

Running Atlantis at Lyft
source link: https://eng.lyft.com/running-atlantis-at-lyft-b95c7fa51db1
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Running Atlantis at Lyft
By: Nish Krishnan and Sarvar Muminov
Introduction
For the past couple of years, Terraform has been gaining traction as an easy-to-use, well-supported and flexible provisioning tool of choice in the industry and as such, has also been gaining increasing popularity within Lyft. While we initially chose to forego adoption of Terraform as our general configuration management solution in favor of stateless configuration, updates to Terraform’s language constraints and featureset made us reconsider.
As individual teams started using Terraform more and more, we found a number of centralized platforms starting to gain popularity at the company.
There was a homegrown Jenkins solution that was difficult to maintain, providing only the benefits of a central version of terraform but lacking any of the security features that a critical platform should contain.
There were a number of teams using a commercial product offering for Terraform automation and management, which was a great solution for its primary functions. However, this didn’t quite fit the needs of Lyft as whole so we chose to leverage Atlantis instead.
Atlantis is an Open Source Terraform Automation platform designed to be run as part of a version control provider’s pull request (PR) workflow. It gives us:
- Workflow customization on a per-team basis,
- Centralized permissions and binaries
- Audit logs in the form of VCS pull requests
- Apply guardrails such as PR approvals and mergeability
- Opportunities to iterate and contribute features/bug fixes upstream
System Architecture
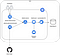
At Lyft, we manage our own Kubernetes stack which we leveraged to run Atlantis as well. We run Atlantis as a statefulset singleton with a persistent volume containing Atlantis’ state — PR state, plan files, terraform binaries etc. Running this on a mature infrastructure stack gives us a number of things for free including, logging, stats, deployment setups in addition to network access to our other Lyft services when we need it.
We run two ingress configurations for Atlantis:
- Internal only allows traffic from within our company’s VPN. This is used to load the static Atlantis app, providing details such as PR locks currently held and allowing force unlocks, global apply locks etc.
- Public only allows traffic on /events for VCS webhook integrations. This endpoint is secured using webhook secrets.
Instead of using webhooks directly, Atlantis is registered as a Github Application, which can be installed to any repository in our organization.
- This allows us to onboard repositories to Atlantis easily, since permissions are managed at the app level
- This gives us a higher rate limit threshold than webhook configuration
Since we also manage repository setups through code, we can enforce certain repository level settings for those with the Atlantis app installed. The one with the biggest benefit has been enforcing atlantis/apply as a required status check for Atlantis-managed repositories to prevent developers from merging changes before applying them.
Repository Configuration
As a platform team, we had to strike a balance between providing flexibility to our customers and limiting maintenance overhead for special cases. The default approach is to use a managed configuration option that abstracts the Atlantis configuration file from developers by integrating with existing Lyft service configuration tools. For non-standard cases, we provide an option to bypass the managed approach and directly create the Atlantis configuration file.
Service Manifests are used at Lyft, to define service-specific metadata such as on-call information, code repository, deploy pipeline configuration etc. Lyft’s reliance on manifests made it an easy choice to be used for infrastructure orchestration as well. This led to faster adoption due to familiarity, provided a standard for the underlying Atlantis configuration, and reduced the amount of work required to educate our customers.
Using the managed approach, only necessary fields are surfaced to the customer which are used to generate repo level configuration using pre workflow hooks. We implemented pre-workflow hooks to function similarly to custom workflows in that a predefined script can be executed. However, there are several differences between them:
- Execution occurs before a workflow on each command
- Hooks can only be defined in the server side repo configuration
- Errors are non-blocking and are transparent to the end user
A generated Atlantis configuration looks as follows:
version: 3
projects:
- name: <PROJECT_NAME>
dir: <PROJECT_DIR>
workflow: managed_backend
terraform_version: 0.14.5
autoplan:
enabled: true
With this setup, customers don’t have to think about the various configuration options for a given Atlantis project. Autoplan is enforced to catch errors at the time a pull request is opened. Terraform versions are managed transparently, allowing non-invasive upgrades. Finally, a single workflow can be enforced across all projects, in our case one which provides a standard for Terraform backends.
State Management
We enforce S3 as the backend in our managed Atlantis workflow. S3 provides a number of security features such as versioning, encryption and replication in addition to the access control benefits provided by AWS. We ensure that only Atlantis and Atlantis operators have access to these states for compliance purposes.
We also use DynamoDB as a lock provider. On top of what Atlantis already provides at the pull request layer, this provides an additional blanket of security when doing out-of-band terraform operations (e.g., state manipulations).
Given that we enforce a managed workflow by default, we are able to dynamically generate the backend for a given project by leveraging a combination of custom run steps and override files.
Prior to running terraform init the managed_backend workflow runs the following script to create a backend override file:
A couple things to point out:
- BASE_REPO_OWNER, BASE_REPO_NAME, and PROJECT_NAME are all provided to the run step by Atlantis
- TERRAFORM_STATES_LOCKS_TABLE, TERRAFORM_STATES_BUCKET are global environment variables we’ve defined in our image.
There are a number of advantages to overriding the backend at runtime:
- We can conveniently swap the backends as necessary,
- We can enforce a schema for partitioning our data allowing for easier management and future automation
- Offloads the complexity of correctly defining a backend from developers.
But the biggest benefit is, It just works.
Safety and Security
At Lyft, apply requirements are used to require that all pull requests are approved by another engineer and all of its status checks are passing. This ensures that we are meeting existing compliance standards defined for our code deployments.
Although a PR review works well for detecting issues, automation is more scalable and can be used for managing more nuanced risks. We implemented a policy checking command to run a predefined set of policies against the plan output as an additional layer of security and safety. This enables the team, as operators, to enforce best practices and mitigate common security risks. Additionally, policies can be used to detect changes that might be harmful and require secondary approval from a domain-specific team. Policies are written using conftest, a wrapper around Open Policy Agent(OPA), which makes it easy to evaluate structured files.
Some of our use cases for this step include:
- Checking for any destructive changes to critical infrastructure(VPCs, DNS records, datastores, etc).
- Denying resource provisioning through unauthorized modules.
Finally, in the event of a code freeze, or a bad Atlantis deploy, we added an API endpoint to lock all applies through the platform. This allows us to quickly and temporarily halt infrastructure provisioning without bringing down Atlantis.
Observability
Lyft infrastructure gives us service level metrics by default, but we’ve added a number of application level metrics to Atlantis to track failures, successes and latencies across each command (Plan/Apply/Policy Check), and Github API calls. Metrics are emitted using gostats, a wrapper around statsd.
In addition to metrics, we’ve added structured logging to Atlantis to replace its own logging implementation, a wrapper around the default go logging library. Structured logging is useful for a couple of use cases:
- Processing log files for analytics (e.g., aggregations)
- Querying logs across multiple dimensions in a consistent fashion
This second point in particular, is what we were looking for. We wanted a central place we could look to see all the changes that Atlantis has made in the past X period of time. This is super useful when we are diagnosing on-going incidents. Additionally, we also need to be able to query this data e.g. filtering by repository, pull request number, project or any combination of the three. Since our logs are ingested by Elasticsearch and searchable using Kibana, defining structured logs allows us to use a flexible query DSL to search to our heart’s content.
Current State of the World
We’ve been running Atlantis with this setup for 6 months now. Since then, our team has contributed a number of features upstream, has become core maintainers of Atlantis and has scaled the platform to operate on 2000+ Terraform projects across the company. We have multiple teams contributing Terraform modules and conftest policies in an effort to streamline infrastructure orchestration around a pre-defined standard.
Upstream Contributions
Pre-workflow hooks — partially released in 0.16.0, with full functionality in 0.17.0-beta
Policy checking — released in 0.17.0-beta
Structured logging — coming soon
Global Apply lock — coming soon
Getting started with Atlantis
If you’d like to try out Atlantis for your team, you can download the latest release.
Note: we are currently running our own fork of 0.17.0-beta in production.
To read more about Atlantis check out: https://www.runatlantis.io.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK