

从统计学角度来看深度学习(1):递归广义线性模型
source link: https://cosx.org/2015/05/a-statistical-view-of-deep-learning-i-recursive-glms/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
从统计学角度来看深度学习(1):递归广义线性模型
Shakir Mohamed
翻译:王小宁;审校:冯凌秉、朱雪宁;编辑:王小宁
原文链接:http://blog.shakirm.com/2015/01/a-statistical-view-of-deep-learning-i-recursive-glms/
本文得到了原英文作者 Shakir Mohamed 的授权同意,由王小宁翻译、冯凌秉和朱雪宁审校。感谢他们的支持和帮助。
深度学习及其应用已经成为实用机器学习的一个关键工具。神经网络和许多现有的统计学、机器学习方法有同等重要的地位,我将在这篇文章中探索其中的一个观点。
看待深度神经网络,我们这里选择一个特别的角度:就是它可以被看做是一个递归的广义线性模型。广义线性模型作为概率建模的基石之一,在实验科学的应用中无处不在,并且极其实用。这篇文章集中讨论前馈神经网络(Feed Forward Neural Network),而关于回馈式神经网络(Recurrent Network)与前者的统计联系,我将在以后文章中讨论。
广义线性模型(GLMs)
基本的线性回归模型是一个从由自变量 X 组成的 P 维空间到一组因变量 Y 组成的空间的线性映射。具体地,该线性映射是指通过一组权重 (或回归系数) 对 X 进行加权,并与截距项 的和。线性回归的输出可以是多元的, 但在本文中假定其输出为标量。完整的概率模型假定上述线性模型受到高斯噪音的干扰(一般假设其方差未知)。
η=βTx+β0
y=η+ϵϵ∼N(0,σ2)
在此公式中, η是该模型的系统成分, η是随机扰动项。广义线性模型(GLMs) [2] 使我们能够对这一模型进行扩展,允许因变量的分布不局限于高斯分布而扩展到更广泛的分布(例如典型的指数分布族)。在这种情况下,我们可以写出广义回归问题,结合系数和偏置为更紧凑的表示法,如:
η=β⊤x,β=[ˆβ,β0],x=[ˆx,1]
E[y]=μ=g−1(η)
其中 g(•) 是连接函数,使我们能够从自然参数η求出均值参数μ 。如果把这个连接函数定义成是逻辑斯蒂函数,那么均值参数对应着服从伯努利分布的 y 等于 1 或 0 的概率。
有很多其他的连接函数让我们能够为目标(响应)变量 y 的分布做出不同假设。在深度学习中,连结函数一般指激活函数,我在下表中列出了它们在两个领域中的名称。从这个表中我们可以看出,很多流行的方法在神经网络与统计学中是一样的,但是在相关文献中(有时)有着完全不一样的名字,如统计中的多项分类回归 (multimonial) 和深度学习中的 softmax 分类,或是深度学习中的整流器以及统计中的截取回归模型,它们其实是一样的。
类型 回归 连结 连结的逆 激活 实数 线性 恒等式 恒等式
二元 逻辑斯蒂 逻辑斯蒂logμ1–μ S 型σ11+exp(−η) S 型 二元 概率 逆的高斯累计分布函数Φ−1(μ) 高斯分布函数Φ(η) 概率 二元 耶贝尔分布 Compl. log-loglog(−log(μ)) 耶贝尔累计分布函数e−e−x
二元 逻辑斯蒂
双曲正切tanh(η) Tanh 分类的 多项式
多项式逻辑斯蒂ηi∑jηj SOFTMAX 计数 泊松 logμ exp(ν)
计数 泊松 √(μ) ν2
非负的 伽玛 倒数1μ 1ν
稀疏的 截取回归
最大值max(0;ν) 纠正线性单位 顺序 序数
累积的逻辑斯蒂回归
递归广义线性模型
广义线性模型的形式十分简单:它们求出输入和权重β做线性组合,并把结果传入一个简单的非线性函数。在深度学习中,这样的基本组成部件被称为层。很容易看出,我们可以方便地重复使用这样的基本部件,以形成更复杂的分层非线性回归函数。这个基本部件的循环利用就是我们说深度学习模型有很多层的原因以及它名字中深度的由来。
给定 层上的线性组合结果η和反连接函数(或激活函数)f,我们将回归函数h定义为:
hl(x)=fl(ηl)
那么我们可以很容易地通过反复应用这一基本部件定义一个递归的 GLM
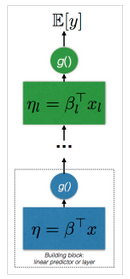
E[y]=μL=hL∘…∘h1∘ho(x)
这正是一个 L 层深度神经网络模型的定义。这个模型中没有什么秘密(在前馈神经网络中也是如此),并且因为我们能很容易地在线性组合的基础上做极大的拓展,相比于只使用线性预测变量的模型它的能力是显而易见的。这表示递归 GLM 和神经网络是核函数回归的一种方式。这里核函数就是不断递归使用线性预测值得到的。
学习和估计
给定这些模型的具体形式后,接下来就是寻找一个训练方法,即对每一层回归参数β的估计。深度学习对这个问题有着很深刻的理解,并展现了这样的模型如何扩展到非常大的超高维数据集上。
一个直接的方法是使用负对数概率作为损失函数从而进行极大似然估计 [3]:
L=–logp(y|μL)
如果使用高斯分布作为似然函数,我们就会得到平方误差损失函数;如果使用伯努利分布,我们得到的是交叉熵损失函数。深度神经网络中的估计或学习正是递归 GLMs 中的极大似然估计。现在,我们可以通过计算参数的梯度并使用梯度下降法来求解回归系数了。深度学习现在常用随机近似(随机梯度下降)等方法训练,通过链式法则计算整个模型的导数(即反向传播),并以强大的分布式集群和 GPU 执行计算。这样的模型能够在至少数百万条记录的数据上训练含有数百万个参数的超大模型 [4]。
从极大似然理论,我们知道这样估计很容易过拟合。不过我们可以引入正则项,使用带惩罚项的回归收缩参数,或者使用贝叶斯回归。正则项的重要性也已在深度学习体现出来,对此进一步的类比思考也可能是有帮助的。
深度前馈神经网络直接对应于统计中的递归广义线性模型和核函数回归 - 认识这点能让深度网络不那么神秘,也不必依赖于与大脑工作方式的类比。。训练过程是(正则化)极大似然估计,而我们现在有丰富的工具来处理大规模的真实数据。统计观点下的深度学习包含了两个领域内的大量相似知识,这可能对进一步提升效率与理解回归问题有帮助。我认为,记住这点对每个人都大有裨益。当然也存在着图模型与深度学习的联系,或者是动力系统与递归神经网络的联系。我希望能在未来也好好思考这些关系。
[1] Christopher M Bishop, Neural networks for pattern recognition, 1995
[2] Peter McCullagh, John A Nelder, Generalized linear models., 1989
[3] Peter J Bickel, Kjell A Doksum, Mathematical Statistics, volume I, 2001
[4] Leon Bottou, Stochastic Gradient Descent Tricks, Neural Networks: Tricks of the Trade, 2012
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:[email protected]),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK