
6

日语OCR的图像预处理
source link: https://blog.xulihang.me/Japanese-ocr-image-preprocessing/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
日语OCR的图像预处理
首页 分类 标签 链接 留言 关于 订阅 2020-09-29
|
分类 技术随笔
ImageTrans集成了百度、有道和微软等厂商的OCR服务,英文和中文的识别效果都还不错,但日语的识别准确率一直不是很高。
OCR一般需要先对文字进行拆分。像中文日文和韩文中存在的汉字都是可以较为容易地切分的,因为汉字都是比较标准的方块,用水平投影和垂直投影就可以得到文字行和单个文字。其实做OCR并不是特别复杂。
日语文字识别的难点在于文字有时候是竖直排版的,而且在文字边上还会有用于注音的振假名(Furigana),对结果存在干扰。
我在测试百度OCR的日语识别效果时,发现它能较精确地识别日语,但不能根据竖直排版调整文字顺序,它提供的API的结果里也没有给出单个汉字的位置信息。
于是我决定预先将文字竖直排版的日语图像转换为水平横向排版图像,并去除振假名等干扰信息,之后再使用现有的OCR软件进行识别。
这一方法存在一些难点:
- 竖直排列的标点符号需要进行旋转
- 正确区分振假名和汉字列
- 要避免上下结构的汉字被切分的问题
- 文字的排列需要合乎规则,比如遵循中心线、固定的行高、拗音的假名等等
有道OCR在这方面做得较好,能识别竖排日文,而且对标点符号的还原也很好。
下面是我实现的效果。


转换后的图像:


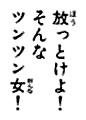
转换后的图像:
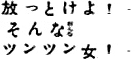
其实我已经把文字都拆分了,完全可以自己做OCR,等有空了再研究下吧。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK