

Streaming Models both Old and New
source link: https://rjlipton.wpcomstaging.com/2009/08/24/streaming-models-both-old-and-new/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Streaming Models both Old and New
Streaming models were started decades ago and continue to be even more exciting

Ian Munro is one of the world’s experts on data structures. If you need to know anything about data structures, either lower bounds or upper bounds, he is one of the few people I would call for advice. If he does not know, or he does not know who knows, or he cannot suggest an approach, you are in deep trouble.
Today I will present some work that Atish Das Sarma and Danupon Nanongkai have recently done on a variation of the streaming model, which was just presented at TAMC 2009. Ian also wrote one of the first papers on streaming, before there was streaming. More on this later.
Atish and Danupon are two graduate students who are working with me, but they are both quite independent and have already written papers with various colleagues from various places on various topics. How is that for a vague statement. In any event, I want to come clean, since I worked with them on their results.
Ian Munro is a long-time friend, and I have many stories about him, which could fill up an almost infinite number of posts.
Ian’s great sense of humor always makes it a pleasure to work with him. Whenever we have worked on a problem and gotten stuck, Ian has a trick that he uses to get us back on track. He says,
“let’s make a list of what we need to do.”
He then proceeds to take a piece of paper and writes on the paper:
-
.
-
-
- Make a list.
where 

-
-
-
- Make a list.
He then would say,
“well we can take a break, since we have done 25 per cent of the work.”
And off we go to get a drink, and hopefully also get an inspiration.
One of my other favorite Ian stories is about the time he got tenure. At STOC that year, he told a group of us that he had just gotten tenure. We all congratulated him—it was wonderful news. He then proceeded to point out that at Waterloo—where he was and still is—tenure is not official until the next trustee meeting. The trustee’s signing off on all the year’s tenure decisions was, of course, pro forma. But, it would not happen for about a month.
Ian then raised an interesting “open problem:” what could he do, in the next month, to get his tenure decision reversed? What behavior would undo tenure? Only Ian. It was a fun discussion, as we argued over which behaviors would lead to tenure being revoked, and which behaviors would not. The group sometimes agreed that this behavior would lead to a revoke, and that behavior would not. Sometimes we were divided. Thankfully, Ian decided not to test the various hypotheses and he got his tenure.
Let’s now turn to talking about the streaming model, and the work of Atish and Danupon.
The Streaming Model
The streaming model is both new and old. In computer science we sometimes create entire new areas of study. However, more often than not, a hot new area is an old one in disguise—or an old one with a slight twist. I think this is the case with the current area that is called streaming. As you probably know, in the basic streaming model, data is send one bit after another to the algorithm, which must compute the answer after the last bit has been sent.
So far the model does not restrict the algorithm at all—just have the algorithm store the input, and then run any method to solve the given problem. This strategy would make the streaming model trivial, so the rules of streaming are that the algorithm is always space limited. That is, if the stream is 

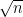

The space restriction makes the model interesting, but does it make the model new? I think no and yes. The basic setup is nothing more than asking: what is the smallest number of states that are needed by a finite state automata (FSA) to solve the given problem? You know I love FSA, and have previously shown their power.
So what is new with streaming? Partly it’s that usually streaming algorithms use randomness, but we could of course replace a FSA by a random finite state automata. So that is not new, since such models have been studied for decades.
I think streaming is new for several reasons—even if the basic model is not really new. The reasons are:

Yet, already in 1978 Ian Munro and Mike Paterson had results on computing the median in a model that was essentially the streaming model. They proved:
Theorem: The median of
numbers can be computed in
space with high probability in one pass over the numbers.
Theorem: The median of
space deterministically with two passes over the numbers.
So is streaming new? You decide.
Order Types of Streaming Models
In the classic FSA model the order of the data is set by the definition of the problem. I have already talked about BDD’s which allow the input order to be selected so that the task of solving the problem is as easy as possible. Streaming models allow an even richer class of order types, which is the principle reason they are exciting.
To explain the notion of order type let us focus on problems that concern matrices. The general ideas apply to many other areas, but I think that the explanation will be easier if we focus first on matrices. Let 

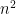

Here are some possible input order types:
Natural: This is an order that only depends on the input being a matrix. Some choices include row order and column order. Note the order has nothing to do with the problem being considered. Best Oblivious: This is the order that is used by BDD’s. The entries of the matrix are sent in the manner that is best for the problem. However, the order can only depend on the problem, not on the actual matrix . This is why the order is called “oblivious.”
Adversarial: This order allows an adversary to look at the input matrix and then decide what order to send the matrix entries to the algorithm. The order thus can be non-oblivious, and the adversary can try to make the input ordering as nasty as possible. This is the most popular, and standard order type for streaming models.
Random: This is just what you would guess: the entries of are send in a random order.
Sorted: This order sends the entries of after they have been sorted according to some rule. For example, the order could be: send the entries sorted first by the value, and then by the indices.
Best Order: This is a new order that was introduced by Atish and Danupon. More on this in a minute.
. This is why the order is called “oblivious.”
Adversarial: This order allows an adversary to look at the input matrix and then decide what order to send the matrix entries to the algorithm. The order thus can be non-oblivious, and the adversary can try to make the input ordering as nasty as possible. This is the most popular, and standard order type for streaming models.
Random: This is just what you would guess: the entries of are send in a random order.
Sorted: This order sends the entries of after they have been sorted according to some rule. For example, the order could be: send the entries sorted first by the value, and then by the indices.
Best Order: This is a new order that was introduced by Atish and Danupon. More on this in a minute.
In all these models often the ability to send the input more than once to the algorithm is allowed. Thus, we could look at the random order type, but allow 
Best Order Streaming Model
Any streaming model can be viewed as a protocol between Alice and Bob. Alice wants to determine some property of the matrix
Unfortunately, for many problems this model is too hard. In one of the earliest papers in this area, it was shown that many problems require prohibitively large amount of space to solve, if the order is worst case. This result has been extended by a more recent result that shows that most graph problems cannot be solved efficiently—even if multiple passes are allowed.
In the best order model Alice and Bob work together: however, Alice does not trust Bob, so she must check that Bob is playing fair. Her big advantage over the adversarial streaming model is that Bob will send the entries in an order that is helpful. Still Alice must check that Bob is playing by the rules. Another way to think of the best order model is that Bob is a prover and Alice is a checker. The prover can play fair and give Alice an easy-to-check proof, or he can try to cheat. In either case Alice must carefully check Bob.
Perhaps an example will help. Suppose that Alice wants to determine whether or not a matrix is the adjacency matrix of a directed cycle of length
Then, Bob will send the entries in the order: first 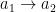

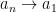

Well not quite. Alice is a checker, so she must be prepared that Bob could send a vertex twice:
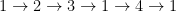
is not valid but would fool Alice, if she is not careful. Thus, Alice must also check that this does not happen. She can do all this in polylog space provided she can uses randomness.
The Main Results
Atish and Danupon prove a number of results in their paper. They study the best order complexity of several graph properties. Instead of entries of a matrix, now the objects being sent by Bob are edges of the graph. The pioneer work in this area was done by Joan Feigenbaum, Sampath Kannan, Andrew McGregor, Siddharth Suri, and Jian Zhang in their beautiful paper. They proved, among many other results, the following:
Theorem: In the adversarial streaming model, proving a graph is connected requires
.
As usual
Theorem: In the best order streaming model, proving a graph is connected can be done in random
space.
Thus, there is an exponential improvement from the adversarial order to the best order.
I will briefly sketch the idea of the proof of the best order result, as usual please see the paper for the details. The key idea is that Bob will first send a spanning tree of the graph. Then, Alice only needs to check connectivity for trees. The trick is to break up the spanning tree into pieces so that Alice can check each piece easily, and also so that she can put the pieces together. Recall all this must be done in small space—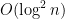
Another result is:
Theorem: The problem of proving that a graph has a perfect matching can be done by a randomized algorithm in
space in the best order streaming model.
Covert Channels
In the above protocols it is necessary for Bob to send more than edges, sometimes he needs to send short messages to Alice. For example, in the connectivity result he needs to send the message: “that is the end of the spanning tree.” In the best order model, like the other models of streaming, only the edges can be sent. Yet Bob can insert short comments, by using a covert channel. Bob can encode messages into how he sends the edges to Alice. There are several ways to do this: suppose we have an ordering on the vertices of the graph and let 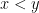




Note, we could have allowed Bob to inject “messages,” but we liked the fact that the best order model was like all the streaming models. However, Bob can use the covert encoding tricks to send extra messages to Alice. In all the algorithms so far this covert trick has been sufficient. I like that covert channels, which are usually viewed as a problem in security, can be used here for a positive purpose.
Here is the sketch of the protocol for the perfect matching problem—note the need for one covert message. Bob sends 
- Find
- Check if the first
. This can be done by using “fingerprinting” via a random hash function.
- Check if there are
Alice accepts, if the input passes all the above tests. This yields a random protocol.
Open Problems
There are many open problems in the streaming area in general, and with respect to the best ordering in particular. The following are some problems that have not been solved for best order:
- Is a graph bipartite?
- Is a graph planar?
- Is a graph 2-connected?
Like this:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK