

利用Python实现K-Means聚类—以创造营2021集资数据为例
source link: https://zhuanlan.zhihu.com/p/362899422
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
利用Python实现K-Means聚类—以创造营2021集资数据为例
快来给小九高卿尘投票把~~~
本文主要讲述利用Python实现K-Means聚类的具体步骤及代码。
本实验以创造营2021选手集资数据(截至2021年4月6日)为例,具体数据如下:
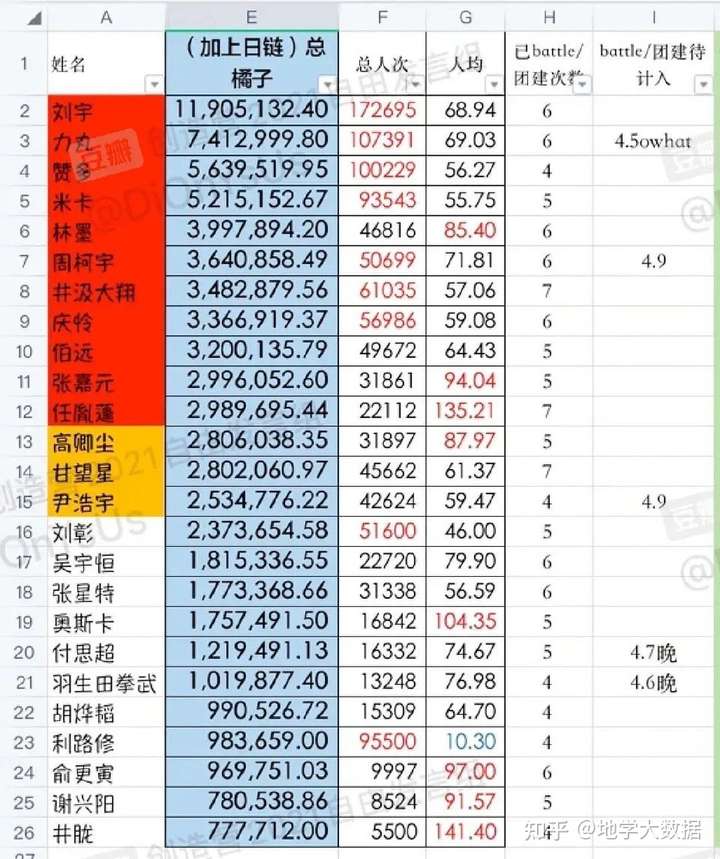 创造营2021选手集资数据
创造营2021选手集资数据第一步:导入相关功能包
import pandas as pd
import numpy as np
from scipy.spatial.distance import cdist
from sklearn import preprocessing
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt # 导入matplotlib的plt第二步:利用pandas读取实验数据
# 读取数据
currentData = pd.read_csv('D:\\数据.csv')
print(currentData)输出结果:
第三步:对实验数据进行预处理
①剔除数据异常值
数据中的异常值能明显改变K-Means聚类结果,因此执行聚类操作之前需要进行异常值处理。不过本次实验的数据是创造营2021选手真实的集资数据,不存在异常值的情况,因此不需要进行异常值处理。
②数据标准化
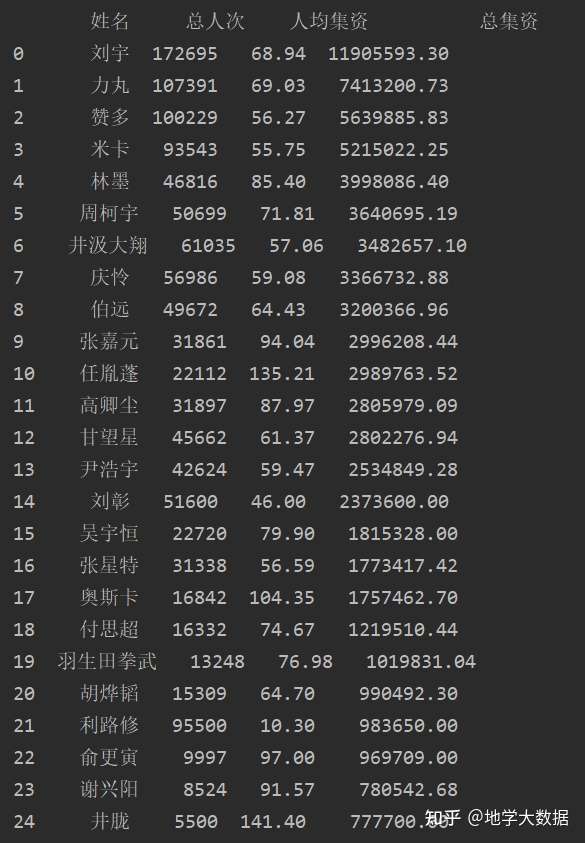
不同变量之间存在数值规模或量纲的差异会明显影响K-Means聚类的结果。例如集资人数分布区间是[0,200000],人均集资是[0,200],总集资是[0,20000000],如果没有标准化操作,那么聚类结果将主要受到总集资的影响。本文利用sklearn中preprocessing功能对集资数据进行标准化处理,使标准化后的“集资人数”、“人均集资”以及“总集资”3个变量在一个量纲。
# 对总人次和人均集资进行标准化处理
nameDataFrame = pd.DataFrame(currentData[['姓名']],columns=['姓名'])
valueDataFrame = pd.DataFrame(sklearn.preprocessing.StandardScaler().fit_transform(currentData[['总人次','人均']]),columns=['总人次','人均'])
traninDataFrame = nameList.join(valueDataFrame)
print(traninDataFrame)输出结果:
第四步:执行K-Means聚类
kmeans = KMeans(n_clusters=3) # 指定聚类数量
kmeans.fit(valueDataFrame) # 执行聚类
result_kmeans = pd.DataFrame(kmeans.labels_, columns=['type'])
result = currentData.join(result_kmeans) # 将聚类结果与数据合并
print(result)输出结果:
第五步:找到最合适的聚类数量
本文使用肘部法则进行聚类数量的选择。肘部法则的原理可以点击下面链接学习。
肘部法则和轮廓系数_qq_28957465的博客-CSDN博客_肘部法则blog.csdn.net肘部法则实现代码:
# 利用肘部法则找到合适的聚类数量
K = range(1, 10) # 执行9次聚类尝试
meandistortions = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(valueDataFrame)
# 计算肘部系数
meandistortions.append(sum(np.min(cdist(valueDataFrame, kmeans.cluster_centers_, 'euclidean'), axis=1))/valueDataFrame.shape[0])
# 进行可视化
plt.plot(K, meandistortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Average Dispersion')
plt.title('Selecting k with the Elbow Method')
plt.show()肘部法则输出结果:
通过肘部法则得到聚类数量为3时,聚类结果较为合理。
第六步:执行聚类、可视化并进行统计分析
当聚类数量为3时的聚类结果:
可视化结果:
统计分析结果:
从统计分析数据中可以看出,创造营2021选手大概可以分为以下3类:
第一类,类别编号为1的,人气极高(总人次极高)且粉丝狂热程度较高(人均集资较高),因此总集资排在绝对领先地位,代表人物有刘宇、力丸。
第二类,类别编号为0的,人气较高(总人次较高)但粉丝狂热程度一般(人均集资不高),因此总集资排在相对领先地位,且竞争十分激烈,代表人物有林墨、周柯宇。
第三类,类别编号为2的,人气一般(总人次不高)但粉丝狂热程度极高(人均集资极高),虽然粉丝十分愿意花钱和花时间但是由于人数较少,这类选手在总集资排在相对落后地位,代表人物有任胤蓬、奥斯卡、井胧。
上面就是利用Python实现K-Means聚类的具体步骤及代码
快来给小九高卿尘投票把~~~

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK