

Computational storage: Pure Storage - Segment, sandbox, stream & shape for s...
source link: https://www.computerweekly.com/blog/CW-Developer-Network/Computational-storage-Pure-Storage-Segment-sandbox-stream-shape-for-storage-supremacy
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Software runs on data and data is often regarded as the new oil. So it makes sense to put data as close to where it is being processed as possible, in order to reduce latency for performance-hungry processing tasks.
Content Continues Below
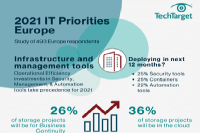

IT Priority Topics 2021 Infographic
This year, a survey was conducted quizzing nearly 500 European IT sector professionals to gather what topics they identified as being imperative for 2021. In this infographic see whether remote working is here to stay, if there will be shifts in information management trends and what infrastructure tools will be deployed by most in 2021. Download this PDF infographic to find out what the results showed.
- Corporate Email Address:
- I agree to TechTarget’s Terms of Use, Privacy Policy, and the transfer of my information to the United States for processing to provide me with relevant information as described in our Privacy Policy.
- I agree to my information being processed by TechTarget and its Partners to contact me via phone, email, or other means regarding information relevant to my professional interests. I may unsubscribe at any time.
Some architectures call for big chunks of memory-like storage located near the compute function, while, conversely, in some cases, it makes more sense to move the compute nearer to the bulk storage.
In this series of articles we explore the architectural decisions driving modern data processing… and, specifically, we look at computational storage
The Storage Network Industry Association (SNIA) defines computational storage as follows:
“Computational storage is defined as architectures that provide Computational Storage Functions (CSF) coupled to storage, offloading host processing or reducing data movement. These architectures enable improvements in application performance and/or infrastructure efficiency through the integration of compute resources (outside of the traditional compute & memory architecture) either directly with storage or between the host and the storage. The goal of these architectures is to enable parallel computation and/or to alleviate constraints on existing compute, memory, storage and I/O.”
This post features a Q&A with Alex McMullan, international CTO at Pure Storage — a company that says it offers a ‘modern data experience’ for organisations to run their operations as a true, automated, storage-as-a-service model seamlessly across multiple clouds. As noted here on TechTarget, Pure Storage differentiates itself from other storage hardware vendors such as Dell EMC, IBM and Hewlett Packard Enterprise by focusing on flash and performance.
CWDN: How much refactoring does it take to bring about a successful computational storage deployment and, crucially, how much tougher is that operation when the DevOps team in question is faced with a particularly archaic older legacy system?
McMullan: The biggest challenge is not necessarily the refactoring itself, it’s having a fundamental understanding of the capabilities of a computational storage portfolio and how it can be adjusted for efficiency and better performance, based on observability. This allows developers to segment the application based on a computational storage drive’s (CSD) capabilities and refine the code over time to improve it. Legacy apps tend towards 2-tier or 3-tier architecture with little or no concept of distributed datasets or parallel processing, so in these apps, the business case rarely makes commercial sense.
It’s highly unlikely that a CSD environment will be homogenous. Therefore infrastructure managers need to be able to fine-tune each CSD and tweak to make systems run better: for example data encryption, or how much time is spent asking a CSD to complete a task vs the time spent actually executing the task. The way to do this is to build a sandbox to develop and test to maximise the deployment’s success.
Data engineering is becoming a big part of creating efficiencies in distributed apps. Additionally curating and cleansing the data set has become important for a successful deployment, as it has in machine learning based applications.
CWDN: Given our online-always existence, could data streaming be the next killer app (or app function) to come?
McMullan: Over the last decade, we’ve seen the capability of networks develop more quickly than storage drives, allowing TB and PB scale datasets to be shipped to a compute farm in minutes rather than hours. This means that customers no longer need to have multiple copies of data tied up in regional data warehouses, different applications or different formats.
Instead, it’s stored in one place and streamed at a higher bandwidth delivering better consistency – both in data quality and as a single source of truth. For instance, adjustments or corrections can be made in real-time, with users guaranteed to derive the same value because they’re pulling information from one data set: one version of the truth. Data streaming democratises access to value, while providing scalability that customers often look for.
CWDN: Given the duality of computational storage e.g (FCSS vs PCSS), do organisations approaching their first use of computational storage know the difference and know how and when they should be looking at either option?
McMullan: In the early stages of deployment, it’s likely that most organisations will opt for fixed computational storage services (FCSS) because it’s easier to use and suits basic storage requirements like data reduction, encryption or image processing. They’re useful as users get up to speed, refine their applications and enhance how they are stored and protected.
As an organisation grows and its storage demands change, they might find the need to shift towards a programmable computational storage service with additional app signing and security infrastructure required. This will enable them to tailor to specific requirements and workloads and also provide better security capabilities to protect the data stored.
CWDN: How should software engineers identify, target and architect specific elements of the total processing workload to reside closer to computational storage functions?
McMullan: Many software engineers already have experience doing this with containerised workloads. Following Pure’s acquisition of Portworx, for instance, we’ve observed that many engineers are building specific classes of compute or storage in the Kubernetes eco-system that lets them architect around specific features like data reduction, image processing or encryption in the cluster nodes. Modern app developers already have these capabilities because they are doing the work on containers.
In fact, it’s my view that CSDs and containers have emerged as competitors for the mindshare of distributed applications and application grids. Kubernetes has a head start because it’s the incumbent for the modern distributed application management paradigm.
This means that for developers, CSDs are great for making an application much more efficient in targeted places in the calling stack. A containerised application allows the SRE function to become more capable and agile, as it allows developers to tweak the entire stack, not just a targeted/specific offload on the computation side of the storage.
Image source: Pure Storage
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK