

Binary Trees are optimal… except when they’re not. | Harder, Better, Faster, Str...
source link: https://hbfs.wordpress.com/2021/07/20/binary-trees-are-optimal-except-when-theyre-not/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Binary Trees are optimal… except when they’re not.
The best case depth for a search tree is 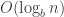


While it’s true that an optimal search tree will have depth 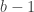
If we use a naïve comparison scheme, each keys ask for two (potentially expensive) comparisons. One to test if the sought value, 

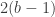
The main problem with this straightforward approach is that comparisons can be very expensive. While comparing two integral types (int and the like) is often thought of as “free”, comparing string is expensive. So you clearly do not want to test two strings twice, once for < and once for =. The much better approach is to use a three-way comparison, also known as the “spaceship operator”.
The spaceship operator, <=> is C++20’s version of C’s old timey qsort comparison function (it is in fact much better because it also automagically provides all comparison operators). Basically, a<=>b can return <0 if a<b, 0 if they’re equal, and >0 if a>b. We can therefore store the result of the expensive comparison, then do inexpensive comparisons for the result. That reduces the number of expensive comparisons to
The search complexity, counting the number of comparisons in the worst case for the best-case tree is

a strictly increasing function in 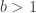
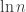


We therefore conclude that 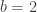
Except when it isn’t
We have neglected, or rather abstracted, something important: the cost of accessing the node. In main memory, it’s very convenient to suppose that reading a node is free, that is, incurs no cost. That’s of course false, because even reading from cache incurs a delay; fortunately very small. It is even more false if we read the node from disk (yes, even NVMe). A classical spinning rust disk reading a block will cause a few millisecond delay, that may be really, really expensive relative to the comparison of two keys (once they’re) in memory.
The new cost function to optimize will be
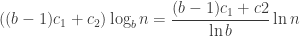
with 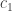
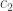

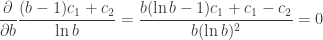
for
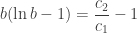
isn’t algebraic. We must use a numerical solution to the Lambert W Function. It gives us, with 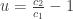

The following graph shows the function’s surface with 


To conclude, binary trees are optimal when we ignore the cost of accessing a node, but they aren’t when it becomes costly to access a node. When we access the nodes on disk, with a high cost, it becomes interesting to bundles many keys in a node, and we gave the optimal solution. However, the problem is often solved quite more directly. We just fit as many keys as possible in an I/O block. Disks operates on small blocks of (typically) 512 bytes, but file systems operate in somewhat larger, but fixed-sized blocks, something like 4 or 8k. A good strategy is therefore to fit as many keys as possible in that block, since even if the number of comparisons is large, it will still be faster than bringing that block into main memory.
This entry was posted on Tuesday, July 20th, 2021 at 2:52 am and is filed under Uncategorized. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.
Post navigation
« Previous PostRecommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK