

我是小R,昨晚我好像把B站搞崩了!!!
source link: https://my.oschina.net/u/3944379/blog/5130654
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

我是小R,昨晚我好像把B站搞崩了!!! - yes的练级攻略的个人空间 - OSCHINA - 中文开源技术交流社区
我是小 R,每天晚上我都会去逛 B 站。
看可爱的贝贝子吃播。
由于来来回回千百次了,对于去 B 站的路,我非常熟悉。
说到去 B 站的路,我依稀记得第一次去的时候,那拐的山路十八弯都给我绕晕了。
首先我从浏览器出发,经过域名解析(DNS),拿到了一个 CNAME ,我一看 xxx.cdn.ababa就知道 B 站是上了 CDN 啦,很正常这么大的网站不上 CDN 是不可能的。
拿到这个 CDN 的网址后,我就去访问了这个 CDN 服务商的权威 DNS,CDN 厂商根据我的地理位置等其他负载策略返回了一个 最合适我的 CDN 缓存节点的 IP,之后我就一直去请求这个 IP 啦。
当然,我是一个有学问的小 R ,我知道如果我的访问不命中 CDN 缓存的话,CDN 服务器就会去源站(B站)请求得到响应,然后缓存并返回。
所以本质上 CDN 节点就是一个缓存,它减轻了源站(B站)的负载,并且由于 CDN 节点遍布全国,所以挑选距离我们最近、最佳的节点供我们服务,也提高了响应速度。
不扯 CDN 了,咱们继续说说去 B 站的路。
B 站当然不会只有一个数据中心,根据前端负载均衡我被划到了上海的数据中心。
而数据中心内部,又有一个负载均衡器,它的作用主要是均匀的将请求分发给后面的服务、并且识别异常的服务、进行节点的扩容,减少错误,提高可用性。
据我所知,这个负载均衡的算法,B站也颇有研究。
他们发现 CPU 忙时、闲时占用率过大,对每个请求来说,不同请求的成本是不一样的,有些请求耗时,有些请求很轻量,所以即便做了均衡的流量分发,但是从负载的角度来看,实际上还是不均匀的。
并且又有物理机环境上的差异,因为 B 站通常都是分年采购服务器,新买的服务器通常主频 CPU 会更强一些,所以服务器本质上很难做到强同质。
画外音:别问我为什么知道,这是B站总监和我说的,嘻嘻。
所以 B 站使用 the choice-of-2 算法,随机选取的两个节点进行打分,选择更优的节点:

就这样通过负载均衡算法的分配,我来到了一个服务里,我发现它们还实现了一个叫quota-server的分布式限流!
这个服务的负责人跟我说,“无论负载均衡策略如何高效,系统某个部分总会过载,所以他们会先考虑优雅降级,返回低质量的结果,提供有损服务。在最差的情况,妥善的限流来保证服务本身稳定。”
我想了想,确实有道理!这个负责人还说,他们这个分布式限流服务是基于过去时间的滑动窗口内的 inflight (就理解为最近的请求量历史值)来做配额,每次服务会向 quota-server 申请一批配额到本地,这样客户端请求的时候可以直接消费服务本地的配额,而不用每次都去 quota-server 申请。并且在算法层面,采用了最大最小公平算法,解决某个大消耗者导致的饥饿。
我听了直呼666,心中默默的给 B 站比了个大拇指。
没想到这个服务的负责人好像一下子打开了话匣子。
“我们客户端还做了截流,因为当服务出现限流的时候,客户端可能会一直请求,使得服务端还得忙着返回限流啦,限流啦。所以为了进一步减轻服务端的负载,我们对客户端截流,使之在限流时请求发不到网络层,具体是参考 Google SRE里一个有意思的公式,max(0, (requests- K*accepts) / (requests + 1)),客户端直接发生请求,当达到限制,直接进行概率截流,怎么样是不是很厉害?”
这次,我直接给了他两个大拇指。
“想必你还不知道我们是如何开启限流的吧?我们是基于 CPU 的负载来判断压力的,我们将 CPU的滑动均值(CPU > 800 )作为启发阈值,一旦触发就进入到过载保护阶段。算法为:(MaxPass * AvgRT) < InFlight。其中MaxPass、AvgRT都为触发前的滑动时间窗口的统计值。”
“我们还使用了冷却时间,防止限流生效短时间内的CPU下降,导致大量请求被放行,瞬间又打满CPU的情况。”
这次,我直接给了他两个大拇指,外加一个脚拇指,考虑的真周到!
“当然,基于限流或者其他错误,我们还是有重试的,为了防止重试对已经过载的服务造成更大的压力,我们限制重试的次数,并采用周期性的重试时间,逐渐递增。比如100ms重试一次不行,等300ms再重试一次,还是不行再等500ms重试一次这样。”
“对了,还有服务间的超时也很重要。特别是高并发下,如果有高延迟服务,因为下游延时长,导致请求堆积,引发线程阻塞,而请求流量还在不断涌入,最终引发故障,导致雪崩,然后服务全面崩盘,3.25打在公屏上。”
“所以出现这种情况,应该要采用 Fail-fast,不要拖着等待,直接快速失败,这样请求就不会堆积,保证了整体服务的稳定。”
“所以可以定义一个全局的时间,然后每个服务调用前判断一下剩余的时候够不够消费,如果不够直接返回,切断下游的继续调用,节省资源。”
说了之后,负责人看了我一眼。我心领神会,直接给了他两个大拇指,外加两个脚拇指!
负责人满意的点了点头,我再给你汇总一下咯。
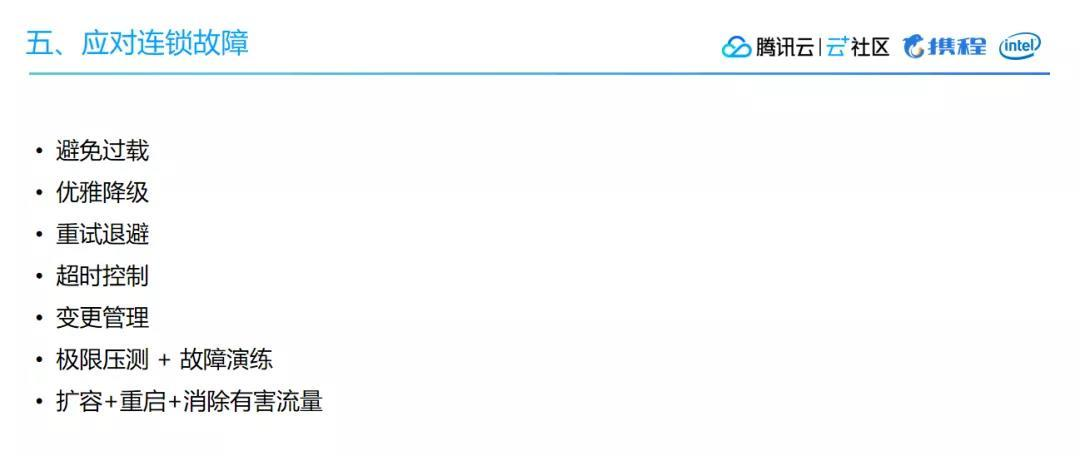
第一次去B站,负责人就给我盘了这么多。你看,B站的路确实不好走吧,需要经历这么多管制,B站不愧是个大公司呢!
好了,不跟你们说了,我要去看贝贝子吃播啦~
我去也!!
我去也!!!
怎么回事,我家网络坏了?等我重启下电脑!
好了,路由器重新插拔了,电脑也重启了,我去也!!!!!
wtf???那个负责人,你说说到底咋回事?不是天衣无缝了嘛!!
还我一天大会员!!!
这篇文章于7.14号午休期间匆忙BB而出,如有错误还请包涵和指正。
本人不是B站员工,也不了解 B 站的架构,以上故事,参考 B 站技术总监毛剑老师在「云加社区沙龙online」的分享整理。
网址如下:https://cloud.tencent.com/developer/article/1618923
故事瞎编,如有雷同,纯属你抄我。其中的调侃也是为了剧情需要,我还是很热爱 B 站的,每天都看。
故事说完了,我再来瞎分析一波。
一开始是 502 错误,我估计是 CDN 厂商出了问题,导致流量都打到 B 站去,这时候网关拦了,开始降级限流等。
但是晚上那个时候应该是流量高峰期,大家都下班回家看视频,导致一下子流量洪峰过高,并且由于 B 站挂了,大家都想去瞅一瞅,这下更雪上加霜,B站一下子 hold 不足,然后瞬间网关也挂了,产生雪崩,后面都挂了,于是导致了后面的404,服务直接找不到了。
由于级联挂的太多,服务又很多,盘子太大,所以启动没这么快,所以导致很久都没恢复,期间我估计事情扩散,又有很多人去访问...所以就比较难。
至于火灾的话,上海消防局辟谣了,没有发生火灾。
说断电的,机房不可能没备用电源(发电机)。
据网友反馈,国外的也看不了,我觉得很奇怪。
异地多活,我觉得 B 站应该有的,但是好像这次是全国各地都访问不了?我也不知道具体的....
官方的是这样回复的,所以啥都看不出来,坐等着 B站的技术人员来一波分析?
我估计这个事情一出,又会有大厂面试题:你如何看待7.13日晚 B 站挂了的情况?
所以下篇我再借着 B 站挂了的情况,从面试的角度来讲讲,关注我等着哈。
关于面试题,这里推荐有个仓库,汇总了好多面试题
欢迎关注我的公众号【yes的练级攻略】,更多硬核文章等你来读。
我是yes,我们下篇见。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK