

一个基于skiplist的有序集合
source link: https://zhuanlan.zhihu.com/p/371716161
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一个基于skiplist的有序集合
Redis 有一个叫 ZSET 的容器,可以有序的存储数据项,每个数据项通过一个分数来决定先后顺序。这样的特性非常适合于排行类的应用,一些游戏的排行榜就是用 redis 来实现的。ZSET 内部用了一种叫 skiplist 的数据结构,它可以在O(logN)内实现增删查改,在对外的表现上有点像平衡树,但内部的实现却比平衡树简单得多。
我的 colib 库也使用 skiplist 来实现有序集合(oset),并提供了简单直观的Lua接口;
如果你想看oset的实现细节,可以clone上面的库。这篇文章我想描述一下skiplist是什么样的数据结构,以及用它如何一步步的实现oset。
skiplist
skiplist本质上是一个链表,不同的地方在于每个结点可能有多个next指针,next指针自底向上构成了一个层级,最底层的next总是指向下一个结点,再往上一层可能会跳过一些结点指向下下...个结点,越往上的next指向的结点越远。
用图形来看skiplist像这样的:
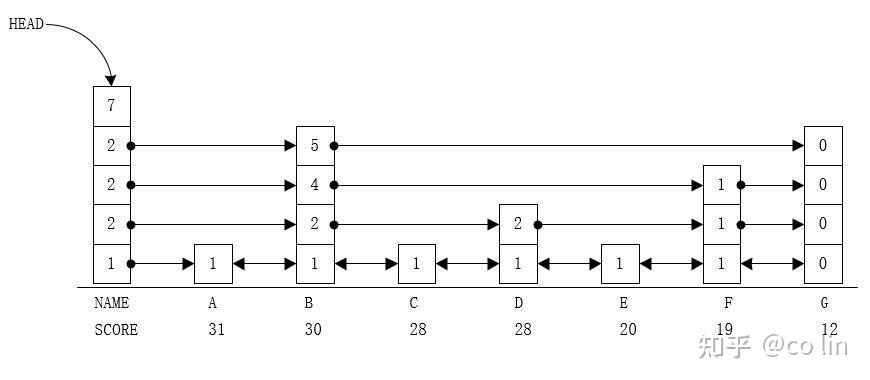
- 一条柱子代表一个结点,其中第一个结点是头结点,也叫dummy node;后面的结点才是外部插进来的。
- 结点的每个层级都有一个数字(即方框里的数字),这代表当前结点到下一个结点的跨度(span),越上层的跨度越大;显然跨度是用于辅助计算排名的。
- 下面的NAME这一行是结点的名字,这是为方便理解增加的,实际的代码并没有这个;或者可以认为这是结点的地址。
- SCORE这一行是每个结点的分数,分数决定结点的位置;在我的实现中分数越大结点越靠前,这比反过来要更直观一些,比如排行榜当然是分数越大排名越前。图示中可看到C和D都是28分,分数相同的情况下,是什么决定位置的前后呢?这个等一下再说。
- 第一层除了有next指针,还有prev指针,这样在找到一个结点后,不单可以向后遍历,还可以向前遍历。
每个结点的层级由一个随机函数决定,在创建结点的时候调用这个函数得到结点的层级:
int randomlevel() {
int level = 1;
while (level < MAX_LEVEL && (random() < LEVEL_P))
level += 1;
return level;
}LEVEL_P 就是生成每个层级的概率,
我们先来定义结点的内容,一个结点有两个成员:一个是score,另一个value;score决定了结点在链表中的位置,而value则代表这个结点,它在集合中必须唯一;结点可形式化地表示为:{value, score}
现在我们提供一个Lua接口用于插入结点:
oset:add(value, score)首先我们要判断这个value是否已经存在于集合中,这需要另一个数据结构的帮助:字典(dict),它维护着从value到node的映射,同时也维护着从node到value的映射;因此我们只要知道value就可以查找到node,返过来只要知道node就可以查找到value。
lua的table就可以用来作dict,所以我们不需要关心dict,只要知道它存在于oset中就可以了。
现在我们用dict查一下value是否存在,如果不存在就:
- 创建一个node,node的层级由前面的randomlevel函数决定。
- 将node加到skiplist中。
- 将node和value加到dict中,即:
dict[value] = node, dict[node] = value
我们重点来看看第2步怎么做,先想一想,普通的有序链表怎么插入结点?说起来简单的要命:从head遍历比较每个结点的score,一直找到合适的位置,然后插进去。
skiplist 的插入其实也类似,只不过它有多个next指针,所以我们要一层层遍历:
- 先从最高层的next遍历,找到合适的前驱结点,记住这个结点
- 然后向下一层遍历next,找到合适的前驱结点,记住这个结点
- 重复这个过程一直到第一层。
结合上图看,假设我们要找插入的结点是F1,它的分数是15,它的层级是5层,那么它应该插入到F和G的结点之间,查找的过程如下:
图中黄色块即是待插入结点的每一层的前驱,这个查找过程很直观地能感觉到比一个个遍历快得多,因为上面层级的跨度很大,很容易就跨过一些中间结点,将结点F1插入后就变成下面这样:
分数是可以相同的,相同分数的结点应该怎么确定前后顺序呢?最直观的感觉是谁先插进来谁就在前面。为了实现这个特性,我给每个结点加了一个序号(seq),在结点创建时分配;这个序号一直增长,所以越后进来的结点序号越大,也就是相同分数时,序号越大的结点排得越后。
虽然序号是size_t的大小,正常情况下是很难被分配完的,不过如果一直删除增加的话,还是会有分配完的一天,如果seq又回滚到0,后面再分配的seq就有可能和现存的结点重复。
为了解决这个问题,需要在seq回滚到0时对现存结点执行一次重分配,第1个结点分配为0,第2个分配为1,一直重复把所有结点重分配完,其作用和哈希表的rehash类似,这样就能确保seq永远唯一。
删除结点的接口是:
oset:remove(value)- 通过dict[value]找到node。
- 自上向下,从前往后的遍历链表,得到node的每个层级的前驱结点。
- 将node从链表删除。
- 调整这些前驱结点的跨度(span)。
- 删除dict的相关映射:
dict[value] = nil, dict[node] = nil。
第2步的查找和前面基本是一样的;而删除结点也是正常的链表操作,只不过需要删除每个层级。调整跨度其实也很简单,就是把要删除的结点的跨度加给前驱结点。
结点的分数更新时,需要调整它在链表中的位置,使链表保持有序。最简单的做法是先把结点从链表删除,然后更新结点的分数,最后再重新插入链表。
但是有一个情况是可以优化的,比如上面的F结点,假如它的分数从19改成了17,这时并不需要调整位置;可以先判断一下第1层的前驱和后继结点,如果新分数在中间,只更新分数即可;否则就执行删除再插入的操作。
上面是有序集合的基本操作,至于查找遍历这些非常地简单,先定位到目标结点,然后进行链表的遍历,这里直接略掉了。
在实现有序集合时,我写了一个打印函数,可以把集合的样子打印出来,这个函数帮助我发现了很多问题,比如下面代码:
local set = oset.new()
for i = 1, 10 do
set:add("id"..i, math.random(1, 50))
end
set:dump()调用set:dump()之后,打印出来的内容是这样的:
length: 10, level: 3
=====================================================================================
[ 8]---------------------------------------------------------->[ 2]---------->
[ 1]-->[ 3]------------------>[ 2]---------->[ 2]---------->[ 1]-->[ 1]-->[ 0]
[ 1]-->[ 1]-->[ 1]-->[ 1]-->[ 1]-->[ 1]-->[ 1]-->[ 1]-->[ 1]-->[ 1]-->[ 0]
=====================================================================================
rank 1 2 3 4 5 6 7 8 9 10
score 49 48 37 33 23 21 21 14 13 11
value id7 id1 id5 id6 id9 id8 id10 id3 id2 id4看起来还不错的样子。
真想了解ordered set的实现,还是阅读代码更好,代码在lset.c中,如果还能在 Github 上点个小星星,那真是万分感激。
中间发现有什么问题,或是有可以探讨的点子,欢迎留言。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK