

译 | 缓存穿透问题导致Facebook史上最严重事故之一
source link: https://club.perfma.com/article/2449043
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

译 | 缓存穿透问题导致Facebook史上最严重事故之一
2010年9月23,这个世界上最大的社交平台项目facebook,遭遇了最严重宕机故障之一,以至于facebook网站4个小时后才恢复运行。而且这次事故非常极端,工程师不得不先让facebook下线,才能恢复。虽然10年前的facebook远没有现在这么大,不过仍然有超过10亿用户,人们去twitter上抱怨或者取笑这次故障。
那么,导致是什么原因导致这次facebook宕机呢?
- Today we made a change to the persistent copy of a configuration value that was interpreted as invalid. This meant that every single client saw the invalid value and attempted to fix it. Because the fix involves making a query to a cluster of databases, that cluster was quickly overwhelmed by hundreds of thousands of queries a second.
一个错误的配置变更,导致大量的请求击穿缓存,直达数据库。我们把这种现象称之为cache stampede,wiki地址:https://en.wikipedia.org/wiki/Cache_stampede。
这在技术行业是一个非常普遍的问题,很多公司都出现过类似的事故,无数工程师为了不让自己的项目遭遇这样的问题做了大量的工作。
1、什么是缓存踩踏
cache stampede是指很多线程尝试并行访问缓存,如果缓存中不存在要访问的数据,那么这时候,线程一般会请求数据库获取它们需要的数据(所以cache stampede可以翻译成缓存踩踏。和缓存穿透有点不一样,Cache Stampede的重点是很多的线程穿透缓存)。
缓存踩踏破坏性这么大的主要原因是,它可能会导致故障雪崩,也就是说一个故障接着一个故障:
大量线程并发请求没有从缓存中获取到数据,导致这些请求都会落到数据库上。
数据库由于恐怖的CPU毛刺而宕机,从而导致大量的超时错误。
请求线程接收到超时后,又不断重试请求,从而又导致新一轮的灾难。
反反复复,无穷无尽。
需要说明的是,即使你没有 Facebook 那样的规模,也会遇到这个问题,因为它与规模无关。这个问题一直困扰着初创公司和科技巨头。
2、如何阻止缓存踩踏
这是个很好的问题,在这篇文章中,我们将探索不同的策略来缓解甚至阻止缓存踩踏的出现。毕竟,你也不想等到你自己的服务出现问题后,才想到要学习如何预防。
2.1 增加更多的缓存
一个很简单的方法就是增加更多的缓存,它的原理有点类似操作系统的多级缓存。操作系统使用了一个缓存层次结构(L1、L2、L3),为了更快速的访问。参考操作系统,你也能在你的应用中引入多级缓存。比如本地内存缓存叫做L1缓存(例如Guava Cache,Caffeine),远程缓存叫做L2缓存(例如Redis,memcached):
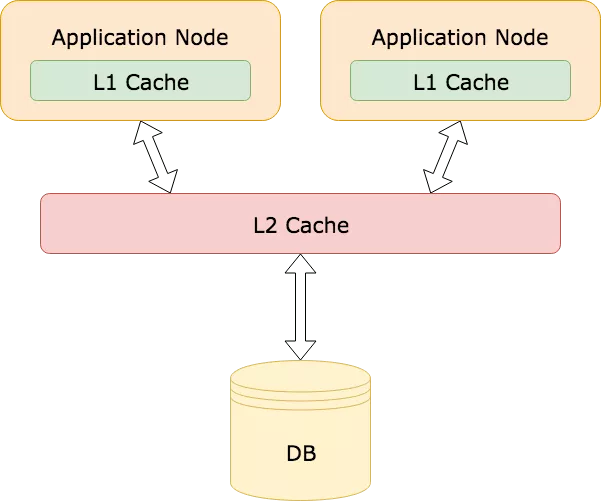
这个策略对那些频繁访问的数据来说是非常有用的。即使L2缓存中的Key失效了,L1缓存中仍然有值,能够挡住大量请求不会打到数据库上。
然后,这种方法需要做一些取舍,在应用服务器本地缓存中缓存数据可能会导致OOM。在使用本地缓存的时候要非常小心,尤其当你会缓存一些大量数据的时候。
另外,这个策略在接下来我要说的这种情况下仍然没有作用。例如,当一个有很多粉丝的大V上传了一个新的照片或者视频到他们的社交账号上,这时候大量粉丝被提醒大V有新的内容发布,这时候粉丝会集中在相同的时间点上登陆社交平台查看新的内容。但是可能大V发送的新内容数据还没有加载到缓存中,这就会导致可怕的缓存踩踏。那么,我们还能做什么呢?
2.2 锁和Promise
缓存踩踏的核心问题是竞态条件(race condition),即很多的线程争夺共享资源。只不过这里争夺的共享资源是缓存。
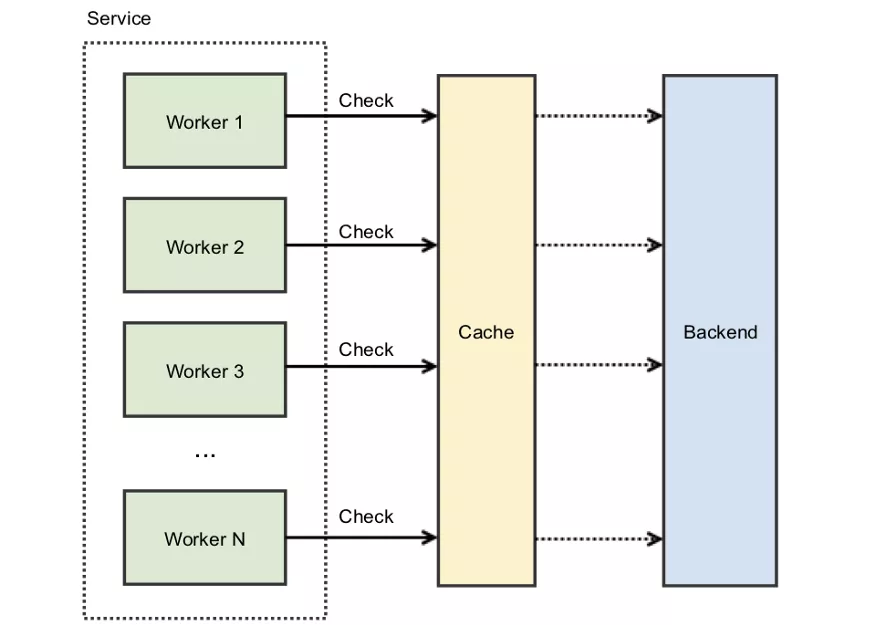
通常在高并发的系统中,一种阻止共享资源竞态的方法是加锁。一般来讲,锁是用在相同机器上的不同线程,不过也可以使用分布式锁来应对不同机器对共享资源的竞争(参考redis分布式锁:http://redis.cn/topics/distlock.html )。
通过给缓存KEY加锁,就会在同一时间只有一个调用者能访问争夺的缓存。如果KEY不存在或者已经过期,调用者就会拿到锁。这时候其他争夺的处理线程必须等待直到这个锁被释放。
用锁来解决这个问题,它也会引入另一个问题:系统如何处理所有正在等待锁释放的那些线程?
你想尝试自旋锁(spinlock),让这些线程持续不断的轮询去获取锁?这就会导致出现非常busy的场景,消耗大量的CPU。或者让线程在检查锁是否可用之前随机等待一段时间?这样的话,你又会碰到惊群效应问题(thundering herd problem)。
引入退避和抖动机制来防止惊群效应?这可能行得通,但还有另外一个问题。持有锁的线程必须重新计算值,并在释放锁之前更新缓存键。这个过程可能需要耗费一点时间,特别是当计算成本很高或存在网络问题时,如果因为计算缓存而耗尽了可用的连接池,仍然可能导致宕机。
- backoff-and-jitter
幸运的是,一些大公司也碰到过这样的问题,他们使用promises来解决这样的问题。
2.3 Promises如何防止自旋
引用Instagram工程师博客(Thundering Herds & Promises)中的内容:
- 在Instagram, 当我们启用一个新的集群,并且因为集群中的缓存是空的,我们就会碰到缓存stampede问题。这时候,我们就会用promises来解决这个问题。它的核心思想是:不缓存实际的值,而是缓存一个promise,这个promise最终会提供我们需要的值。当我们使用缓存时,如果碰到一个不存在的KEY,我们不立即去数据库中查询,而是创建一个promise然后放到缓存中,这个缓存中的promise会去查询数据库,其他的并发请求发现这个promise就不会把请求打到数据库上,它们都会等待第一个线程放进去的promise去数据库中查询结果。
通过缓存promise而不是实际的值,就不会自旋锁了。第一个线程发现缓存中没有数据,就会用原子性的操作创建并缓存一个异步的promise,所有后续的请求都能立即返回这个promise:
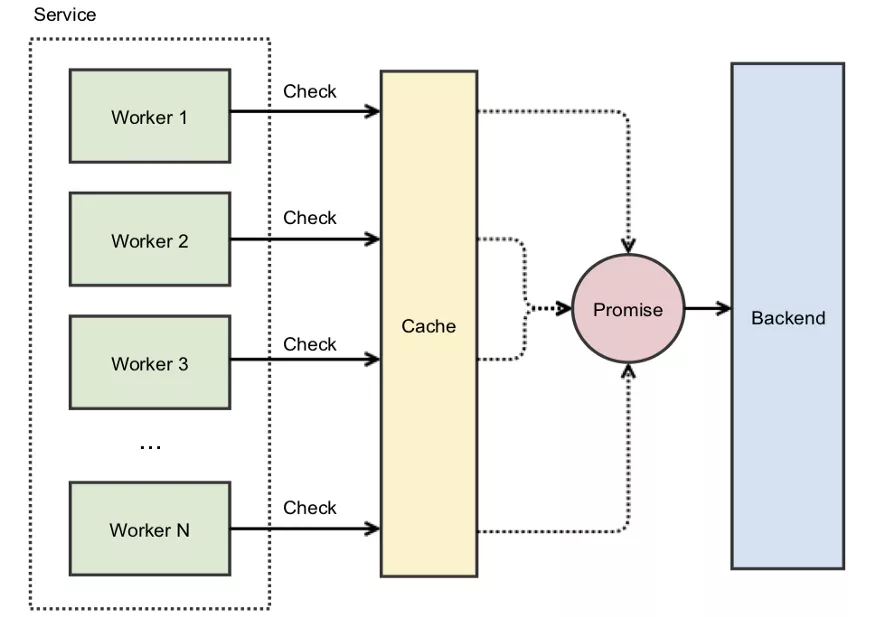
你仍然需要使用锁来防止多个线程访问缓存KEY,假设创建 Promise 是一个近乎即时的操作,那么线程停留在自旋锁中的时间长度就可以忽略不计了。但是,如果重新计算缓存数据需要相当长的时间,那该怎么办?即使线程能够立即获取到缓存的 Promise,它们仍然需要等待异步进程完成后才能将数据返回。虽然这种场景不一定会导致宕机,但仍然会导致尾部延迟和影响整体用户体验。如果保持较低的尾部延迟对于应用程序来说很重要,那么就需要考虑另外一种策略。
2.4 预先重新计算
预先重新计算(也被称为提前过期)原理很简单:在缓存KEY失效发生前,重新计算缓存的值然后延长失效时间,这就能确保缓存总是最新的,缓存缺失的问题也永远不会发生。
最简单的实现方式就是开启一个后台处理线程,或者一个定时任务。例如。假设缓存KEY过期时间时一个小时,它需要花两分钟来计算值。那么,定时任务可以在过期时间到来之前的5分钟运行,更新缓存的值并延长失效时间一个小时。
虽然原理非常简单,但是有一个明显的缺点,除非你很清楚哪个缓存KEY会被使用,否则你需要重新计算缓存中每个KEY的值,这将是一个非常耗时的过程。而且如果考虑到高可用,某个节点上计算任务失败了,还需要转移到另一个可用的节点上继续计算。
基于这个原因,生产环境上很少有这么做的。当然,也有一个例外。
2.5 概率性重新计算
在2015年,一组研究员发布了一份白皮书 Optimal Probabilistic Cache Stampede Prevention,即最优概率性预防缓存踩踏。在这份白皮书中,他们描述了一个算法来预测在缓存失效之前,什么时候需要重新计算缓存的值。这里涉及到很多数学理论,但是可以做一个简单的总结:
currentTime - ( timeToCompute * beta * log(rand()) ) > expiry
这个公式中各变量的含义如下所示:
- currentTime 表示当前时间;
- timeToCompute 表示重新计算缓存值需要的时间;
- beta是一个大于0的非负数,默认为1,可配置;
- rand() 一个返回0~1之间随机数的方法;
- expiry 下一次需要设置的失效时间戳;
- 它的思想是,每次线程从缓存中获取数据时,它都需要运行这个算法,如果返回true,那么这个线程将主动去重新计算缓存值。而且离失效时间越近,这个算法返回true的概率就越大。
3、如何停止正在发生的缓存踩踏
facebook缓存踩踏之所以如此严重的原因之一是,即使当工程师找到了解决方案,他们并不能通过部署来解决。因为踩踏仍在继续。事后诊断报告提到:
更糟糕的是,每次客户端接收到数据库查询错误时,都会把它当作一个无效的值,然后就会删除缓存中相关的KEY,这就意味着即使原来的问题被修复了,但是查询还在继续。一旦数据库无法正确响应某一部分请求,那么就会导致缓存KEY被删除,从而引起更多的请求打到数据库上。
所幸的是,有一种已知的模型能处理这个问题。
这个策略不是很好理解,但是实现非常简单,不需要考虑失败转移,也不需要到重新计算缓存中每一个KEY的值。当然,预先重计算假设有一个值需要重新计算,它本身并不能防止其他线程引起缓存踩踏问题。为此,你需要将其与锁和 Promise 结合起来使用。
熔断器
这个想法不是很新的事情,2007年Michael Nygard发布了 Release It!后就慢慢流行了。熔断器(Circuit breaking)的原理非常简单,我们会在熔断器中封装一个方法,当监测到失败时进行计数,并且一旦失败达到一定阈值时,调用就会收到熔断器直接返回的错误码,而不会调用到受到熔断器保护的地方,例如数据库等。如下图所示,第一次supplier能正常服务,但是第二次、第三次访问都是超时。达到熔断器阈值后,第四次直接返回错误码,而不会将请求直接打给supplier:
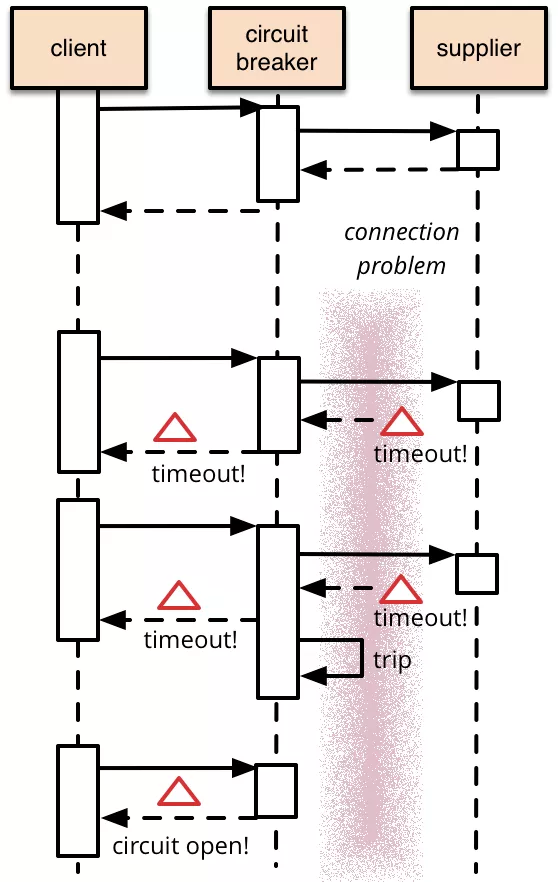
熔断器是响应式的,所以它不能阻止宕机。不过它可以防止连锁故障的发生。而且它提供了一个终止开关,当事态已经彻底失控时可以开启。如果 Facebook 使用了熔断机制,就可以避免让整个网站瘫痪下线。2010年的时候熔断器还不是很流行,不过今天已经有很多熔断的开源组件,例如:Resilience4j, Istio和 Envoy。
4、学到了什么
这篇文章中谈论了很多应对缓存踩踏问题的策略,以及其他的科技公司是如何使用这些策略的。那么facebook呢?他们从这次事故中学到了什么?以及他们采取了什么措施来防止事故再次发生?他们的工程师写了一篇文章:Under the hood: Broadcasting live video to millions,讨论了他们对架构所做的改进。和本文我们提到的一样,比如二级缓存。当然,也提到了一些新的方法,比如 HTTP请求合并。总之,这篇文章非常值得一读
5、写在最后
我相信理解缓存踩踏对系统的破坏性是非常有必要的,当然,并不是说每个团队必须马上把这些策略用到他们的系统中。因为,选择何种策略要应对缓存踩踏并不是一件容易的事情,它依赖你的实际用户场景,架构,以及流量负载情况。但是了解缓存踩踏以及对可能的解决方案对您将来有所帮助,当你以后面对类型问题时,能从容应对。
Recommend
-
88
缓存穿透、缓存并发、热点缓存之最佳招式
-
41
把redis作为缓存使用已经是司空见惯,但是使用redis后也可能会碰到一系列的问题,尤其是数据量很大的时候,经典的几个问题如下:(一)缓存和数据库间数据一致性问题分布式环境下(单机就不用说了)非常容易出现缓存和数据库间的数据一致性问题,针对这一点的话,只...
-
46
缓存穿透 缓存系统,一般流程都是按照key去查询缓存,如果不存在对应的value,就去后端系统(例如: 持久层数据库)查找。 如果key对应的value是一定不存在的,并且对该key并...
-
31
缓存击穿/穿透/雪崩 Intro 使用缓存需要了解几个缓存问题,缓存击穿、缓存穿透以及缓存雪崩,需要了解它们产生的原因以及怎么避免,尤其是当你打算设计自己的缓存框架的时候需要考虑如何处理这些问题。 ...
-
13
当线上接口请求量比较大时,如果恰好遇到缓存失效,会造成大量的请求直接打到数据库,导致数据库压力过大、甚至崩溃。如果缓存的数据实时性要求不那么高,可以试试 do-once-while-concurrent
-
13
阅读时间大约4分钟(1328字) ...
-
8
史上最严重:Facebook 遭遇全球宕机近 7 小时后重新上线,股价下跌5%发布于 今天 04:05 刚刚,Facebook 在经历了持续近 7 个小时的全球宕机后重新上线。这期间,该...
-
4
Facebook 史上最严重宕机:互联网企业是时候重新审视架构了? 2021 年 10 月 08 日
-
6
场景问题及原因 缓存穿透: 原因:客户端请求的数据在缓存和数据库中不存在,这样缓存永远不会生效,请求全部打入数据库,造成数据库连接异常。 解决思路: 缓存空对...
-
9
1. 什么是缓存雪崩 当我们提到缓存系统中的问题,缓存雪崩是一个经常被讨论的话题。缓存雪崩是指在某一时刻发生大量的缓存失效,导致瞬间大量的请求直接打到了数据库,可能会导致数据库瞬间压力过大甚至宕机。尤其在高并发的系统中,...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK