

磁盘快照服务USnap:公有云连续数据保护(CDP)系统升级改造实践
source link: https://zhuanlan.zhihu.com/p/364720375
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
磁盘快照服务USnap:公有云连续数据保护(CDP)系统升级改造实践
UCloud在2015年推出了为云主机磁盘提供持续数据保护(CDP)的数据方舟(UDataArk)产品,支持最小精确到秒级的恢复,针对数据删除或者丢失事件,能够最大程度的挽回数据。数据方舟已经在多个数据安全案例中得到应用,并得到了众多客户的认可。
近些年,随着用户高性能存储场景需求的增多,SSD云盘和RSSD云盘成为主流选择, 但是数据方舟只针对本地盘及普通云盘,SSD云盘和RSSD云盘缺乏高效的备份手段成为用户的痛点。为此我们推出了磁盘快照服务(USnap),USnap基于数据方舟CDP技术并进一步升级,以更低的成本为全系列云盘(普通/SSD/RSSD)提供了数据备份功能。
如何接入SSD/RSSD云盘等高性能设备以及如何降低连续数据保护功能的实现成本,是USnap产品要解决的两个核心问题。这不仅仅需要在数据方舟架构层面上做出改进,所有IO路径的相关模块也需要做重新设计。本文将详细介绍USnap是如何使用数据方舟CDP技术并对其升级改造的技术细节。
Client捕获用户写IO
方舟备份存储集群独立于UDisk存储集群,是我们重要的设计前提,这保证了即使出现了UDisk集群遭遇故障而导致数据丢失的极端事件,用户仍能从备份存储集群中恢复数据。对此,我们实现了一个ark plug-in,集成到了UDisk的client中,这个plug-in会异步的捕获UDisk的写IO,并将其推送到方舟备份存储集群。
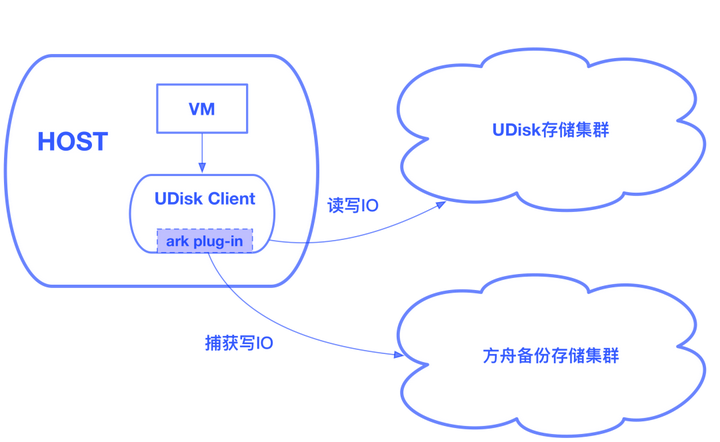
如何高效的捕获UDisk IO是个重要的问题,我们希望对UDisk的IO路径影响到最低。对于SSD UDisk client和RSSD UDisk client,IO的捕获模式是完全不同的。
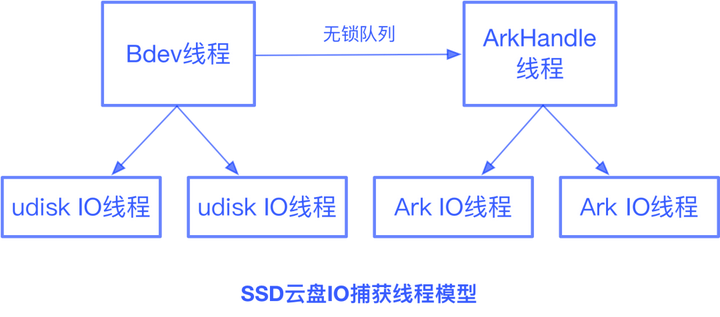
对于SSD UDisk,Bdev线程在接受一个IO后,先提交到UDisk的IO线程中,如果是写IO还需要推送至方舟备份存储集群。对此Bdev线程会构建一个ArkIORequest,拷贝一份包含data的智能指针对象,加入到无锁队列中。ArkHandle线程从无锁队列中获取IO,转发给ArkIO线程进行推送。UDisk IO完成后,无需等待方舟IO完成即可返回成功。UDisk IO和方舟IO均完成后,data才会被释放。
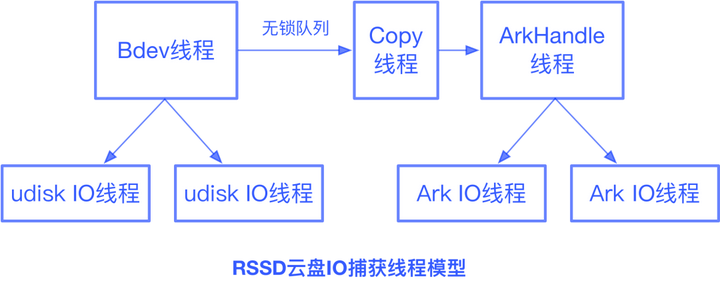
对于RSSD UDisk,由于采用SPDK Vhost方案,Vhost和guest VM共享内存,UDisk IO完成后,data内存空间会立即被guest VM使用。为此我们加入了一个copy线程,由copy线程从无锁队列中获取bdev_io,进行数据copy,数据copy完毕后再构建一个ArkIORequest转发给ArkIO线程进行推送,方舟IO完成后data由方舟plug-in中的ArkHandle进行释放。
我们模拟了各种类型的IO场景,研究方舟plug-in对UDisk性能的影响。发现在低io_depth的场景下,方舟功能对于UDisk性能的影响最大不会超过5%,在高io_depth的场景下,方舟功能对于UDisk性能的影响接近0%。可见方舟plug-in实现了高效的数据捕获与转发,不会影响用户的线上业务。
块层IO可以理解为一个三元组(sector, sector_num, data),代表读写位置、读写大小和实际数据。对于CDP系统,IO的三元组信息是不够的,需要标记额外信息,才能够恢复到任何一个时间点。在数据捕获时,所有的写IO都会标记好序列号(seq_num),序列号保证严格连续递增,这是我们保证块级数据一致性的基础。并且所有的写IO也会打上时间戳,方舟plug-in会保证即使在出现时钟跳变的情况下,时间戳也不会出现回退。这样数据变化及其时间戳都被保存下来,后端可以根据这些信息通过某种方式回放,恢复到过去的任意时刻,这就是CDP技术的基本原理。在推送到方舟备份存储集群前,方舟plug-in会对IO进行合并,这可以显著减少方舟接入层的IOPS。
Front实时IO接入层
方舟备份集群采用分层存储,实时IO接入层使用少量的NVME等高速存储设备,承接海量实时IO,实时IO会定期下沉到采用大量HDD设备构建的容量存储层。方舟的接入层(Front)是整个数据方舟系统的门户,其性能关系到能否接入SSD/RSSD云盘等高性能的设备。
原始的Front是基于Log-structured的设计,每块逻辑盘会被分配一组Front节点,对于一次简单的磁盘IO写入操作,client将IO转发到Primary Front节点,Primary Front节点将此次的IO追加写入到最新的Log中,并将IO同步到Slavery Front节点。
分析可知该设计存在以下问题:1. 一块逻辑盘的实时IO只落在一组(Primary-Slavery)Front节点上,所以系统对于单块逻辑盘的接入性能受到Front单节点性能限制。这种设计是无法接入RSSD云盘这种超高性能设备的。2.虽然通过hash的方式将用户逻辑盘打散分布到整个接入层集群,但是可能出现分配在同一组Front节点的多块逻辑盘同时存在高IO行为,由此产生了热点问题,虽然可以通过运维手段将其中的部分逻辑盘切换到空闲的Front节点上,但这并不是解决问题的最佳方式。
针对于此,我们提出了基于Stream数据流的设计,以满足高IO场景下业务对于接入能力的要求。Stream数据流的概念即是将逻辑盘的所有写入数据抽象成为一段数据流,数据只在Stream尾部进行追加写。Stream按照固定大小分片,每个分片按照一致性hash算法映射到一个归置组,归置组代表一个副本组,由存储资源按照一定策略组成。这样就将一块逻辑盘的实时IO打散到了所有接入层集群上,这不仅解决了接入RSSD云盘这种超高性能设备的问题,同时还解决了接入层热点的问题。
Stream数据流符合Buffer的特性,即从尾部写入、从头部读出。我们使用一组数据来标识Stream数据流的有效区域:read_offset和write_offset。当Stream有实时数据写入,write_offset增长。Shuffle模块会处理实时IO下沉到容量存储层的工作。Shuffle会从Front定期拉取数据,在内存中进行分片(sharding),并组织为Journal数据,推送至下层的Arker容量存储层。推送Arker成功后,read_offset更新。对于已经下沉到方舟Arker容量存储层的数据,我们会对其进行回收以释放存储资源。
Arker容量存储层
CDP数据需要按照粒度(Granu)进行组织。根据业务需要,Granu被分为5种类型:journal、hour、day、base和snapshot,journal是秒级数据,包含用户的原始写请求;hour代表小时级别的增量数据;day代表天级别的增量数据;base是CDP的最底层数据;snapshot是用户的手动快照数据。Granu会按照设定的备份策略进行合并。以默认的支持恢复到12小时内任意一秒、24小时内的任意整点以及3天内的任意零点为例,journal至少会被保留12小时,超过12小时的journal会被合并为hour,此时数据的tick信息会被丢弃,之后的时间区间无法再恢复到秒级,超过24小时的hour会被合并为day,超过3天的day会和base合并为新的base,对于snapshot则会长久保留除非用户主动删除了快照。
作为方舟的容量存储层,Arker为5类不同的Granu提供了统一的存储;对于5种类型的Granu,又存在3种存储格式:BASE Blob、CUT Blob和JOURNAL Bob。其中base和snapshot两类Granu以BASE Blob格式存储,day和hour两类Granu以CUT Blob格式存储,journal类型的Granu以JOURNAL Blob格式存储。
对于journal、hour和day三类Granu,我们直接按分片进行存储,每个有数据存在的分片都唯一对应了一个inode对象,这个inode对象关联一个JOURNAL Blob或CUT Blob。对于base和snapshot两类Granu,我们将分片中的数据进一步细化,切分成一系列的TinyShard作为重删单元,每个TinyShard也会唯一对应一个inode对象,这个inode对象会关联一个BASE Blob,数据相同的TinyShard会指向同一个inode对象,复用BASE Blob,由此达到了重删的目的。
为了提高合并效率,我们还将索引和数据的存储进行分离,以上所有业务元数据(Granu、Shard/TinyShard、Inode)都以key-value的形式存储在KVDevice中,Blob数据经过压缩后存储在FSDevice中,数据压缩算法采用zstd算法,比起原先使用的snappy算法,又节约了至少30%的存储成本。
一次完整的回滚流程
整个回滚流程由调度模块Chrono进行控制。当用户指定了一个回滚时间点,Chrono首先通过查询Granu元数据确认该目标点数据命中的位置。命中位置只有两种情况,一种是目标点数据还在Front接入层,尚未被Shuffle推送至Arker容量存储层,另一种是已经被Shuffle推送至Arker容量存储层。
如果是第一种情况,Chrono会命令Shuffle主动拉取这部分数据至Arker容量存储层。在确认目标点数据已经在Arker容量存储层后,Chrono会查询获取到所有需要合并的Granu以及需要合并到哪个seq_num,并分发合并任务至所有Arker。Arker容量存储层会对这些Granu进行合并,对于一个合并任务,会首先进行索引合并,随后会根据已经合并完成的索引进行数据合并,合并完成后最终会生成一份新版本的BASE,这就是恢复后的全量数据。在得到恢复后的全量数据后,再将数据写回到UDisk集群中。
我们可以看到,数据合并阶段是以shard为单位并发进行的,能利用到所有容量层磁盘的IO能力;数据回吐UDisk阶段,也利用了方舟和UDisk都是分布式存储,可以采取分片并发对拷的方式将数据写入到UDisk集群。因此恢复的RTO也能得到保证,1TB的数据恢复时间通常在30min以内。
总结
本文围绕着公有云CDP备份系统如何构建、CDP系统如何接入高性能IO设备以及CDP系统如何降低实现成本等几个主要问题,介绍了UCloud磁盘快照服务USnap在业务架构、存储引擎等多方面的设计考虑和优化方案。
后续我们还会在多个方面继续提升磁盘快照服务USnap的使用体验。产品上将会提供可以自定义备份时间范围的增值服务,让用户可以自定义秒级、小时级、天级的保护范围,满足用户的不同需求。技术上,则会引入全量全删和Erasure Coding等技术进一步降低成本,以及使用Copy On Read技术加快回滚速度,让用户能够享受到更先进技术带来的丰富功能、性能提升和价格红利。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK