

Secure coding with Snyk Code: Ignore functionality with a twist
source link: https://snyk.io/blog/secure-coding-snyk-code-ignore-feature-twist/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Secure coding with Snyk Code: Ignore functionality with a twist

Frank Fischer
March 30, 2021
When scanning your code with our secure coding tool, Snyk Code might find all kinds of security vulnerabilities. And while Snyk Code is fast, accurate, and rich in content, sometimes there is the need to suppress specific warnings. Typical example use cases arise in test code when you explicitly use hard coded passwords to test your routines, or you know about an issue but decide not to fix it. For this situation, Snyk Code—as well as the other Snyk platform products—provides the ability to ignore suggestions.
And there is more to ignore than you think (at least more than I thought). Let’s explore how you ignore an issue, and then take look behind the scenes at how we implemented the feature.
How to use the ignore feature in Snyk Code
In the Snyk Code web UI, you will find a new button called Ignore (on the lower right side with a crossed-out eye as an icon):
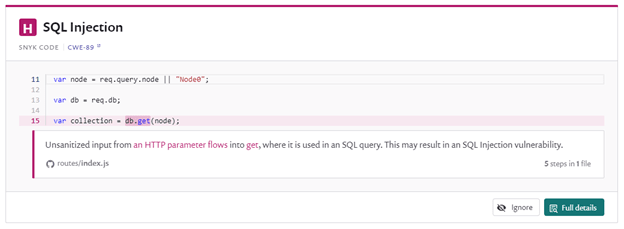
It enables you to configure the static application security testing (SAST) engine. We’ll explore how it works in a bit, but for now, let’s focus on the usage.
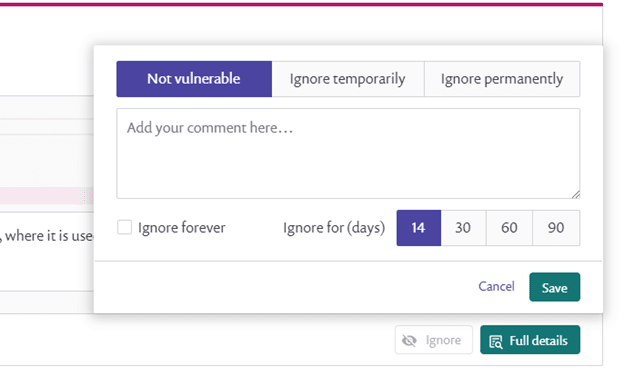
When you click on Ignore, you will see an overlay (shown above). The first step is to provide a classification of whether this is to be marked not vulnerable, ignore temporarily (so you just want to suppress the message for now), or ignore permanently (won’t fix). Next, you have the opportunity to write a comment to yourself or your colleagues (and we highly recommend writing a quick explanation, as sometimes last week’s decisions are mystical without a few comments). Finally, you can set a timer for how long to ignore the issue (14, 30, 60, or 90 days to forever).
If you select to ignore an issue, it is not shown by default. There is a status selector for ignored issues on the left side, and you can include those (and remove or edit the ignore flag). To learn more about this feature, check out our Snyk Code ignore documentation.
Ignoring suggestions is not as simple as it seems
Obviously, to flag something to be ignored (or not integrated into the issue report), an issue needs to be identified stably. Every re-scan you do, the engine needs to find the same issue and flag it again. Clearly, the algorithm cannot simply remember the filename and line number, as code is constantly changing, and so can the line number. The traditional solution used by linters is to add a comment next to the issue telling the system to ignore it. This was also the original implementation we followed. However, we got feedback from some developers that they didn’t like peppering their code with comments just to configure static code analysis. Therefore we came up with a unique and (in our opinion) superior solution.
Traditional systems use the source code where the issue happens (and few lines around it), calculate a hash, and use it as identification for the issue. Changing the text changes the issue ID, and thus deleting all flags assigned to the issue. But we as humans think a bit differently. If I add a comment next to the issue, I have not changed the issue itself in reality, but the hash changed and the issue will be seen as a new one.
To remedy this, most other tools will only match a few lines of the report. This leads to either ignoring similar reports in case another issue with a similar signature reappears (too aggressive ignoring). Or it would forget the match when unrelated code changes happen (causing spam reports). To have an acceptable mechanism, some tools even use assembled lists with dozens of exceptions on how reports are matched. Both of these approaches are flawed. They fundamentally operate on the text-level, unaware of the analyzer that provided the actual result. It is as if they treat the words of a sentence as a sequence of characters without trying to understand the meaning.
How Snyk Code implements Ignore
One thing that static code analysis does is transform the input code into what is called an intermediate representation. This is a data structure that captures the data or control flow of code but abstracts away some details. Our idea is to use this representation to generate the hash. So, the implementation recognizes the same issue even when you refactor your code or rename a variable. Furthermore, we loosened the exact match requirements, so most small changes to code with an ignored issue will not cause irrelevant reappearances of the report.
By going on a semantic level of matching, we can recognize the same issue as before, just as a human developer would. And you do no longer need comments in your source code. As an example, the following two code snippets—despite textual differences—denounce the same issue as we only renamed the variables:
var fs = require('fs');
var logFileName = req.query.file || 'standard_log.log';
var logfile = fs.readFile(logFileName, "utf8", function(err, data) {...var filesystem = require('fs');
var generalLogFileName = req.query.file || 'standard_log.log';
var handleLogFile = filesystem.readFile(generalLogFileName, "utf8", function(err, data) {...We won’t ignore feedback
We hope you find this new take on ignore functionality to be more useful. This is just one example of how our users gave us valuable feedback that we could act upon. Please, let us know how you like the new ignore feature and how we can improve the product in the future. We love to hear your feedback.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK