争激烈时,对应的缓存行不停地获取和失效,浪费大量CPU资源。故在ARM机器的优化下将padding_size直接设置为128,消除伪共享,提升整体LWLock的使用性能。
3. WAL INSERT 128CAS无锁临界区保护
目前数据库或文件系统,WAL需要把内存中生成的日志信息插入到日志缓存中。为了实现日志高速缓存,日志管理系统会并发插入,通过预留全局位置来完成,一般使用两个64位的全局数据位置索引分别表示存储插入的起始和结束位置,最大能提供16EB(Exabyte)的数据索引的支持。为了保护全局的位置索引,WAL引入了一个高性能的原子锁实现每个日志缓存位置的保护,在NUMA架构中,特别是ARM架构中,由于原子锁退避和高跨CPU访问延迟,缓存一致性性能差异导致WAL并发的缓存保护成为瓶颈。
优化的主要涉及思想是将两个64位的全局数据位置信息通过128位原子操作替换原子锁,消除原子锁本身在跨CPU访问、原子锁退避(backoff)、缓存一致性代价。如图5-21所示。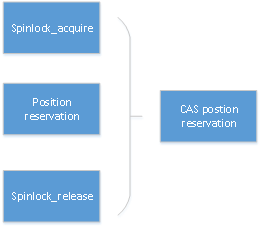
图5-21 128CAS无锁临界区保护示意图
全局位置信息包括一个64位起始地址和一个64位的结束地址,将这两个地址合并成为一个128位信息,通过CAS原子操作完成免锁位置信息的预留。在ARM平台中没有实现128位的原子操作库,openGauss通过exclusive命令加载两个ARM64位数据来实现,ARM64汇编指令为LDXP/STXP。
关键数据结构及函数ReserveXLogInsertLocation的代码如下:
typedef union {
uint128 u128;
uint64 u64[2];
uint32 u32[4];
} uint128_u; /* 为了代码可读及操作,将u128设计成union的联合结构体,内存位置进行64位数值的赋值。 */
static void ReserveXLogInsertLocation(uint32 size, XLogRecPtr* StartPos, XLogRecPtr* EndPos, XLogRecPtr* PrevPtr)
{
volatile XLogCtlInsert* Insert = &t_thrd.shemem_ptr_cxt.XLogCtl->Insert;
uint64 startbytepos;
uint64 endbytepos;
uint64 prevbytepos;
size = MAXALIGN(size);
#if defined(__x86_64__) || defined(__aarch64__)
uint128_u compare;
uint128_u exchange;
uint128_u current;
compare = atomic_compare_and_swap_u128((uint128_u*)&Insert->CurrBytePos);
loop1:
startbytepos = compare.u64[0];
endbytepos = startbytepos + size;
exchange.u64[0] = endbytepos; /* 此处为了代码可读,将uint128设置成一个union的联合结构体。将起始和结束位置写入到exchange中。 */
exchange.u64[1] = startbytepos;
current = atomic_compare_and_swap_u128((uint128_u*)&Insert->CurrBytePos, compare, exchange);
if (!UINT128_IS_EQUAL(compare, current)) { /* 如果被其他线程并发更新,重新循环*/
UINT128_COPY(compare, current);
goto loop1;
}
prevbytepos = compare.u64[1];
#else
SpinLockAcquire(&Insert->insertpos_lck); /* 其余平台使用自旋锁原子锁来保护变量更新 */
startbytepos = Insert->CurrBytePos;
prevbytepos = Insert->PrevBytePos;
endbytepos = startbytepos + size;
Insert->CurrBytePos = endbytepos;
Insert->PrevBytePos = startbytepos;
SpinLockRelease(&Insert->insertpos_lck);
#endif /* __x86_64__|| __aarch64__ */
*StartPos = XLogBytePosToRecPtr(startbytepos);
*EndPos = XLogBytePosToEndRecPtr(endbytepos);
*PrevPtr = XLogBytePosToRecPtr(prevbytepos);
}
4. CLOG Partition优化
CLOG日志即是事务提交日志(详情可参考章节“5.2.2 事务ID分配及CLOG/CSNLOG)”,每个事务存在4种状态:IN_PROGRESS、COMMITED、ABORTED、SUB_COMMITED,每条日志占2 bit。CLOG日志需要存储在磁盘上,一个页面(8kB)可以包含215条,每个日志文件(段=256 x 8k)226条。当前CLOG的访问通过缓冲池实现,代码中使用统一的SLRU缓冲池算法。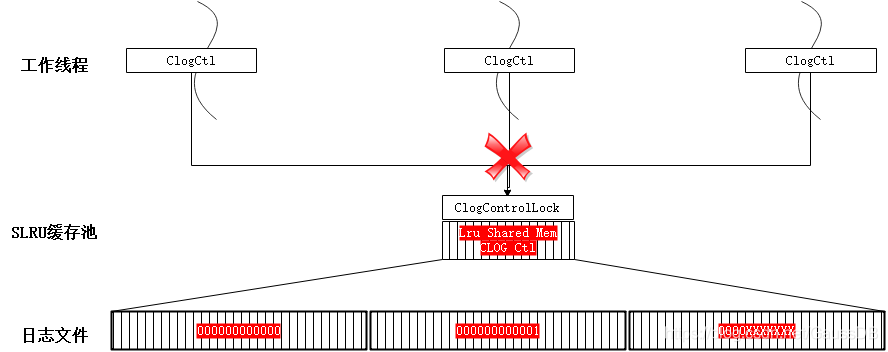
图5-23 CLOG的日志缓冲池优化后
如图5-22所示,CLOG的日志缓冲池在共享内存中且全局唯一,名称为名称为“CLOG Ctl”,为各工作线程共享该资源。在高并发的场景下,该资源的竞争成为性能瓶颈,优化分区后如图5-23。按页面号进行取模运算(求两个数相除的余数)将日志均分到多个共享内存的缓冲池中,由线程局部对象的数组ClogCtlData来记录,名称为“CLOG Ctl i”,同步增加共享内存中的缓冲池对象及对应的全局锁。也就是通过打散的方式提高整体吞吐。
CLOG分区优化需要将源代码中涉及原缓冲池的操作进行修改,改为操作对应的分区的缓冲池,而通过事务id、页面号能方便地找到对应的分区,与此同时对应的控制锁也从原来的一把锁改为多把锁的操作,涉及的结构体代码如下,涉及的函数如表5-8所示:
/* CLOG分区*/
#define NUM_CLOG_PARTITIONS 256 /*分区打散的个数*/
/* CLOG轻量级分区锁*/
#define CBufHashPartition(hashcode) \
((hashcode) % NUM_CLOG_PARTITIONS)
#define CBufMappingPartitionLock(hashcode) \
(&t_thrd.shemem_ptr_cxt.mainLWLockArray[FirstCBufMappingLock + CBufHashPartition(hashcode)].lock)
#define CBufMappingPartitionLockByIndex(i) \
(&t_thrd.shemem_ptr_cxt.mainLWLockArray[FirstCBufMappingLock + i].lock)
表5-8 CLOG分区优化函数
CLOGShmemInit
调用SimpleLruInit 初始化共享内存中的CLOG缓冲区
ZeroCLOGPage
CLOG日志页面的初始化为0
BootStrapCLOG
创建数据库时,在缓冲区中创建初始可用的CLOG日志页面,并调用 ZeroCLOGPage初始化页面为0,写回到磁盘,并返回页面
CLogSetTreeStatus
设置事务提交的最终状态
CLogGetStatus
查询事务状态
ShutdownCLOG
关闭缓冲区,刷新到磁盘中
ExtendCLOG
为新分配的事务,创建CLOG页面
TruncateCLOG
日志检查点的建立使得部分事务的日志过期,可删除以节省空间
WriteZeroPageXlogRec
新建XLOG页面时,写“CLOG_ZEROPAGE” XLOG日志,以便将来恢复使用
clog_redo
CLOG日志相关的 redo 操作,含CLOG_ZEROPAGE及CLOG_TRUNCATE
5. 支持NUMA-aware数据和线程访问分布
NUMA远端访问:内存访问涉及访问线程和被访问内存两个的物理位置。只有两者在同一个NUMA Node中时,内存访问才是本地的,否则就会涉及跨Node远端访问,此时性能开销较大。
Numactl开源软件提供了libnuma库允许应用程序方便地将线程绑定在特定的NUMA Node或者CPU列表,可以在指定的NUMA Node上分配内存。下面对openGauss代码可能涉及的api进行描述。
(1) “int numa_run_on_node(int node);”将当前任务及子任务运行在指定的Node上。该API对应函数如下所示。
numa_run_on_node函数在特定节点上运行当前任务及其子任务。在使用numa_run_on_node_mask函数重置节点关联之前,这些任务不会迁移到其他节点的CPU上。传递-1让内核再次在所有节点上调度。成功时返回0;错误-1时返回,错误码记录在errno中。
(2) “void numa_set_localalloc(void);”将调用者线程的内存分配策略设置为本地分配,即优先从本节点进行内存分配。该API对应函数如下所示。
numa_set_localalloc函数 设置调用任务的内存分配策略为本地分配。在此模式下,内存分配的首选节点为内存分配时任务正在执行的节点。
(3) “void numa_alloc_onnode(void);”在指定的NUMA Node上申请内存。该API对应函数如下所示。
numa_alloc_onnode函数在特定节点上分配内存。分配大小为系统页的倍数并向上取整。如果指定的节点在外部拒绝此进程,则此调用将失败。与函数系列Malloc(3)相比,此函数相对较慢。必须使用numa_free函数释放内存。错误时返回NULL。
openGauss基于NUMA架构进行了内部数据结构优化。
1) 全局PGPROC数组优化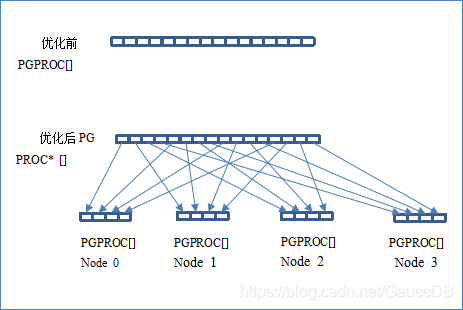
图5-24 全局PGPROC数组优化
如图5-24所示,对每个客户端连接系统都会分配一个专门的PGPROC结构来维护相关信息。ProcGlobal->allProcs原本是一个PGPROC结构的全局数组,但是其物理内存所在的NUMA Node是不确定的,造成每个事务线程访问自己的PGPROC结构时,线程可能由于操作系统的调度在多个NUMA Node间,而对应的PGPROC结构的物理内存位置也是无法预知,大概率会是远端访存。
由于PGPROC结构的访问较为频繁,根据NUMA Node的个数将这个全局结构数组分为多份,每份分别使用numa_alloc_onnode来固定NUMA Node分配内存。为了尽量减少对当前代码的结构性改动,将ProcGlobal->allProcs由PGPROC* 改为PGPROC**。对应所有访问ProcGlobal->allProcs的地方均需要做相应调整(多了一层间接指针引用)。相关代码如下:
#ifdef __USE_NUMA
if (nNumaNodes > 1) {
ereport(INFO, (errmsg("InitProcGlobal nNumaNodes: %d, inheritThreadPool: %d, groupNum: %d",
nNumaNodes, g_instance.numa_cxt.inheritThreadPool,
(g_threadPoolControler ? g_threadPoolControler->GetGroupNum() : 0))));
int groupProcCount = (TotalProcs + nNumaNodes - 1) / nNumaNodes;
size_t allocSize = groupProcCount * sizeof(PGPROC);
for (int nodeNo = 0; nodeNo < nNumaNodes; nodeNo++) {
initProcs[nodeNo] = (PGPROC *)numa_alloc_onnode(allocSize, nodeNo);
if (!initProcs[nodeNo]) {
ereport(FATAL, (errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("InitProcGlobal NUMA memory allocation in node %d failed.", nodeNo)));
}
add_numa_alloc_info(initProcs[nodeNo], allocSize);
int ret = memset_s(initProcs[nodeNo], groupProcCount * sizeof(PGPROC), 0, groupProcCount * sizeof(PGPROC));
securec_check_c(ret, "\0", "\0");
}
} else {
#endif
2) 全局WALInsertLock数组优化
WALInsertLock用来对WAL Insert操作进行并发保护,可以配置多个,比如16。优化前,所有的WALInsertLock都在同一个全局数组,并通过共享内存进行分配。事务线程运行时在整个全局数组中分配其中的一个Insert Lock进行使用,因此大概率会涉及远端访存,即多个线程会进行跨Node、跨P竞争。WALInsertLock也可以按NUMA Node单独分配内存,并且每个事务线程仅使用本Node分组内的WALInsertLock,这样就可以将数据竞争限定在同一个NUMA Node内部。基本原理如图5-25所示。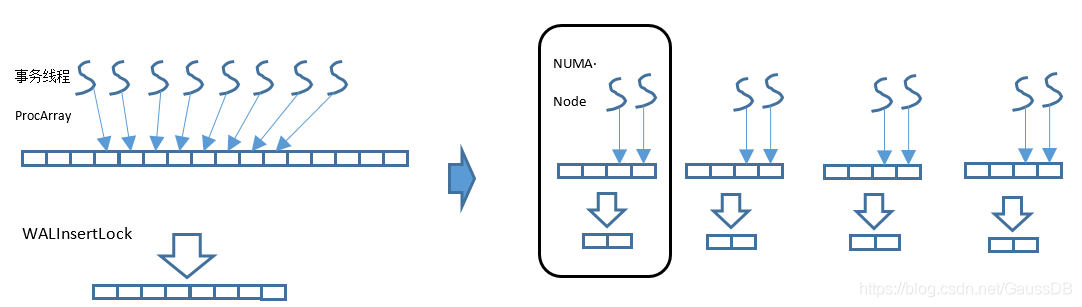
图5-25 全局WALInsertLock数组优化原理
假如系统配置了16个WALInsertLock,同时NUMA Node配置为4个,则原本长度为16的数组将会被拆分为4个数组,每个数组长度为4。全局结构体为“WALInsertLockPadded **GlobalWALInsertLocks”,线程本地WALInsertLocks将由指向本Node内的WALInsertLock[4],不同的NUMA Node下拥有不同地址的WALInsertLock子数组。GlobalWALInsertLocks则用于跟踪多个Node下的WALInsertLock数组,以方便遍历。WALInsertLock分组方式如图5-26所示。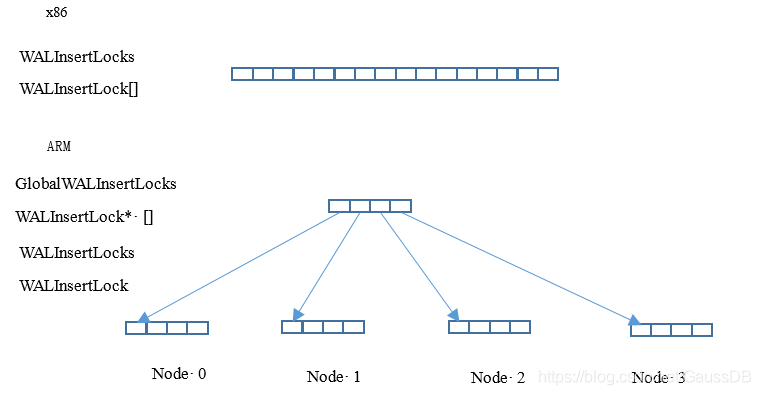
图5-26 WALInsertLock分组示意图
初始化WALInsertLock结构体的代码如下:
WALInsertLockPadded** insertLockGroupPtr =
(WALInsertLockPadded**)CACHELINEALIGN(palloc0(nNumaNodes * sizeof(WALInsertLockPadded*) + PG_CACHE_LINE_SIZE));
#ifdef __USE_NUMA
if (nNumaNodes > 1) {
size_t allocSize = sizeof(WALInsertLockPadded) * g_instance.xlog_cxt.num_locks_in_group + PG_CACHE_LINE_SIZE;
for (int i = 0; i < nNumaNodes; i++) {
char* pInsertLock = (char*)numa_alloc_onnode(allocSize, i);
if (pInsertLock == NULL) {
ereport(PANIC, (errmsg("XLOGShmemInit could not alloc memory on node %d", i)));
}
add_numa_alloc_info(pInsertLock, allocSize);
insertLockGroupPtr[i] = (WALInsertLockPadded*)(CACHELINEALIGN(pInsertLock));
}
} else {
#endif
char* pInsertLock = (char*)CACHELINEALIGN(palloc(
sizeof(WALInsertLockPadded) * g_instance.attr.attr_storage.num_xloginsert_locks + PG_CACHE_LINE_SIZE));
insertLockGroupPtr[0] = (WALInsertLockPadded*)(CACHELINEALIGN(pInsertLock));
#ifdef __USE_NUMA
}
#endif
在ARM平台下,访问WALInsertLock需遍历GlobalWALInsertLocks两维数组,第一层遍历NUMA Node,第二层遍历Node内部的WALInsertLock数组。
WALInsertLock引用的LWLock内存结构在ARM平台下也进行的相应的优化适配,代码如下所示:
typedef struct
{
LWLock lock;
#ifdef __aarch64__
pg_atomic_uint32xlogGroupFirst;
#endif
XLogRecPtrinsertingAt;
} WALInsertLock;
这里的lock成员变量将引用共享内存中的全局LWLock数组中的某个元素,在WALInsertLock优化之后,尽管WALInsertLock已经按照NUMA Node分布了,但是其引用的LWLock却无法控制其物理内存位置,因此在访问WALInsertLock的lock时仍然涉及了大量的跨Node竞争。因此将LWLock直接嵌入到WALInsertLock内部,从而将使用的LWLock一起进行NUMA分布,同时还减少了一次缓存访问。
5.4 小结
本章主要介绍了openGauss事务及并发控制的机制。
事务系统将SQL、执行及存储模块串联起来,是数据库的重要角色:收到外部命令,根据当前内部系统状态,决定执行走向。保证了事务处理的连贯性及正确性。
本章除了介绍openGauss最基础最核心的事务系统外,还详细描述了openGauss是如何基于鲲鹏服务器做出性能优化的。
总而言之,用“急如闪电,稳如泰山”来形容openGauss的事务及并发控制模块是最适合不过了。
第五章事务机制源码解析的全部内容将告一段落,下一篇我们开启第六章“SQL引擎源解析”的相关内容的介绍。敬请期待。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK