

死磕以太坊源码分析之Fetcher同步
source link: https://learnblockchain.cn/article/2158
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

死磕以太坊源码分析之 Fetcher 同步
Fetcher 功能概述
区块数据同步分为被动同步和主动同步:
-
被动同步是指本地节点收到其他节点的一些广播的消息,然后请求区块信息。
-
主动同步是指节点主动向其他节点请求区块数据,比如 geth 刚启动时的 syning,以及运行时定时和相邻节点同步
Fetcher 负责被动同步,主要做以下事情:
- 收到完整的 block 广播消息(NewBlockMsg)
- 收到 blockhash 广播消息(NewBlockHashesMsg)
这两个消息又是分别由 peer.AsyncSendNewBlockHash 和 peer.AsyncSendNewBlock 两个方法发出的,这两个方法只有在矿工挖到新的区块时才会被调用:
// 订阅本地挖到新的区块的消息
func (pm *ProtocolManager) minedBroadcastLoop() {
for obj := range pm.minedBlockSub.Chan() {
if ev, ok := obj.Data.(core.NewMinedBlockEvent); ok {
pm.BroadcastBlock(ev.Block, true) // First propagate block to peers
pm.BroadcastBlock(ev.Block, false) // Only then announce to the rest
}
}
}
func (pm *ProtocolManager) BroadcastBlock(block *types.Block, propagate bool) {
......
if propagate {
......
for _, peer := range transfer {
peer.AsyncSendNewBlock(block, td) //发送区块数据
}
}
if pm.blockchain.HasBlock(hash, block.NumberU64()) {
for _, peer := range peers {
peer.AsyncSendNewBlockHash(block) //发送区块哈希
}
}
}
所以,当某个矿工产生了新的区块、并将这个新区块广播给其它节点,而其它远程节点收到广播的消息时,才会用到 fetcher 模块去同步这些区块。
fetcher 的状态字段
在 Fetcher 内部对区块进行同步时,会被分成如下几个阶段,并且每个阶段都有一个状态字段与之对应,用来记录这个阶段的数据:
Fetcher.announced:此阶段代表节点宣称产生了新的区块(这个新产生的区块不一定是自己产生的,也可能是同步了其它节点新产生的区块),Fetcher对象将相关信息放到Fetcher.announced中,等待下载。Fetcher.fetching:此阶段代表之前「announced」的区块正在被下载。Fetcher.fetched:代表区块的header已下载成功,现在等待下载body。Fetcher.completing:代表body已经发起了下载,正在等待body下载成功。Fetcher.queued:代表body已经下载成功。因此一个区块的数据:header和 body 都已下载完成,此区块正在等待写入本地数据库。
Fetcher 同步区块哈希
而新产生区块时,会使用消息 NewBlockHashesMsg 和 NewBlockMsg 对其进行传播。因此 Fetcher 对象也是从这两个消息处发现新的区块信息的。先来看同步区块哈希的过程。
case msg.Code == NewBlockHashesMsg:
var announces newBlockHashesData
if err := msg.Decode(&announces); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
// Mark the hashes as present at the remote node
// 将hash 标记存在于远程节点上
for _, block := range announces {
p.MarkBlock(block.Hash)
}
// Schedule all the unknown hashes for retrieval 检索所有未知哈希
unknown := make(newBlockHashesData, 0, len(announces))
for _, block := range announces {
if !pm.blockchain.HasBlock(block.Hash, block.Number) {
unknown = append(unknown, block) // 本地不存在的话就扔到unkonwn里面
}
}
for _, block := range unknown {
pm.fetcher.Notify(p.id, block.Hash, block.Number, time.Now(), p.RequestOneHeader, p.RequestBodies)
}
先将接收的哈希标记在远程节点上,然后去本地检索是否有这个哈希,如果本地数据库不存在的话,就放到 unknown 里面,然后通知本地的 fetcher 模块再去远程节点上请求此区块的 header 和 body。 接下来进入到 fetcher.Notify 方法中。
func (f *Fetcher) Notify(peer string, hash common.Hash, number uint64, time time.Time,
headerFetcher headerRequesterFn, bodyFetcher bodyRequesterFn) error {
block := &announce{
hash: hash,
number: number,
time: time,
origin: peer,
fetchHeader: headerFetcher,
fetchBodies: bodyFetcher,
}
select {
case f.notify <- block:
return nil
case <-f.quit:
return errTerminated
}
它构造了一个 announce 结构,并将其发送给了 Fetcher.notify 这个 channel。注意 announce 这个结构里带着下载 header 和 body 的方法: fetchHeader 和 fetchBodies 。这两个方法在下面的过程中会讲到。 接下来我们进入到 fetcher.go 的 loop 函数中,找到 notify,分以下几个内容:
①:校验防止 Dos 攻击(限制为 256 个)
count := f.announces[notification.origin] + 1
if count > hashLimit {
log.Debug("Peer exceeded outstanding announces", "peer", notification.origin, "limit", hashLimit)
propAnnounceDOSMeter.Mark(1)
break
}
②:新来的块号必须满足 chainHeight−blockno<7 或者 blockno−chainHeight<32
if notification.number > 0 {
if dist := int64(notification.number) - int64(f.chainHeight()); dist < -maxUncleDist || dist > maxQueueDist {
... }
}
③:准备下载 header 的 fetching 中存在此哈希则跳过
if _, ok := f.fetching[notification.hash]; ok {
break
}
④:准备下载 body 的 completing 中存在此哈希也跳过
if _, ok := f.completing[notification.hash]; ok {
break
}
⑤:当确定 fetching 和 completing 不存在此区块哈希时,则把此区块哈希放入到 announced 中,准备拉取 header 和 body。
f.announced[notification.hash] = append(f.announced[notification.hash], notification)
⑥:如果 Fetcher.announced 中只有刚才新加入的这一个区块哈希,那么调用 Fetcher.rescheduleFetch 重新设置变量 fetchTimer 的周期
if len(f.announced) == 1 {
f.rescheduleFetch(fetchTimer)
}
拉取 header
接下来就是到 fetchTimer.C 函数中:进行拉取 header 的操作了,具体步骤如下:
①:选择要下载的区块,从 announced 转移到 fetching 中
for hash, announces := range f.announced {
if time.Since(announces[0].time) > arriveTimeout-gatherSlack {
// 随机挑一个进行fetching
announce := announces[rand.Intn(len(announces))]
f.forgetHash(hash)
// If the block still didn't arrive, queue for fetching
if f.getBlock(hash) == nil {
request[announce.origin] = append(request[announce.origin], hash)
f.fetching[hash] = announce //
}
}
}
②:发送下载 header 的请求
//发送所有的header请求
for peer, hashes := range request {
log.Trace("Fetching scheduled headers", "peer", peer, "list", hashes)
fetchHeader, hashes := f.fetching[hashes[0]].fetchHeader, hashes
go func() {
if f.fetchingHook != nil {
f.fetchingHook(hashes)
}
for _, hash := range hashes {
headerFetchMeter.Mark(1)
fetchHeader(hash)
}
}()
}
现在我们再回到 f.notify 函数中,找到 p.RequestOneHeader,发送 GetBlockHeadersMsg 给远程节点,然后远程节点再通过 case msg.Code == GetBlockHeadersMsg 进行处理,本地区块链会返回 headers,然后再发送回去。
origin = pm.blockchain.GetHeaderByHash(query.Origin.Hash)
...
p.SendBlockHeaders(headers)
这时候我们请求的 headers 被远程节点给发送回来了,又是通过新的消息 BlockHeadersMsg 来传递的,当请求的 header 到来时,会通过两种方式来过滤 header :
Fetcher.FilterHeaders通知Fetcher对象
case msg.Code == BlockHeadersMsg:
....
filter := len(headers) == 1
if filter {
headers = pm.fetcher.FilterHeaders(p.id, headers, time.Now())
}
2.downloader.DeliverHeaders 通知 downloader 对象
if len(headers) > 0 || !filter {
err := pm.downloader.DeliverHeaders(p.id, headers)
...
}
downloader 相关的放在接下的文章探讨。继续看 FilterHeaders:
filter := make(chan *headerFilterTask)
select {
case f.headerFilter <- filter: ①
....
select {
case filter <- &headerFilterTask{peer: peer, headers: headers, time: time}: ②
...
select {
case task := <-filter: ③
return task.headers
...
}
主要分为 3 个步骤:
- 先发一个通信用的
channel给headerFilter - 将要过滤的
headerFilterTask发送给filter - 检索过滤后剩余的标题
主要的处理步骤还是在 loop 函数中的 filter := <-f.headerFilter,在探讨处理前,先了解三个参数的含义:
unknown:未知的 headerincomplete:header 拉取完成,但是 body 还没有拉取complete:header 和 body 都拉取完成,一个完整的块,可导入到数据库
接下来正式进入到 for _, header := range task.headers {} 循环中: 这是第一段重要的循环
①:判断是否是在 fetching 中的 header,并且不是其他同步算法的 header
if announce := f.fetching[hash]; announce != nil && announce.origin == task.peer && f.fetched[hash] == nil && f.completing[hash] == nil && f.queued[hash] == nil {
.....
}
②:如果传递的 header 与承诺的 number 不匹配,删除 peer
if header.Number.Uint64() != announce.number {
f.dropPeer(announce.origin)
f.forgetHash(hash)
}
③:判断此区块在本地是否已存在,如果不存在且只有 header(空块),直接放入 complete 以及 f.completing 中,否则就放入到 incomplete 中等待同步 body。
if f.getBlock(hash) == nil {
announce.header = header
announce.time = task.time
if header.TxHash == types.DeriveSha(types.Transactions{}) && header.UncleHash == types.CalcUncleHash([]*types.Header{}) {
...
block := types.NewBlockWithHeader(header)
block.ReceivedAt = task.time
complete = append(complete, block)
f.completing[hash] = announce
continue
}
incomplete = append(incomplete, announce) // 否则添加到需要完成拉取body的列表中
④:如果 f.fetching 中不存在此哈希,就放入到 unkown 中
else {
// Fetcher doesn't know about it, add to the return list |fetcher 不认识的放到unkown中
unknown = append(unknown, header)
}
⑤:之后再把 Unknown 的 header 再通知 fetcher 继续过滤
select {
case filter <- &headerFilterTask{headers: unknown, time: task.time}:
case <-f.quit:
return
}
接着就是进入到第二个循环,要准备拿出 incomplete 里的哈希,进行同步 body 的同步
for _, announce := range incomplete {
hash := announce.header.Hash()
if _, ok := f.completing[hash]; ok {
continue
}
f.fetched[hash] = append(f.fetched[hash], announce)
if len(f.fetched) == 1 {
f.rescheduleComplete(completeTimer)
}
}
如果 f.completing 中存在,就表明已经在开始同步 body 了,直接跳过,否则把这个哈希放入到 f.fetched,表示 header 同步完毕,准备 body 同步,由 f.rescheduleComplete(completeTimer) 完成。最后是安排只有 header 的区块进行导入操作。
for _, block := range complete {
if announce := f.completing[block.Hash()]; announce != nil {
f.enqueue(announce.origin, block)
}
}
重点分析 completeTimer.C,同步 body 的操作,这步完成就是要准备区块导入到数据库流程了。
拉取 body
进入 completeTimer.C,从 f.fetched 获取哈希,如果本地区块链查不到的话就把这个哈希放入到 f.completing 中,再循环进行 fetchBodies,整个流程就结束了,代码大致如下:
case <-completeTimer.C:
...
for hash, announces := range f.fetched {
....
if f.getBlock(hash) == nil {
request[announce.origin] = append(request[announce.origin], hash)
f.completing[hash] = announce
}
}
for peer, hashes := range request {
...
go f.completing[hashes[0]].fetchBodies(hashes)
}
...
关键的拉取 body 函数: p.RequestBodies,发送 GetBlockBodiesMsg 消息同步 body。回到 handler 里面去查看对应的消息:
case msg.Code == GetBlockBodiesMsg:
// Decode the retrieval message
msgStream := rlp.NewStream(msg.Payload, uint64(msg.Size))
if _, err := msgStream.List(); err != nil {
return err
}
var (
hash common.Hash
bytes int
bodies []rlp.RawValue
)
for bytes < softResponseLimit && len(bodies) < downloader.MaxBlockFetch {
...
if data := pm.blockchain.GetBodyRLP(hash); len(data) != 0 {
bodies = append(bodies, data)
bytes += len(data)
}
}
return p.SendBlockBodiesRLP(bodies)
softResponseLimit 返回的 body 大小最大为 $2 * 1024 * 1024$,MaxBlockFetch 表示每个请求最多 128 个 body。
之后直接通过 GetBodyRLP 返回数据通过 SendBlockBodiesRLP 发回给节点。
节点将会接收到新消息:BlockBodiesMsg,进入查看:
// 过滤掉filter请求的body 同步,其他的都交给downloader
filter := len(transactions) > 0 || len(uncles) > 0
if filter {
transactions, uncles = pm.fetcher.FilterBodies(p.id, transactions, uncles, time.Now())
}
if len(transactions) > 0 || len(uncles) > 0 || !filter {
err := pm.downloader.DeliverBodies(p.id, transactions, uncles)
...
}
过滤掉 filter 请求的 body 同步,其他的都交给 downloader,downloader 部分之后的篇章讲。进入到 FilterBodies:
filter := make(chan *bodyFilterTask)
select {
case f.bodyFilter <- filter: ①
case <-f.quit:
return nil, nil
}
// Request the filtering of the body list
// 请求过滤body 列表
select { ②
case filter <- &bodyFilterTask{peer: peer, transactions: transactions, uncles: uncles, time: time}:
case <-f.quit:
return nil, nil
}
// Retrieve the bodies remaining after filtering
select { ③:
case task := <-filter:
return task.transactions, task.uncles
主要分为 3 个步骤:
- 先发一个通信用的
channel给bodyFilter - 将要过滤的
bodyFilterTask发送给filter - 检索过滤后剩余的
body
现在进入到 case filter := <-f.bodyFilter 里面,大致做了以下几件事:
①:首先从 f.completing 中获取要同步 body 的哈希
for i := 0; i < len(task.transactions) && i < len(task.uncles); i++ {
for hash, announce := range f.completing {
...
}
}
②:然后从 f.queued 去查这个哈希是不是已经获取了 body,如果没有并满足条件就创建一个完整 block
if f.queued[hash] == nil {
txnHash := types.DeriveSha(types.Transactions(task.transactions[i]))
uncleHash := types.CalcUncleHash(task.uncles[i])
if txnHash == announce.header.TxHash && uncleHash == announce.header.UncleHash && announce.origin == task.peer {
matched = true
if f.getBlock(hash) == nil {
block := types.NewBlockWithHeader(announce.header).WithBody(task.transactions[i], task.uncles[i])
block.ReceivedAt = task.time
blocks = append(blocks, block)
}
}
③:最后对完整的块进行导入
for _, block := range blocks {
if announce := f.completing[block.Hash()]; announce != nil {
f.enqueue(announce.origin, block)
}
}
最后用一张粗略的图来大概的描述一下整个同步区块哈希的流程:
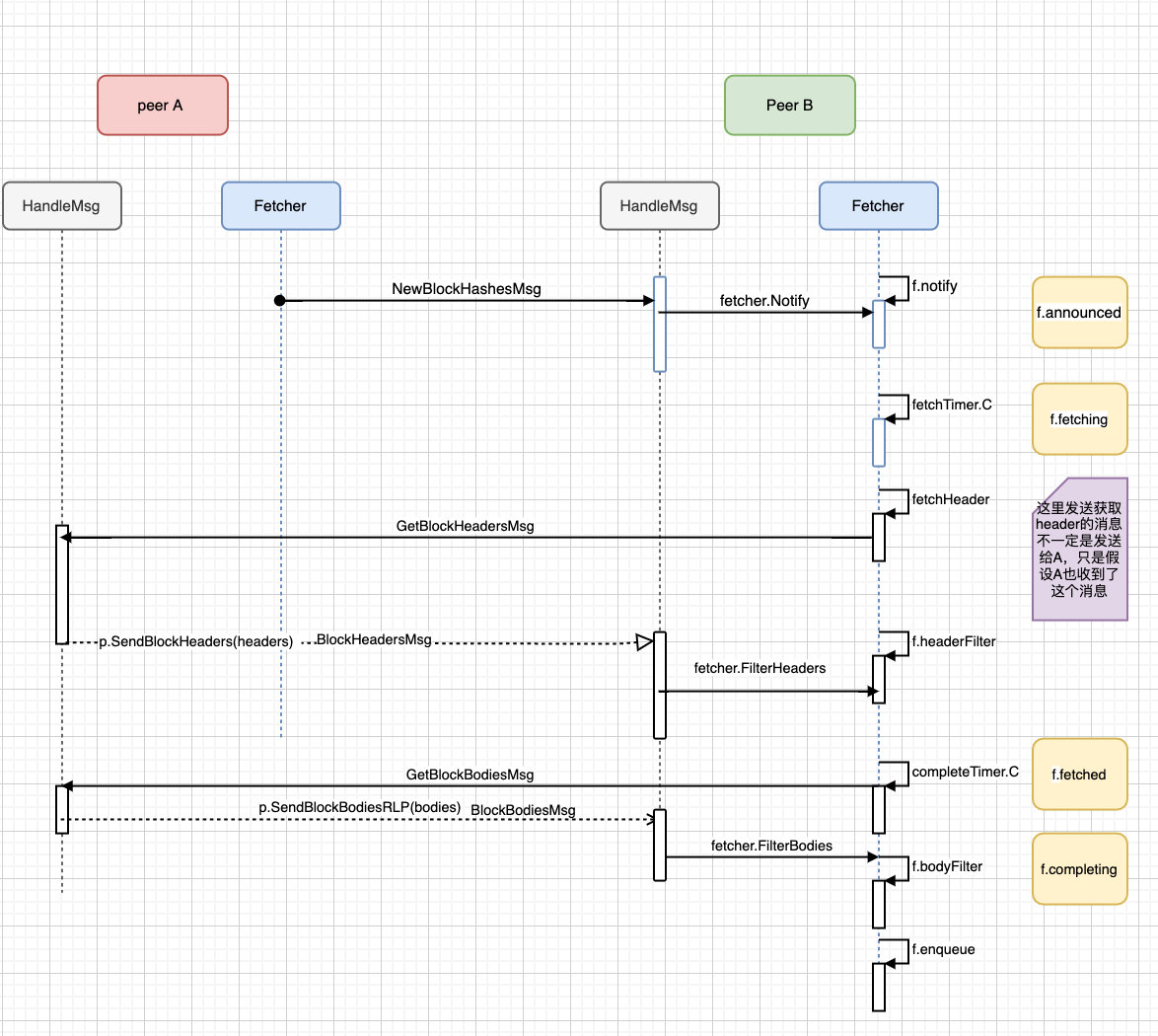
同步区块哈希的最终会走到 f.enqueue 里面,这个也是同步区块最重要的要做的一件事,下文就会讲到。
Fetcher 同步区块
分析完上面比较复杂的同步区块哈希过程,接下来就要分析比较简单的同步区块过程。从 NewBlockMsg 开始:
主要做两件事:
①:fetcher 模块导入远程节点发过来的区块
pm.fetcher.Enqueue(p.id, request.Block)
②:主动同步远程节点
if _, td := p.Head(); trueTD.Cmp(td) > 0 {
p.SetHead(trueHead, trueTD)
currentBlock := pm.blockchain.CurrentBlock()
if trueTD.Cmp(pm.blockchain.GetTd(currentBlock.Hash(), currentBlock.NumberU64())) > 0 {
go pm.synchronise(p)
}
}
主动同步由 Downloader 去处理,我们这篇只讨论 fetcher 相关。
区块入队列
pm.fetcher.Enqueue(p.id, request.Block)
case op := <-f.inject:
propBroadcastInMeter.Mark(1)
f.enqueue(op.origin, op.block)
正式进入将区块送进 queue 中,主要做了以下几件事:
①: 确保新加 peer 没有导致 DOS 攻击
count := f.queues[peer] + 1
if count > blockLimit {
log.Debug("Discarded propagated block, exceeded allowance", "peer", peer, "number", block.Number(), "hash", hash, "limit", blockLimit)
propBroadcastDOSMeter.Mark(1)
f.forgetHash(hash)
return
}
②:丢弃掉过去的和比较老的区块
if dist := int64(block.NumberU64()) - int64(f.chainHeight()); dist < -maxUncleDist || dist > maxQueueDist {
f.forgetHash(hash)
}
③:安排区块导入
if _, ok := f.queued[hash]; !ok {
op := &inject{
origin: peer,
block: block,
}
f.queues[peer] = count
f.queued[hash] = op
f.queue.Push(op, -int64(block.NumberU64()))
if f.queueChangeHook != nil {
f.queueChangeHook(op.block.Hash(), true)
}
log.Debug("Queued propagated block", "peer", peer, "number", block.Number(), "hash", hash, "queued", f.queue.Size())
}
到此为止,已经将区块送入到 queue 中,接下来就是要回到 loop 函数中去处理 queue 中的区块。
loop 函数在处理队列中的区块主要做了以下事情:
- 判断队列是否为空
- 取出区块哈希,并且和本地链进行比较,如果太高的话,就暂时不导入
- 最后通过 f.insert 将区块插入到数据库。
代码如下:
height := f.chainHeight()
for !f.queue.Empty() {
op := f.queue.PopItem().(*inject)
hash := op.block.Hash()
...
number := op.block.NumberU64()
if number > height+1 {
f.queue.Push(op, -int64(number))
...
break
}
if number+maxUncleDist < height || f.getBlock(hash) != nil {
f.forgetBlock(hash)
continue
}
f.insert(op.origin, op.block) //导入块
}
进入到 f.insert 中,主要做了以下几件事:
①:判断区块的父块是否存在,不存在则中断插入
parent := f.getBlock(block.ParentHash())
if parent == nil {
log.Debug("Unknown parent of propagated block", "peer", peer, "number", block.Number(), "hash", hash, "parent", block.ParentHash())
return
}
②: 快速验证 header,并在传递时广播该块
switch err := f.verifyHeader(block.Header()); err {
case nil:
propBroadcastOutTimer.UpdateSince(block.ReceivedAt)
go f.broadcastBlock(block, true)
③:运行真正的插入逻辑
if _, err := f.insertChain(types.Blocks{block}); err != nil {
log.Debug("Propagated block import failed", "peer", peer, "number", block.Number(), "hash", hash, "err", err)
return
}
④:导入成功广播此块
go f.broadcastBlock(block, false)
真正做区块入库的是 f.insertChain,这里会调用 blockchain 模块去操作,具体细节会后续文章讲述,到此为止 Fether 模块的同步就到此结束了,下面是同步区块的流程图:
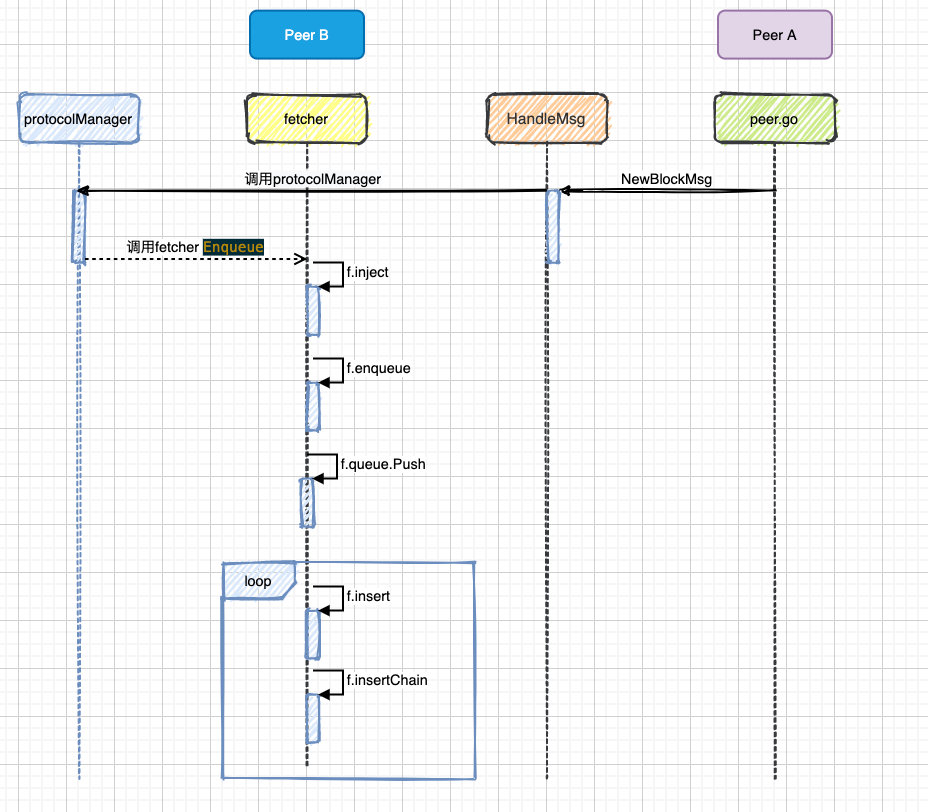
https://github.com/blockchainGuide (文章资料在此,给个 Star 哦)
Recommend
-
40
前言 这篇文章从区块传播策略入手,介绍新区块是如何传播到远端节点,以及新区块加入到远端节点本地链的过程,同时会介绍fetcher模块,fetcher的功能是处理Peer通知的区块信息。在介绍过程中,还会涉及到p2p,eth等模块,不会...
-
12
死磕以太坊源码分析之挖矿流程分析 代码分支: https://github.com/ethereum/g... 基本架构 以太坊挖矿的主要流程是由...
-
15
死磕以太坊源码分析之p2p网络启动 死磕以太坊源码分析之p2p网络启动 相关代码:https://github.com/blockchainGuide/ 持续输出区块链相关技术文章,喜欢作者可以持续关注,文章有问题,可以随时指出...
-
7
死磕以太坊源码分析之p2p节点发现 死磕以太坊源码分析之 p2p 节点发现 在阅...
-
10
死磕以太坊源码分析之 Kademlia 算法 KAD 算法概述 Kademlia 是一种点对点分布式哈希表(DHT),它在容易出错的环境中也具有可证明的一致性和性能。使用一种基于异或指标的拓扑结构来路由查询和定位节点,这简化了...
-
7
死磕以太坊源码分析之 rlpx 协议 文章资料:https://github.com/blockchainGuide/blockchainguide 本文主要参考自 eth 官方文档:
-
11
死磕以太坊源码分析之state 配合以下代码进行阅读: https://github.com/blockchainGuide/ 希望读者在阅读过程中发现问题可以及时评论哦,大家一起进步。
-
11
死磕以太坊源码分析之EVM指令集 配合以下代码进行阅读: https://github.com/blockchainGuide/ 写文不易,给个小关注,有什么问题可以指出,便于大家交流学习。 ...
-
6
死磕以太坊源码分析之挖矿流程 死磕以太坊源码分析之挖矿流程 https://github.com/blockchainGuide (文章资料在此,给个Star哦) 基本架构 以太坊挖矿的主要流程是由 miner 包负...
-
5
死磕以太坊源码分析之blockChain分析 配合以下代码进行阅读:https://github.com/blockchainGuide/ 写文不易,给个小关注,有什么问题可以指出,便于大家交流学习。
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK