

【Redis场景3】缓存穿透、击穿问题 - xbhog
source link: https://www.cnblogs.com/xbhog/p/17076595.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

场景问题及原因
缓存穿透:
原因:客户端请求的数据在缓存和数据库中不存在,这样缓存永远不会生效,请求全部打入数据库,造成数据库连接异常。
解决思路:
-
缓存空对象
-
- 对于不存在的数据也在Redis建立缓存,值为空,并设置一个较短的TTL时间
- 问题:实现简单,维护方便,但短期的数据不一致问题
缓存雪崩:
原因:在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决思路:给不同的Key的TTL添加随机值(简单),给缓存业务添加降级限流策略(复杂),给业务添加多级缓存(复杂)
缓存击穿(热点Key):
前提条件:热点Key&在某一时段被高并发访问&缓存重建耗时较长
原因:热点key突然过期,因为重建耗时长,在这段时间内大量请求落到数据库,带来巨大冲击
解决思路:
-
- 给缓存重建过程加锁,确保重建过程只有一个线程执行,其它线程等待
- 问题:线程阻塞,导致性能下降且有死锁风险
-
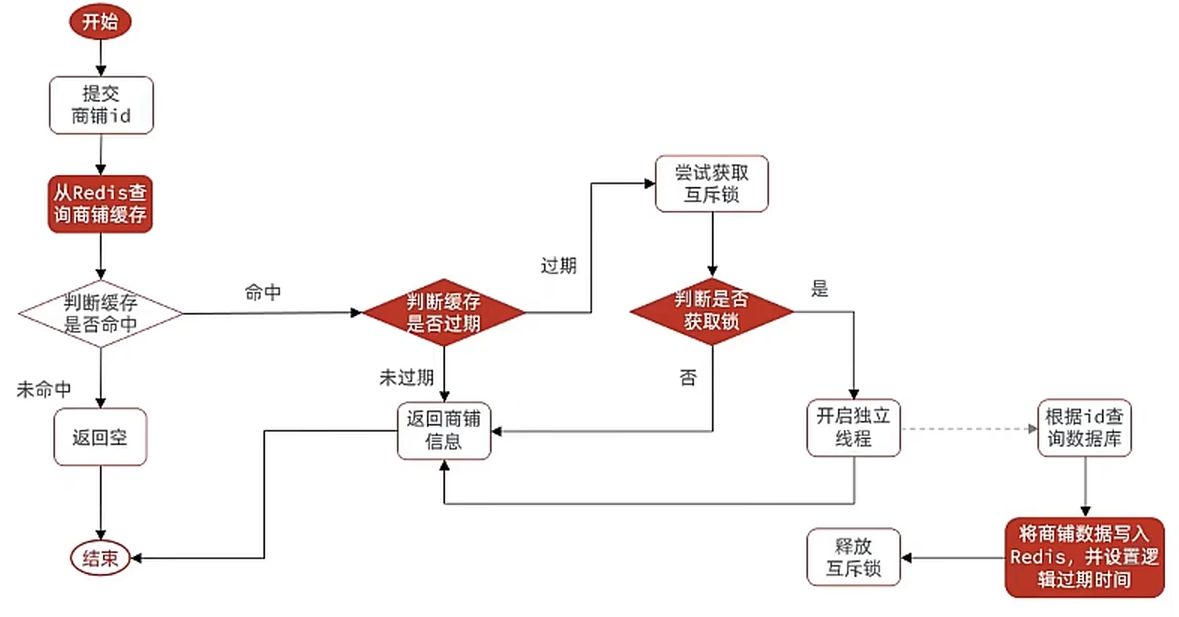
- 热点key缓存永不过期,而是设置一个逻辑过期时间,查询到数据时通过对逻辑过期时间判断,来决定是否需要重建缓存;重建缓存也通过互斥锁保证单线程执行,但是重建缓存利用独立线程异步执行,其它线程无需等待,直接查询到的旧数据即可
- 问题:不保证一致性,有额外内存消耗且实现复杂
场景问题实践解决
完整代码地址:https://github.com/xbhog/hm-dianping
分支:20221221-xbhog-cacheBrenkdown
分支:20230110-xbhog-Cache_Penetration_Avalance
缓存穿透:
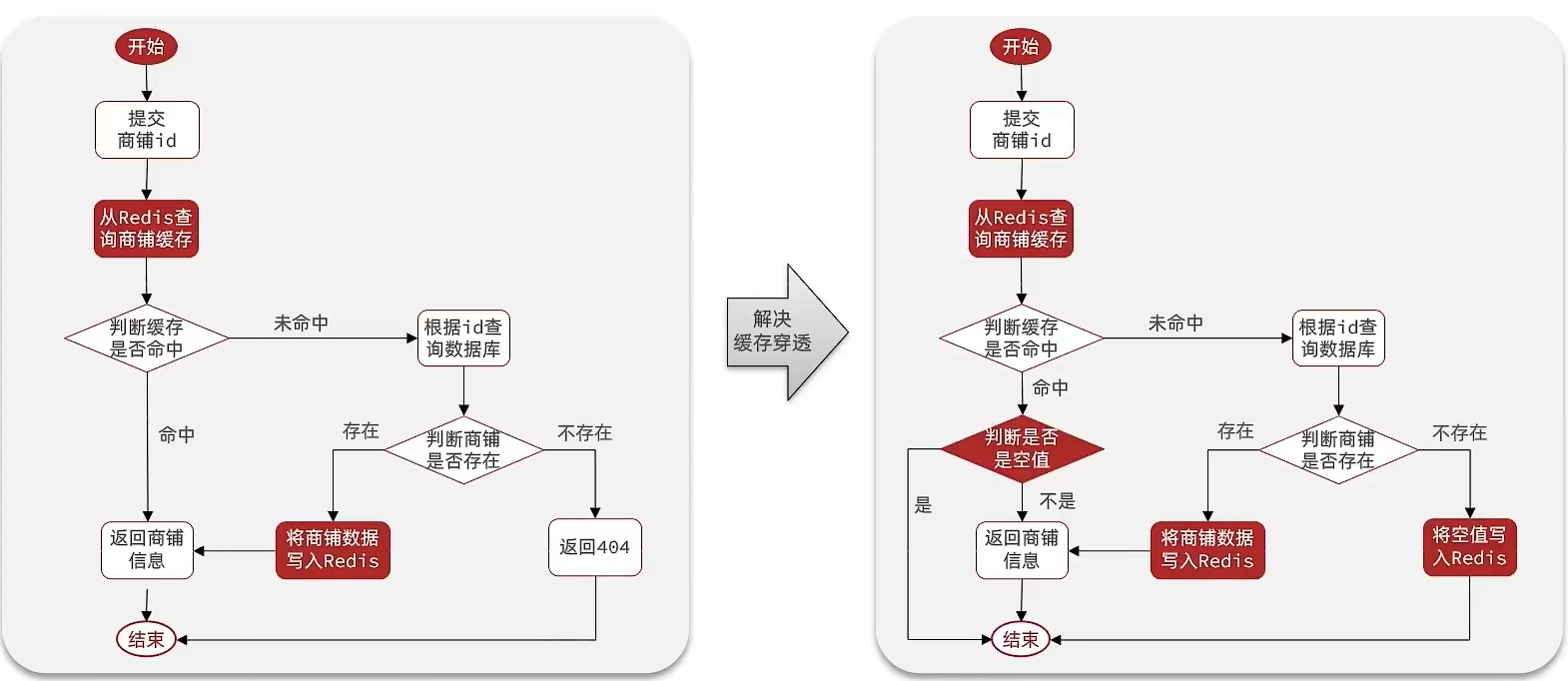
代码实现:
public Shop queryWithPassThrough(Long id){
//从redis查询商铺信息
String shopInfo = stringRedisTemplate.opsForValue().get(SHOP_CACHE_KEY + id);
//命中缓存,返回店铺信息
if(StrUtil.isNotBlank(shopInfo)){
return JSONUtil.toBean(shopInfo, Shop.class);
}
//redis既没有key的缓存,但查出来信息不为null,则为空字符串
if(shopInfo != null){
return null;
}
//未命中缓存
Shop shop = getById(id);
if(Objects.isNull(shop)){
//将null添加至缓存,过期时间减少
stringRedisTemplate.opsForValue().set(SHOP_CACHE_KEY+id,"",5L, TimeUnit.MINUTES);
return null;
}
//对象转字符串
stringRedisTemplate.opsForValue().set(SHOP_CACHE_KEY+id,JSONUtil.toJsonStr(shop),30L, TimeUnit.MINUTES);
return shop;
}
上述流程图和代码非常清晰,由于缓存雪崩简单实现(复杂实践不会)增加随机TTL值,缓存穿透和缓存雪崩不过多解释。
缓存击穿:
缓存击穿逻辑分析:
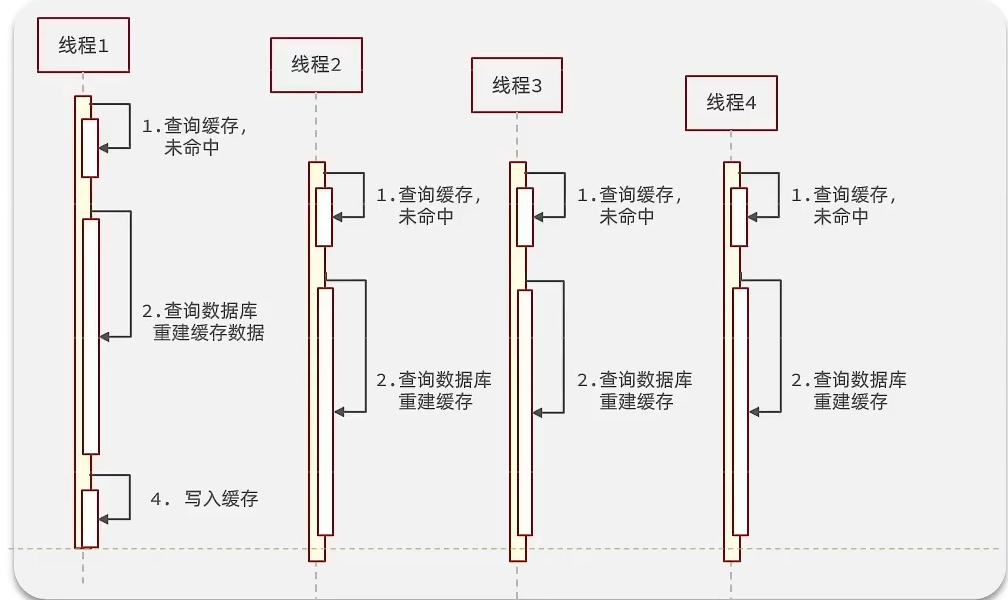
首先线程1在查询缓存时未命中,然后进行查询数据库并重建缓存。注意上述缓存击穿发生的条件,被高并发访问&缓存重建耗时较长;
由于缓存重建耗时较长,在这时间穿插线程2,3,4进入;那么这些线程都不能从缓存中查询到数据,同一时间去访问数据库,同时的去执行数据库操作代码,对数据库访问压力过大。
解决方式:加锁;****可以采用**tryLock方法 + double check**来解决这样的问题
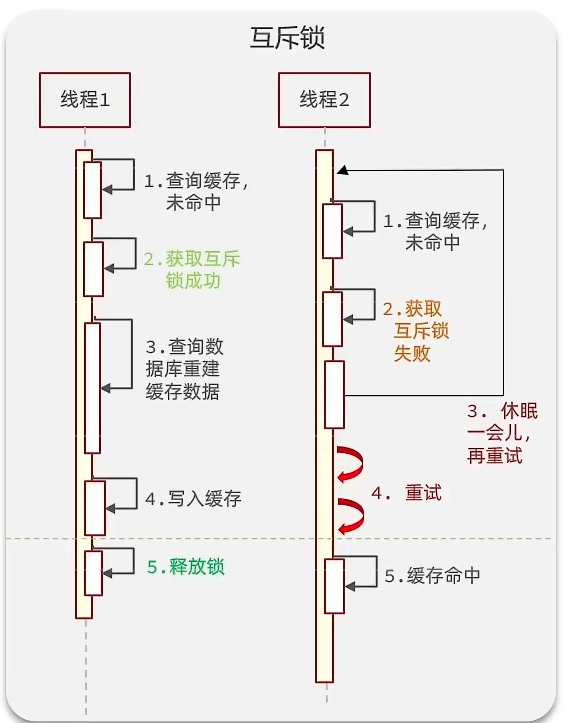
在线程2执行的时候,由于线程1加锁在重建缓存,所以线程2被阻塞,休眠等待线程1执行完成后查询缓存。由此造成在重建缓存的时候阻塞进程,效率下降且有死锁的风险。
private Shop queryWithMutex(Long id) {
//从redis查询商铺信息
String shopInfo = stringRedisTemplate.opsForValue().get(SHOP_CACHE_KEY + id);
//命中缓存,返回店铺信息
if(StrUtil.isNotBlank(shopInfo)){
return JSONUtil.toBean(shopInfo, Shop.class);
}
//redis既没有key的缓存,但查出来信息不为null,则为空字符串
if(shopInfo != null){
return null;
}
//实现缓存重建
String lockKey = "lock:shop:"+id;
Shop shop = null;
try {
Boolean aBoolean = tryLock(lockKey);
if(!aBoolean){
//加锁失败,休眠
Thread.sleep(50);
//递归等待
return queryWithMutex(id);
}
//获取锁成功应该再次检测redis缓存是否还存在,做doubleCheck,如果存在则无需重建缓存。
synchronized (this){
//从redis查询商铺信息
String shopInfoTwo = stringRedisTemplate.opsForValue().get(SHOP_CACHE_KEY + id);
//命中缓存,返回店铺信息
if(StrUtil.isNotBlank(shopInfoTwo)){
return JSONUtil.toBean(shopInfoTwo, Shop.class);
}
//redis既没有key的缓存,但查出来信息不为null,则为“”
if(shopInfoTwo != null){
return null;
}
//未命中缓存
shop = getById(id);
// 5.不存在,返回错误
if(Objects.isNull(shop)){
//将null添加至缓存,过期时间减少
stringRedisTemplate.opsForValue().set(SHOP_CACHE_KEY+id,"",5L, TimeUnit.MINUTES);
return null;
}
//模拟重建的延时
Thread.sleep(200);
//对象转字符串
stringRedisTemplate.opsForValue().set(SHOP_CACHE_KEY+id,JSONUtil.toJsonStr(shop),30L, TimeUnit.MINUTES);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
unLock(lockKey);
}
return shop;
}
在获取锁失败时,证明已有线程在重建缓存,使当前线程休眠并重试(递归实现)。
代码中需要注意的是synchronized关键字的使用,在获取到锁的时候,在判断下缓存是否存在(失效)double-check,该关键字锁的是当前对象。在其关键字{}中是同步处理。
推荐博客:https://blog.csdn.net/u013142781/article/details/51697672
然后进行测试代码,进行压力测试(jmeter),首先去除缓存中的值,模拟缓存失效。
设置1000个线程,多线程执行间隔5s。
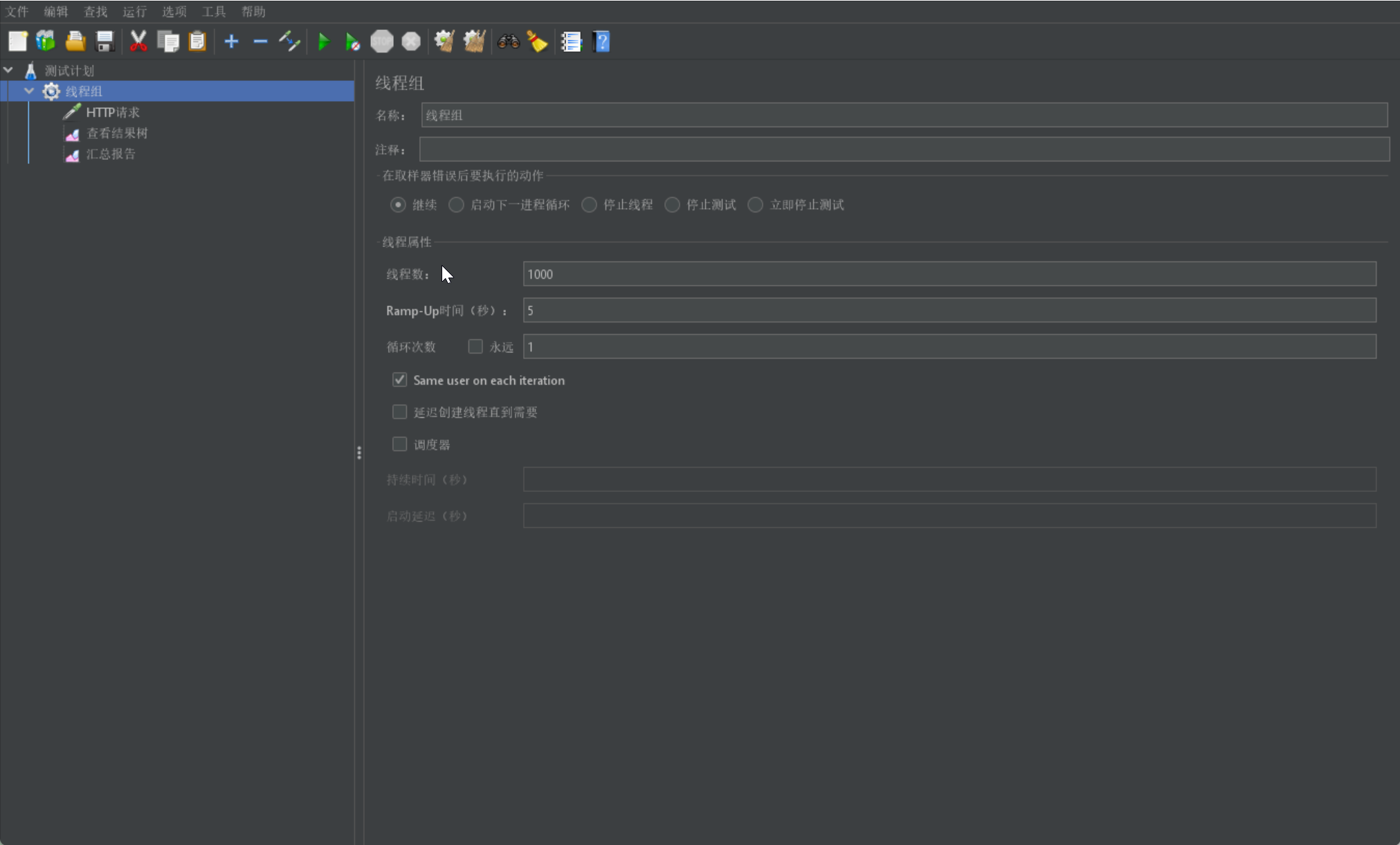
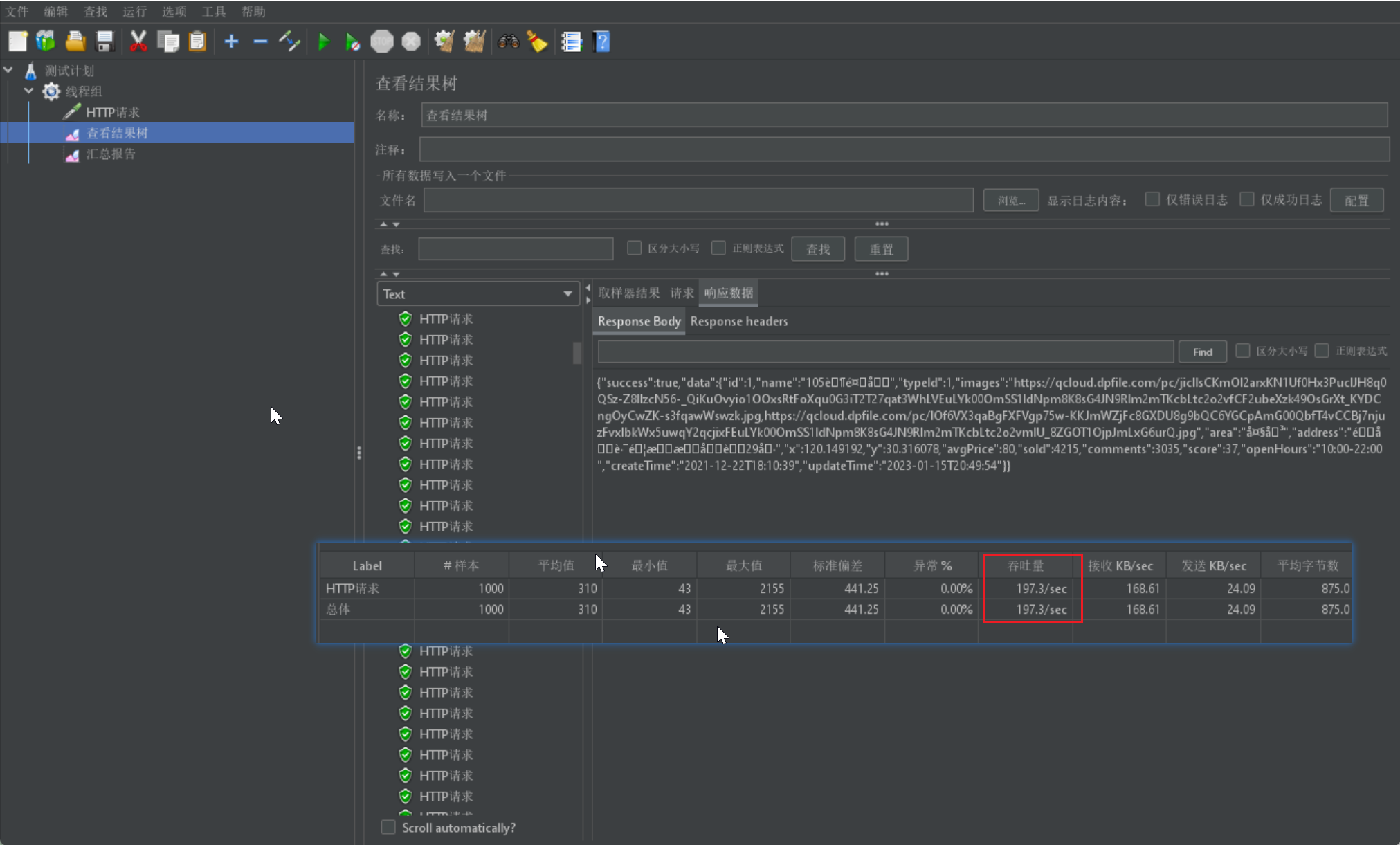
所有的请求都是成功的,其qps大约在200,其吞吐量还是比较可观的。然后看下缓存是否成功(只查询一次数据库);
逻辑过期:
思路分析:
当用户开始查询redis时,判断是否命中,如果没有命中则直接返回空数据,不查询数据库,而一旦命中后,将value取出,判断value中的过期时间是否满足,如果没有过期,则直接返回redis中的数据,如果过期,则在开启独立线程后直接返回之前的数据,独立线程去重构数据,重构完成后释放互斥锁。
封装数据:这里我们采用新建实体类来实现
/**
* @author xbhog
* @describe:
* @date 2023/1/15
*/
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}
使得过期时间和数据有关联关系,这里的数据类型是Object,方便后续不同类型的封装。
public Shop queryWithLogicalExpire( Long id ) {
String key = CACHE_SHOP_KEY + id;
// 1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isBlank(json)) {
// 3.存在,直接返回
return null;
}
// 4.命中,需要先把json反序列化为对象
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
// 5.判断是否过期
if(expireTime.isAfter(LocalDateTime.now())) {
// 5.1.未过期,直接返回店铺信息
return shop;
}
// 5.2.已过期,需要缓存重建
// 6.缓存重建
// 6.1.获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(lockKey);
// 6.2.判断是否获取锁成功
if (isLock){
exectorPool().execute(() -> {
try {
//重建缓存
this.saveShop2Redis(id, 20L);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
unLock(lockKey);
}
});
}
// 6.4.返回过期的商铺信息
return shop;
}
当前的执行流程跟互斥锁基本相同,需要注意的是,在获取锁成功后,我们将缓存重建放到线程池中执行,来异步实现。
线程池代码:
/**
* 线程池的创建
* @return
*/
private static ThreadPoolExecutor exectorPool() {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5,
//根据自己的处理器数量+1
Runtime.getRuntime().availableProcessors()+1,
2L,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
return executor;
}
缓存重建代码:
/**
* 重建缓存
* @param id 重建ID
* @param l 过期时间
*/
public void saveShop2Redis(Long id, long l) {
//查询店铺信息
Shop shop = getById(id);
//封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(l));
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(redisData));
}
测试条件:100线程,1s线程间隔时间,缓存失效时间10s。
测试环境:缓存中存在对应的数据,并且在缓存快失效之前修改数据库中的数据,造成缓存与数据库不一致,通过执行压测,来查看相关线程返回的数据情况。
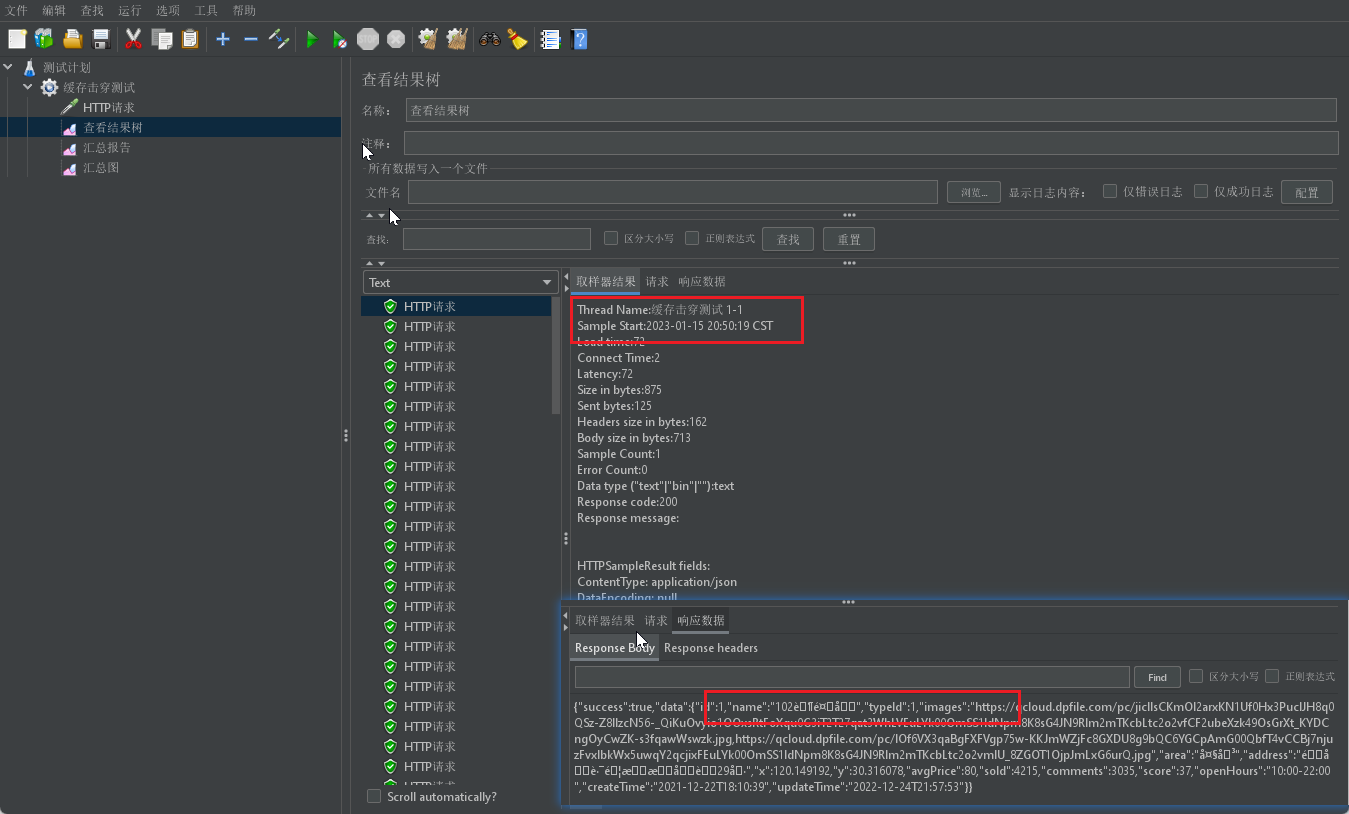
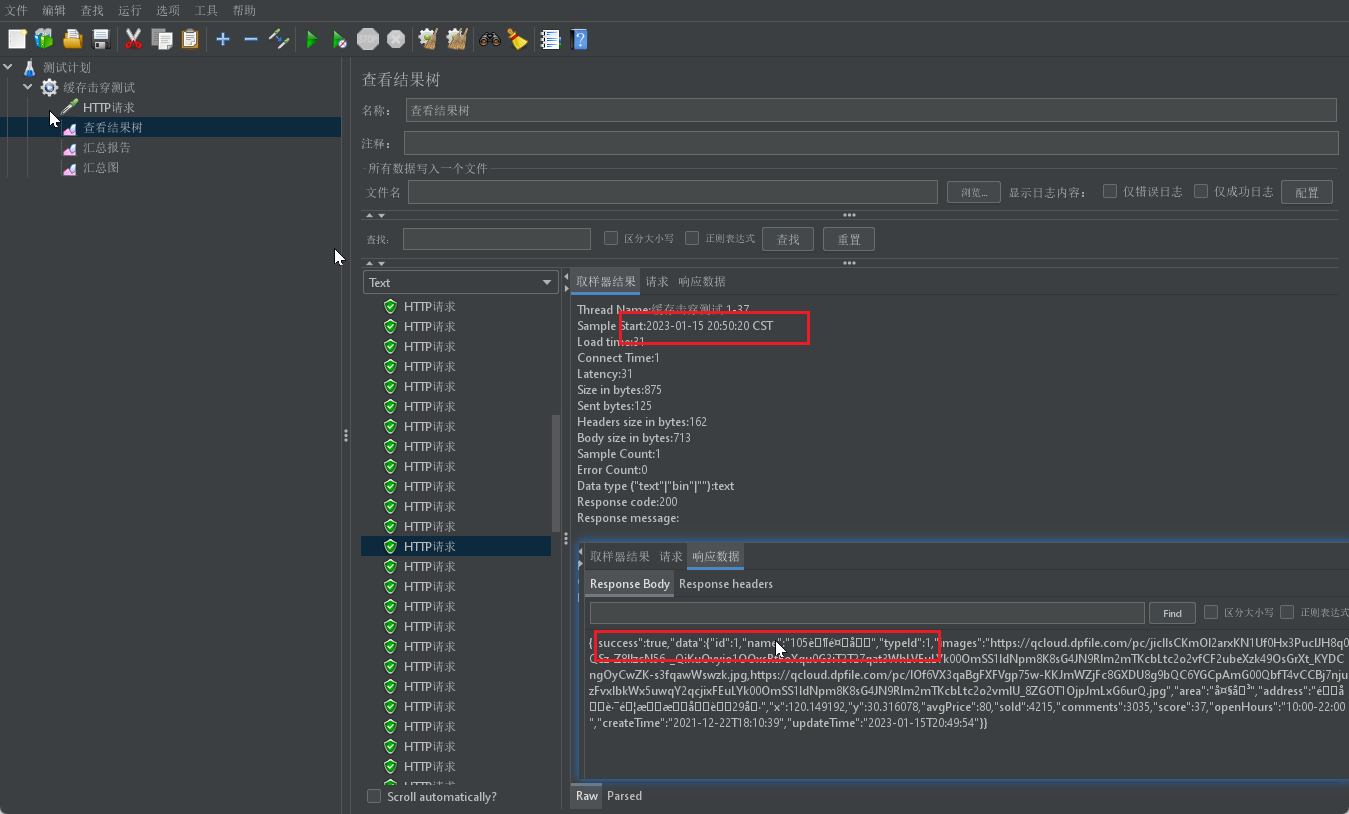
从上述两张图中可以看到,在前几个线程执行过程中店铺name为102,当执行时间从19-20的时候店铺name发生变化为105,满足逻辑过期异步执行缓存重建的需求.
本文作者:xbhog
本文链接:https://www.cnblogs.com/xbhog/p/17076595.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。
这是一条自定义内容
这是一条自定义内容
Recommend
-
31
缓存击穿/穿透/雪崩 Intro 使用缓存需要了解几个缓存问题,缓存击穿、缓存穿透以及缓存雪崩,需要了解它们产生的原因以及怎么避免,尤其是当你打算设计自己的缓存框架的时候需要考虑如何处理这些问题。 ...
-
31
文中 cache 指缓存,比如 redis,db 指数据库,比如mysql。 一,缓存一般有三种模式 这里主要指的是 应用代码 对 cache 和 db 中数据的维护方式。 1.1 Cache Aside 应用代码同时更新 cache 和 db...
-
36
为了应对越来越大的流量,缓存便成为系统服务必不可少的一部分,但使用缓存就会出现缓存击穿和缓存穿透的威胁。 背景介绍 互联网应用...
-
19
1.前言 当我们设计一个Redis缓存服务时,缓存穿透、缓存击穿、缓存雪崩这三大问题我们不得不考虑。同时参见面试时面试官也会常问这三大问题。本章我们来分析一下这三大问题。 2.缓存穿透 2.1什么叫缓存穿...
-
20
点击上方 “ 匠心零度 ” ,选择“
-
8
缓存穿透,击穿,雪崩以及解决方案,干货满满发布于 5 月 14 日缓存的设计包含很多技巧,设计不当将会导致严重的后果。redis作为一种非关系型数据库,也总是免不了...
-
3
细节回顾: 关于cookie和session不熟悉的朋友; 建议阅读该博客:https://www.cnblogs.com/ityouknow/p/1...
-
9
单机环境下的秒杀问题 全局唯一ID# 为什么要使用全局唯一ID:
-
10
集群环境下的秒杀问题 前序#
-
9
1. 什么是缓存雪崩 当我们提到缓存系统中的问题,缓存雪崩是一个经常被讨论的话题。缓存雪崩是指在某一时刻发生大量的缓存失效,导致瞬间大量的请求直接打到了数据库,可能会导致数据库瞬间压力过大甚至宕机。尤其在高并发的系统中,...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK