

六个问题助你理解 React Fiber
source link: https://segmentfault.com/a/1190000039682751
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
React Fiber 是Facebook花费两年余时间对 React 做出的一个重大改变与优化,是对 React 核心算法的一次重新实现。从Facebook在 React Conf 2017会议上确认,React Fiber 会在React 16 版本发布至今,也已过去三年有余,如今,React 17 业已发布,社区关于Fiber的优秀文章不在少数。
本文源于一次团队内部的技术分享,借鉴社区优秀文章,结合个人理解,进行整合,从六个问题出发,对 React Fiber 进行理解与认识,同时对时下热门的前端框架Svelte进行简要介绍与剖析,希望对正在探究 React 及各前端框架的小伙伴们能有所助益。
全文大量参考和引用以下几篇博文,读者可自行查阅:
一、React 的设计理念是什么?
React官网在React哲学一节开篇提到:
我们认为,React 是用 JavaScript 构建快速响应的大型 Web 应用程序的首选方式。它在 Facebook 和 Instagram 上表现优秀。React 最棒的部分之一是引导我们思考如何构建一个应用。
由此可见,React 追求的是 “快速响应”,那么,“快速响应“的制约因素都有什么呢?
- CPU的瓶颈:当项目变得庞大、组件数量繁多、遇到大计算量的操作或者设备性能不足使得页面掉帧,导致卡顿。
- IO的瓶颈:发送网络请求后,由于需要等待数据返回才能进一步操作导致不能快速响应。
本文要聊的fiber 架构主要就是用来解决 CPU 和网络的问题,这两个问题一直也是最影响前端开发体验的地方,一个会造成卡顿,一个会造成白屏。为此 react 为前端引入了两个新概念:Time Slicing 时间分片和Suspense。
二、React的“先天不足” —— 听说 Vue 3.0 采用了动静结合的 Dom diff,React 为何不跟进?
Vue 3.0 动静结合的 Dom diff
Vue3.0 提出动静结合的 DOM diff 思想,动静结合的 DOM diff其实是在预编译阶段进行了优化。之所以能够做到预编译优化,是因为 Vue core 可以静态分析 template,在解析模版时,整个 parse 的过程是利用正则表达式顺序解析模板,当解析到开始标签、闭合标签和文本的时候都会分别执行对应的回调函数,来达到构造 AST 树的目的。
借助预编译过程,Vue 可以做到的预编译优化就很强大了。比如在预编译时标记出模版中可能变化的组件节点,再次进行渲染前 diff 时就可以跳过“永远不会变化的节点”,而只需要对比“可能会变化的动态节点”。这也就是动静结合的 DOM diff 将 diff 成本与模版大小正相关优化到与动态节点正相关的理论依据。
React 能否像 Vue 那样进行预编译优化?
Vue 需要做数据双向绑定,需要进行数据拦截或代理,那它就需要在预编译阶段静态分析模版,分析出视图依赖了哪些数据,进行响应式处理。而 React 就是局部重新渲染,React 拿到的或者说掌管的,所负责的就是一堆递归 React.createElement 的执行调用(参考下方经过Babel转换的代码),它无法从模版层面进行静态分析。JSX 和手写的 render function 是完全动态的,过度的灵活性导致运行时可以用于优化的信息不足。
JSX 写法:
<div>
<h1>六个问题助你理解 React Fiber</h1>
<ul>
<li>React</li>
<li>Vue</li>
</ul>
</div>递归 React.createElement:
// Babel转换后
React.createElement(
"div",
null,
React.createElement(
"h1",
null,
"\u516D\u4E2A\u95EE\u9898\u52A9\u4F60\u7406\u89E3 React Fiber"
),
React.createElement(
"ul",
null,
React.createElement("li", null, "React"),
React.createElement("li", null, "Vue")
)
);JSX vs Template

- JSX 具有 JavaScript 的完整表现力,可以构建非常复杂的组件。但是灵活的语法,也意味着引擎难以理解,无法预判开发者的用户意图,从而难以优化性能。
- Template 模板是一种非常有约束的语言,你只能以某种方式去编写模板。
既然存在以上编译时先天不足,在运行时优化方面,React一直在努力。比如,React15实现了batchedUpdates(批量更新)。即同一事件回调函数上下文中的多次setState只会触发一次更新。
但是,如果单次更新就很耗时,页面还是会卡顿(这在一个维护时间很长的大应用中是很常见的)。这是因为React15的更新流程是同步执行的,一旦开始更新直到页面渲染前都不能中断。
三、从架构演变看不断进击的 React 都做过哪些优化?
React渲染页面的两个阶段
- 调度阶段(reconciliation):在这个阶段 React 会更新数据生成新的 Virtual DOM,然后通过Diff算法,快速找出需要更新的元素,放到更新队列中去,得到新的更新队列。
- 渲染阶段(commit):这个阶段 React 会遍历更新队列,将其所有的变更一次性更新到DOM上。
React 15 架构
React15架构可以分为两层:
- Reconciler(协调器)—— 负责找出变化的组件;
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上;
在React15及以前,Reconciler采用递归的方式创建虚拟DOM,递归过程是不能中断的。如果组件树的层级很深,递归会占用线程很多时间,递归更新时间超过了16ms,用户交互就会卡顿。
为了解决这个问题,React16将递归的无法中断的更新重构为异步的可中断更新,由于曾经用于递归的虚拟DOM数据结构已经无法满足需要。于是,全新的Fiber架构应运而生。
React 16 架构
为了解决同步更新长时间占用线程导致页面卡顿的问题,也为了探索运行时优化的更多可能,React开始重构并一直持续至今。重构的目标是实现Concurrent Mode(并发模式)。
从v15到v16,React团队花了两年时间将源码架构中的Stack Reconciler重构为Fiber Reconciler。
React16架构可以分为三层:
- Scheduler(调度器)—— 调度任务的优先级,高优任务优先进入Reconciler;
- Reconciler(协调器)—— 负责找出变化的组件:更新工作从递归变成了可以中断的循环过程。Reconciler内部采用了Fiber的架构;
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上。
React 17 优化
React16的expirationTimes模型只能区分是否>=expirationTimes决定节点是否更新。React17的lanes模型可以选定一个更新区间,并且动态的向区间中增减优先级,可以处理更细粒度的更新。
Lane用二进制位表示任务的优先级,方便优先级的计算(位运算),不同优先级占用不同位置的“赛道”,而且存在批的概念,优先级越低,“赛道”越多。高优先级打断低优先级,新建的任务需要赋予什么优先级等问题都是Lane所要解决的问题。
Concurrent Mode的目的是实现一套可中断/恢复的更新机制。其由两部分组成:
- 一套协程架构:Fiber Reconciler
- 基于协程架构的启发式更新算法:控制协程架构工作方式的算法
资料参考:React17新特性:启发式更新算法
四、浏览器一帧都会干些什么以及requestIdleCallback的启示
浏览器一帧都会干些什么?
我们都知道,页面的内容都是一帧一帧绘制出来的,浏览器刷新率代表浏览器一秒绘制多少帧。原则上说 1s 内绘制的帧数也多,画面表现就也细腻。目前浏览器大多是 60Hz(60帧/s),每一帧耗时也就是在 16.6ms 左右。那么在这一帧的(16.6ms) 过程中浏览器又干了些什么呢?

通过上面这张图可以清楚的知道,浏览器一帧会经过下面这几个过程:
- 接受输入事件
- 执行事件回调
- 执行 RAF (RequestAnimationFrame)
- 页面布局,样式计算
- 执行 RIC (RequestIdelCallback)
第七步的 RIC 事件不是每一帧结束都会执行,只有在一帧的 16.6ms 中做完了前面 6 件事儿且还有剩余时间,才会执行。如果一帧执行结束后还有时间执行 RIC 事件,那么下一帧需要在事件执行结束才能继续渲染,所以 RIC 执行不要超过 30ms,如果长时间不将控制权交还给浏览器,会影响下一帧的渲染,导致页面出现卡顿和事件响应不及时。
requestIdleCallback 的启示
我们以浏览器是否有剩余时间作为任务中断的标准,那么我们需要一种机制,当浏览器有剩余时间时通知我们。
requestIdleCallback((deadline) => {
// deadline 有两个参数
// timeRemaining(): 当前帧还剩下多少时间
// didTimeout: 是否超时
// 另外 requestIdleCallback 后如果跟上第二个参数 {timeout: ...} 则会强制浏览器在当前帧执行完后执行。
if (deadline.timeRemaining() > 0) {
// TODO
} else {
requestIdleCallback(otherTasks);
}
});// 用法示例
var tasksNum = 10000
requestIdleCallback(unImportWork)
function unImportWork(deadline) {
while (deadline.timeRemaining() && tasksNum > 0) {
console.log(`执行了${10000 - tasksNum + 1}个任务`)
tasksNum--
}
if (tasksNum > 0) { // 在未来的帧中继续执行
requestIdleCallback(unImportWork)
}
}其实部分浏览器已经实现了这个API,这就是requestIdleCallback。但是由于以下因素,Facebook 抛弃了 requestIdleCallback 的原生 API:
- 浏览器兼容性;
- 触发频率不稳定,受很多因素影响。比如当我们的浏览器切换tab后,之前tab注册的requestIdleCallback触发的频率会变得很低。
基于以上原因,在React中实现了功能更完备的requestIdleCallbackpolyfill,这就是Scheduler。除了在空闲时触发回调的功能外,Scheduler还提供了多种调度优先级供任务设置。
五、 Fiber 为什么是 React 性能的一个飞跃?
什么是 Fiber
Fiber 的英文含义是“纤维”,它是比线程(Thread)更细的线,比线程(Thread)控制得更精密的执行模型。在广义计算机科学概念中,Fiber 又是一种协作的(Cooperative)编程模型(协程),帮助开发者用一种【既模块化又协作化】的方式来编排代码。
在 React 中,Fiber 就是 React 16 实现的一套新的更新机制,让 React 的更新过程变得可控,避免了之前采用递归需要一气呵成影响性能的做法。
React Fiber 中的时间分片
把一个耗时长的任务分成很多小片,每一个小片的运行时间很短,虽然总时间依然很长,但是在每个小片执行完之后,都给其他任务一个执行的机会,这样唯一的线程就不会被独占,其他任务依然有运行的机会。
React Fiber 把更新过程碎片化,每执行完一段更新过程,就把控制权交还给 React 负责任务协调的模块,看看有没有其他紧急任务要做,如果没有就继续去更新,如果有紧急任务,那就去做紧急任务。
Stack Reconciler
基于栈的 Reconciler,浏览器引擎会从执行栈的顶端开始执行,执行完毕就弹出当前执行上下文,开始执行下一个函数,直到执行栈被清空才会停止。然后将执行权交还给浏览器。由于 React 将页面视图视作一个个函数执行的结果。每一个页面往往由多个视图组成,这就意味着多个函数的调用。
如果一个页面足够复杂,形成的函数调用栈就会很深。每一次更新,执行栈需要一次性执行完成,中途不能干其他的事儿,只能"一心一意"。结合前面提到的浏览器刷新率,JS 一直执行,浏览器得不到控制权,就不能及时开始下一帧的绘制。如果这个时间超过 16ms,当页面有动画效果需求时,动画因为浏览器不能及时绘制下一帧,这时动画就会出现卡顿。不仅如此,因为事件响应代码是在每一帧开始的时候执行,如果不能及时绘制下一帧,事件响应也会延迟。
Fiber Reconciler
在 React Fiber 中用链表遍历的方式替代了 React 16 之前的栈递归方案。在 React 16 中使用了大量的链表。
- 使用多向链表的形式替代了原来的树结构;
<div id="A">
A1
<div id="B1">
B1
<div id="C1"></div>
</div>
<div id="B2">
B2
</div>
</div>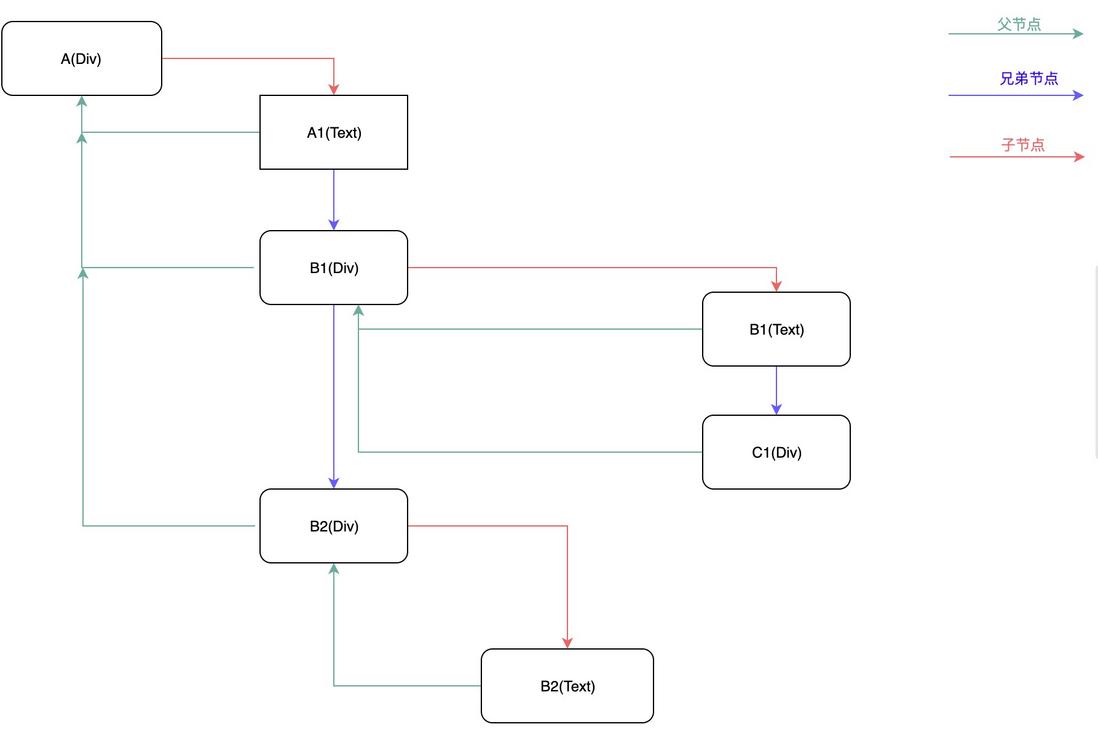
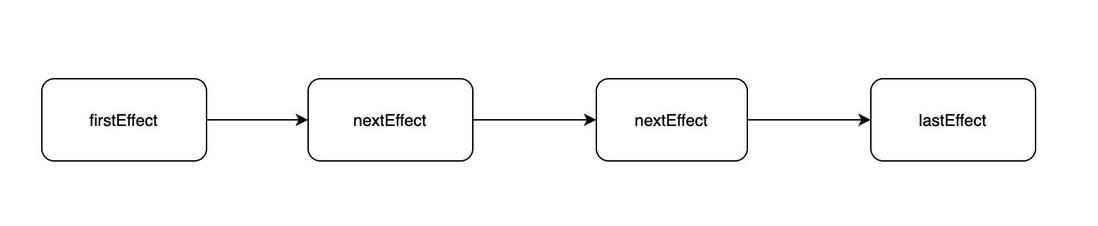
- 副作用单链表;
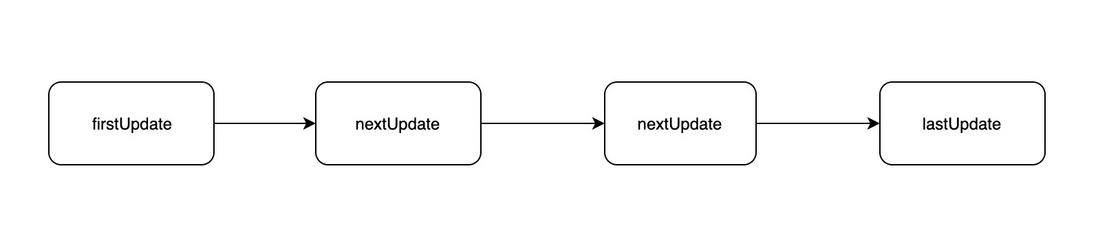
- 状态更新单链表;
链表是一种简单高效的数据结构,它在当前节点中保存着指向下一个节点的指针;遍历的时候,通过操作指针找到下一个元素。

链表相比顺序结构数据格式的好处就是:
- 操作更高效,比如顺序调整、删除,只需要改变节点的指针指向就好了。
- 不仅可以根据当前节点找到下一个节点,在多向链表中,还可以找到他的父节点或者兄弟节点。
但链表也不是完美的,缺点就是:
- 比顺序结构数据更占用空间,因为每个节点对象还保存有指向下一个对象的指针。
- 不能自由读取,必须找到他的上一个节点。
React 用空间换时间,更高效的操作可以方便根据优先级进行操作。同时可以根据当前节点找到其他节点,在下面提到的挂起和恢复过程中起到了关键作用。
斐波那契数列的 Fiber
递归形式的斐波那契数列写法:
function fib(n) {
if (n <= 2) {
return 1;
} else {
return fib(n - 1) + fib(n - 2);
}
}采用 Fiber 的思路将其改写为循环(这个例子并不能和 React Fiber 的对等):
function fib(n) {
let fiber = { arg: n, returnAddr: null, a: 0 }, consoled = false;
// 标记循环
rec: while (true) {
// 当展开完全后,开始计算
if (fiber.arg <= 2) {
let sum = 1;
// 寻找父级
while (fiber.returnAddr) {
if(!consoled) {
// 在这里打印查看形成的链表形式的 fiber 对象
consoled=true
console.log(fiber)
}
fiber = fiber.returnAddr;
if (fiber.a === 0) {
fiber.a = sum;
fiber = { arg: fiber.arg - 2, returnAddr: fiber, a: 0 };
continue rec;
}
sum += fiber.a;
}
return sum;
} else {
// 先展开
fiber = { arg: fiber.arg - 1, returnAddr: fiber, a: 0 };
}
}
}六、React Fiber 是如何实现更新过程可控?
更新过程的可控主要体现在下面几个方面:
- 任务挂起、恢复、终止
- 任务具备优先级
在 React Fiber 机制中,它采用"化整为零"的思想,将调和阶段(Reconciler)递归遍历 VDOM 这个大任务分成若干小任务,每个任务只负责一个节点的处理。
任务挂起、恢复、终止
workInProgress tree
workInProgress 代表当前正在执行更新的 Fiber 树。在 render 或者 setState 后,会构建一颗 Fiber 树,也就是 workInProgress tree,这棵树在构建每一个节点的时候会收集当前节点的副作用,整棵树构建完成后,会形成一条完整的副作用链。
currentFiber tree
currentFiber 表示上次渲染构建的 Filber 树。在每一次更新完成后 workInProgress 会赋值给 currentFiber。在新一轮更新时 workInProgress tree 再重新构建,新 workInProgress 的节点通过 alternate 属性和 currentFiber 的节点建立联系。
在新 workInProgress tree 的创建过程中,会同 currentFiber 的对应节点进行 Diff 比较,收集副作用。同时也会复用和 currentFiber 对应的节点对象,减少新创建对象带来的开销。也就是说无论是创建还是更新、挂起、恢复以及终止操作都是发生在 workInProgress tree 创建过程中的。workInProgress tree 构建过程其实就是循环的执行任务和创建下一个任务。
当第一个小任务完成后,先判断这一帧是否还有空闲时间,没有就挂起下一个任务的执行,记住当前挂起的节点,让出控制权给浏览器执行更高优先级的任务。
在浏览器渲染完一帧后,判断当前帧是否有剩余时间,如果有就恢复执行之前挂起的任务。如果没有任务需要处理,代表调和阶段完成,可以开始进入渲染阶段。
- 如何判断一帧是否有空闲时间的呢?
使用前面提到的 RIC (RequestIdleCallback) 浏览器原生 API,React 源码中为了兼容低版本的浏览器,对该方法进行了 Polyfill。
- 恢复执行的时候又是如何知道下一个任务是什么呢?
答案是在前面提到的链表。在 React Fiber 中每个任务其实就是在处理一个 FiberNode 对象,然后又生成下一个任务需要处理的 FiberNode。
其实并不是每次更新都会走到提交阶段。当在调和过程中触发了新的更新,在执行下一个任务的时候,判断是否有优先级更高的执行任务,如果有就终止原来将要执行的任务,开始新的 workInProgressFiber 树构建过程,开始新的更新流程。这样可以避免重复更新操作。这也是在 React 16 以后生命周期函数 componentWillMount 有可能会执行多次的原因。

任务具备优先级
React Fiber 除了通过挂起,恢复和终止来控制更新外,还给每个任务分配了优先级。具体点就是在创建或者更新 FiberNode 的时候,通过算法给每个任务分配一个到期时间(expirationTime)。在每个任务执行的时候除了判断剩余时间,如果当前处理节点已经过期,那么无论现在是否有空闲时间都必须执行该任务。过期时间的大小还代表着任务的优先级。
任务在执行过程中顺便收集了每个 FiberNode 的副作用,将有副作用的节点通过 firstEffect、lastEffect、nextEffect 形成一条副作用单链表 A1(TEXT)-B1(TEXT)-C1(TEXT)-C1-C2(TEXT)-C2-B1-B2(TEXT)-B2-A。
其实最终都是为了收集到这条副作用链表,有了它,在接下来的渲染阶段就通过遍历副作用链完成 DOM 更新。这里需要注意,更新真实 DOM 的这个动作是一气呵成的,不能中断,不然会造成视觉上的不连贯(commit)。
<div id="A1">
A1
<div id="B1">
B1
<div id="C1">C1</div>
<div id="C2">C2</div>
</div>
<div id="B2">
B2
</div>
</div>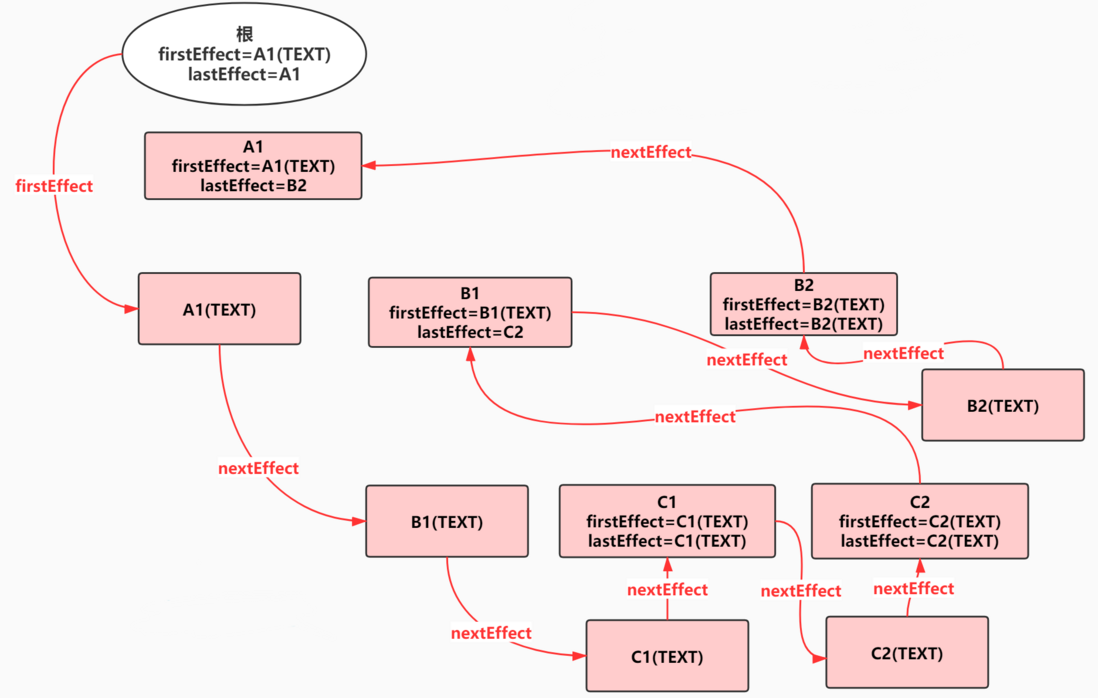
正是基于以上这些过程,使用Fiber,我们就有了在社区经常看到的两张对比图。
清晰展示及交互、源码可通过下面两个链接进入,查看网页源代码。
Fiber 结构长什么样?
基于时间分片的增量更新需要更多的上下文信息,之前的vDOM tree显然难以满足,所以扩展出了fiber tree(即Fiber上下文的vDOM tree),更新过程就是根据输入数据以及现有的fiber tree构造出新的fiber tree(workInProgress tree)。
FiberNode 上的属性有很多,根据笔者的理解,以下这么几个属性是值得关注的:return、child、sibling(主要负责fiber链表的链接);stateNode;effectTag;expirationTime;alternate;nextEffect。各属性介绍参看下面的class FiberNode:
class FiberNode {
constructor(tag, pendingProps, key, mode) {
// 实例属性
this.tag = tag; // 标记不同组件类型,如函数组件、类组件、文本、原生组件...
this.key = key; // react 元素上的 key 就是 jsx 上写的那个 key ,也就是最终 ReactElement 上的
this.elementType = null; // createElement的第一个参数,ReactElement 上的 type
this.type = null; // 表示fiber的真实类型 ,elementType 基本一样,在使用了懒加载之类的功能时可能会不一样
this.stateNode = null; // 实例对象,比如 class 组件 new 完后就挂载在这个属性上面,如果是RootFiber,那么它上面挂的是 FiberRoot,如果是原生节点就是 dom 对象
// fiber
this.return = null; // 父节点,指向上一个 fiber
this.child = null; // 子节点,指向自身下面的第一个 fiber
this.sibling = null; // 兄弟组件, 指向一个兄弟节点
this.index = 0; // 一般如果没有兄弟节点的话是0 当某个父节点下的子节点是数组类型的时候会给每个子节点一个 index,index 和 key 要一起做 diff
this.ref = null; // reactElement 上的 ref 属性
this.pendingProps = pendingProps; // 新的 props
this.memoizedProps = null; // 旧的 props
this.updateQueue = null; // fiber 上的更新队列执行一次 setState 就会往这个属性上挂一个新的更新, 每条更新最终会形成一个链表结构,最后做批量更新
this.memoizedState = null; // 对应 memoizedProps,上次渲染的 state,相当于当前的 state,理解成 prev 和 next 的关系
this.mode = mode; // 表示当前组件下的子组件的渲染方式
// effects
this.effectTag = NoEffect; // 表示当前 fiber 要进行何种更新(更新、删除等)
this.nextEffect = null; // 指向下个需要更新的fiber
this.firstEffect = null; // 指向所有子节点里,需要更新的 fiber 里的第一个
this.lastEffect = null; // 指向所有子节点中需要更新的 fiber 的最后一个
this.expirationTime = NoWork; // 过期时间,代表任务在未来的哪个时间点应该被完成
this.childExpirationTime = NoWork; // child 过期时间
this.alternate = null; // current 树和 workInprogress 树之间的相互引用
}
}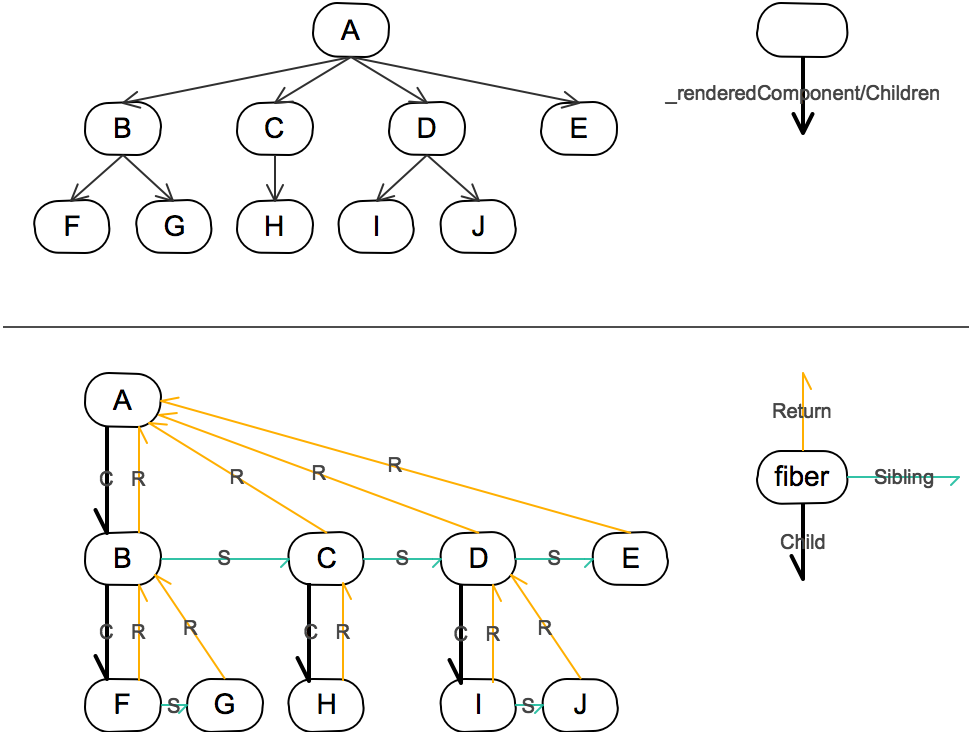
图片来源:完全理解React Fiber
function performUnitWork(currentFiber){
//beginWork(currentFiber) //找到儿子,并通过链表的方式挂到currentFiber上,每一偶儿子就找后面那个兄弟
//有儿子就返回儿子
if(currentFiber.child){
return currentFiber.child;
}
//如果没有儿子,则找弟弟
while(currentFiber){//一直往上找
//completeUnitWork(currentFiber);//将自己的副作用挂到父节点去
if(currentFiber.sibling){
return currentFiber.sibling
}
currentFiber = currentFiber.return;
}
}Concurrent Mode (并发模式)
Concurrent Mode 指的就是 React 利用上面 Fiber 带来的新特性的开启的新模式 (mode)。react17开始支持concurrent mode,这种模式的根本目的是为了让应用保持cpu和io的快速响应,它是一组新功能,包括Fiber、Scheduler、Lane,可以根据用户硬件性能和网络状况调整应用的响应速度,核心就是为了实现异步可中断的更新。concurrent mode也是未来react主要迭代的方向。
目前 React 实验版本允许用户选择三种 mode:
- Legacy Mode: 就相当于目前稳定版的模式
- Blocking Mode: 应该是以后会代替 Legacy Mode 而长期存在的模式
- Concurrent Mode: 以后会变成 default 的模式
Concurrent Mode 其实开启了一堆新特性,其中有两个最重要的特性可以用来解决我们开头提到的两个问题:
- Suspense:Suspense 是 React 提供的一种异步处理的机制, 它不是一个具体的数据请求库。它是React 提供的原生的组件异步调用原语。
- useTrasition:让页面实现
Pending -> Skeleton -> Complete的更新路径, 用户在切换页面时可以停留在当前页面,让页面保持响应。 相比展示一个无用的空白页面或者加载状态,这种用户体验更加友好。
其中 Suspense 可以用来解决请求阻塞的问题,UI 卡顿的问题其实开启 concurrent mode 就已经解决的,但如何利用 concurrent mode 来实现更友好的交互还是需要对代码做一番改动的。
资料参考:Concurrent 模式介绍 (实验性) | 理解 React Fiber & Concurrent Mode | 11.concurrent mode(并发模式是什么样的) | 人人都能读懂的react源码解析
Concurrent Mode只是并发,既然任务可拆分(只要最终得到完整effect list就行),那就允许并行执行,(多个Fiber reconciler + 多个worker),首屏也更容易分块加载/渲染(vDOM森林。
并行渲染的话,据说Firefox测试结果显示,130ms的页面,只需要30ms就能搞定,所以在这方面是值得期待的,而React已经做好准备了,这也就是在React Fiber上下文经常听到的待unlock的更多特性之一。
isInputPending —— Fiber架构思想对前端生态的影响
Facebook 在 Chromium 中提出并实现了 isInputPending() API,它可以提高网页的响应能力,但是不会对性能造成太大影响。Facebook 提出的 isInputPending API 是第一个将中断的概念用于浏览器用户交互的的功能,并且允许 JavaScript 能够检查事件队列而不会将控制权交于浏览器。
目前 isInputPending API 仅在 Chromium 的 87 版本开始提供,其他浏览器并未实现。
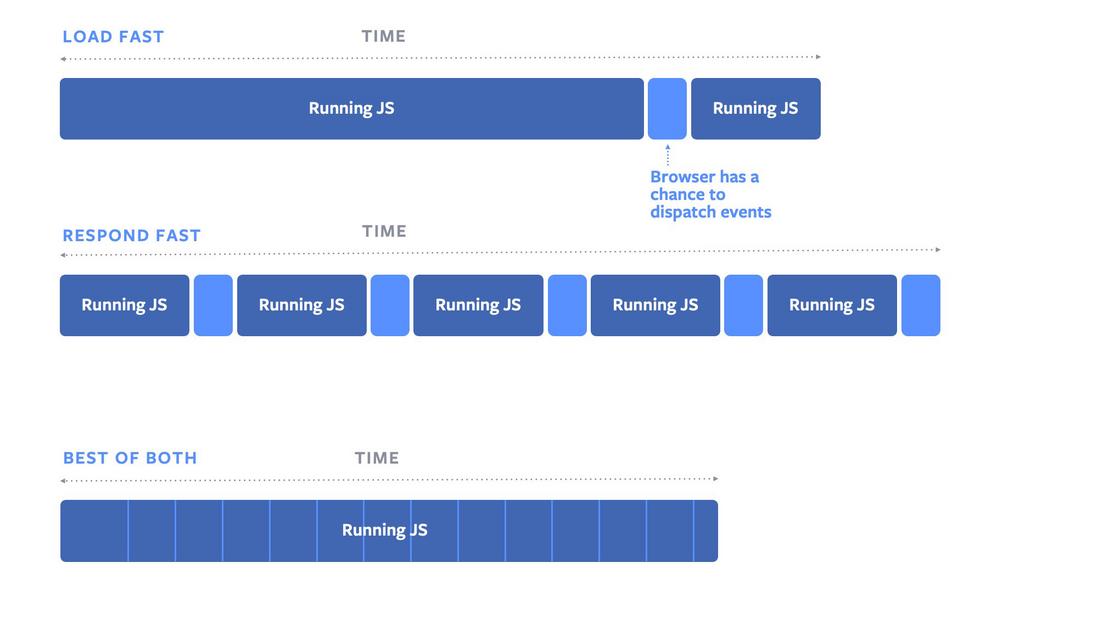
资料参考:Facebook 将对 React 的优化实现到了浏览器! | Faster input events with Facebook’s first browser API contribution
Svelte 对固有模式的冲击
当下前端领域,三大框架React、Vue、Angular版本逐渐稳定,如果说前端行业会出现哪些框架有可能会挑战React或者Vue呢?很多人认为Svelte 应该是其中的选项之一。
Svelte叫法是[Svelte], 本意是苗条纤瘦的,是一个新兴热门的前端框架。在开发者满意度、兴趣度、市场占有率上均名列前茅,同时,它有更小的打包体积,更少的开发代码书写,在性能测评中,与React、Vue相比,也不遑多让。
Svelte 的核心思想在于『通过静态编译减少框架运行时的代码量』。
Svelte 优势有哪些
- No Runtime —— 无运行时代码
- Less-Code —— 写更少的代码
- Hight-Performance —— 高性能
Svelte 劣势
Svelte 在编译时,就已经分析好了数据 和 DOM 节点之间的对应关系,在数据发生变化时,可以非常高效的来更新DOM节点。
- Rich Harris 在进行Svelte的设计的时候没有采用 Virtual DOM,主要是因为他觉得Virtual DOM Diff 的过程是非常低效的。具体可参考Virtual Dom 真的高效吗一文;Svelte 采用了Templates语法,在编译的过程中就进行优化操作;
- Svelte 记录脏数据的方式:位掩码(bitMask);
- 数据和DOM节点之间的对应关系:React 和 Vue 是通过 Virtual Dom 进行 diff 来算出来更新哪些 DOM 节点效率最高。Svelte 是在编译时候,就记录了数据 和 DOM 节点之间的对应关系,并且保存在 p 函数中。
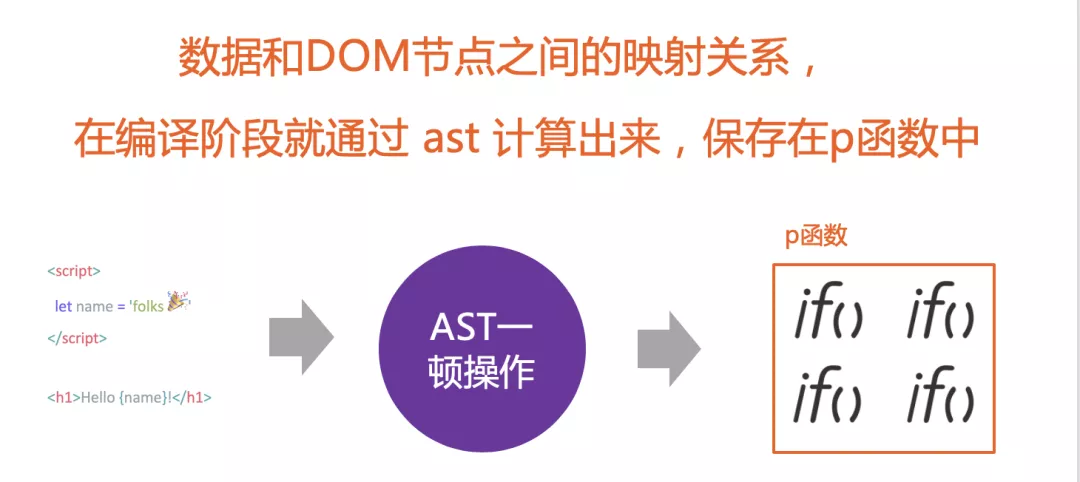
资料参考:新兴前端框架 Svelte 从入门到原理
资料参考与推荐
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK