

[译]C++17,使用 string_view 来避免复制
source link: https://blog.csdn.net/tkokof1/article/details/82527370
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
[译]C++17,使用 string_view 来避免复制
看到一个介绍 C++17 的系列博文(原文),有十来篇的样子,觉得挺好,看看有时间能不能都简单翻译一下,这是第五篇~
当字符串数据的所有权已经确定(譬如由某个string对象持有),并且你只想访问(而不修改)他们时,使用 std::string_view 可以避免字符串数据的复制,从而提高程序效率,这(指程序效率)也是这篇文章的主要内容.
这次要介绍的 string_view 是 C++17 的一个主要特性.
我假设你已经了解了一些 std::string_view 的知识,如果没有,可以看看我之前的这篇文章.C++ 中的 string 类型在堆上存放自己的字符串数据,所以当你处理 string 类型的时候,很容易就会产生(堆)内存分配.
Small string optimisation
我们先看下以下的示例代码:
#include <iostream>
#include <string>
void* operator new(std::size_t count)
{
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str) {}
int main()
{
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string small = "0123456789";
std::string substr = small.substr(5);
std::cout << " " << substr << std::endl;
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(small);
getString("0123456789");
const char message[] = "0123456789";
getString(message);
std::cout << std::endl;
return 0;
}
代码第4到第8行,我重载了全局的 new 操作符,这样我就能跟踪(堆)内存的分配了,而后,代码分别在第18行,第19行,第27行,第29行创建了string对象,所以这几处代码都会产生(堆)内存分配.相关的程序输出如下:
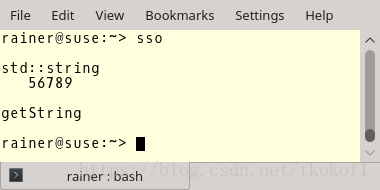
咦, 程序竟然没有产生内存分配?这是怎么回事?其实 string 类型只有在字符串超过指定大小(具体实现相关)时才会申请(堆)内存,对于 MSVC 来说,指定大小为 15, 对于 GCC 和 Clang,这个值则为 23.
这也就意味着,较短的字符串数据是直接存储于 string 的对象内存中的,不需要分配(堆)内存.
从现在开始,示例代码中的字符串将拥有至少30个字符,这样我们就不需要关注短字符串优化了.好了,带着这个前提(字符串长度>=30个字符),让我们重新开始讲解.
No memory allocation required
现在, std::string_view 无需复制字符串数据的优点就更加明显了(std::string不进行短字符串优化的情况下),下面的代码就是例证.
#include <cassert>
#include <iostream>
#include <string>
#include <string_view>
void* operator new(std::size_t count)
{
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str) {}
void getStringView(std::string_view strView) {}
int main()
{
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string large = "0123456789-123456789-123456789-123456789";
std::string substr = large.substr(10);
std::cout << std::endl;
std::cout << "std::string_view" << std::endl;
std::string_view largeStringView{ large.c_str(), large.size() };
largeStringView.remove_prefix(10);
assert(substr == largeStringView);
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(large);
getString("0123456789-123456789-123456789-123456789");
const char message[] = "0123456789-123456789-123456789-123456789";
getString(message);
std::cout << std::endl;
std::cout << "getStringView" << std::endl;
getStringView(large);
getStringView("0123456789-123456789-123456789-123456789");
getStringView(message);
std::cout << std::endl;
return 0;
}
代码22行,23行,39行,41行因为创建了 string 对象 所以会分配(堆)内存,但是代码29行,30行,47行,48行,49行也相应的创建了 string_view 对象,但是并没有发生(堆)内存分配!
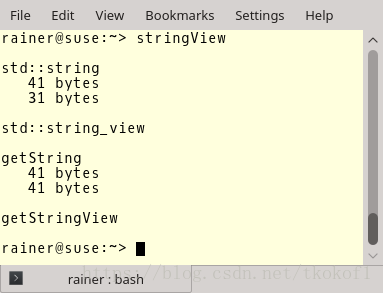
这个结果令人印象深刻,(堆)内存分配是一个非常耗时的操作,尽量的避免(堆)内存分配会给程序带来很大的性能提升,使用 string_view 能提升程序效率的原因也正是在此,当你需要创建很多 string 的子字符串时, string_view 带来的效率提升将更加明显.
O(n) versus O(1)
std::string 和 std::string_view 都有 substr 方法, std::string 的 substr 方法返回的是字符串的子串,而 std::string_view 的 substr 返回的则是字符串子串的"视图".听上去似乎两个方法功能上比较相似,但他们之间有一个非常大的差别: std::string::substr 是线性复杂度, std::string_view::substr 则是常数复杂度.这意味着 std::string::substr 方法的性能取决于字符串的长度,而std::string_view::substr 的性能并不受字符串长度的影响.
让我们来做一个简单的性能对比:
#include <chrono>
#include <fstream>
#include <iostream>
#include <random>
#include <sstream>
#include <string>
#include <vector>
#include <string_view>
static const int count = 30;
static const int access = 10000000;
int main()
{
std::cout << std::endl;
std::ifstream inFile("grimm.txt");
std::stringstream strStream;
strStream << inFile.rdbuf();
std::string grimmsTales = strStream.str();
size_t size = grimmsTales.size();
std::cout << "Grimms' Fairy Tales size: " << size << std::endl;
std::cout << std::endl;
// random values
std::random_device seed;
std::mt19937 engine(seed());
std::uniform_int_distribution<> uniformDist(0, size - count - 2);
std::vector<int> randValues;
for (auto i = 0; i < access; ++i) randValues.push_back(uniformDist(engine));
auto start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i)
{
grimmsTales.substr(randValues[i], count);
}
std::chrono::duration<double> durString = std::chrono::steady_clock::now() - start;
std::cout << "std::string::substr: " << durString.count() << " seconds" << std::endl;
std::string_view grimmsTalesView{ grimmsTales.c_str(), size };
start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i)
{
grimmsTalesView.substr(randValues[i], count);
}
std::chrono::duration<double> durStringView = std::chrono::steady_clock::now() - start;
std::cout << "std::string_view::substr: " << durStringView.count() << " seconds" << std::endl;
std::cout << std::endl;
std::cout << "durString.count()/durStringView.count(): " << durString.count() / durStringView.count() << std::endl;
std::cout << std::endl;
return 0;
}
展示程序结果之前,让我先来简单描述一下:测试代码的主要思路就是读取一个大文件的内容并保存为一个 string ,然后分别使用 std::string 和 std::string_view 的 substr 方法创建很多子字符串.我很好奇这些子字符串的创建过程需要花费多少时间.
我使用了<格林童话>作为程序的读取文件.代码中的 grimmTales(第22行) 存储了文件的内容.代码34行中我向 std::vector 填充了 10000000 个范围为[0, size - count - 2]的随机数字.接着就开始了正式的性能测试.代码37行到40行我使用 std::string::substr 创建了很多长度为30的子字符串,之所以设置长度为30,是为了规避 std::string 的短字符串优化.代码46行到49行使用 std::string_view::substr 做了相同的工作(创建子字符串).
程序的输出如下,结果中包含了文件的长度, std::string::substr 所花费的时间, std::string_view::substr 所花费的时间以及他们之间的比例.我使用的编译器是 GCC 6.3.0.
Size 30
没有开启编译器优化的结果:
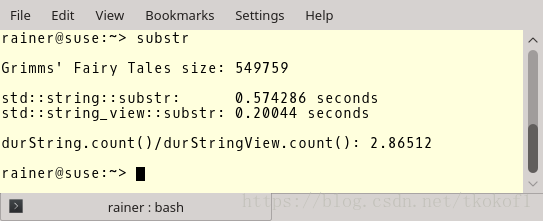
开启编译器优化的结果:
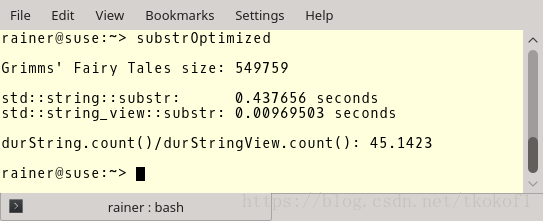
编译器的优化对于 std::string::substr 的性能提升并没有多大作用,但是对于 std::string_view::substr 的性能提升则效果明显.而 std::string_view::substr 的效率几乎是 std::string::substr 的 45 倍!
Different sizes
那么如果我们改变子字符串的长度,上面的测试代码又会有怎样的表现呢?当然,相关测试我都开启了编译器优化,并且相关的数字我都做了3位小数的四舍五入.
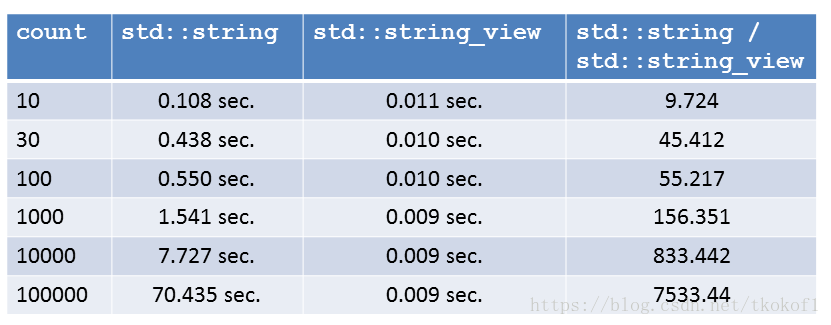
对于上面的结果我并不感到惊讶,这些数字正好反应了 std::string::substr 和 std::string_view::substr 的算法复杂度. std::string::substr 是线性复杂度(依赖于字符串长度), std::string_view::substr 则是常数复杂度(不依赖于字符串长度).最后的结论就是: std::string_view::substr 的性能要大幅优于 std::string::substr.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK